SparkSQL 聚合函数 COUNT 对 NULL 值的处理
SparkSQL 聚合函数 COUNT 对 NULL 值的处理
官网:https://spark.apache.org/docs/4.0.0/sql-ref-functions.html
https://spark.apache.org/docs/4.0.0/sql-ref-null-semantics.html#builtin-aggregate-expressions
| 表达式 | 是否统计 NULL | 说明 |
|---|---|---|
| COUNT(*) | ✅ 是 | 统计所有行数,不管有没有 NULL |
| COUNT(列名) | ❌ 否 | 只统计该列中 非 NULL 值的数量 |
| COUNT(DISTINCT 列名) | ❌ 否 | 忽略 NULL,并去重统计 |
| COUNT(1) | ✅ 是 | 等价于 COUNT(*) |
Demo:
%sql
WITH data AS (SELECT * FROM VALUES(1, 'A'),(2, NULL),(3, 'B'),(4, NULL),(5, 'A')AS tab(id, category)
)
SELECTcount(*) AS `count(*)`,count(category) AS `count(category)`,count(1) AS `count(1)`,count(DISTINCT category) AS `count(DISTINCT category)`
FROM data;
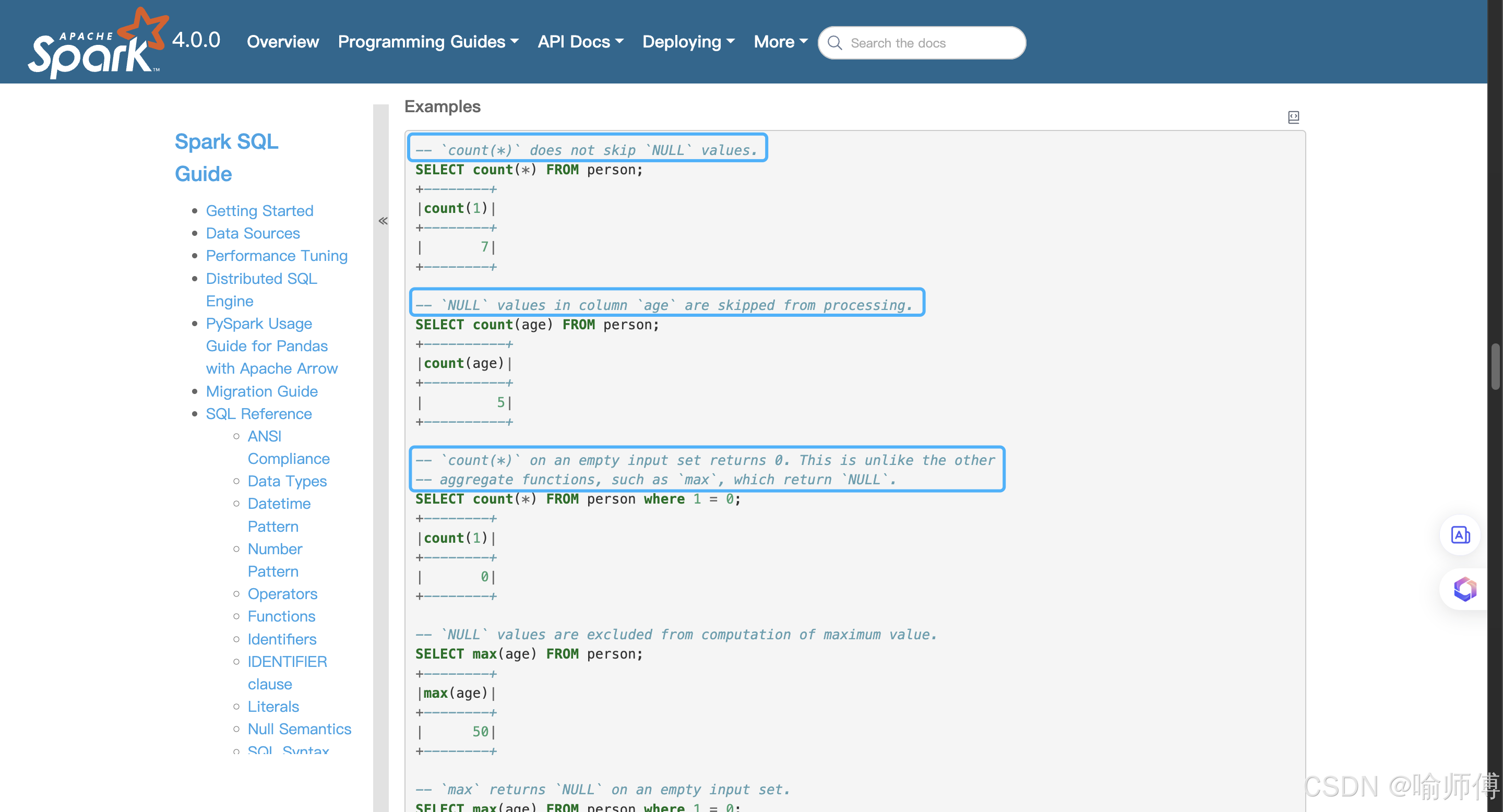
输出结果:
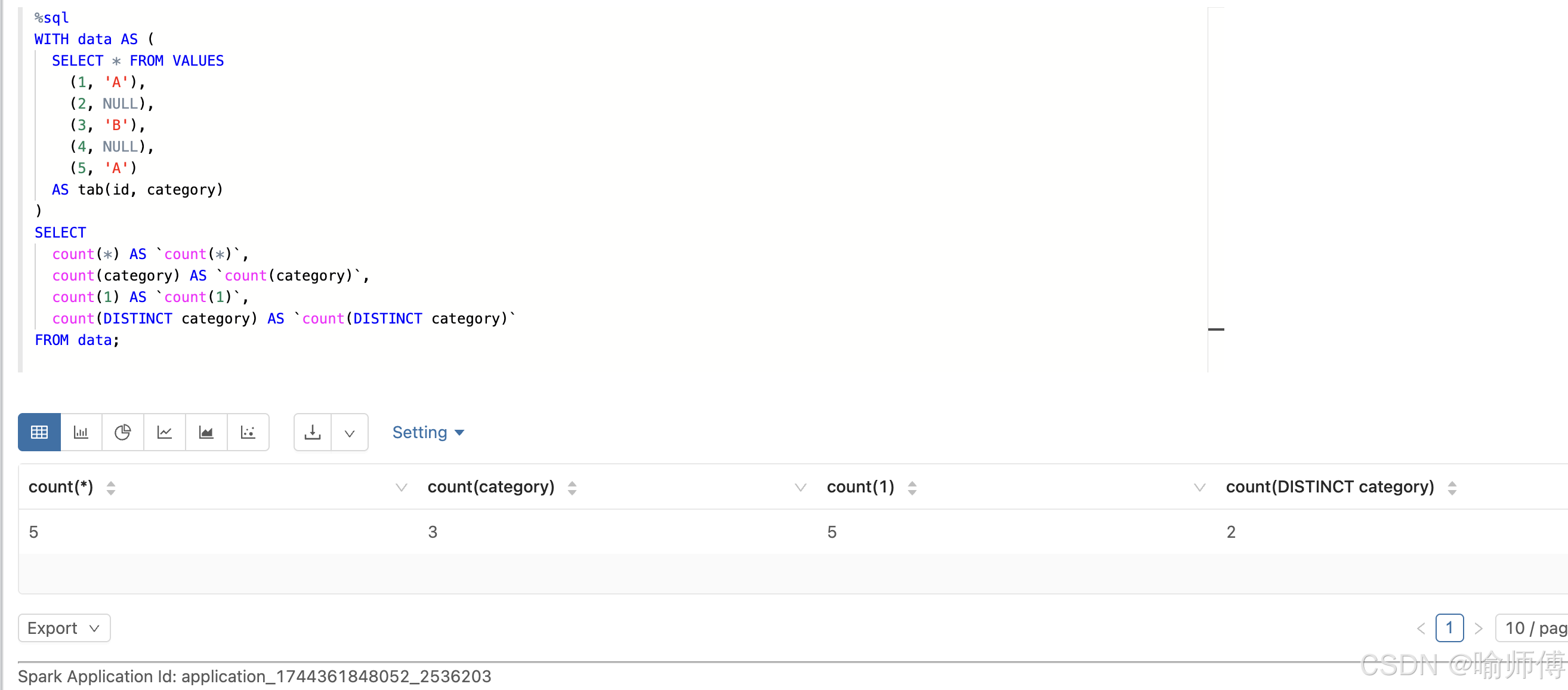
count(*) = 5:总共有 5 行,包含NULL。count(category) = 3:只有 3 个非NULL值(‘A’, ‘B’, ‘A’)。count(1) = 5:等价于count(*)。count(DISTINCT category) = 2:非NULL的唯一值是'A'和'B'。
-
统计总行数时,优先使用
COUNT(*) -
统计某列的有效值数量时,使用
COUNT(col)—— 可以知道有多少条记录是非空的。 -
COUNT(DISTINCT col)—— 它只统计非空且唯一的值,不是总数。
Spark官方对于各种函数处理null值的说明:
https://spark.apache.org/docs/4.0.0/sql-ref-null-semantics.html#builtin-aggregate-expressions