(Arxiv-2025)利用 MetaQueries 实现模态间迁移
利用 MetaQueries 实现模态间迁移
paper title:Transfer between Modalities with MetaQueries
paper是Meta发布在Arxiv 2025的工作
Code:链接
Abstract
统一的多模态模型旨在整合理解(文本输出)与生成(像素输出)能力,但在单一架构中对齐这些不同模态通常需要复杂的训练策略与精细的数据平衡。我们提出 MetaQueries,这是一组可学习的查询向量,作为自回归多模态大语言模型(MLLM)与扩散模型之间的高效接口。MetaQueries 将 MLLM 的潜在表示连接至扩散解码器,从而利用 MLLM 的深层理解与推理能力,实现知识增强的图像生成。我们的方法简化了训练流程,仅依赖图文对数据与标准扩散目标函数即可完成训练。值得注意的是,即使在 MLLM 主干保持冻结的情况下,该迁移方式依然有效,从而在保持其最先进的多模态理解能力的同时,也获得了强大的生成性能。此外,我们的方法具有良好的灵活性,可轻松进行指令微调,适用于图像编辑、主体驱动生成等高级应用场景。
1 Introduction
统一多模态模型的目标是同时具备深层理解(通常输出文本)与高质量生成(输出像素)的能力,这一方向被广泛认为具有巨大潜力(OpenAI,2025;Google,2025)。这类系统能够实现理解与生成的协同增强,即理解促进生成,反之亦然。然而,如何在单一架构中有效连接这些不同的输出模态依旧是重大挑战——例如:我们该如何将自回归多模态大语言模型(MLLM)中潜藏的世界知识传递给图像生成器?尽管已有大量工作取得进展(Ge 等,2024;Sun 等,2024b;Tong 等,2024;Jin 等,2024;Liu 等,2024a;Team,2024a;Xie 等,2024;Wang 等,2024;Wu 等,2025a;Chen 等,2025;Dong 等,2024;Zhou 等,2025;Shi 等,2024),但大多数方法依赖精细调优 MLLM 主干以同时处理理解与生成任务。这通常需要复杂的架构设计、数据与损失平衡、多阶段训练流程等,一旦稍有偏差,优化生成能力就可能损害理解能力,反之亦然。
本文提出一种更简洁的路径:将“生成”交给扩散模型,将“理解”交给 LLM。换言之,我们不试图从零构建一个一体化的庞大系统,而是致力于在已经擅长不同模态任务的预训练模型之间建立高效的能力迁移机制。为此,我们保持 MLLM 冻结,让其专注于语义理解;同时将图像生成任务交由扩散模型负责。我们证明,即使在 MLLM 冻结的前提下,其内在的世界知识、强大的推理能力与上下文学习能力仍然可以成功迁移到图像生成任务中,前提是设计出合适的“架构桥梁”。
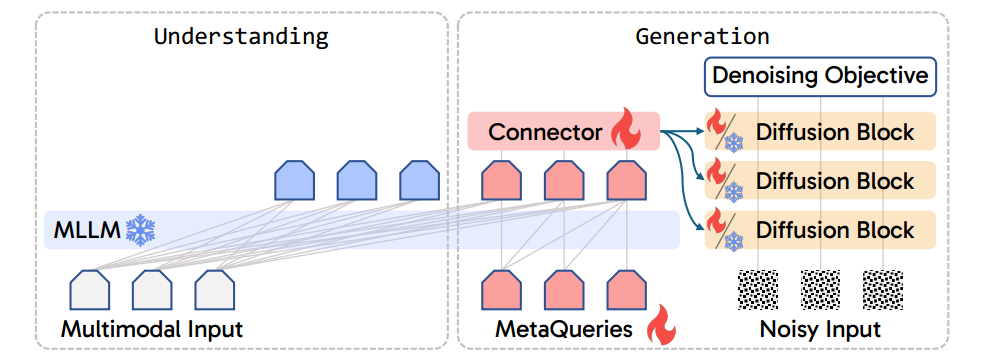
图1 我们模型的概览。蓝色 token 表示保持最先进的多模态理解能力;MetaQueries 是可学习的查询向量,直接作用于冻结的 MLLM,用于提取生成所需的条件信息。模型仅通过配对数据和去噪目标进行训练。扩散生成模型可以保持冻结状态,或进一步通过指令调优以支持高级生成任务。
然而,要让一个冻结的 MLLM 同时服务于多模态理解与生成并不简单。虽然已有研究将冻结的 LLM 用作文本到图像生成中的条件编码器(Zhuo 等,2024;Xie 等,2025;Ma 等,2024),但它们难以胜任一些核心任务,如上下文学习或多模态交错输出。在本研究中,我们设计的架构桥梁是 MetaQuery(见图1)。MetaQuery 将一组可学习查询直接输入冻结的 MLLM,从中提取可用于多模态生成的条件表示。我们的实验显示,即使不进行微调或启用双向注意力机制,冻结的 MLLM 也能作为强大的特征重采样器(Alayrac 等,2022),为多模态生成提供高质量条件信号。借助 MetaQueries,仅需少量图文对数据即可训练统一模型,将 MLLM 的输出连接至任意条件扩散模型。由于整个 MLLM 保持冻结,训练目标仍为标准的扩散去噪目标,训练过程高效且稳定。
