SparkSQL 聚合函数 MAX 对 NULL 值的处理
SparkSQL 聚合函数 MAX 对 NULL 值的处理
官网:https://spark.apache.org/docs/4.0.0/sql-ref-functions.html
https://spark.apache.org/docs/4.0.0/sql-ref-null-semantics.html#builtin-aggregate-expressions

MAX(column)会自动忽略NULL值,只在非空值中寻找最大值。
- 如果整列都是
NULL,则返回NULL;- 如果列中只有部分为
NULL,不影响最大值的计算。
Demo:
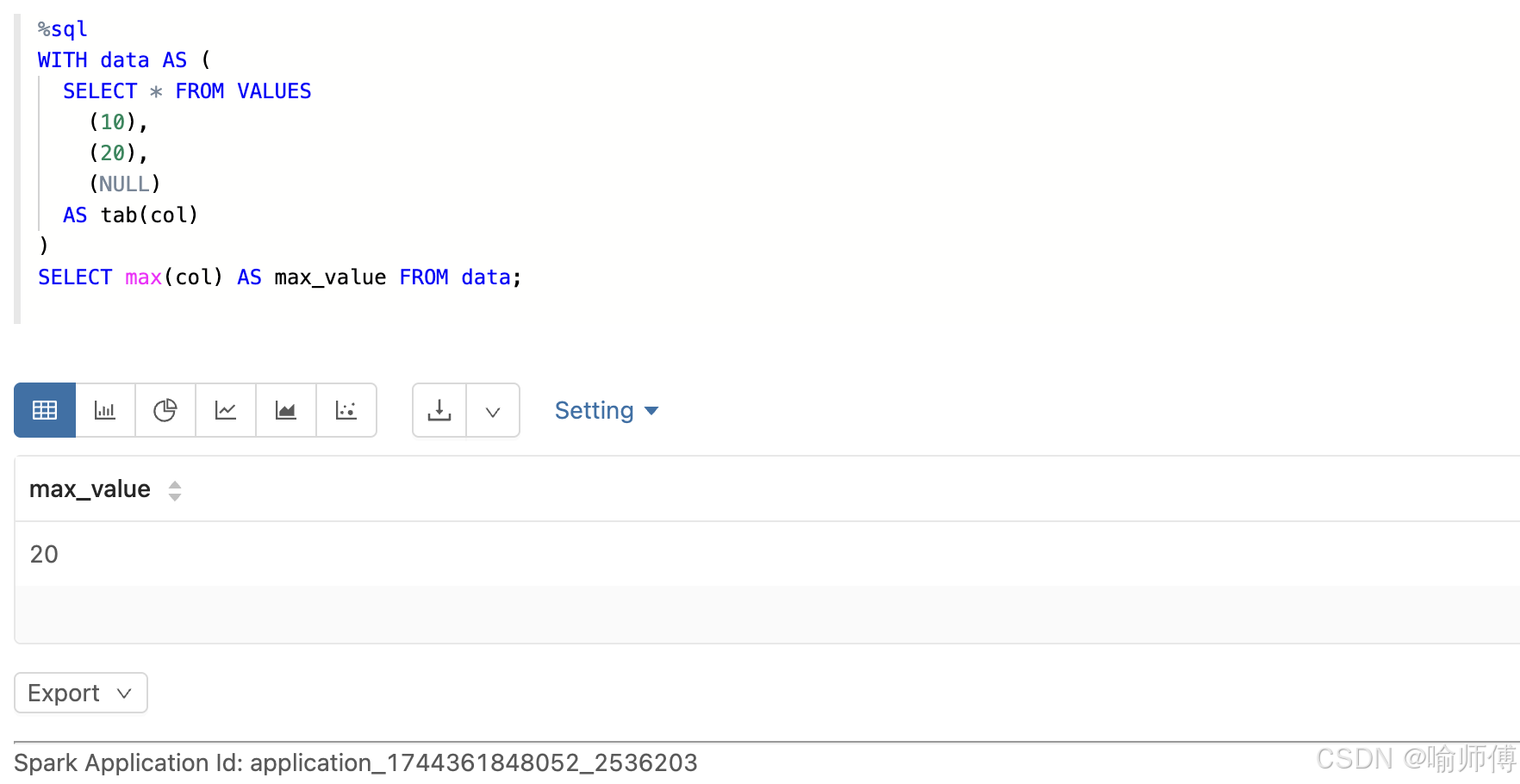
WITH data AS (SELECT * FROM VALUES(10),(20),(NULL)AS tab(col)
