SQL基础⑥ | 聚合函数
0 序言
本文将系统讲解·SQL中的聚合函数·,包括其类型、用法,以及GROUP BY子句、HAVING子句的使用,还会阐述SELECT语句的执行过程。
通过学习,你将掌握如何用聚合函数汇总数据、按条件分组统计、筛选分组结果,并理解SQL查询的底层执行逻辑,提升数据查询与分析能力。
1 聚合函数介绍
1.1 聚合函数的定义
聚合函数是对一组数据进行汇总的函数,输入为一组数据的集合,输出为单个值。
例如,计算EMPLOYEES表中工资的最大值(MAX(SALARY))。
1.2 聚合函数的类型
常用聚合函数包括:AVG()、SUM()、MAX()、MIN()、COUNT()。
1.3 聚合函数的语法
SELECT [column,] group_function (column)
FROM table
[WHERE condition]
[GROUP BY column]
[ORDER BY column];
2 常用聚合函数详解
2.1 AVG()和SUM()函数
- 功能:AVG()用于计算一组数值型数据的
平均值,SUM()用于计算总和。 - 适用数据类型:仅适用于数值型数据。
- 示例:
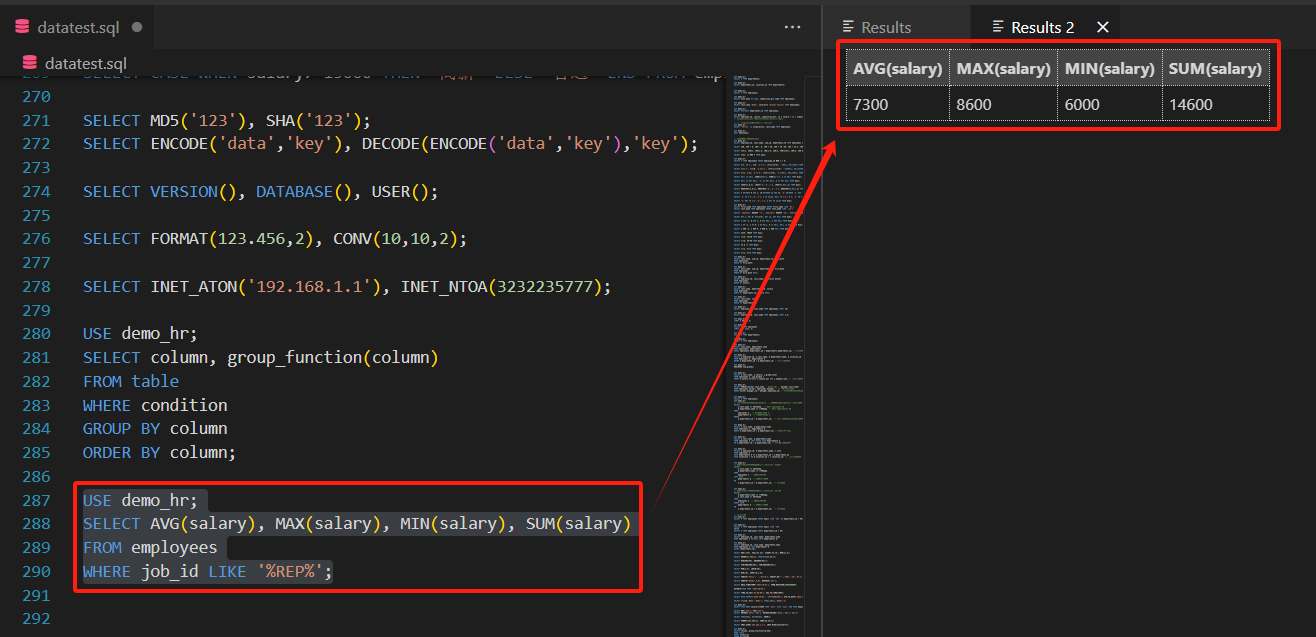
SELECT AVG(salary), MAX(salary), MIN(salary), SUM(salary)
