Custom SRP - Draw Calls
https://catlikecoding.com/unity/tutorials/custom-srp/draw-calls/
目标:
-
书写我们的 hlsl shader
-
支持 SRP batcher, Gpu Instancing, dynamic batching
-
配置每个对象的材质属性,并随机渲染大量物体
-
创建透明和镂空材质

1. Shaders
1.1 Unlit
我们的第一个例子是纯色,无光照的 shader。
通过 Assets/Create/Shader/UnlitShader ,在 Custom RP/Shaders/ 下创建 shader。我们要从头开始写我们的 shader,因此删除所有内容。
Shader "Custom RP/Unlit"
{Properties { }SubShader{Pass{}}
}-
Shader 定义,后面的字符串,是在编辑器材质编辑时,选择 shader 的下拉列表框的路径
-
Properties 块定义材质属性,这些属性可以在材质编辑器中编辑
-
SubShader 块,定义一个 Pass
-
Pass 定义一种渲染方式
-
上面代码块都是空的,Unity 会给一个默认实现,将其渲染成实心白色,并且默认渲染队列为 2000,是默认不透明集合体的渲染队列。同时还有双面渲染开关。
1.2 HLSL
Unity shader 用 HLSL 书写,在 Pass 中,HLSLPROGRAM and ENDHLSL 关键字之间。
Shader "Custom RP/Unlit"
{Properties { }SubShader{Pass{}}
}Shader 主要有2种
-
vertex 顶点变换,将顶点变换到设备空间。通过 #pragma vertex vertex_func_name 声明
-
fragment 渲染像素。通过 #pragma fragment fragment_func_name 声明
声明的 vertex/fragment 函数,可以直接写在 HLSLPROGRAM/ENDHLSL 之间,也可以写在其它的 .hlsl 文件中,并通过 #include “xxx.hlsl" 包含进来。
HLSLPROGRAM
#pragma vertex UnlitPassVertex
#pragma fragment UnlitPassFragment
#include "UnliePass.hlsl"
ENDHLSL下面简单实现我们的 shader:
#ifndef CUSTOM_UNLIT_PASS_INCLUDED
#define CUSTOM_UNLIT_PASS_INCLUDEDfloat4 UnlitPassVertex() : SV_POSITION
{return .0f;
}float4 UnlitPassFragment() : SV_TARGET
{return .0f;
}#endif-
hlsl 文件可能被个文件引用包含,为了保证多次包含,只引入一次代码,需要用到宏来确保
-
shader 入口函数的返回值,需要有“语义”来修饰,以告诉GPU这些值用来干什么,比如上面:
-
SV_POSITION 告诉 GPU 返回值是齐次空间的顶点位置。
-
SV_TARGET 告诉 GPU 将颜色合并到 render target。
-
1.3 Space Transformation
vertex shader 主要工作就是将顶点变换到正确的空间。因此 shader 需要输入一个位置参数,位置参数用 POSITION 语义修饰。
顶点变换需要一些矩阵,由CPU在渲染对象时传入。这些输入都是类似的,为了后面复用,我们把这些输入定义到一个单独的文件 ShaderLibrary/UnityInput.hlsl 中。
#ifndef UNITY_INPUT_INCLUDED
#define UNITY_INPUT_INCLUDEDfloat4x4 unity_ObjectToWorld;
float4x4 unity_MatrixVP;#endif我们需要一些变换函数,将顶点变换到对应的空间。这些函数也是通用的,因此放到 ShaderLibrary/Common.hlsl 中
#ifndef COMMON_INCLUDED
#define COMMON_INCLUDED#include "UnityInput.hlsl"float3 TransformObjectToWorld(float3 positionOS)
{return mul(unity_ObjectToWorld, float4(positionOS, 1.0f)).xyz;}float4 TransformWorldToHClip(float3 positionWS)
