有没有能读懂PDF里手写批注的工具?
当面对复杂版面的文档时。例如多栏布局、嵌套表格或含有手写批注的PDF文件时,读取就容易出现信息丢失或错误解析的情况。这时候就需要识别文档或图片中的文字信息,将文档解析为Markdown格式,并按常见的阅读顺序进行还原,赋能下游各类大语言模型任务。
然而手写内容或者手写批注往往是文档中常见的元素,可是市面上传统的OCR工具对于手写内容的识别解析都存在一定的偏差。而TextIn采用版面分析技术,并依托其自研的垂直领域的语义模型,能够有效读取文档中的手写内容,完成手写内容的结构化提取。
我们以TextIn合作博主华一说AI的体验为例,
博主上传了一份手写信,字迹很潦草,直接上传到 DeepSeek 看看能识别出来吗?


DeepSeek 识别不准,好多错误的地方,AI 都识别不准,那怎么可能有准确的回答。
我用TextIn试试看,结果真的震惊到我了!我这么潦草的手写字,竟然识别100% 准确。
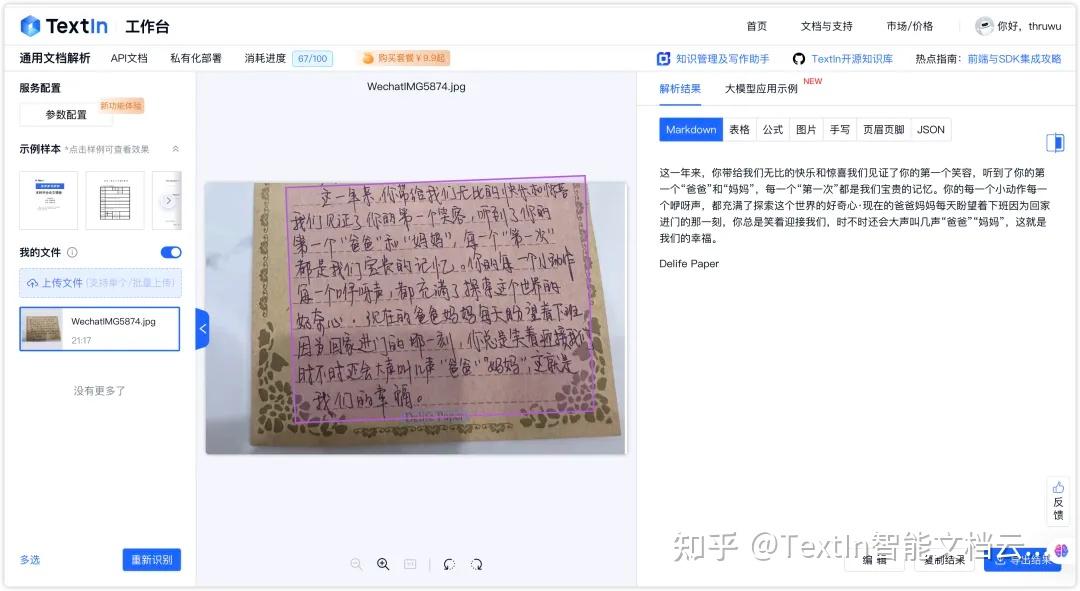
接下来,可以将 TextIn 解析的结果导出为 TXT 或 Markdown 文件,然后上传到 DeepSeek 进行识别,准确度非常高,后续对话效果也更好。
我也会直接把这些解析过的文件批量上传到 ima 知识库,然后用它的 DeepSeek 模型跟这个知识库对话,好用到飞起。