FROM employees
WHERE job_id LIKE '%REP%';
结果会返回符合条件记录的工资平均值、最大值、最小值和总和。
2.2 MAX()和MIN()函数
- 功能:MAX()用于获取一组数据中的
最大值,MIN()用于获取最小值。 - 适用数据类型:适用于任意数据类型(如数值、日期等)。
- 示例:
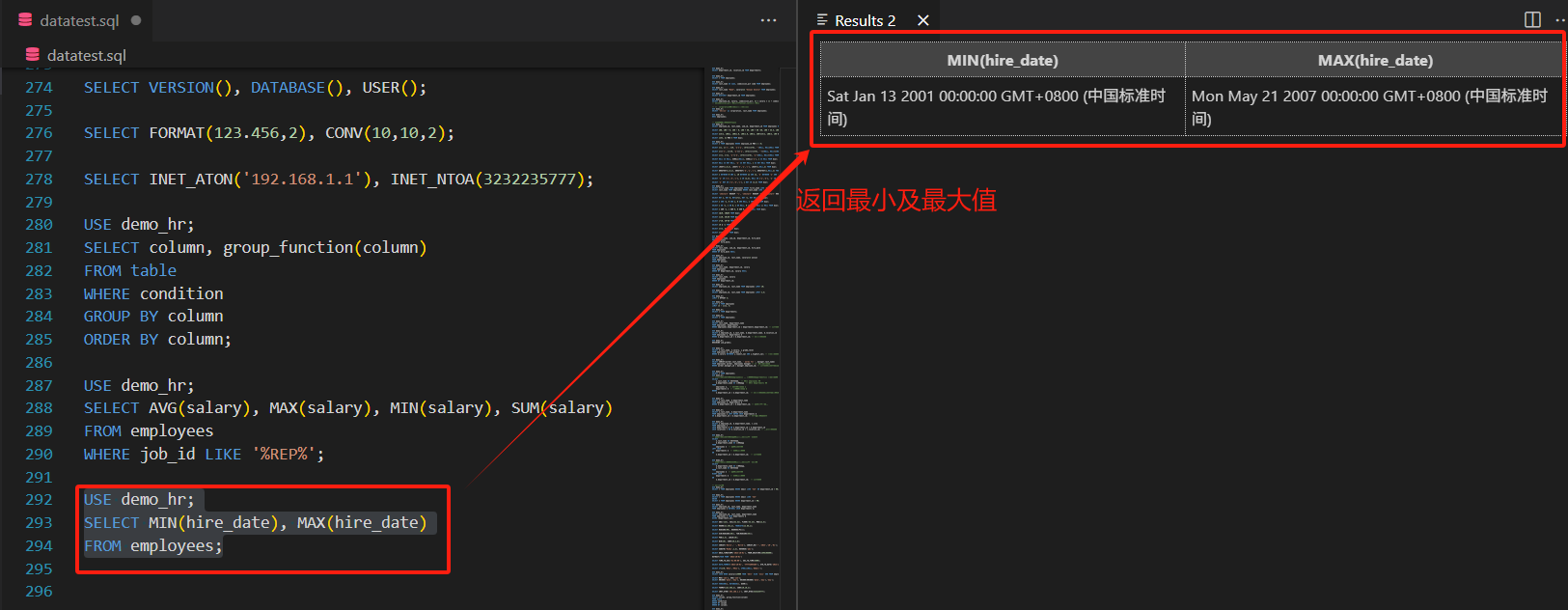
SELECT MIN(hire_date), MAX(hire_date)
FROM employees;
可查询员工表中最早和最晚的入职日期。
2.3 COUNT()函数
- 功能:统计数据记录的数量,有三种常用形式:
COUNT(*):返回表中所有记录的总数,适用于任意数据类型,包括值为NULL的行。COUNT(expr):返回表达式expr不为空的记录总数,不统计expr为NULL的行。COUNT(1):效果类似COUNT(*),统计所有记录数。
- 不同数据库引擎的差异:
MyISAM引擎:COUNT(*)、COUNT(1)、COUNT(列名)无区别,内部有计数器维护行数。InnoDB引擎:COUNT(*)、COUNT(1)直接读行数(复杂度O(n)),但优于COUNT(列名)。
- 注意事项:不要用COUNT(列名)替代COUNT(),COUNT()是SQL92标准的统计行数语法,与NULL无关,而COUNT(列名)不统计列值为NULL的行。