{return mul(unity_MatrixVP, float4(positionWS, 1.0f));
}#endifUnlit.hlsl 现在变成
#ifndef CUSTOM_UNLIT_PASS_INCLUDED
#define CUSTOM_UNLIT_PASS_INCLUDED#include "../ShaderLibrary/Common.hlsl"float4 UnlitPassVertex(float3 positionOS : POSITION) : SV_POSITION
{float3 positionWS = TransformObjectToWorld(positionOS);return TransformWorldToHClip(positionWS);
}float4 UnlitPassFragment() : SV_TARGET
{return .0f;
}#endif1.4 core library
我们定义的两个变换函数,实际上已经在 Core RP Library package 中定义了,同时还定义了很多很有用的必须函数或其它定义。安装这个 package。
在我们的 Common.hlsl 中包含 Packages/com.unity.render-pipelines.core/ShaderLibrary/SpaceTransforms.hlsl
SpaceTransforms.hlsl 中使用的是用宏定义的常量,所以我们定义这些宏。后面会讨论用宏的原因。
Packages/com.unity.render-pipelines.core/ShaderLibrary/Common.hlsl 中定义了一些类型,如 real4,根据不同平台,可能是 float4 或 half4。
我们的 shader 现在是这样的:
UnityInput.hlsl
#ifndef UNITY_INPUT_INCLUDED
#define UNITY_INPUT_INCLUDEDfloat4x4 unity_ObjectToWorld;
float4x4 unity_WorldToObject;
real4 unity_WorldTransformParams;float4x4 unity_MatrixVP;
float4x4 unity_MatrixV;
float4x4 unity_MatrixInvV;
float4x4 unity_prev_MatrixM;
float4x4 unity_prev_MatrixIM;
float4x4 glstate_matrix_projection;#endifCommon.hlsl
#ifndef COMMON_INCLUDED
#define COMMON_INCLUDED#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/Common.hlsl"#include "UnityInput.hlsl"#define UNITY_MATRIX_M unity_ObjectToWorld
#define UNITY_MATRIX_I_M unity_WorldToObject
#define UNITY_MATRIX_V unity_MatrixV
#define UNITY_MATRIX_I_V unity_MatrixInvV
#define UNITY_MATRIX_VP unity_MatrixVP
#define UNITY_PREV_MATRIX_M unity_prev_MatrixM
#define UNITY_PREV_MATRIX_I_M unity_prev_MatrixIM
#define UNITY_MATRIX_P glstate_matrix_projection#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/SpaceTransforms.hlsl"//float3 TransformObjectToWorld(float3 positionOS)
//{
// return mul(unity_ObjectToWorld, float4(positionOS, 1.0f)).xyz;//}//float4 TransformWorldToHClip(float3 positionWS)
//{
// return mul(unity_MatrixVP, float4(positionWS, 1.0f));
//}#endif1.5 Color
-