与先前试图训练一个单一自回归 Transformer 主干来联合建模 p(text,pixels)p(\text{text}, \text{pixels})p(text,pixels) 的统一模型不同,我们采用 token → [transformer] → [diffusion] → pixels 的范式。该思路与 OpenAI 在 GPT-4o 图像生成系统中的哲学类似(OpenAI,2025)。此方法组合了 MLLM 的自回归先验与强大的扩散解码器,直接利用冻结 MLLM 对压缩语义表示的建模能力,避免了直接生成像素的高难度任务。
我们通过一系列对比实验验证了方法有效性,结果表明 MetaQuery 明显优于将冻结 MLLM 仅作条件文本编码器的做法,同时也能达到接近或超越调优版 MLLM 的性能,并具有更高的训练效率。我们还系统研究了训练策略,包括 token 数量与结构设计等。在仅使用 2500 万条公开图文对数据的前提下,我们成功训练出一系列统一模型,既保持了最先进的图像理解性能,也在多个文本生成图像基准上实现了 SOTA 水平的生成表现。
统一建模的愿景不仅在于并行处理多模态理解与图像生成,还应深入挖掘如推理、世界知识、多模态感知与上下文学习等高级能力,反哺生成过程。我们的实验结果表明,方法可利用冻结 MLLM 的常识性知识,在 CommonsenseT2I 基准(Fu 等,2024)上实现 SOTA 视觉常识生成表现。此外,我们还验证了方法可在 WISE(Niu 等,2025)上进行复杂世界知识推理,如响应“黄石国家公园所在国家的国旗”生成美国国旗(见图9示例)。
最后,通过 MetaQueries 将多模态输入连接、保留并增强至冻结的 MLLM 主干,我们的方法还能在无需微调 MLLM 的前提下实现指令调优,用于更复杂的生成任务,如主体驱动生成。我们展示该过程可以通过可扩展的数据收集流程高效完成,直接利用网络语料中自然形成的图像对,而无需人工标注或合成数据(Brooks 等,2023;Hu 等,2024a;Xiao 等,2025)。这种自然监督方式意外解锁了包括视觉联想与 logo 设计等全新能力(见图8示例)。
总结而言,我们提出了统一多模态建模的一个简洁却被低估的替代路径。我们的方法 MetaQuery 架起了冻结 MLLM 主干与扩散模型之间的桥梁。实验证明,该框架无需微调即可实现此前只有微调 MLLM 才能具备的全部能力,同时训练过程更加高效。主要成果包括:
- 通过 MetaQuery 和冻结的 MLLM 主干,我们实现了 SOTA 的多模态理解能力,并支持 SOTA 级别的图像生成能力;
- MetaQuery 可迁移 MLLM 的推理与知识能力,用于增强图像生成;
- MetaQuery 能从冻结的 MLLM 中提取远超语义相似性的细粒度视觉条件,用于图像重建与编辑;
- 该方法支持指令调优,哪怕在 MLLM 冻结的前提下,也能胜任如主体驱动生成等高级多模态生成任务。
2 Related Work
统一理解与生成模型。下一 token 预测已被证明是一种有效的语言理解训练方式(Devlin,2019;Brown 等,2020),也广泛应用于多模态内容理解(Liu 等,2024b)。近期,研究社区尝试将多模态理解的成功经验(Liu 等,2024b)进一步拓展至多模态生成任务,通过训练大语言模型(LLM)主干同时进行图像生成。然而,与仅使用文本 token 预测目标将文本 LLM 扩展至多模态理解任务不同(Touvron 等,2023;Liu 等,2024b),多模态生成需要一套完全不同的训练目标。SEED-X(Ge 等,2024)、Emu(Sun 等,2024b)和 MetaMorph(Tong 等,2024)通过回归图像特征实现生成;LaVIT(Jin 等,2024)、LWM(Liu 等,2024a)、Chameleon(Team,2024a)、Show-o(Xie 等,2024)、EMU3(Wang 等,2024)和 Janus(Wu 等,2025a;Chen 等,2025)则采用自回归方式预测下一个视觉 token;而 DreamLLM(Dong 等,2024)和 Transfusion(Zhou 等,2025)则使用扩散式训练目标。这些方法均需调优 LLM 主干以同时生成两种模态内容,因此在多任务训练中面临平衡性挑战。