- 举个例子:
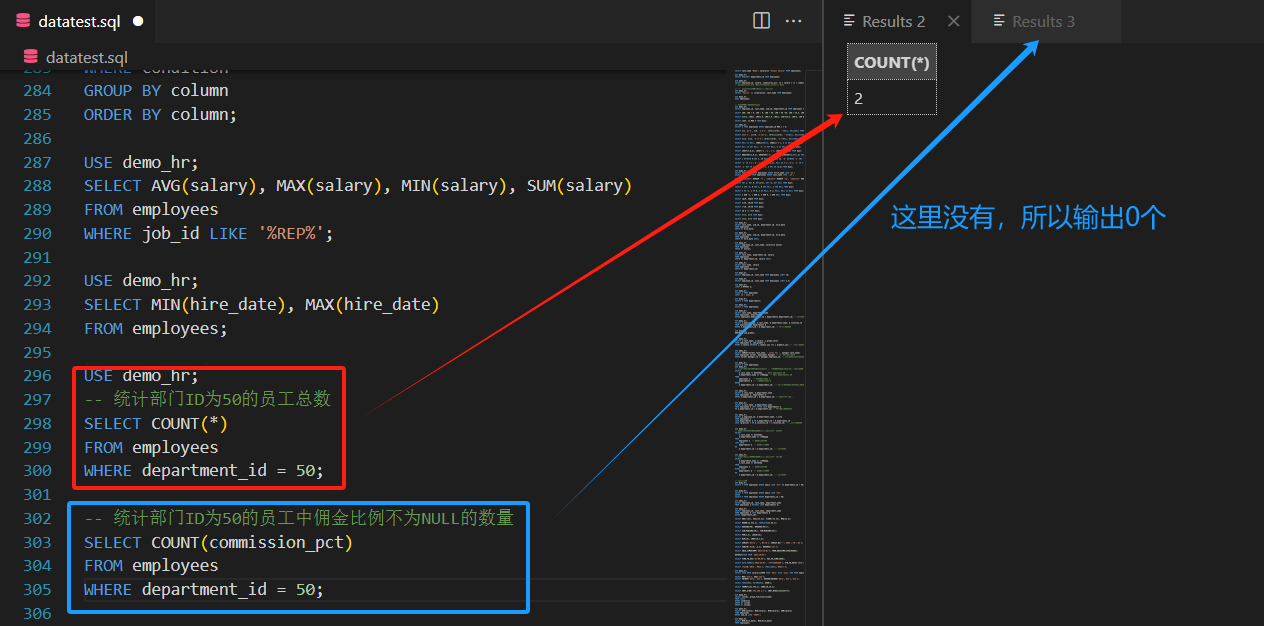
-- 统计部门ID为50的员工总数
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;-- 统计部门ID为50的员工中佣金比例不为NULL的数量
SELECT COUNT(commission_pct)
FROM employees
WHERE department_id = 50;
3 GROUP BY子句
3.1 基本使用
- 功能:将表中的数据
按指定列分成若干组,对每组数据应用聚合函数。 - 语法:
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
- 注意事项:
WHERE子句必须放在FROM之后!!!- SELECT列表中所有未包含在聚合函数中的列,都必须包含在GROUP BY子句中。
- 包含在GROUP BY子句中的列,可不在SELECT列表中。
- 示例:
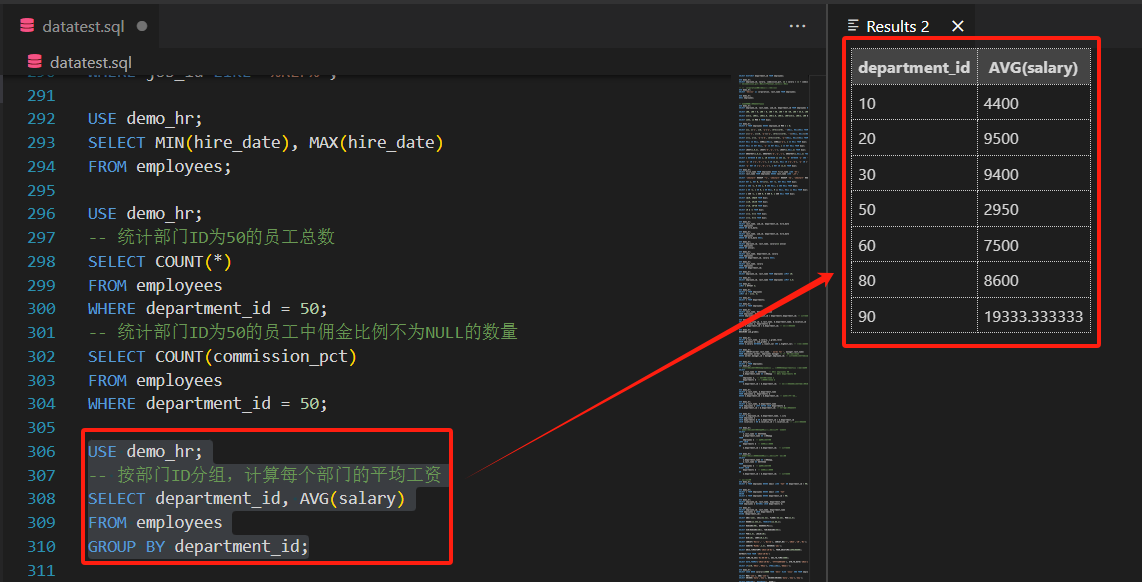
-- 按部门ID分组,计算每个部门的平均工资
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;