通过定义 shader 常量,来定义材质的颜色,像素着色时直接返回这个颜色
float _BaseColor;float4 UnlitPassFragment() : SV_TARGET
{return _BaseColor;
}常量前面的下划线,是告诉 shader,该常量将会被当作材质属性。
-
通过 .shader 的 Properties ,可以在材质面板上编辑这个属性
Properties { _BaseColor("Color", Color) = (1.0,1.0,1.0,1.0)}属性语法规则:常量的名字("在材质面板上显示的名字", 属性类型) = 默认值
1. Batching
每次绘制,都需要 CPU 和 GPU 之间的异步操作。如果CPU向GPU传递的数据太多,就会导致浪费时间在等待(传递完成)上。同时,CPU就没有时间处理其它任务了。这最终都会导致 FPS 降低。
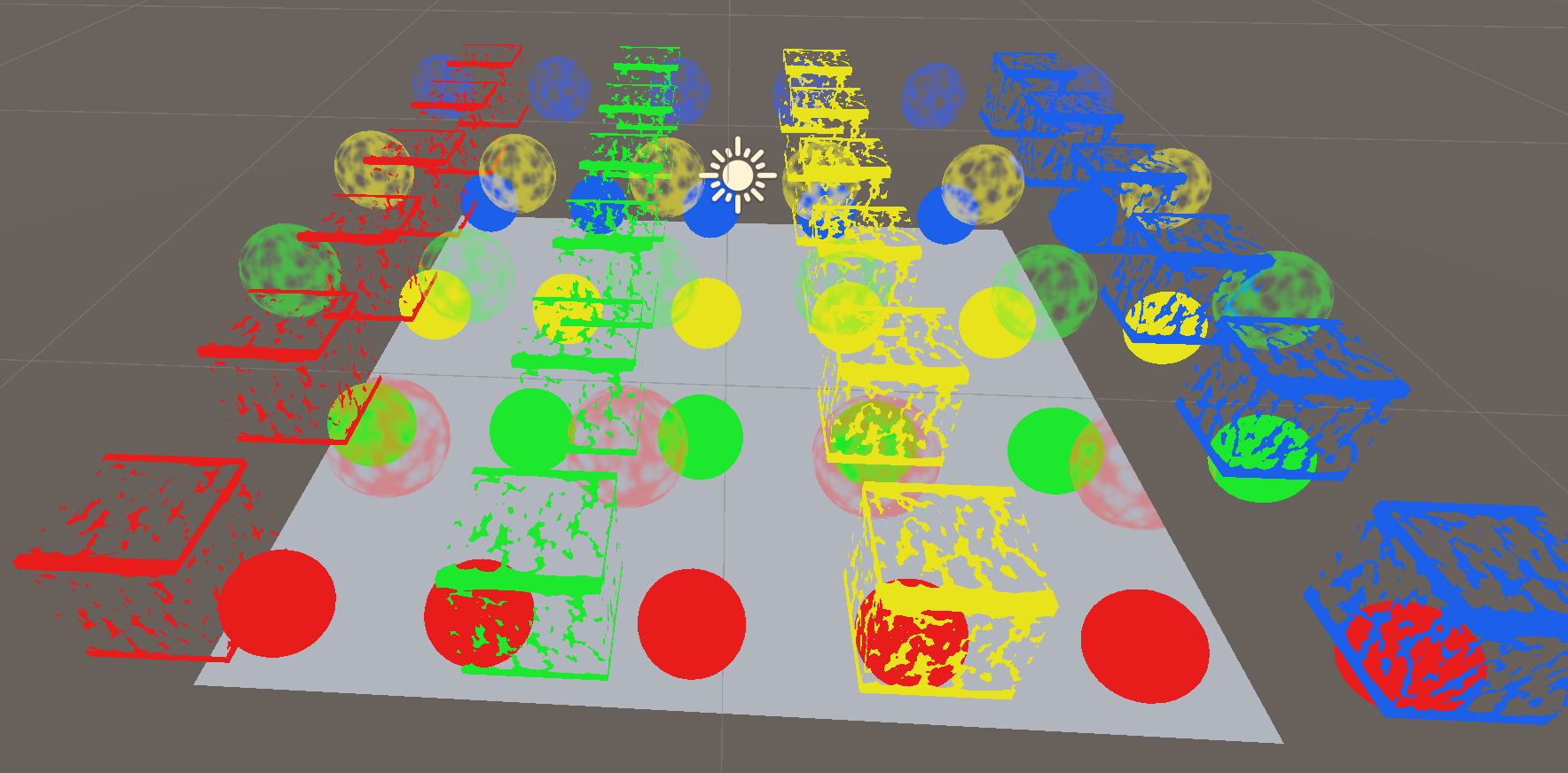
创建一个有80个小球的场景,分别用4个我们 shader 创建的材质:红,绿,黄,蓝色。这需要82次 draw call,80个是小球渲染,一个渲染天空盒,还有一个清理 render target。
2.1 SRP Batcher
Batching 是用来合并 draw call(按照这里的上下文,draw call 不是指 api 级别的 draw call,而是指的 unity 定义的 draw call:准备 material/object constant buffer,提交到GPU,绑定,draw),降低CPU/GPU同步的时间消耗的。
通过开启 SRP batcher 可以做到这一点,但是必须按照 SRP batcher 的要求来定义我们的 shader,否则会提示不兼容:

要兼容 SRP batcher,需要将我们的 constant buffer 定义成结构体,并且使用其命名规范:
-
UnityPerMaerial 每个材质的常量
-
UnityPerDraw 每个对象的常量
cbuffer UnityPerMaterial{float _BaseColor;
}这里有个问题:不是所有的硬件/API都支持 constant buffer,为了兼容这种情况,unity 提供了一组宏来定义 cbuffer:
CBUFFER_START(UnityPerMaterial)float4 _BaseColor;
CBUFFER_END对于我们的 shader,需要把对象绘制常量做类似的修改:
CBUFFER_START(UnityPerDraw)float4x4 unity_ObjectToWorld;float4x4 unity_WorldToObject;float4 unity_LODFade; // 后面有用,先写上real4 unity_WorldTransformParams;
CBUFFER_END如此改完后,我们的 shader 就是兼容 SRP batcher 的了。通过在Project面板中,选中我们的 Unlit.shader 可以看到。
但这还不够,还要在代码中开启 batching:
public CustomRenderPipeline(){GraphicsSettings.useScriptableRenderPipelineBatching = true;
}最后,在 FrameDebugger 中可以看到只有一个 SRP Batch:
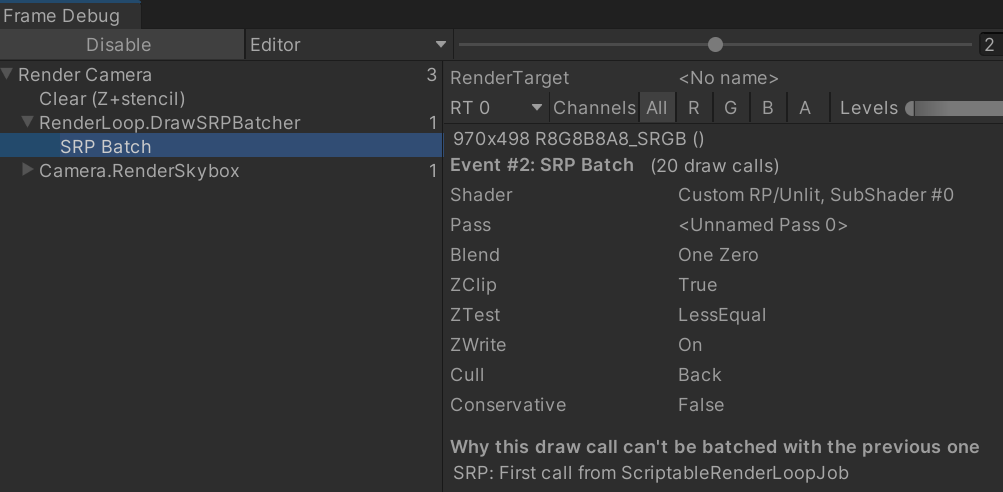
原理:
PerMaterial/PerDraw constant 的数据被整理到一个 GPU Buffer 上,然后提交到GPU,只要在这之后常量没有发生变化,就不需要更新/提交。唯一的限制是 constant buffer layout 必须要一致,也就是说它们是一个 shader 变体。
2.2 MaterialPropertyBlock
如果我们希望每个小球都有自己的颜色,那么我们需要为每个小球创建一个材质,这工作量很大,其实不需要这样,我们可以利用 MaterialPropertyBlock:
创建一个 PerObjectMaterialProperties 的脚本来定义每个小球的颜色,并在合适的时机,通过 MaterialPropertyBlock 进行应用。
[DisallowMultipleComponent]
public class PerObjectMaterialProperties : MonoBehaviour
