浅谈——游戏中的各种配置格式
今天起床刷到了一个相关视频,觉得很有意思,就浅浅地总结一下:【游戏开发秘籍】XML?JSON?YAML?一个视频带你搞懂所有配置文件!_哔哩哔哩_bilibili
首先有个最基本的概念:为什么我们需要配置文件,我们明明有数据库这样专门用来处理数据的第三方软件了。
视频中也说了,首先本来游戏的数据就有动态和静态之分,对于静态数据来说,我们只在游戏运行时加载进内存,然后全程只可读不可写,这样避免了频繁的IO操作,也免去了数据库的连接的开销;数据库适合处理频繁更改的动态数据,用于处理多读少写的内容会有浪费。
那下一个问题是:为什么不把所有的游戏相关数据直接在代码里写死?而是要专门单独拎出来集中处理?
但凡稍微接触过真正游戏开发的人应该都知道,首先游戏中相关的数据其实不是由程序来定的而是策划来填,程序要做的就是提供工具;其次是后续游戏的更新,如果不把数据单独拎出来而是写在代码中,那么每一次更新数据都必须是全量更新(所有代码重新编译),效率非常低下。
视频中从最开始到最后一共提到了这些配置文件格式:

我们来一个一个介绍与分析。
当我们分析具体的配置文件选择时,往往从这几个角度进行考虑:

INI
ini是一种历史悠久的配置文件格式,有多悠久呢?

可以看到是早早地就归隐田园了啊,虽然看起来非常old school,但客观地说确实格式也相对比较简单,也满足了我们的可读性要求。格式上分为三个部分, 由节(Sections)、键值对(Key-Value Pairs) 和 注释 组成,[]中的就是节的内容,用于分组,用等号连接键和值,最后以分号开头后续添加注释。

缺点当然也很明显,只有等号连接键值对的方式以及用中括号来分组,那么难以适应后续越来越复杂的嵌套数据需求。
[user]
name = Alice
# 无法直接表示 user.address.city 这样的三级结构XML
xml是第一个支持复杂嵌套数据的可读配置文件格式。

可以从示例中看到,我们的XML语言是基于标签来进行分层的(图中的<Button>与</Button>、<Background>与</Background>等),这虽然帮助我们支持了复杂的嵌套数据,但是如果嵌套的层数足够多,那么文件体积会过大,可读性也会削弱。
<User><Id>123</Id><Name>Alice</Name><Address><City>Beijing</City><Street>Main St</Street><Postcode>100000</Postcode></Address><Contacts><Email>alice@example.com</Email><Phone type="mobile">123-456-7890</Phone></Contacts>
</User>可以看到这个XML示例文件中其实真正存储的数据内容甚至没有标签的内容多,这就是所谓的标签冗余。
JSON
为了解决XML文件冗余的问题,又有一种新的配置文件格式被搬了上来:JSON。
比起XML标签化来处理嵌套数据导致冗余的问题,JSON的格式非常简单直接:JSON的内存也是键值对,但是采用花括号{}和中括号[]来进行分组与嵌套,具体地说,对象用{}来包裹,键值对之间用:连接,而数组用[]包裹。
<user><name>Alice</name><address><city>Beijing</city><street>Main St</street></address><hobbies><hobby>reading</hobby><hobby>coding</hobby></hobbies>
</user>
...
...
// JSON
{"name": "Alice","address": {"city": "Beijing", "street": "Main St"},"hobbies": ["reading", "coding"]
}无疑,JSON文件格式更小更方便,实际的应用中JSON文件也使用非常广泛了,但是JSON格式存在一个缺陷:缺少专门的注释语法。
那么从前三种配置文件的格式可以看出,我们从最开始的无法表达嵌套数据,到标签冗余,再到缺少注释,问题逐渐被解决,那么有没有一种方法完美解决了上述的所有需求呢?
有的兄弟有的。
YAML

关于YAML格式,他满足了上述的所有需求:有注释,足够轻量,支持嵌套,硬要挑毛病的话就是这个类python文件的通过缩进来实现分层的方法对程序员编写时要求较高。
Lua
其实我视频看到这里的时候也有点没想到Lua居然还可以作为我们的配置文件格式,不过想了想其实也合理:Lua最常被提及的用途就是我们的热更新,作为解释执行的脚本语言,方便我们可以在游戏运行时动态更新,那么这不就是完美符合我们配置文件更新的需求吗?


其中,Lua的解释器的大小仅有200KB左右,是已知的最小的解释器之一。
上述所有的配置文件格式都是文本格式,也就是保留可读性的文本格式,但是如果我们可以抛弃可读性这一需求的话,二进制格式的文件显然体积更小读取更快,更符合我们对于数据文件的需求,聊到二进制格式就绕不开大名鼎鼎的ProtoBuf格式。
ProtoBuf
关于ProtoBuf的好处,我们之前也介绍过,主要就是:体积小,跨平台,兼容性强,允许你在不删处旧有字段的前提下直接添加新字段实现热更,在这里我不妨更深入一点,聊聊ProtoBuf为何这么好。
TLV
所谓的TLV指的是ProtoBuf在序列化过程中的编码方式:Tag-Length-Value,Tag是每个字段的编号,Length是每个字段的长度而Value是具体每个字段的内容。传统的二进制编码方式中为了明确消息边界需要用分隔符,而TLV编码方式相当于帮助我们把传统的流式传输变成了一个一个字段的拼接,我们不再需要分隔符来划分消息边界,效率自然就高了。

Wire Type
Protobuf 定义了 6 种 Wire Type,每种对应不同的数据类型和编码方式,每个字段的Tag由具体的Wire Type和字段编号组成:

我们这里来讲讲varint和length-delimited这两种编码类型。
Varint
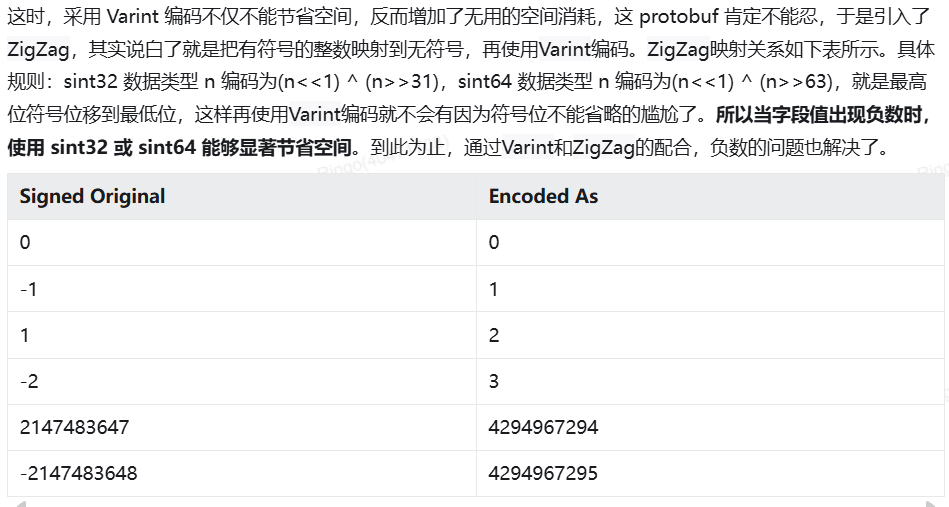
Varint 是一种动态长度的整数编码方式,根据数值大小自动调整字节数。数值越小,占用字节越少(如 1 仅需 1 字节,而 300 需 2 字节)。每个字节的最高位(MSB)为标志位:1 表示后续还有字节,0 表示终止,低 7 位存储有效数据,按小端序排列(低位字节在前)。

虽然目前为止Varint表现得很好,但是有一个特殊情况:负数。二进制一般针对负数的做法就是补码,那这样的话Varint可就没法再节省字节数了(Varint 依赖 高位 0 压缩,而负数的补码高位全为 1,无法压缩),这个特殊情况我们需要Zigzag。
Length-delimited
当wire_type=0/1/5的时候是不需要指定Length,0代表Varint上面已经介绍,1和5分别表示64bit和32bit就已经指定长度。只有当wire_type=2时,需要Length表示Value的编码后的字节长度,Length也是采用的Varint编码,如下所示,需要注意的是此时的Value无需Varint编码,例如,string类型就使用UTF-8编码。
除此之外,还有一些基本的比如设定默认值,没有明确赋值的内容就直接不编码而是直接套默认值,以及压缩算法等方法来帮助ProtoBuf节省空间。以上种种就是ProtoBuf的效率高效的原因。
当然ProtoBuf并非全能,有一个双刃剑的东西就是,ProtoBuf有着强scheme依赖:
强scheme依赖

我们需要预先定义好相关的IDL文件(.proto文件)之后ProtoBuf才能识别并实现序列化/反序列化。
那么有没有不需要IDL文件就可以进行序列化和反序列化的二进制格式呢?
MsgPack
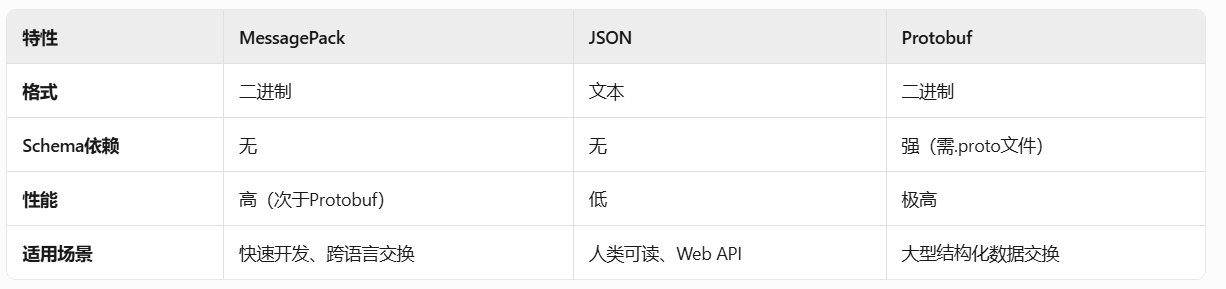
MessagePack 是轻量级高性能序列化方案,适合对性能敏感且无需严格类型检查的场景。若需强类型或企业级规范,Protobuf 更优;若追求可读性,JSON 仍是首选 。