)
SELECT max(col) AS max_value FROM data;
-- 找到最大值 30,忽略所有 NULL 值。
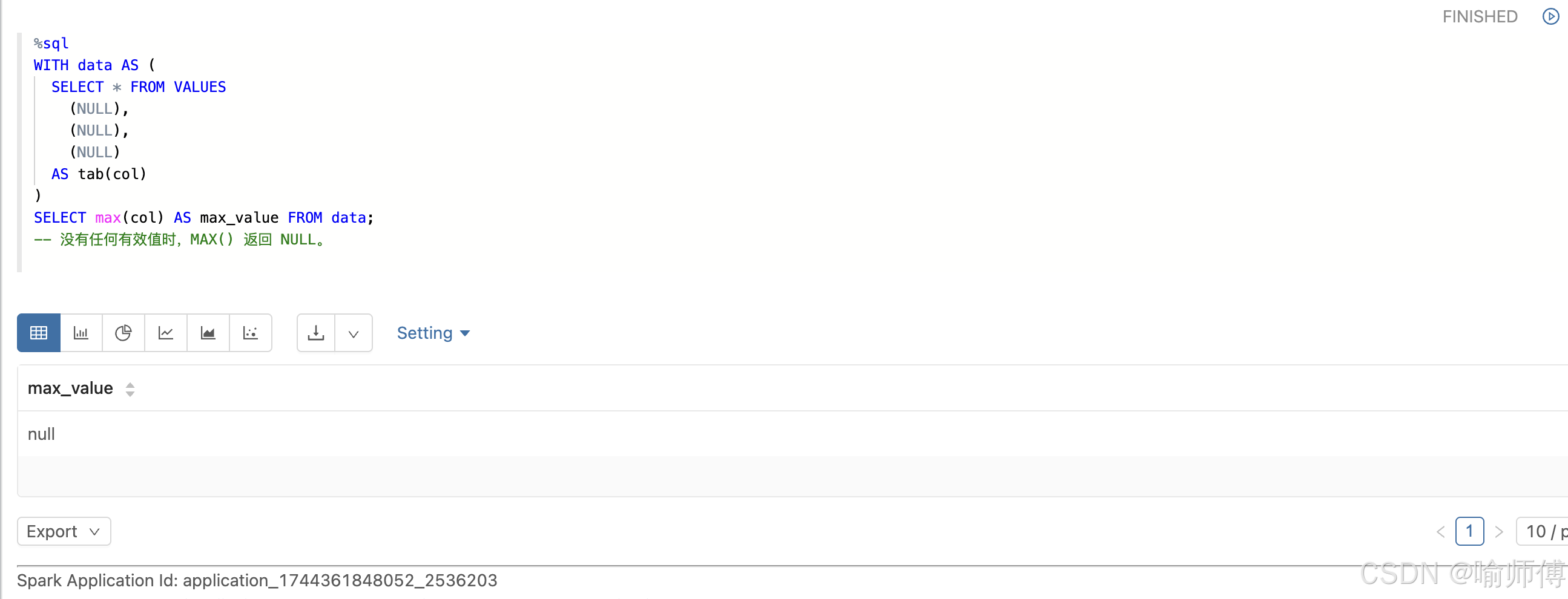
WITH data AS (SELECT * FROM VALUES(NULL),(NULL),(NULL)AS tab(col)
)
SELECT max(col) AS max_value FROM data;
-- 没有任何有效值时,MAX() 返回 NULL。
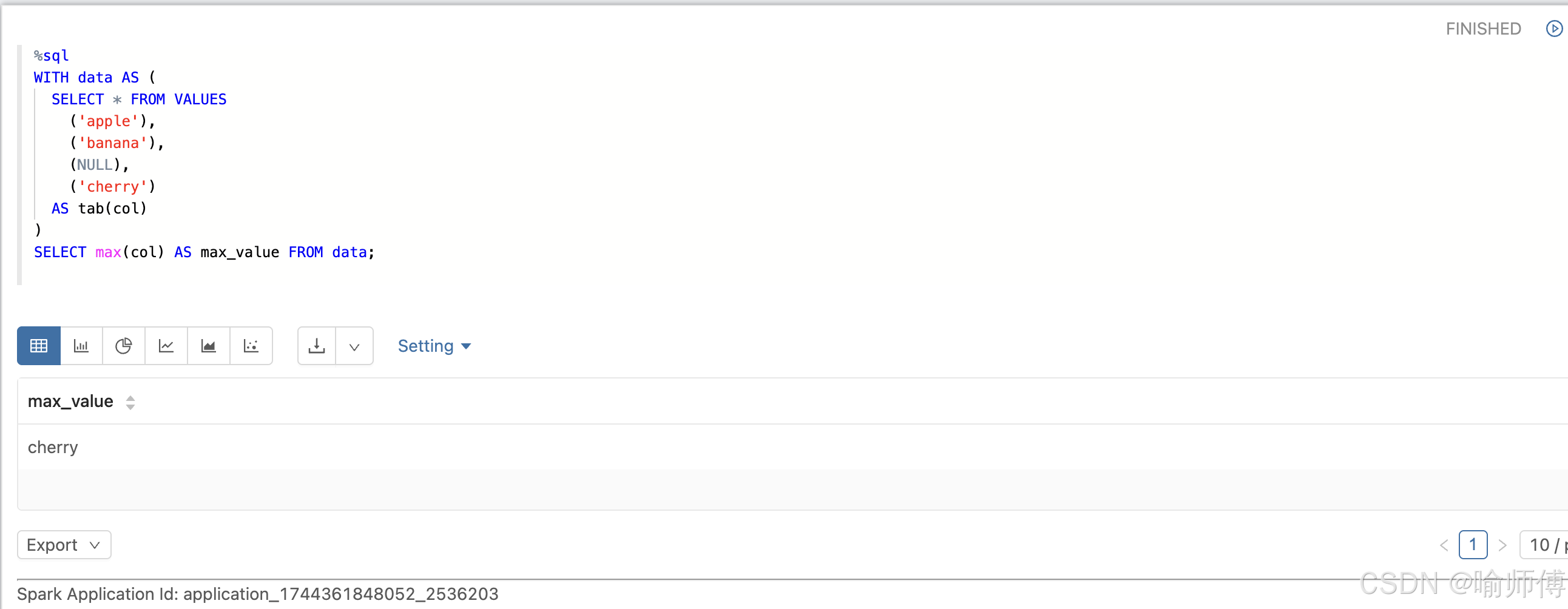
MAX() 也适用于字符串。
WITH data AS (SELECT * FROM VALUES('apple'),('banana'),(NULL),('cherry')AS tab(col)
)
SELECT max(col) AS max_value FROM data;
-- 字符串按照字典顺序排序,'cherry' 是最大的。
其它聚合函数:
| 函数 | 如何处理 NULL |
|---|---|
| MAX(col) | 忽略 NULL,找最大值;全为 NULL 返回 NULL |
| MIN(col) | 忽略 NULL,找最小值;全为 NULL 返回 NULL |
| SUM(col) | 忽略 NULL,加总非空值;全为 NULL 返回 NULL |
| AVG(col) | 忽略 NULL,计算平均值;全为 NULL 返回 NULL |
| COUNT(col) | 只统计非 NULL 数量 |
| COUNT(*) | 统计所有行数,包含 NULL |
Spark官方对于各种函数处理null值的说明:
https://spark.apache.org/docs/4.0.0/sql-ref-null-semantics.html