{static int baseColorId = Shader.PropertyToID("_BaseColor");[SerializeField]private Color baseColor = Color.white;static MaterialPropertyBlock matPropBlock;private void Awake(){OnValidate();}private void OnValidate(){if (matPropBlock == null)matPropBlock = new MaterialPropertyBlock();matPropBlock.SetColor(baseColorId, baseColor);GetComponent<Renderer>().SetPropertyBlock(matPropBlock);}
}OnValidate 仅在编辑器,该脚本被加载,以及脚本属性被修改时调用。因此需要在 Awake 中主动调用。
不幸的是,应用了 MaterialPropertyBlock 之后,SRP batcher 将失效。
2.3 GPU Instancing
GPU Instancing 是管线将 mesh 相同,材质也相同的 draw call ,将对象的变换和材质属性收集起来,放到一个数组中提交给 GPU,通过一次 draw call,GPU 遍历每个对象的数据进行渲染。
启用 GPU Instancing,需要在 .shader 中,声明 vertex/fragment shader 前,声明 multi_compile_instancing:
#pragma multi_compile_instancing
#pragma vertex UnlitPassVertex
#pragma fragment UnlitPassFragmenthlsl 中,instancing 相关的定义是在 UnityInstancing.hlsl 中的,因此需要在我们的 Common.hlsl 中,在 SpaceTransforms.hlsl 之前将其包含进来:
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/UnityInstancing.hlsl"
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/SpaceTransforms.hlsl"UnityInstancing.hlsl 主要是定义了 instancing 相关的一些宏:
-
UNITY_VERTEX_INPUT_INSTANCE_ID 为 vertex/fragment input 声明 instance id
-
UNITY_SETUP_INSTANCE_ID 准备,使 instance id 有效
-
UNITY_TRANSFER_INSTANCE_ID 将 instance id 传递到下个结构体
-
UNITY_ACCESS_INSTANCED_PROP 根据UNITY_SETUP_INSTANCE_ID 准备好的 instance id,访问当前 instance 的属性。
-
UNITY_INSTANCING_BUFFER_START/UNITY_INSTANCING_BUFFER_END
-
UNITY_DEFINE_INSTANCED_PROP
首先,将 BaseColor 声明到 instancing buffer 中:
UNITY_INSTANCING_BUFFER_START(UnityPerMaterial)float4 _BaseColor;
UNITY_INSTANCING_BUFFER_END(UnityPerMaterial)将顶点输入数据,定义成结构体,并声明 instance id 输入:
struct Attributes{float3 positionOS : POSITION;UNITY_VERTEX_INPUT_INSTANCE_ID
};顶点返回,传递给 fragment 的值,也定义到结构体中,并声明 instance id 输入:
struct Varyings{float4 positionCS : SV_POSITION;UNITY_VERTEX_INPUT_INSTANCE_ID
};修改 vertex shader:
Varying UnlitPassVertex(Attributes input){Varyings output;UNITY_SETUP_INSTANCE_ID(input);UNITY_TRANSFER_INSTANCE_ID(input, output);float3 positionWS = TransformObjectToWorld(input.positionOS);output.positionCS = TransformWorldToHClip(positionWS);return output;