另外TextIn还有以下优势,助力文档处理更高效
兼容多源、多格式文档,覆盖类型全面
一个接口,即可支持PDF、Word(doc/docx)、常见图片(jpg/png/webp/tiff)、HTML 等多种文件格式,识别文档中的文字段落、表格、标题层级、公式、手写字符、图片信息等元素信息,将文档解析为Markdown格式,并按常见阅读顺序进行还原,统一输入与输出。
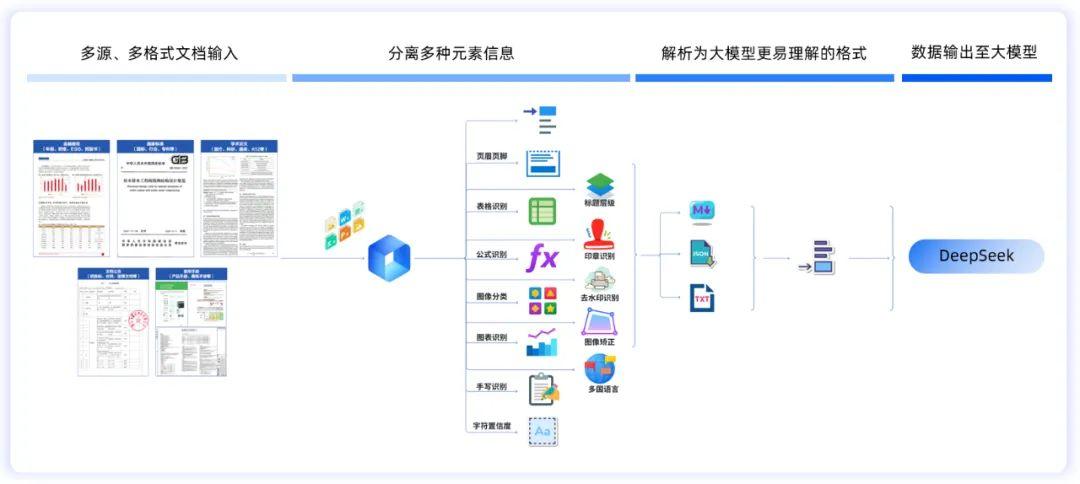
TextIn文档解析覆盖文档类型全面,支持金融报告、国家标准、论文、企业招投标文件、合同、文书、工程图纸、电子书、试卷等各类常见文档。

解析准确率高
文档解析主要面临以下难点:精准的表格识别、按语义的跨页表格/段落的合并、阅读顺序还原、多层级标题还原、公式还原、非正文元素的检测与去除、手写文字的识别与区分等
TextIn文档解析很好地解决了这些技术难点,尤其在复杂表格识别方面,无论是有线表、无线表、有线无线混合表、密集表格、带底色表格,还是合并单元格、跨页表格,都能精准解析。

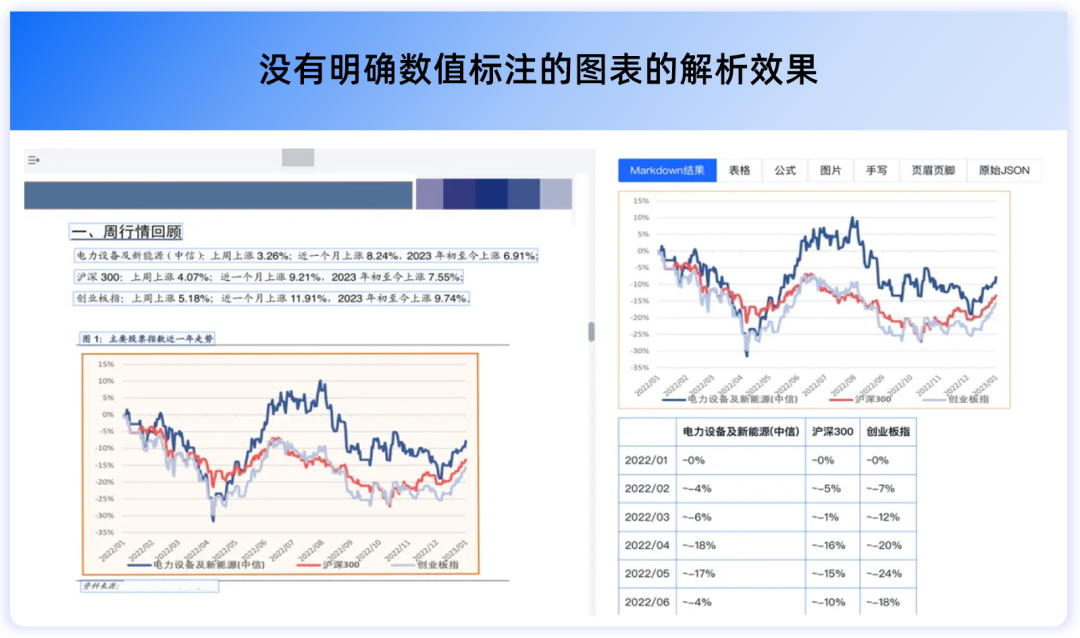
同时,TextIn文档解析近期上线的“图表解析”功能,更是进一步解决了金融研报、市场分析材料、学术论文等类型文档中,柱状图、折线图、散点图等各类图表承载大量信息,但却难以被大模型读懂的难点。
对于有数值标注的图表,TextIn文档解析可以直接输出准确表格,将其转化为结构化数据,方便后续的数据入库、分析或输入大模型进行处理。
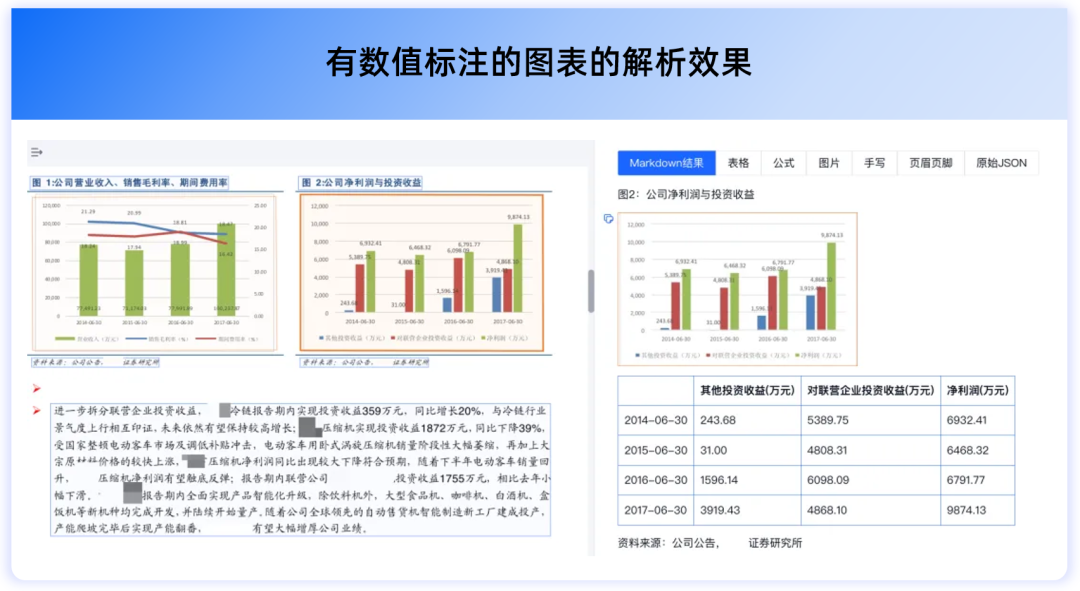
对于没有明确数值的复杂图表,TextIn接口也会通过精确测量给出预估数值,在仅有扫描件、图片文件的情况下,帮助挖掘更多有效数据信息,完成分析及预测工作。
解析速度快
100页长文档,TextIn文档解析在2秒内即可完成解析。以金融行业为例,数据时效性要求高、上市公司年报常常多达数百页,解析效率的提升至关重要。
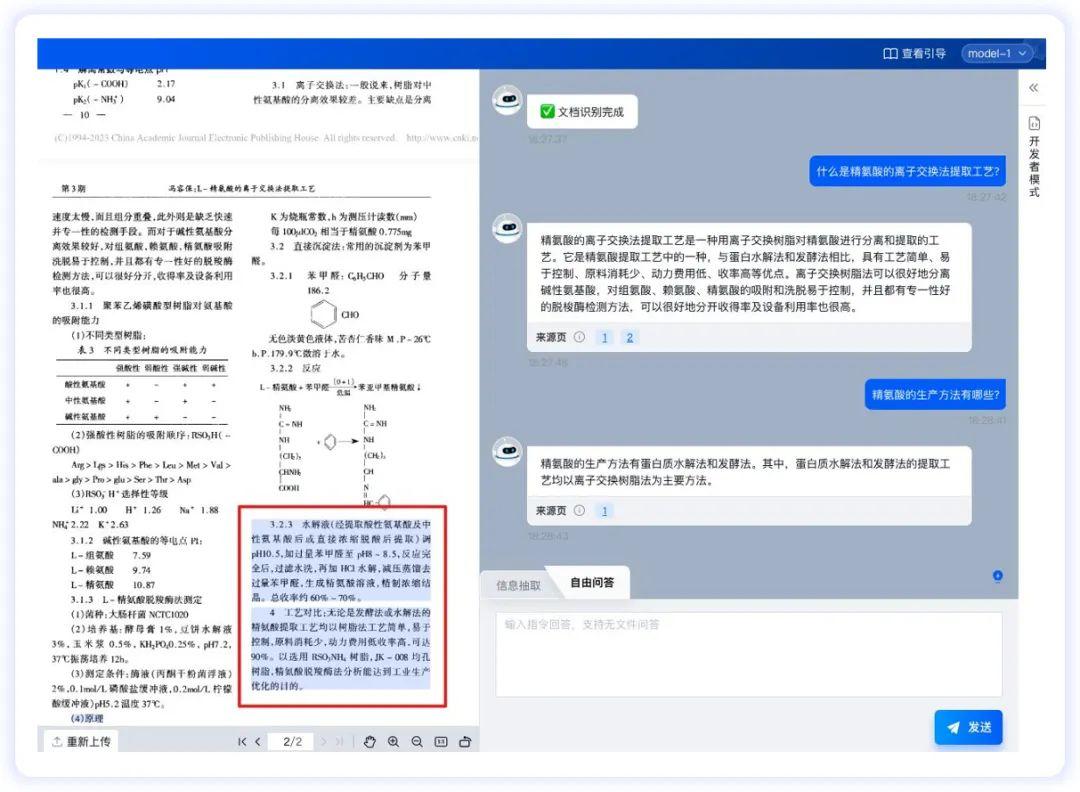
支持溯源定位
为了排查大模型幻觉干扰,企业在应用大模型赋能业务时,常需要复核大模型给出的答案是否符合输入数据。本方案提供溯源定位能力,可提示每条回答所参考的原文位置,便于快速复核。
多种部署方式
TextIn文档解析支持公有云API接口、私有化部署、混合云部署等多种灵活部署方式,满足企业不同需求。
客户案例
目前,该方案已在金融、教育、生物医药、供应链、大数据、传媒等多行业企业落地应用,有效提升了大模型在实际业务场景中的可用性。