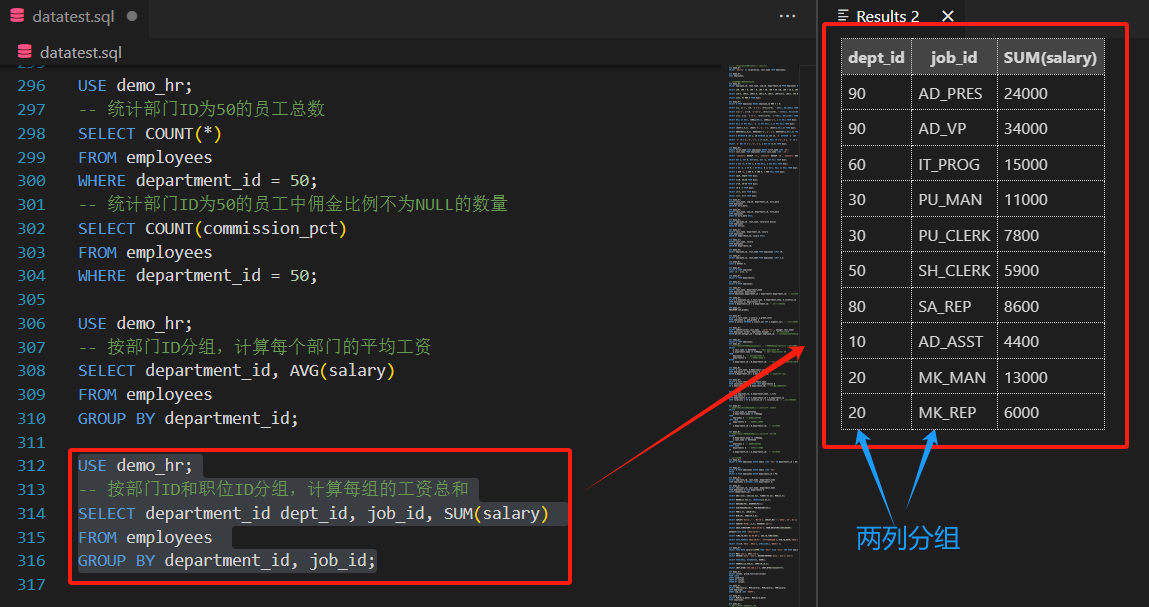
3.2 多列分组
- 功能:按多个列依次分组,
先按第一列分组,同一组内再按第二列分组,以此类推。 - 示例:
-- 按部门ID和职位ID分组,计算每组的工资总和
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id;
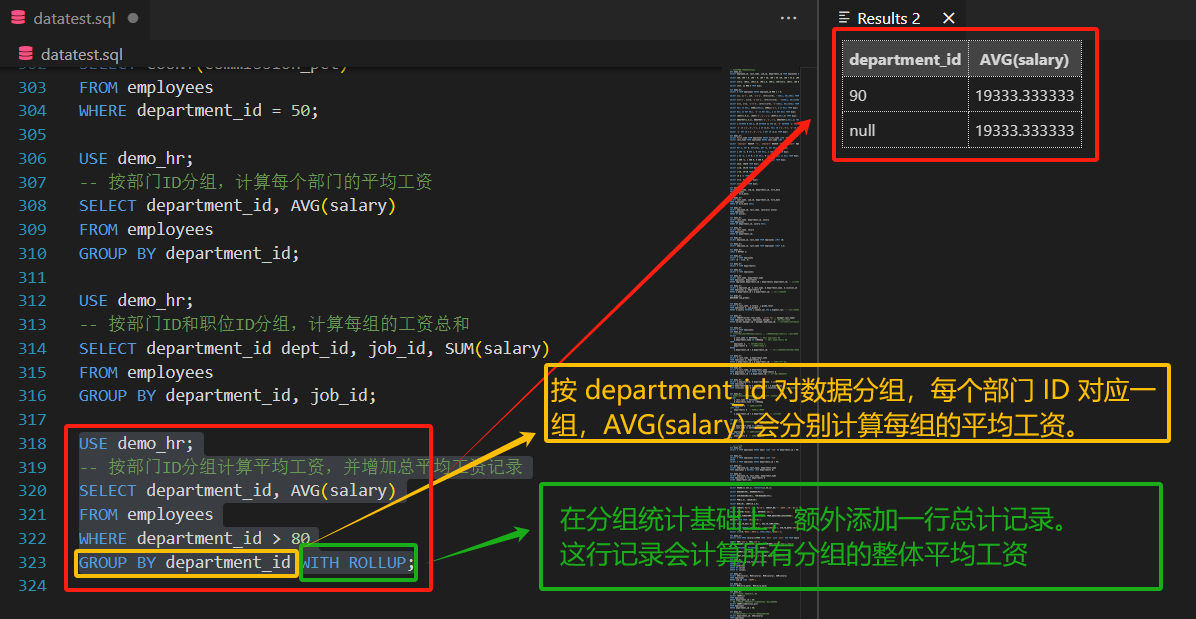
3.3 WITH ROLLUP
- 功能:在所有查询出的分组记录后增加一条记录,计算所有记录的总和(或总聚合结果)。
- 注意事项:使用ROLLUP时,
不能同时使用ORDER BY子句(两者互相排斥)。 - 示例:
-- 按部门ID分组计算平均工资,并增加总平均工资记录
SELECT department_id, AVG(salary)
FROM employees
WHERE department_id > 80
GROUP BY department_id WITH ROLLUP;
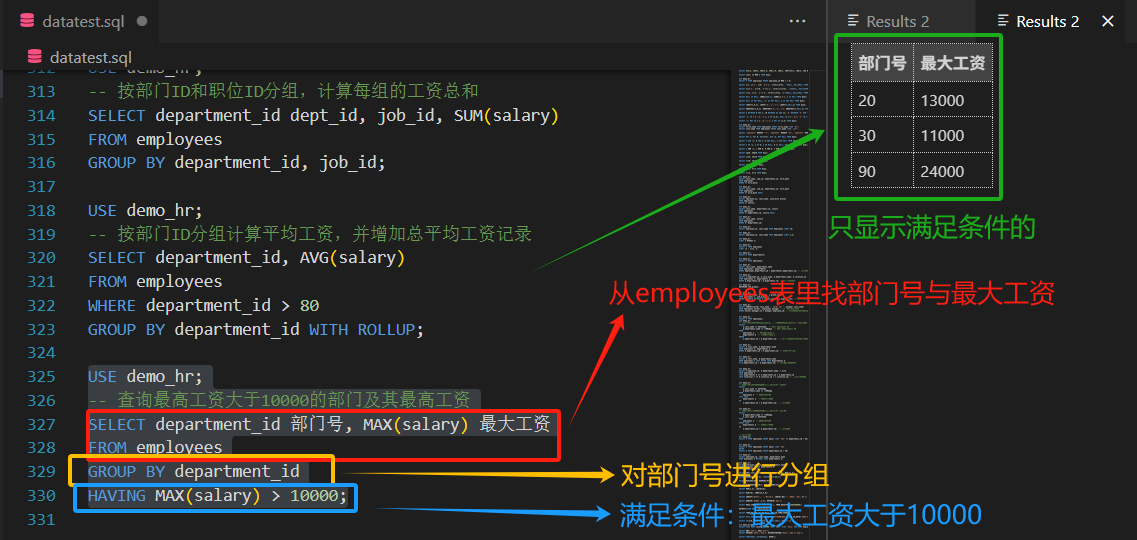
4 HAVING子句
4.1 基本使用
- 功能:过滤分组后的结果,
仅显示满足条件的分组。 - 特点:
- 必须与GROUP BY子句配合使用。
- 可使用聚合函数作为筛选条件。
- 示例:
-- 查询最高工资大于10000的部门及其最高工资
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary) > 10000;
- 错误示例:不能在WHERE子句中使用聚合函数,如下语句会报错:
SELECT department_id, AVG(salary)
FROM employees
WHERE AVG(salary) > 8000 -- 错误:WHERE中不允许使用聚合函数
GROUP BY department_id;
4.2 WHERE和HAVING的对比
| 对比维度 | WHERE | HAVING |
|---|---|---|
| 执行时机 | 在GROUP BY之前执行 | 在GROUP BY之后执行 |
| 筛选对象 | 原始数据行 | 分组后的结果 |
| 能否使用聚合函数 | 不能 | 能 |
| 执行效率 | 先筛选再关联/分组,效率高 | 先关联/分组再筛选,效率低 |
| 适用场景 | 筛选普通条件(非聚合结果) | 筛选基于聚合函数的条件 |
- 使用建议:可同时使用WHERE和HAVING,普通条件用WHERE(提高效率),聚合条件用HAVING(满足分组筛选需求)。
5 SELECT的执行过程
5.1 查询结构
SQL查询的完整结构(包含常用关键字)如下:
-- 方式1
SELECT ..., ...., ...
FROM ..., ..., ....
WHERE 多表的连接条件 AND 不包含组函数的过滤条件
GROUP BY ..., ...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ..., ...-- 方式2(多表连接)
SELECT ..., ...., ...
FROM ... JOIN ... ON 多表的连接条件
JOIN ... ON ...
WHERE 不包含组函数的过滤条件 AND/OR 不包含组函数的过滤条件
GROUP BY ..., ...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ..., ...
这个就是一般来说查询的方法,
或者你可以理解为基本的步骤吧。
了解清楚语法规则,然后找个数据库自己动手去体会感受一下,
很快就能够掌握了。
其实只需要掌握一种一般来说就已经够用,无非就是你如果想要语法简洁,那可以再多学一下。
5.2 执行顺序
- 关键字顺序(不可颠倒):SELECT … FROM … WHERE … GROUP BY … HAVING … ORDER BY … LIMIT…
- 执行步骤(MySQL和Oracle基本一致):
- FROM:指定查询的表,多表时计算笛卡尔积、筛选连接条件、添加外部行,得到原始数据虚拟表。
- WHERE:筛选原始数据行,得到过滤后的虚拟表。
- GROUP BY:按指定列分组,得到分组后的虚拟表。
- HAVING:筛选分组结果,得到符合条件的分组虚拟表。
- SELECT:提取需要的字段,得到字段筛选后的虚拟表。
- DISTINCT:去除重复行(若有),得到去重后的虚拟表。
- ORDER BY:按指定列排序,得到排序后的虚拟表。
- LIMIT:提取指定行记录,得到最终结果虚拟表。
一般步骤可以见下图:
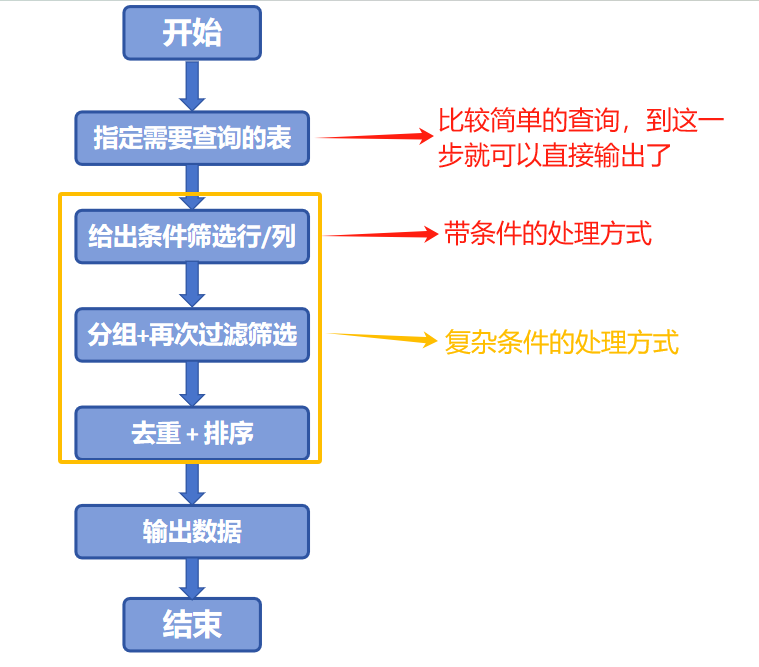
基本都是按照此步骤进行。
6 总结
本文介绍了SQL聚合函数的核心知识,包括AVG()、SUM()、MAX()、MIN()、COUNT()的功能与用法,重点讲解了COUNT()的不同形式及数据库引擎差异。
通过GROUP BY子句可实现数据分组统计,多列分组和WITH ROLLUP拓展了分组功能。
HAVING子句用于筛选分组结果,与WHERE的区别在于执行时机和适用场景。
通过本文这些知识,能更有效进行数据汇总、分组分析和结果筛选,提升SQL的查询能力。