}最后修改 fragment shader:
float4 UnlitPassFragment(Varyings input) : SV_TARGET{UNITY_SETUP_INSTANCE_ID(input);return UNITY_ACCESS_INSTANCE_PROP(UnityPerMaterial, _BaseColor);
}最后,要看到效果,记得先把 SRP batching 关掉。
2.4 Graphics.DrawMeshInstanced
GPU Instancing 在绘制成百的对象时有巨大的提升,但是在场景中编辑这么多对象不太现实。在某些情况下,可能需要通过一种程序化的方式,创建,渲染大量对象。
下面的例子,随机生成了1023个球,并且将它们是变换,颜色,分别收集起来,通过 MaterialPropertyBlock 应用这些球的颜色,最后通过 Graphics.DrawMeshInstanced 进行渲染:
public class MeshBall : MonoBehaviour
{[SerializeField]Mesh mesh = default;[SerializeField]Material material = default;static int colorID = Shader.PropertyToID("_BaseColor");MaterialPropertyBlock matPropBlock = new MaterialPropertyBlock();Matrix4x4[] matrices = new Matrix4x4[1023];Vector4[] baseColors = new Vector4[1023];private void Awake(){for (int i = 0; i < matrices.Length; i++){matrices[i] = Matrix4x4.TRS(Random.insideUnitSphere * 10f, Quaternion.identity, Vector3.one);baseColors[i] =new Vector4(Random.value, Random.value, Random.value, 1f);}matPropBlock.SetVectorArray(colorID, baseColors);}void Update(){Graphics.DrawMeshInstanced(mesh, 0, material, matrices, 1023, matPropBlock);}
}这些小球以创建的顺序渲染,而且无法被裁剪,因为我们直接调用了 Graphics 的接口。

2.5 Dynamic Batching
对于那些使用同一个材质,且面数很低的模型,可以将这些对象的 mesh 合并成一个 mesh,一次 draw call 完成渲染。
通过配置 DrawingSettings 启用该功能:
var drawingSettings = new DrawingSettings(unlitShaderTagId, sortingSettings){enableDynamicBatching = true,enableInstancing = false};同时禁用 SRP batcher:
GraphicsSettings.useScriptableRenderPipelineBatching = false;还有 static batching,原理同 dynamic batching,却别是离线进行合并。
2.6 Configuring Batching
我们希望在我们的RP中,将这些 batching 策略,作为选项进行配置。
首先 DrawVisibleGeometry 支持这些开关:
void DrawVisibleGeometry(bool useDynamicBatching, bool useGPUInstancing)
{// 渲染不透明物体var sortingSettings = new SortingSettings(camera){ criteria = SortingCriteria.CommonOpaque };var drawingSettings = new DrawingSettings(unlitShaderTagId, sortingSettings){ enableDynamicBatching = useDynamicBatching, enableInstancing = useGPUInstancing};...
