【上市公司变量测量】Python+FactSet Revere全球供应链数据库,测度供应链断裂与重构变量——丁浩员等(2024)《经济研究》复现
目录
- 1 对Factset全球供应链数据库的简单解读
- 2 对丁浩员等测度方式的解读
- 2.1 断裂和恢复指标的解读
- 2.2 转移指标的解读
- 3 供应链断裂与重构指标的测度
- 3.1 原始数据库处理
- 3.2 中国沪深A股上市企业作为供应商的供应链关系对筛选、标记与调整
- 3.2.1 筛选与标记:基于Python
- 3.2.2 根据rel_type关系进行调整
- 3.3 供应链关系的时间顺序调整与断裂、恢复变量测度
- 3.3.1 运行Python代码
- 3.3.2 供应链关系的时间顺序调整
- 3.3.3 供应链断裂、恢复变量测度
- 3.4 供应链转移的测量
丁浩员等在《经济研究》2024年第8期发表了一篇题为《贸易政策冲击下的跨国供应链断裂与重构研究》的文章,提出了跨国供应链断裂与重构两个变量的测度方式,但是稍微有点儿说得不够清楚。
下文将对其所采用的FastSet Revere全球供应链数据库和其测度方式进行简单解读,并基于Python,结合Excel操作实现。
1 对Factset全球供应链数据库的简单解读
数据库获取渠道:正规来讲是去WRDS官网花钱买,但是众鲤、马克、咸鱼、淘宝已经泛滥了。
可以获取到的数据包括company.dta、ralations.dta两个数据文件,前者为公司在各个时间段的信息,后者为各个时间段的数据信息,还有一系列变量含义的说明文档。
结合说明文档,在此对一些对研究比较重要的变量进行个人解读:
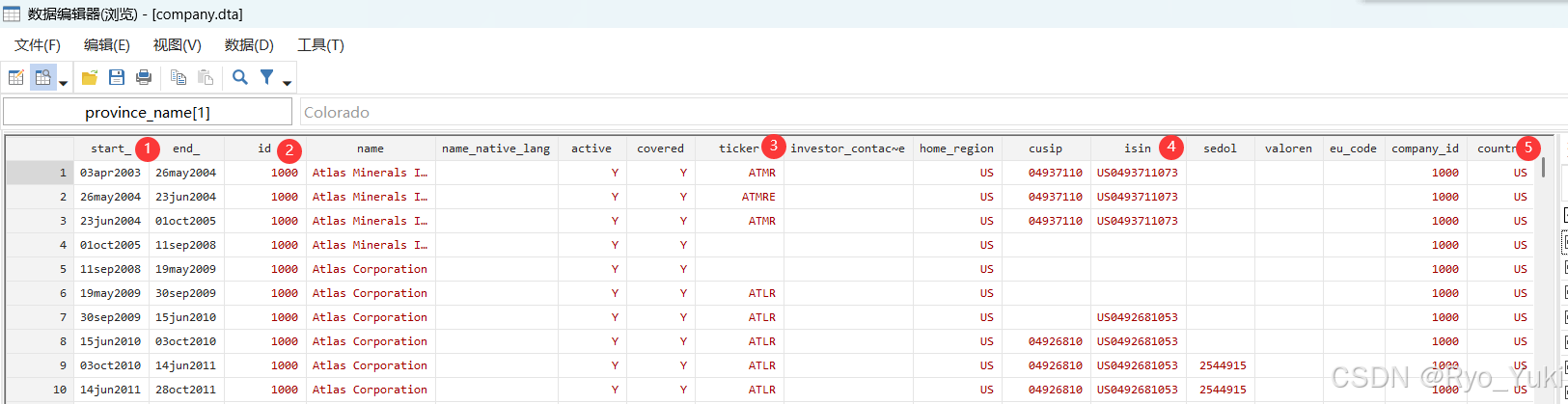
首先是company.dta,有七个变量比较重要:
第一处,start_和end_,公司信息的时间段数据。
第二处,id,数据库中的唯一标识符,用于与relations.dta数据库进行匹配。
第三处,ticker,如果该企业是上市公司,这里就有上市企业代码,中国沪深A股上市企业就是六位的代码,注意这里没法显示深交所代码前边的0,需要自行补齐后,与年份结合就可以与国泰安数据库进行匹配。
第四处,cusip和isin,两种国际通用的唯一标识符,用于于其他外国数据库里的控制变量进行匹配。
第五处,country,公司所处地区(注意不是国家的意思,因为里边有TW、HK、MO)。
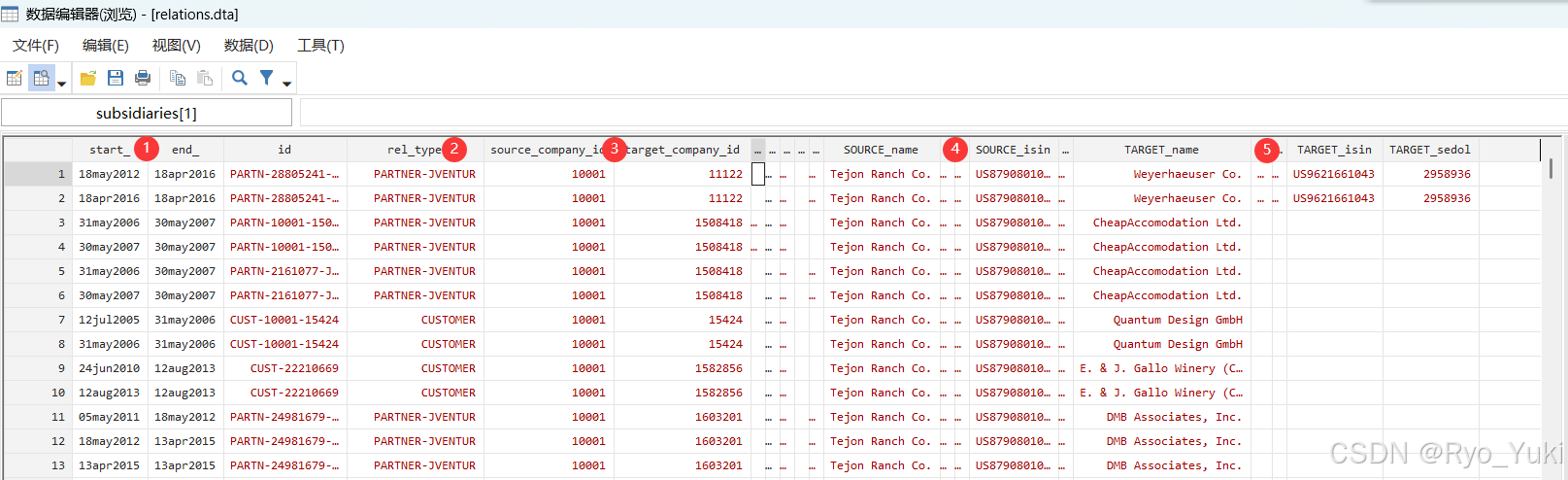
再就是relations.dta,有九个变量比较重要:
第一处,供应链关系信息的时间段数据,表示公司在start_至end_期间的某些特征属性。
第二处,供应链关系rel_type,有供应商(supplier)、客户(customer)、竞争者、合作者等,前两类是对研究有用的数据,表示target企业是source企业的rel_type。
第三处,source企业和target企业各自的id,本数据库中的唯一标识符,可以与company.dta数据进行匹配。
第四处,source企业和target企业各自的isin、cusip,两种国际通用的唯一标识符,用于于其他外国数据库里的控制变量进行匹配。
还需要注意一个点就是,这里边end_会出现01jan4000,一般默认成至今即可。
2 对丁浩员等测度方式的解读
2.1 断裂和恢复指标的解读
首先要明确,丁浩员等的数据是月度频次的,即以“供应链关系-月份”为数据单元,可类比常见的“企业-年份”数据单元。举例来说,如果一个供应链关系对在2019年1月至2019年6月存在,那么这个供应链关系对在生成的数据中就应该有六条数据。

关于断裂的测量,文章只有短短的这两行话,并没有说得很详细。以我的理解,如果同一个供应链关系对在2019年1月至6月存在,7月至9月不存在,10月至12月存在,那么2019年1月至5月、10月至11月,Break变量为0,代表未发生断裂行为。2019年6月和20 19年12月,Break为1,代表发生断裂行为。而2019年7月至9月,该供应链对无数据。

重构包括恢复和转移两个变量。关于重构中恢复的测量比较好理解,还是上边的例子,同一个供应链关系,在2019年6月断裂后又在2019年10月恢复,从丁浩员等(2024)的注释中可以看出,他们是在2019年6月的Recover标“1”


而我希望更好的捕捉到供应链恢复这个行为,想将2019年10月的Recover标记为“1”
因此,下文会在代码中标注两种方法,默认是丁浩员那种,我自定义的这种会注释掉,如需要可取消注释。
2.2 转移指标的解读
关于重构中转移的变量感觉可能争议比较大,我理解的是,如果一家中国供应商,在整个数据库中有多个不同的外国客户,以与客户彻底断裂时间(即不再出现恢复情况)的最早时间T为基准,若与其他客户构建供应链关系的时间晚于T,则将其构建供应链的时间的Transfer标记为1。例如:
- 中国供应商与外国客户A在2019年1月至2月和2019年10月至12月存在存在供应链关系
- 与外国客户B在2019年3月至5月存在供应链关系
- 与外国客户C在2019年4月至8月存在供应链关系
- 与外国客户D在2019年6月至8月存在供应链关系
- 与外国客户E在2019年8月至10月存在供应链关系
那么最早彻底断链时间为2019年5月,则在D的6月份Transfer标1,E的8月份Transfer标1,其他为0。
当然,以上我的理解,并不一定是这篇文章中真正的标注方式,所以如果我在论文中用到这样测出的变量,我会明确把自己的思路说一遍,防止出问题。
另外可能是作者的不注意,留了个细微的bug,在数据说明部分提到了“本文从该数据库中筛选出所有中国上市公司的跨国供应链关系数据。其中“跨国”说明研究数据应该不包括客户为中国企业的供应链关系对,但是此处又说可以转移到中国,有点儿相互矛盾。

最后把Recover和Transfer的1合并,即为Refill。
3 供应链断裂与重构指标的测度
依据丁浩员等的做法,该部分的目标是进行以中国沪深A股上市企业作为供应商,外国企业作为客户的供应链断裂与重构指标的测度,其他可作为参考。
3.1 原始数据库处理
原始数据确实有点大,建议根据自己所需要的研究区间进行精简操作,此步骤非必需。例如,保留2018年往后的数据,对company.dta、ralations.dta都进行如下操作,并另存为新数据文件:
gen year=year(start_)
drop if year<2018
3.2 中国沪深A股上市企业作为供应商的供应链关系对筛选、标记与调整
3.2.1 筛选与标记:基于Python
在company.dta里筛选出中国沪深A股上市企业,先删除没有股票代码的数据,再删除不是CN的公司
drop if missing(ticker)
drop if country!="CN"
后续导出至Excel进行粗略筛选,仅保留在沪深A股上市的企业,可以用数字大小来判别,即股票代码在1-100000(深证),300000-399999(创业板),600000-699999(上证),当然如果想保留北证,就加上400000-499999、800000-899999,但需要留意港股是五位数字代码,不要一味图快。其他的诸如新三板、美股上市的都给删除。
最后根据企业id、股票代码进行excel的删除重复值操作,在我的18-24区间里,一个id就只对应一个股票代码,如果其他区间记得留意是否有特殊情况。最后将这两列保存为CNcompany.xlsx。
在relations.dta中仅保留关系为customer和supplier的数据
keep if rel_type=="CUSTOMER" | rel_type=="SUPPLIER"
运行下方Python代码(理解时注意看注释),读取中国上市企业文件,读取relations.dta,将结果输出至result.xlsx,即为与中国沪深A股上市公司相关的所有供应链关系对。
import pandas as pd
unique=pd.read_excel('CNcompany.xlsx',sheet_name='only',header=[0])
IDlist=unique['id'].tolist() #读取唯一id,在这个列表里的都是中国沪深A股上市公司
df=pd.read_stata('relations.dta')
result=pd.DataFrame(columns=['start_','end_','id','rel_type','source_company_id','source_ticker','source_cusip','target_company_id','target_cusip','flag'],index=range(1,200000))#创建一个新表,用于存储有用信息
index=1
for i in range(len(df)):print(i)#用来看运行进度#如果source和target都是中国沪深A股上市公司,录信息,标记为S&T,表示位于source和target端if int(df['source_company_id'][i]) in IDlist and int(df['target_company_id'][i]) in IDlist:result['start_'][index]=df['start_'][i]result['end_'][index]=df['end_'][i]result['id'][index]=df['id'][i]result['rel_type'][index]=df['rel_type'][i]result['source_company_id'][index]=df['source_company_id'][i]result['source_ticker'][index]=df['SOURCE_ticker'][i]result['source_cusip'][index]=df['SOURCE_cusip'][i]result['target_company_id'][index]=df['target_company_id'][i]result['target_cusip'][index]=df['TARGET_cusip'][i]result['flag'][index]='S&T'index+=1#如果source是中国沪深A股上市公司,录信息,标记为S,表示位于source端elif int(df['source_company_id'][i]) in IDlist:result['start_'][index]=df['start_'][i]result['end_'][index]=df['end_'][i]result['id'][index]=df['id'][i]result['rel_type'][index]=df['rel_type'][i]result['source_company_id'][index]=df['source_company_id'][i]result['source_ticker'][index]=df['SOURCE_ticker'][i]result['source_cusip'][index]=df['SOURCE_cusip'][i]result['target_company_id'][index]=df['target_company_id'][i]result['target_cusip'][index]=df['TARGET_cusip'][i]result['flag'][index]='S'index+=1#如果target是中国沪深A股上市公司,录信息,标记为T,表示位于target端elif int(df['target_company_id'][i]) in IDlist:result['start_'][index]=df['start_'][i]result['end_'][index]=df['end_'][i]result['id'][index]=df['id'][i]result['rel_type'][index]=df['rel_type'][i]result['source_company_id'][index]=df['source_company_id'][i]result['source_ticker'][index]=df['SOURCE_ticker'][i]result['source_cusip'][index]=df['SOURCE_cusip'][i]result['target_company_id'][index]=df['target_company_id'][i]result['target_cusip'][index]=df['TARGET_cusip'][i]result['flag'][index]='T'index+=1else:continue
result.to_excel('result.xlsx')
3.2.2 根据rel_type关系进行调整
至此时,reslut.xlsx上有着供应链关系仅有customer和supplier,至少有一端是中国沪深A股上市公司,以及标记具体在哪一端的flag数据。
对于rel_type为customer,表示target中的企业是source中的企业的客户,flag标记为S的不动,flag标记为T的调换位置
对于rel_type为supplier,表示target中的企业是source中的企业的供应商,flag标记为S的调换位置,flag标记为T的不动
将列标题中的source改为supplier,target改为customer,完成单一端为中国沪深A股上市公司的数据调整。
对于flag标记为S&T,即两端均为中国沪深A股上市公司,如果做到是跨国供应链,直接删除即可(我是这么做的)。如果做的是全球供应链,建议与自己的导师讨论,这里不再讨论。
3.3 供应链关系的时间顺序调整与断裂、恢复变量测度
3.3.1 运行Python代码
注意运行下方Python之前,在excel里新插入“supplier_customer”列,把source_company_id和target_company_id做一个字符串拼接,中间用“-”分割,并把excel表中最后一行的该拼接值替换掉***SCchains.remove(‘8727858-99946865’)***这里边的8727858-99946865,运行后会输出该批次有问题需要调整的拼接值,以及最终包含break和recover的数据文件。
注意,建议可以事先做个匹配,把外国客户的所属地区、中国供应商的一些控制变量、是否ST和金融业都给做好,根据自己的数据需求,提前做好删除工作,这样可以减少工作量,也是提高后边转移变量的测度。
import pandas as pddfindex=1
monthList=['2018-01','2018-02','2018-03','2018-04','2018-05','2018-06','2018-07','2018-08','2018-09','2018-10','2018-11','2018-12','2019-01','2019-02','2019-03','2019-04','2019-05','2019-06','2019-07','2019-08','2019-09','2019-10','2019-11','2019-12','2020-01','2020-02','2020-03','2020-04','2020-05','2020-06','2020-07','2020-08','2020-09','2020-10','2020-11','2020-12','2021-01','2021-02','2021-03','2021-04','2021-05','2021-06','2021-07','2021-08','2021-09','2021-10','2021-11','2021-12','2022-01','2022-02','2022-03','2022-04','2022-05','2022-06','2022-07','2022-08','2022-09','2022-10','2022-11','2022-12','2023-01','2023-02','2023-03','2023-04','2023-05','2023-06','2023-07','2023-08','2023-09','2023-10','2023-11','2023-12','2024-01','2024-02','2024-03','2024-04','2024-05','2024-06','2024-07','2024-08','2024-09','2024-10','2024-11','2024-12','4000-01']
DATA=pd.read_excel('SUPPLIER_DATA.xlsx',sheet_name='Sheet1',header=[0])#中国上市公司供应链数据
SCchain=set(DATA['supplier_customer'])
SCchains=list(SCchain)#不重复供应链对
SCchains.remove('8727858-99946865')#注意这里,需要把自己excel表里最后一行的拼接值放到这儿,因为下方有行数+1的操作,不去除他会导致后边报错
df=pd.DataFrame(columns=['supplier_customer','supplier_id','supplier_ticker','customer_id','TIME','BREAK','REFILL','RECOVER','TRANSFER'],index=range(1,100000))
adjustSC=[]
start=0
end=1000
for SC in SCchains[start:end]:#一次性运行完可能有点慢,可以调整上边start和end的数据,分批运行l=SC.split('-')supplier_id=l[0]#供应商idcustomer_id=l[1]#客户idindex=DATA.loc[DATA['supplier_customer']==SC].index[0]#获取供应链对的行索引count=1#定义当前供应链对的重复次数while DATA['supplier_customer'][index+count]==SC:count+=1#通过while循环,计算出当前供应链对的重复次数#对在月度层面连贯的供应链进行合并,并计算break和recover#如果只有一列数据,则根据该列直接生成if count==1:startmonth=DATA['start'][index]endmonth=DATA['end'][index]for j in range(monthList.index(endmonth)-monthList.index(startmonth)+1): df['supplier_id'][dfindex]=supplier_iddf['customer_id'][dfindex]=customer_iddf['supplier_customer'][dfindex]=SCdf['TIME'][dfindex]=monthList[monthList.index(startmonth)+j]df['BREAK'][dfindex]=0dfindex+=1df['BREAK'][dfindex-1]=1#如果有多列数据,则需要遍历所有行elif count>=2:flag=0 #标记是否为第一次进行生成,即是否存在断裂和恢复breaki=0 #记录断裂时的ifor i in range(1,count+1): #如果下一行的start与本行的end相同,则说明两条连贯,不进行操作if monthList.index(DATA['end'][index+i-1])==monthList.index(DATA['start'][index+i]) and i!=count:continue#如果下一行的start比本行的end晚,则说明两条不连贯,进行操作if monthList.index(DATA['end'][index+i-1])<monthList.index(DATA['start'][index+i]) or i==count:#当flag为0,则说明之前未进行过此操作,第一行的start即为开始的时间点if flag==0:startmonth=DATA['start'][index]#当flag不为0,则说明之前进行过此操作,索引为index+breaki的行的start即为开始的时间点else:startmonth=DATA['start'][index+breaki]#丁浩员等的方法,将恢复标记在断裂行为的那一行df['RECOVER'][index+i-1]=1#我的方法,将恢复标记在恢复行为的那一行#df['RECOVER'][dfindex]=1endmonth=DATA['end'][index+i-1] #设置end为结束的时间点#对df里的数据进行赋值,从monthList中根据下表提取月份for month in monthList[ monthList.index(startmonth) : monthList.index(endmonth)+1 ]: df['supplier_id'][dfindex]=supplier_iddf['customer_id'][dfindex]=customer_iddf['supplier_customer'][dfindex]=SCdf['TIME'][dfindex]=monthdf['BREAK'][dfindex]=0dfindex+=1df['BREAK'][dfindex-1]=1flag=1breaki=i#如果下一行的start与本行的end早,则说明时间上倒置,进行人工调整,以避免处置该情况使得代码过于复杂,工作量约为唯一供应链对数的4%左右elif monthList.index(DATA['end'][index+i-1])>monthList.index(DATA['start'][index+i]):print(SC+" need to adjust")adjustSC.append(SC)
#输出需要调整的供应链及其对数
adjustSC=set(adjustSC)
adjustSC=list(adjustSC)
print(adjustSC)
print(len(adjustSC))
#检验最终结果的不重复供应链对数,观察是否相等
chain1=set(df['supplier_customer'])
chains1=list(chain1)#不重复供应链对
print(len(chains1))
print(len(SCchains))df.to_excel(f'result_{start} to {end}.xlsx')
3.3.2 供应链关系的时间顺序调整
需要做这部分工作也的确是迫于无奈,因为我没有想到合适的办法去解决这一现象,可能会耗费大量时间人工来做,如果有办法做到的朋友欢迎留言讨论
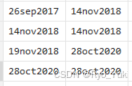
在数据中,大部分(95%左右)供应链关系对是按照时间顺序下来的,即如上方代码注释里,上一条时间线的end总是早于或等于下一条的start,例如
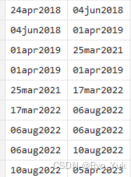
但是有少部分像这样,这时候就得删除第四行,才能让供应链关系的时间顺序被上述代码识别。
该过程比较枯燥,但确实是我能力范围内无法避免的。
3.3.3 供应链断裂、恢复变量测度
把时间顺序调整好后,分批后进行excel拼接或整体运行3.3.1中的代码即可。
3.4 供应链转移的测量
读取3.2.1中调整好的以中国沪深A股上市公司为供应商excel表(即代码中的SUPPLIER_DATA.xlsx),以及上一步测算好供应链断裂、恢复变量的excel表(即代码中的result.xlsx)。
由于转移变量的测量逻辑比较复杂,所以需要单独新建一个py文件测量,代码如下:
import pandas as pdmonthList=['2018-01','2018-02','2018-03','2018-04','2018-05','2018-06','2018-07','2018-08','2018-09','2018-10','2018-11','2018-12','2019-01','2019-02','2019-03','2019-04','2019-05','2019-06','2019-07','2019-08','2019-09','2019-10','2019-11','2019-12','2020-01','2020-02','2020-03','2020-04','2020-05','2020-06','2020-07','2020-08','2020-09','2020-10','2020-11','2020-12','2021-01','2021-02','2021-03','2021-04','2021-05','2021-06','2021-07','2021-08','2021-09','2021-10','2021-11','2021-12','2022-01','2022-02','2022-03','2022-04','2022-05','2022-06','2022-07','2022-08','2022-09','2022-10','2022-11','2022-12','2023-01','2023-02','2023-03','2023-04','2023-05','2023-06','2023-07','2023-08','2023-09','2023-10','2023-11','2023-12','2024-01','2024-02','2024-03','2024-04','2024-05','2024-06','2024-07','2024-08','2024-09','2024-10','2024-11','2024-12','4000-01']
DATA=pd.read_excel('SUPPLIER_DATA.xlsx',sheet_name='Sheet1',header=[0])#中国上市公司供应链数据
df=pd.read_excel('result.xlsx',sheet_name='Sheet1',header=[0])#完成break和recover计算的月度数据表
SCchain=set(DATA['supplier_customer'])
SCchains=list(SCchain)#不重复供应链对
SCchains.remove('8727858-99946865-688223')
df['supplier_id']=df['supplier_id'].astype(str)
company=set(df['supplier_id'])
companies=list(company)
print(len(companies))
for company in companies:company_chain=[]#储存for SC in SCchains:#如果SC的开头是该企业代码,就添加到列表if SC.startswith(company):company_chain.append(SC)#如果只搜索到一个同名,则不存在转移,直接跳过if len(company_chain)==1:continue#如果搜索到多个,可能存在转移,执行后续操作elif len(company_chain)>1: #print(company_chain)startDate={}#字典形式,储存各供应链的开始日期endDate={}#字典形式,储存各供应链的结束日期for chain in company_chain:index=DATA.loc[DATA['supplier_customer']==chain].index[0]#获取供应链对开始的行索引count=1#定义当前供应链对的重复次数while DATA['supplier_customer'][index+count]==chain:count+=1#通过while循环,计算出当前供应链对的重复次数start=DATA['start'][index]end=DATA['end'][index+count-1]startDate[chain]=startendDate[chain]=endmindate=monthList.index('4000-01')for end in list(endDate.values()):if monthList.index(end)<mindate:mindate=monthList.index(end)for chain,start in startDate.items():if monthList.index(start)>mindate:print(chain)#丁浩员等的方法,将转移标记在断裂行为的那一行index=df.loc[(df['Relation']==list_of_key[k]) & (df['Time']==monthList[mindate])].index[0]#我的方法,将转移标记在转移行为的那一行#index=df.loc[df['supplier_customer']==chain].index[0]#获取供应链对开始的行索引 df.loc[index,'TRANSFER']=1
df.to_excel('A.result.xlsx')