1-bit AI 基础设施:第 1.1 部分 —— 在 CPU 上实现快速且无损的 BitNet b1.58 推理
温馨提示:
本篇文章已同步至"AI专题精讲" 1-bit AI 基础设施:第 1.1 部分 —— 在 CPU 上实现快速且无损的 BitNet b1.58 推理
摘要
近期在 1-bit 大语言模型(LLMs)方面的进展,如 BitNet [WMD+23] 和 BitNet b1.58 [MWM+24],为提升 LLM 在速度与能耗方面的效率提供了一种极具前景的路径。这些进展也使得在各种设备上本地部署 LLM 成为可能。在本工作中,我们提出了 bitnet.cpp —— 一个专为释放 1-bit LLM 全部潜力而设计的软件栈。具体而言,我们开发了一组内核,用于在 CPU 上对三值化的 BitNet b1.58 LLM 实现快速且无损的推理。大量实验表明,bitnet.cpp 在不同规模的模型上均实现了显著的加速:在 x86 CPU 上加速范围为 2.37 倍至 6.17 倍,在 ARM CPU 上为 1.37 倍至 5.07 倍。代码可通过以下链接获取:aka.ms/bitnet。
1 bitnet.cpp
bitnet.cpp 是一个面向 1-bit 大语言模型(例如 BitNet b1.58 模型)的推理框架。它在确保无损推理的同时,优化了推理速度与能耗效率。本项目的初始版本支持在 CPU 上进行模型推理。
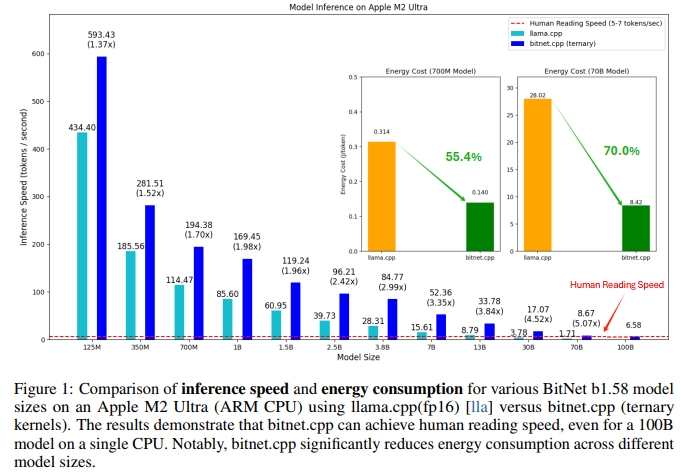
如图 1 所示,bitnet.cpp 在 ARM CPU 上实现了 1.37 倍至 5.07 倍的速度提升,且模型规模越大,性能收益越明显。此外,其能耗下降范围为 55.4% 到 70.0%,进一步提升了整体效率。在 x86 CPU 上,bitnet.cpp 实现了 2.37 倍至 6.17 倍的速度提升,同时能耗降低了 71.9% 至 82.2%。值得一提的是,bitnet.cpp 能够在 单个 CPU 上运行100B 参数规模的 BitNet b1.58 模型,并实现接近人类阅读速度(5–7 个 token 每秒)的推理速度 [Bry19],这大幅提升了在本地设备上运行大语言模型的可行性。
要开始使用 bitnet.cpp 进行模型推理,请按照以下步骤操作:
2 针对 1.58-bit 模型优化的计算内核
bitnet.cpp 提供了一整套为 1.58-bit 模型量身打造的优化计算内核,其中包括 I2_S、TL1 和 TL2 等。
这些内核专为在 x86 和 ARM 架构上进行 快速且无损的模型推理而设计,能够充分发挥 1.58-bit 模型在速度和能效方面的优势。
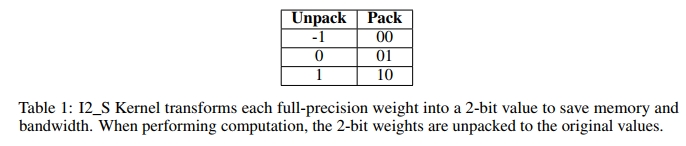
I2_S 内核采用了传统的“先乘后加”(multiply-then-addition)方式来执行矩阵乘法。如下表 1 所示,它在离线阶段将每个全精度权重转换为 2-bit 表示。在计算过程中,该内核会将权重恢复为原始值,并执行传统的 GEMV(通用矩阵-向量乘法) 操作。