}然后在 pipeline asset 声明对应的属性,以便用户编辑,创建管线实例时将参数传递进去,就可以了:
[CreateAssetMenu(menuName = "Rendering/Custom Render Pipeline")]
public class CustomRenderPipelineAsset : RenderPipelineAsset
{[SerializeField] bool useDynamicBatching = false;[SerializeField] bool useGPUInstancing = false;protected override RenderPipeline CreatePipeline(){return new CustomRenderPipeline(useDynamicBatching, useGPUInstancing);}
}3. 透明

可以改变材质的 Render Queue 为 Transparent 使材质在透明阶段渲染,但是仅仅这样还没有效果,还需要让 shader 支持混合。
3.1 Blend Mode
首先要在 Pass 定义中声明混合:
Pass {Blend [_SrcBlend] [_DstBlend]HLSLPROGRAM…ENDHLSL}其次,定义材质属性。这里利用unity定义的枚举定义属性:
[Enum(UnityEngine.Rendering.BlendMode)] _SrcBlend ("Src Blend", Float) = 1
[Enum(UnityEngine.Rendering.BlendMode)] _DstBlend ("Dst Blend", Float) = 0然后在材质编辑面板中,就可以看到并编辑混合模式了:
![]()
Src 指的是当前像素着色器计算的颜色
Dst 指的是当前 render target 上的颜色。
开启混合时,Src Blend 和Dst Blend 分别指定为 SrcAlpha 和 OneMinusSrcAlpha,指示混合公式为 SrcColor.rgb * SrcColor.a + DstColor.rgb * (1-SrcColor.a)。
可以看到效果(下面的不透明的,上面的半透明的):

注意:
-
记得要把材质中的颜色的 alpha 值,改为128(0.5)
-
对于GPU Instancing,由于透明物体是排序渲染的,因此合批是否成功依赖于距离摄像机的距离,所以根据视角的不同,合批结果也会不同。
3.2 Not Writting Depth
半透明渲染不需要写深度,因此我们需要给材质一个开关,当配置为半透明渲染时,禁止写深度。
[Enum(UnityEngine.Rendering.BlendMode)] _DstBlend ("Dst Blend", Float) = 0
[Enum(Off, 0, On, 1)] _ZWrite ("Z Write", Float) = 1
...