冻结 LLM 的统一模型。一些研究探索了使用冻结 LLM 进行多模态理解与生成的方式。例如,LMFusion(Shi 等,2024)在冻结的 LLM 主干基础上,训练图像生成专用的前馈网络(FFNs)和 QKV 模块,以深度融合输入条件并对视觉输出进行去噪。但这种方式灵活性有限,需为每个 LLM 主干分别设计一套生成模块,不仅增加了计算负担,也限制了对已有强大生成模型的复用能力。早期工作 GILL(Koh 等,2023)研究了将可学习 token 输入冻结 MLLM 的策略。该方法结合对比损失与回归损失用于图像检索与生成,而不是直接采用去噪目标进行训练,因此效率较低。此外,其应用范围仅限于上下文图像生成任务,且未系统探索冻结 MLLM 与可学习查询之间的协同效果。
3 MetaQuery
在本研究中,我们提出 MetaQuery,一种在不损失理解能力的前提下,为仅具理解能力的 MLLM 增添多模态生成能力的方法,同时完全保留其原始架构设计与参数不变。我们系统分析了在图像生成任务中引入 MetaQuery 的效果。结果表明,即使在冻结状态下,MLLM 仍能够为多模态生成提供强有力的条件信息。
3.1 Architecture
MetaQuery 架起了冻结 MLLM 与扩散模型之间的桥梁。我们使用随机初始化的可学习查询 Q∈RN×DQ \in \mathbb{R}^{N \times D}Q∈RN×D 来从 MLLM 中查询出用于生成的条件 CCC,其中 NNN 是查询的数量,DDD 是查询的维度,与 MLLM 的隐藏维度一致。为了简化与兼容性,我们对整个序列继续使用因果掩码,而不是专门为 QQQ 启用完整注意力机制。生成的条件 CCC 被送入一个可训练的连接器中,以对齐文本到图像扩散模型的输入空间。只要目标扩散模型具有条件输入接口,就可以被采用;我们仅将其原有条件替换为 CCC。整个模型使用原始的生成目标在配对数据上进行训练。本文聚焦于图像生成任务,但该模型也可轻松扩展至音频、视频、3D 等其他模态。
3.2 Design Choices
该架构设计涉及两个关键选择:使用learnable queries(可学习查询)和保持MLLM backbone frozen(冻结多模态大语言模型主干)。我们解释了为什么做出这些选择,以及它们如何影响性能。在所有实验中,除非另有说明,我们使用相同的冻结MLLM主干:LLaVA-OneVision-0.5B(Li et al., 2024a),冻结的Sana-0.6B(Xie et al., 2025)扩散模型,分辨率为512,使用N=64N=64N=64个可学习查询,以及一个24层transformer编码器的连接器。所有模型都在2500万公开图文对上训练4个epoch。我们在MJHQ-30K(Li et al., 2024b)上报告FID分数(Heusel et al., 2017)用于评估视觉美学质量,使用GenEval(Ghosh et al., 2023)和DPG-Bench(Hu et al., 2024b)(均未重写prompt)用于评估prompt对齐准确性。
Learnable queries. 很多模型如Lumina-Next(Zhuo et al., 2024)、Sana(Xie et al., 2025)和Kosmos-G(Pan et al., 2024)使用(M)LLM最后一层的输入token嵌入作为图像生成的条件。然而,该方法对于统一建模并不理想,因为它与许多统一建模任务(如in-context learning或多模态交错输出)不兼容(我们在第5.6节中对MetaQuery进行了更详细讨论和比较)。如表1所示,使用N=64N=64N=64个learnable queries即可实现与使用最后一层嵌入相当的图像生成质量。虽然随机查询可获得可接受的FID分数,但在prompt对齐方面表现较差,突显了learnable queries的重要性。此外,由于最后一层嵌入的设置自然具有更长的序列长度,我们还测试了N=512N=512N=512的learnable queries,在性能上进一步提升,甚至超过了最后一层嵌入的方法。

表1 图像生成中不同条件的研究。∗表示输入token的嵌入。 可学习查询(learnable queries)在性能上与使用所有隐藏状态相当,并且在使用更多token的情况下甚至可以超越后者。

表2 MLLM 适配策略的研究。 不对 LLM 进行训练的方法不会导致多模态理解能力的下降。 冻结的 MLLM 在性能上可与完整调优的 MLLM 相媲美, 其提示词对齐略低,但视觉质量略有提升。
Frozen MLLM. 现有的统一模型通常训练MLLM以联合建模p(text,pixels)p(\text{text}, \text{pixels})p(text,pixels),这导致训练过程更复杂,并且还会降低理解性能。MetaQuery保留了MLLM原始的架构设计和参数设置,以保持SOTA理解能力。然而,对于多模态生成,一个关键问题是:MetaQuery在参数显著更少的情况下,其性能是否会远逊于完全微调MLLM的方法。如表2所示,冻结的MLLM在性能上与完全微调的MLLM相当,虽然prompt对齐略低,但视觉质量略有提升。对DiT的微调可进一步提升两种设置的性能。这表明MetaQuery是一种可行的训练策略,它更简单但也很有效,可作为全模型微调的替代方案。
3.3 Training Recipe
基于我们在设计选择中的见解,我们进一步研究 MetaQuery 的两个主要组成部分:可学习查询(learnable queries)和连接器(connectors)的关键训练选项。该研究考察了 token 数量和连接器设计。除非另有说明,本节中所有实验均采用第 3.2 节所述的设置。
Token 数量。许多工作(Wu et al., 2023;Pan et al., 2024;Ge et al., 2024)都使用可学习查询进行条件提取。然而,它们通常将 token 数量设置为图像解码器的固定输入序列长度(例如 Stable Diffusion v1.5(Rombach et al., 2021)中 CLIP 文本编码器的 N=77N=77N=77),或者使用 N=64N=64N=64 等任意固定值而不做进一步研究。考虑到现代扩散模型如 Lumina-Next(Zhuo et al., 2024)和 Sana(Xie et al., 2025)自然支持可变长度条件,因此确定可学习查询的最优 token 数量非常关键。
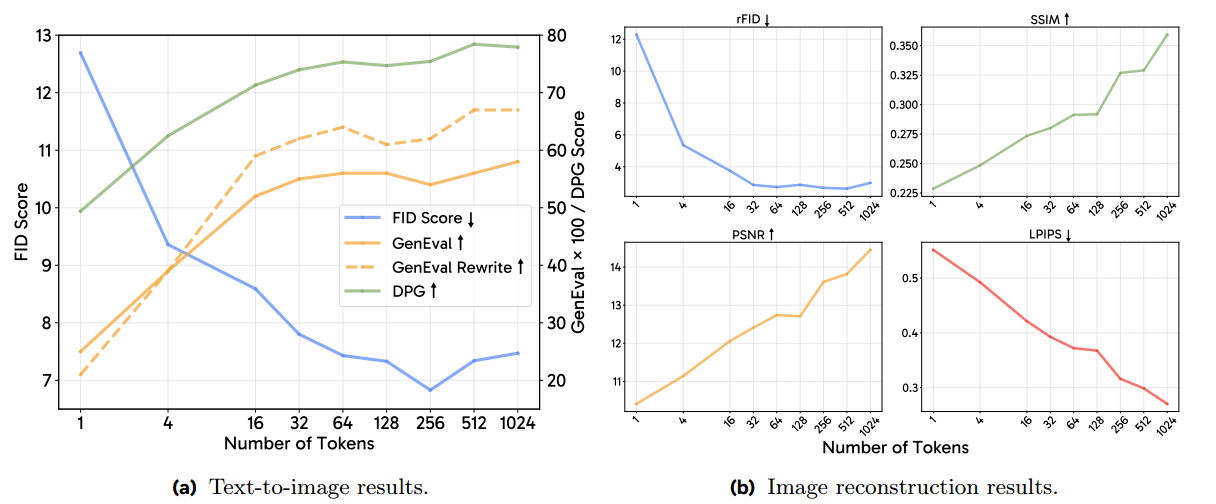
图2:Token 数量扩展性研究。随着 token 数量的增加,文本生成图像的 prompt 对齐效果和图像重建结果持续提升。

图3:不同数量的 token 下的图像重建可视化示例。
在图2中,我们对 token 数量进行了详细研究,并观察到 MetaQuery 在扩展性方面的潜力。对于文本生成图像任务,视觉质量在 646464 个 token 后趋于收敛,而更多的 token 能持续提升 prompt 对齐效果。特别是对于较长的文本描述,当使用重写后的提示进行 GenEval 评估时,随着 token 数量的增加,得分上升更为明显。对于图像重建任务,我们观察到 token 数量越多,重建图像的质量也越高(视觉样例见图3)。在后续实验中,我们将 token 数量统一设置为 N=256N=256N=256,该设置在性能与效率之间取得了良好平衡。
连接器设计。连接器是 MetaQuery 中另一个重要组件。我们采用了 Qwen2.5(Team, 2024b)LLM 的相同架构,但在连接器中启用了双向注意力机制。我们研究了两种不同设计:编码前投影(Proj-Enc)和编码后投影(Enc-Proj)。Proj-Enc 首先将条件投影到扩散解码器的输入维度,然后使用 transformer 编码器进行对齐。而 Enc-Proj 设计则先使用 transformer 编码器在 MLLM 的隐藏状态维度中对齐条件,然后再将其投影到扩散解码器的输入维度。如表3所示,Enc-Proj 的表现优于 Proj-Enc,且参数量更少。
表3:连接器设计研究。先在与 MLLM 隐状态相同维度上对条件进行对齐(Enc-Proj)在效果和参数效率上更优。
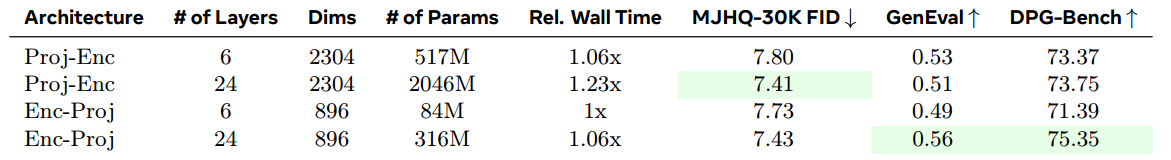
4 Model Training
我们将 MetaQuery 的训练分为两个阶段:预训练阶段和指令微调阶段。两个训练阶段都保持 MLLM 冻结,仅对可学习查询、连接器和扩散模型进行微调。我们采用三种不同规模的 MLLM 主干模型:Base(LLaVAOneVision 0.5B (Li et al, 2024a))、Large(Qwen2.5-VL 3B (Bai et al, 2025))和 X-Large(Qwen2.5-VL 7B (Bai et al, 2025))。所有模型的 token 数量统一设为 N=256N = 256N=256,连接器使用 Enc-Proj 架构并设置为 24 层。
图像生成头部分,我们测试了两种扩散模型:Stable Diffusion v1.5 (Rombach et al, 2021) 和 Sana-1.6B (Xie et al, 2025)。
预训练。我们在 2500 万对公开图文对上对模型进行预训练,训练 8 个 epoch,初始学习率为 1×10−41 \times 10^{-4}1×10−4,全局 batch size 为 4096。学习率采用余弦衰减策略,并设有 4000 步的 warmup,最终降至 1×10−51 \times 10^{-5}1×10−5。
指令微调。在本工作中,我们重新审视了图像生成中指令微调的数据构建过程。目前所有方法均依赖专家模型根据原始图像和指令生成目标图像(Ge et al, 2024;Xiao et al, 2025;Hu et al, 2024a)。但该方法存在扩展性限制,且可能引入偏差,因为专家模型仅涵盖有限的图像变换类型。
受 MagicLens (Zhang et al, 2024) 启发,我们使用自然存在的网页图像对进行指令微调数据构建。这些网页语料中的图像对包含丰富的多模态上下文,其文本和图像交错出现,主题相关。这些图像对经常体现出有意义的联系与具体关系,涵盖从直观视觉相似到更微妙语义关联的广泛范围(如图4所示)。这种自然分布的图像对为指令微调提供了优秀且多样的监督信号。
基于此观察,我们开发了一个数据构建流程,从网页语料中挖掘图像对并利用 MLLM 自动生成描述它们之间转化关系的开放式指令。具体步骤如下:
- 从 mmc4 (Zhu et al, 2023) fewer-faces 子集收集配有图文描述的图像组;
- 使用 SigLIP (Zhai et al, 2023) 对图像进行聚类,聚类依据为 caption 相似度(最多每组 6 张图像,阈值为 0.5);
- 在每组中选取与其他图像平均相似度最低的图像作为目标图,其余为源图;
- 最终获得共计 240 万对图像;
- 使用 Qwen2.5-VL 3B (Bai et al, 2025) 生成每对图像的转化指令,描述如何将源图转换为目标图(具体的 MLLM 提示见附录 A)。
我们在该 240 万指令数据上对 Base 规模模型进行了 3 个 epoch 的指令微调,采用与预训练相同的学习率策略,batch size 为 2048。

图4 指令微调数据构建流程概览。我们使用 SigLIP(Zhai et al, 2023)模型根据图像描述相似度对网页语料中的图像进行分组,
然后通过 MLLM 从这些图像对中构建用于指令微调的数据。