建议在使用 I2_S 内核时配备足够数量的线程,因为这将允许编译器生成高效的流水线指令序列,进一步提升推理性能。
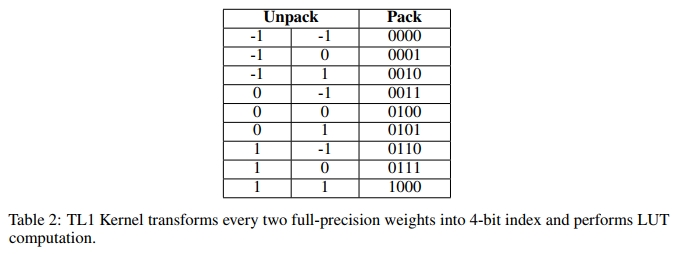
TL1 Kernel 通过将每两个全精度权重打包成一个 4-bit 索引(见表 2)进行预处理,并预先计算它们对应的激活值,共计 32=93^2 = 932=9 个值。这些索引-数值对被存储在一个查找表中,以执行查找表(LUT)计算 [PPK+22, WCC+24]。GEMV 操作通过 int16 类型的查找表执行,并通过加法完成累积。我们建议在服务大型模型时配合有限数量的线程使用该内核。
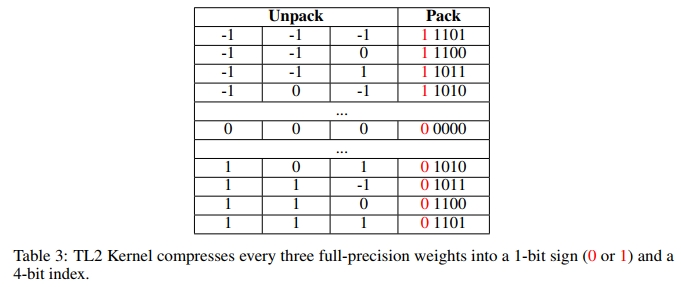
TL2 Kernel 与 TL1 类似。主要区别在于,TL2 每三个权重压缩为一个 5-bit 索引,而 TL1 是每两个权重压缩为一个 4-bit 索引。因此,TL2 相较于 TL1 实现了更高的压缩率。我们建议在内存或带宽受限的环境中使用该内核,因为它采用查找表(LUT)并相较于 TL1 Kernel 将模型大小减少了六分之一,从而降低了带宽需求。
3 评估
3.1 推理性能
我们从推理速度和能耗两个方面评估了 bitnet.cpp 的性能。测试涵盖了从 125M 到 100B 不同参数规模的模型,具体配置详见附录 A。这些规模代表了主流的大语言模型(LLM)配置。此外,我们还在 ARM 与 x86 架构上分别进行了系统性的测试。在 ARM 平台上,我们使用搭载 Apple M2 Ultra 处理器和 64GB 内存的 Mac Studio 进行端到端测试;在 x86 平台上,我们使用搭载 Intel Core i7-13700H(14 核心,20 线程)处理器和 64GB 内存的 Surface Laptop Studio 2 进行评估。
我们在每个设备上分别测试了两种场景:一种限制为两个线程进行推理,另一种则不限制线程数,并报告推理速度的最优结果。这种设计考虑了本地设备线程资源有限的情况,以更真实地评估 BitNet b1.58 在本地环境中的推理性能。
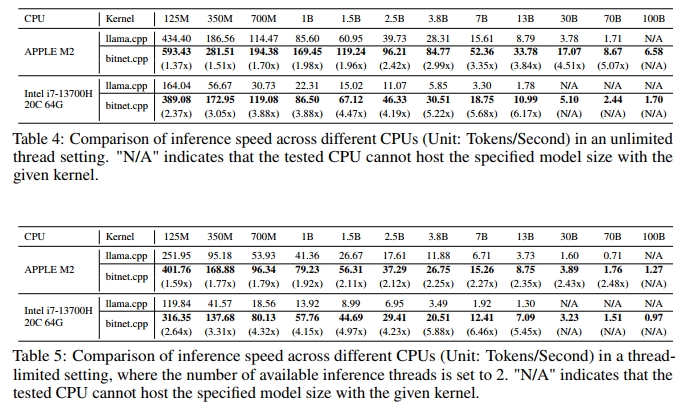
推理速度: 表 4 和表 5 展示了 bitnet.cpp 在 ARM(Apple M2)和 x86(Intel i7-13700H)架构上相较于 llama.cpp 的显著性能优势,尤其是在模型规模增大时表现更为突出。bitnet.cpp 在所有模型与架构下都稳定地超越 llama.cpp,速度提升范围为 1.37 倍至 6.46 倍不等。以 Apple M2 为例,在不限制线程的情况下,bitnet.cpp 的速度提升最高达 5.07 倍;而在 Intel i7-13700H 上,即便限制线程数,bitnet.cpp 仍可实现最高 6.46 倍的提速,尤其适用于资源受限环境下的本地推理。
随着模型规模的增长,bitnet.cpp 的性能优势进一步扩大,13B 及以上的大模型受益最为显著。在 Intel i7-13700H 上,bitnet.cpp 带来了显著的速度提升,使其在 x86 架构上同样具备极高适用性,即使在线程受限的情境下也能高效运行。虽然对于小模型(如 125M 至 1B)也存在可观的加速收益,但 bitnet.cpp 的优势在处理更大、更复杂模型时尤为关键,突显其在重负载任务中的高效性。
除了已观察到的性能差异外,带宽限制也显著影响了 bitnet.cpp 在不同架构下的效率表现,尤其是 Apple M2 与 Intel i7-13700H 之间的对比。由于 Apple M2 拥有更高的内存带宽,在运行大模型时,其搭配 bitnet.cpp 可获得显著更快的速度提升,进一步扩大了性能优势。
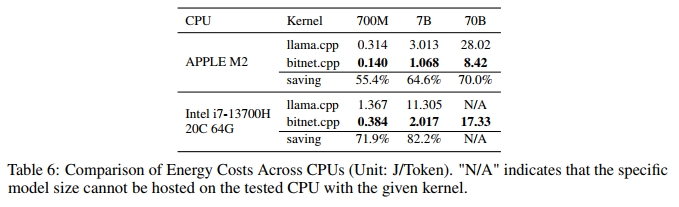
能耗表现:
我们对 700M、7B 和 70B 模型进行了测试,并在不限制线程数的设定下,以最佳推理速度为基础报告每个 token 的能耗(单位:焦/每 token,J/token)。表 6 清晰展示了 bitnet.cpp 在降低能耗方面的显著优势。
在 Apple M2 平台上,bitnet.cpp 根据模型规模的不同,能够将能耗降低 55.4% 至 70.0%。随着模型规模的增大,bitnet.cpp 的能效优势愈加明显,其中最大模型(70B)在能耗方面相较于 llama.cpp 实现了70.0% 的能耗下降。这一结果充分说明,bitnet.cpp 在速度与能耗双重维度上均可实现更高效的大规模推理部署,特别适合诸如移动设备或边缘计算这类对能耗敏感的应用环境。
在 Intel i7-13700H 平台上,bitnet.cpp 带来的能耗节省更为显著,对于最多到 7B 的模型,其能耗降低幅度达 71.9% 至 82.2%。尽管我们没有在 Intel CPU 上获得 70B 模型的能耗数据,但对较小模型的测试结果已经明确显示:bitnet.cpp 能够大幅降低多核高性能处理器上大语言模型推理的能耗需求。
3.2 推理准确性
bitnet.cpp 框架支持三值化 BitNet b1.58 大语言模型的无损推理。为了评估推理准确性,我们从 WildChat [ZRH+24] 中随机选取了 1000 条提示,对比了 bitnet.cpp 和 llama.cpp 生成的输出与 FP32 内核输出的一致性。评估采用逐 token 方式进行,单个模型输出最多比较 100 个 token,且仅当推理结果与全精度输出完全一致时,才被视为无损。
本次评估使用的是 700M 参数规模的 BitNet b1.58 模型。结果验证了 bitnet.cpp 在 1-bit 大语言模型推理中实现了准确且无损的性能。

4 未来工作
我们正在拓展 bitnet.cpp 的支持范围,以涵盖更多平台和设备,包括移动设备(如 iPhone 和 Android)、神经网络处理器(NPU)以及图形处理器(GPU)。未来,我们还计划开展针对 1-bit 大语言模型的训练优化工作。此外,我们也对为 1-bit LLM 共同设计定制化硬件和软件栈抱有浓厚兴趣。
论文名称:
1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
论文地址:
https://arxiv.org/pdf/2410.16144?