Blend [_SrcBlend] [_DstBlend]
ZWrite [_ZWrite]然后在材质编辑面板关闭

3.3 Texturing
该节介绍如何采样贴图,并使用贴图中的alpha的值作为透明度。
-
首先在材质属性中定义贴图属性:
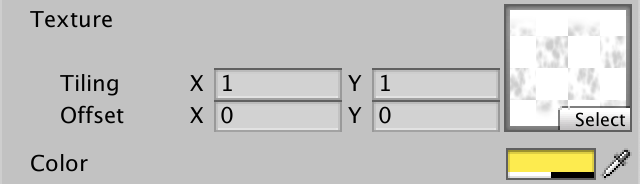
_BaseMap("Texture", 2D) = "white" {}
贴图名为"Texture",类型是 2D,默认是Unity 系统提供的 "white" 白色贴图。后面的 {} 是历史遗留特性,没用,但是不能没有,避免出现奇怪的错误。修改后,材质属性面板显示为:
-
然后修改hlsl:
-
声明全局贴图及其采样器变量。采样器变量名是在贴图变量名前加sampler
TEXTURE2D(_BaseMap); SAMPLER(sampler_BaseMap);UNITY_INSTANCING_BUFFER_START(UnityPerMaterial)UNITY_DEFINE_INSTANCED_PROP(float4, _BaseColor) UNITY_INSTANCING_BUFFER_END(UnityPerMaterial) -
采样贴图,需要顶点提供贴图坐标
struct Attributes {float3 positionOS : POSITION;float2 baseUV : TEXCOORD0;UNITY_VERTEX_INPUT_INSTANCE_ID }; -
在材质中,可以配置贴图坐标的缩放和偏移
UNITY_INSTANCING_BUFFER_START(UnityPerMaterial)UNITY_DEFINE_INSTANCED_PROP(float4, _BaseMap_ST)UNITY_DEFINE_INSTANCED_PROP(float4, _BaseColor) UNITY_INSTANCING_BUFFER_END(UnityPerMaterial) -
材质坐标在顶点着色器中应用缩放和偏移后,交给光栅化器进行插值
struct Varyings {float4 positionCS : SV_POSITION;float2 baseUV : VAR_BASE_UV;UNITY_VERTEX_INPUT_INSTANCE_ID };Varyings UnlitPassVertex (Attributes input) {…float4 baseST = UNITY_ACCESS_INSTANCED_PROP(UnityPerMaterial, _BaseMap_ST);output.baseUV = input.baseUV * baseST.xy + baseST.zw;return output; }
-
-
最后在片段着色器中完成采样
float4 UnlitPassFragment (Varyings input) : SV_TARGET {UNITY_SETUP_INSTANCE_ID(input);float4 baseMap = SAMPLE_TEXTURE2D(_BaseMap, sampler_BaseMap, input.baseUV);float4 baseColor = UNITY_ACCESS_INSTANCED_PROP(UnityPerMaterial, _BaseColor);return baseMap * baseColor; }
效果如下图

3.4 Alpha Clipping
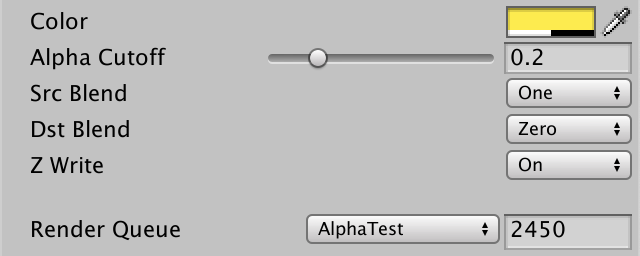
定义一个阈值,在像素着色时,对于那些 alpha 值小于这个阈值的像素,直接丢弃,最终渲染出”镂空“的效果。
-
首先在材质属性中定义阈值 _Cutoff:
_Cutoff("Alpha Cutoff", Range(0.0,1.0) = 0.5
-
_Cutoff 是材质参数,因此定义到 UnityPerMaterial 中:
UNITY_DEFINE_INSTANCED_PROP(float4, _BaseColor) UNITY_DEFINE_INSTANCED_PROP(float, _Cutoff)
-
在像素着色器中,比较 a 的值,如果小于 _Cutoff ,则 clip:
float4 base = baseColor * baseMap; clip(base.a - UNITY_ACCESS_INSTANCED_PROP(UnityPerMaterial, _Cutoff);
编辑材质,设置一个 _Cutoff 参数。
同时clipping渲染是在 AlphaTest 队列中渲染的,该队列在不透明物体渲染完后渲染。
3.5 Shader Features
一个材质,半透明和 alpha test,不能同时存在,因此需要一个开关。同时需要让 hlsl 根据开关执行不同的逻辑。
Shader Features 可以实现该特性。
-
首先在材质属性中添加一个 Feature Toggle 开关,名字为“Alpha Clipping",定义了一个宏关键字:_CLIPPING
[Toggle(_CLIPPING)] _Clipping("Alpha Clipping", Float) = 0
-
在 .shader 中声明 shader feature:
#pragma shader_feature _CLIPPING
-
在 hlsl 中,用宏将 clip 的代码包起来:
#if defined(_CLIPPING) clip(base.a - UNITY_ACCESS_INSTANCED_PROP(UnityPerMaterial, _Cutoff); #endif
最后,看看效果: