RabbitMQ03——面试题
目录
一、mq的作用和使用场景
二、mq的优点
2.1架构设计优势
2.2功能特性优势
2.3性能与可靠性优势
2.4生态系统优势
2.5对比优势
三、mq的缺点
3.1性能与扩展性限制
3.2功能局限性
3.3运维复杂度
3.4与其他消息队列的对比劣势
四、mq相关产品,每种产品的特点
4.1开源产品
4.2 商业/云产品
五、rabbitmq的搭建过程
六、rabbitmq相关角色
七、rabbitmq内部组件
八、生产者发送消息的过程?
九、消费者接收消息过程?
十、springboot项目中如何使用mq?
十一、如何保障消息不丢失?
十二、死信交换机和死信队列
RabbitMQ规定消息符合以下某种情况时,将会成为死信
十三、延迟队列简介
一、mq的作用和使用场景
作用:
RabbitMQ 是一个开源的消息代理和队列服务器,主要用于实现应用程序之间的异步通信和解耦。它的主要作用包括:
-
应用解耦:将相互依赖的应用系统分离,降低系统间的耦合度
-
异步通信:实现系统间的非实时、异步消息传递
-
流量削峰:缓冲突发流量,避免系统被压垮
-
消息分发:支持多种消息路由模式(点对点、发布/订阅等)
-
可靠传递:提供消息持久化、确认机制等保证消息可靠传输
使用场景:
| 使用场景 | 场景示例 | 优势 |
|---|---|---|
| 异步任务处理 | 用户注册后发送欢迎邮件/短信 | 主流程快速响应,耗时操作异步执行 |
| 订单支付成功后通知物流系统 | ||
| 图片/视频上传后的处理任务 | ||
| 应用解耦 | 电商系统中订单系统与库存系统分离 | 系统可独立开发、部署和扩展 |
| 主业务系统与数据分析系统解耦 | ||
| 流量削峰 | 秒杀/抢购活动中的请求排队 | 平滑流量波动,保护后端系统 |
| 突发性大流量日志收集 | ||
| 分布式系统通信 | 微服务间的事件通知 | 提供标准协议支持多语言客户端(如Java、Python等) |
| 跨语言系统间的数据交换 | ||
| 数据同步 | 主数据库变更同步到缓存 | 可靠的消息传递机制 |
| 多个系统间的数据一致性保证 |
1、抢购活动,削峰填谷,防止系统崩塌。
2、延迟信息处理,比如 10 分钟之后给下单未付款的用户发送邮件提醒。
3、解耦系统,对于新增的功能可以单独写模块扩展,比如用户确认评价之后,新增了给用户返积分的功能,这个时候不用在业务代码里添加新增积分的功能,只需要把新增积分的接口订阅确认评价的消息队列即可,后面再添加任何功能只需要订阅对应的消息队列即可。
二、mq的优点
2.1架构设计优势
| 优点 | 说明 |
|---|---|
| 松耦合设计 | 生产者和消费者无需相互感知,通过消息队列实现解耦 |
| 异步通信 | 支持非阻塞式消息传递,提高系统响应速度 |
| 缓冲能力 | 有效应对流量洪峰,实现平滑的系统负载 |
| 扩展性强 | 可通过集群轻松扩展处理能力 |
2.2功能特性优势
| 优点 | 技术实现 |
|---|---|
| 多协议支持 | 原生支持AMQP 0-9-1,同时支持STOMP、MQTT等协议 |
| 灵活路由 | 提供4种交换机类型(Direct/Topic/Fanout/Headers)实现复杂消息路由 |
| 消息可靠性 | 支持持久化、生产者确认、消费者ACK机制 |
| 高可用性 | 支持镜像队列、集群部署,保证服务连续性 |
| 管理便捷 | 提供Web管理界面和HTTP API,支持监控和运维 |
2.3性能与可靠性优势
-
消息持久化:
-
支持将消息和队列持久化到磁盘
-
即使服务器重启也能保证消息不丢失
-
-
集群支持:
-
支持多节点集群部署
-
镜像队列可自动同步消息
-
-
灵活的消息确认机制:
// 消费者确认模式选择 channel.basicConsume(queue, autoAck, consumer);
-
自动确认(autoAck=true)
-
手动确认(autoAck=false)
2.4生态系统优势
| 方面 | 支持情况 |
|---|---|
| 多语言客户端 | 支持Java/.NET/Python/Ruby/Go等几乎所有主流语言 |
| 社区支持 | 活跃的开源社区,丰富的文档和解决方案 |
| 云平台集成 | 完美支持Kubernetes,各大云平台提供托管服务 |
| 插件体系 | 支持多种官方/社区插件(如延迟消息、MQTT协议等) |
2.5对比优势
| 特性 | RabbitMQ | Kafka | ActiveMQ |
|---|---|---|---|
| 消息延迟 | 支持(需插件) | 不支持 | 支持 |
| 吞吐量 | 万级QPS | 百万级QPS | 万级QPS |
| 协议支持 | 多协议 | 自定义协议 | 多协议 |
| 运维复杂度 | 低 | 高 | 中 |
三、mq的缺点
3.1性能与扩展性限制
| 缺点 | 具体表现 | 对比数据 |
|---|---|---|
| 吞吐量有限 | 单节点最佳吞吐约5万-10万msg/s,低于Kafka等分布式队列 | Kafka单节点可达百万级msg/s |
| 队列数量限制 | 单个集群建议不超过5万个队列,过多队列会导致性能下降 | Kafka的topic分区数可轻松过万 |
| 消息堆积能力弱 | 内存受限,默认当内存使用超过40%会阻塞生产者 | Kafka依赖磁盘存储,堆积能力更强 |
3.2功能局限性
| 缺点 | 具体表现 | 解决方案 |
|---|---|---|
| 消息顺序不严格 | 在多消费者场景下无法保证全局消息顺序 | 需单消费者+单队列实现有限顺序保证 |
| 延迟消息实现复杂 | 原生不支持延迟队列,需通过TTL+死信队列间接实现 | 安装rabbitmq_delayed_message_exchange插件 |
| 事务性能差 | AMQP事务性能低下,提交事务的吞吐量下降10倍以上 | 使用Confirm模式替代 |
3.3运维复杂度
| 缺点 | 具体表现 | 影响范围 |
|---|---|---|
| 集群管理复杂 | 镜像队列配置繁琐,节点增减需要手动维护 | 增加运维成本 |
| 内存管理敏感 | 内存使用超过阈值(默认40%)会阻塞生产者,需精细调优 | 生产环境需设置监控告警 |
| 跨机房同步困难 | 原生不支持多机房同步,需借助Shovel或Federation插件 | 异地容灾实现成本高 |
3.4与其他消息队列的对比劣势
| 功能维度 | RabbitMQ | Kafka | RocketMQ | Pulsar |
|---|---|---|---|---|
| 消息堆积能力 | 内存受限 | 磁盘存储,极强 | 磁盘存储,强 | 分层存储,最强 |
| 严格顺序 | 仅单队列保证 | 分区内严格有序 | 分区严格有序 | 分区严格有序 |
| 横向扩展 | 队列粒度扩展困难 | 分区自动平衡 | 自动负载均衡 | 自动扩展 |
| 延迟消息 | 需插件支持 | 不支持 | 原生支持 | 原生支持 |
| 事务支持 | 性能差 | 支持 | 支持 | 支持 |
四、mq相关产品,每种产品的特点
4.1开源产品
1. RabbitMQ
| 特点 | 说明 |
|---|---|
| 协议支持 | 支持AMQP、MQTT、STOMP等多种协议 |
| 消息路由 | 提供4种交换机类型,路由策略最灵活 |
| 可靠性 | 支持持久化、确认机制、事务(性能低) |
| 管理界面 | 提供功能完善的Web管理控制台 |
| 适用场景 | 企业级应用、需要复杂路由的中等规模消息处理 |
2. Apache Kafka
| 特点 | 说明 |
|---|---|
| 高吞吐 | 设计用于日志处理,单机可达百万级TPS |
| 持久化 | 消息持久化到磁盘,支持长期保存 |
| 分区顺序 | 保证分区内消息严格有序 |
| 流处理 | 与Kafka Streams深度集成 |
| 适用场景 | 日志收集、流数据处理、大数据管道 |
3. Apache RocketMQ
| 特点 | 说明 |
|---|---|
| 事务消息 | 提供完整的事务消息解决方案 |
| 延迟消息 | 原生支持18个级别的延迟消息 |
| 消息轨迹 | 可追踪消息全生命周期 |
| 双主双从 | 高可用架构设计 |
| 适用场景 | 金融支付、电商交易等对一致性要求高的场景 |
4. Apache Pulsar
| 特点 | 说明 |
|---|---|
| 分层架构 | 计算与存储分离,支持无限扩展 |
| 多租户 | 原生支持多租户隔离 |
| 消息模型 | 统一队列和流处理模型 |
| 地理复制 | 内置多机房同步机制 |
| 适用场景 | 云原生环境、多租户SaaS应用、全球分布式系统 |
5. ActiveMQ
| 特点 | 说明 |
|---|---|
| JMS支持 | 完整实现JMS 1.1规范 |
| 协议支持 | 支持OpenWire、STOMP、AMQP等 |
| 嵌入式 | 可作为嵌入式消息系统使用 |
| 适用场景 | 传统Java EE应用、需要JMS规范的项目 |
4.2 商业/云产品
1. AWS SQS/SNS
| 特点 | 说明 |
|---|---|
| 全托管 | 无需运维基础设施 |
| 弹性扩展 | 自动扩展处理能力 |
| 与AWS集成 | 深度集成Lambda、EC2等服务 |
| 适用场景 | 运行在AWS上的应用,需要轻量级消息服务 |
2. Azure Service Bus
| 特点 | 说明 |
|---|---|
| 企业级特性 | 支持会话、死信队列、计划消息等 |
| 高级消息模式 | 提供主题、队列和中继三种模式 |
| Geo-DR | 内置异地灾难恢复 |
| 适用场景 | 企业级应用集成,特别是微软技术栈项目 |
3. Google Cloud Pub/Sub
| 特点 | 说明 |
|---|---|
| 全球消息传递 | 消息可在全球任何区域生产和消费 |
| 强一致性 | 保证至少一次投递,支持精确一次处理 |
| 实时分析集成 | 无缝对接BigQuery等数据分析服务 |
| 适用场景 | 全球分布式系统、实时分析管道 |
4. Alibaba Cloud MQ
| 特点 | 说明 |
|---|---|
| 多协议支持 | 兼容RabbitMQ、RocketMQ和Kafka协议 |
| 金融级可靠 | 提供金融级消息可靠性保证 |
| 全链路追踪 | 支持消息生产、存储、消费全链路追踪 |
| 适用场景 | 阿里云上的金融、电商等关键业务系统 |
-
需要复杂路由 → RabbitMQ
-
超高吞吐日志 → Kafka
-
金融交易场景 → RocketMQ
-
云原生/多租户 → Pulsar
-
全托管服务 → AWS SQS/Azure Service Bus
-
传统Java EE → ActiveMQ
五、rabbitmq的搭建过程
docker下安装配置rabbitmq
1、拉取镜像
docker pull rabbitmq:latest
docker pull rabbitmq:3.9.0-management
2、创建并启动容器
docker run -id --name rabbitmq -p 5672:5672 -p 15672:15672 -v /etc/rabbimq:/etc/rabbitmq rabbitmq:3.9.0-management
3、查看容器状态
docker ps如果容器状态显示为Up,并且端口映射正确,那么RabbitMQ服务已经成功启动。
4、查看容器日志
docker logs rabbitmq访问RabbitMQ管理界面
5、创建用户赋权
# 进入容器
docker exec -it rabbitmq bash#启用 RabbitMQ 的管理控制台插件
rabbitmq-plugins enable rabbitmq_management
# 在容器内执行
rabbitmqctl add_user admin 123456
rabbitmqctl set_user_tags admin administrator
rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"
6、使用浏览器打开RabbitMQ管理界面。
默认情况下,管理界面端口为15672。在浏览器地址栏输入以下URL:
http://<宿主机IP地址>:15672
六、rabbitmq相关角色
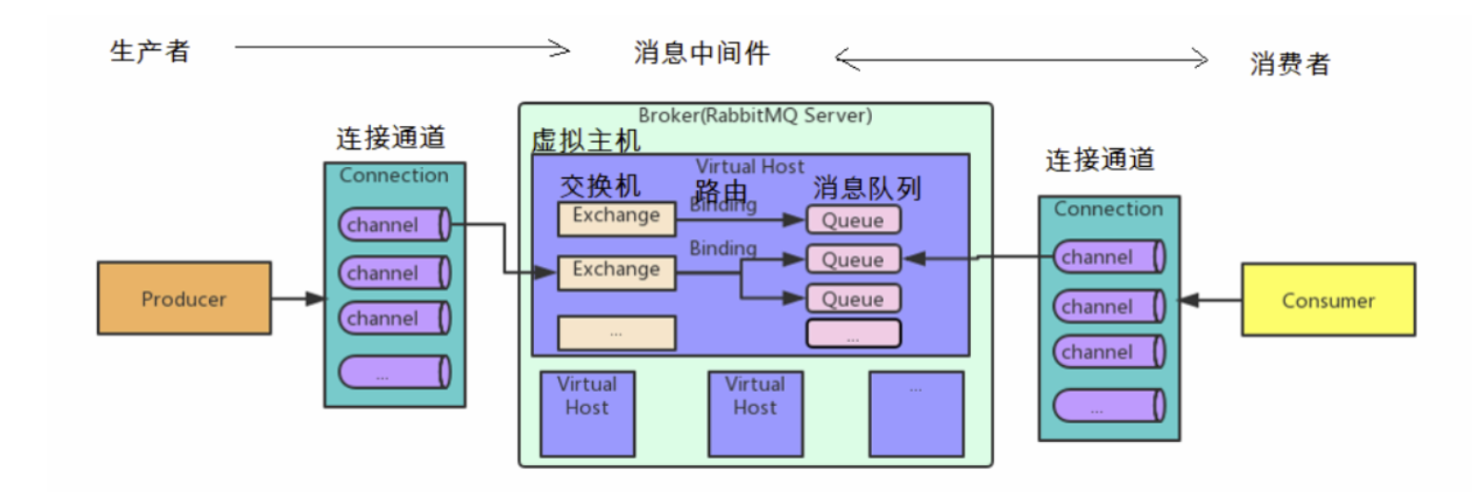
RabbitMQ 中重要的角色有:生产者、消费者和代理:
生产者:消息的创建者,负责创建和推送数据到消息服务器;
消费者:消息的接收方,用于处理数据和确认消息;
代理:就是 RabbitMQ 本身,用于扮演“快递”的角色,本身不生产消息,只是扮演“快递”的角色。
七、rabbitmq内部组件
1、ConnectionFactory(连接管理器):应用程序与Rabbit之间建立连接的管理器,程序代码中使用。
2、Channel(信道):消息推送使用的通道。
3、Exchange(交换器):用于接受、分配消息。
4、Queue(队列):用于存储生产者的消息。
5、RoutingKey(路由键):用于把生成者的数据分配到交换器上。
6、BindingKey(绑定键):用于把交换器的消息绑定到队列上。
八、生产者发送消息的过程?
发送消息的核心步骤
-
建立连接
-
创建通道
-
声明交换机/队列(可选)
-
发布消息
-
处理确认(可选)
-
关闭连接
首先客户端必须连接到 RabbitMQ 服务器才能发布和消费消息,客户端和 rabbit server 之间会创建一个 tcp 连接,一旦 tcp 打开并通过了认证(认证就是你发送给 rabbit 服务器的用户名和密码),你的客户端和 RabbitMQ 就创建了一条 amqp 信道(channel),信道是创建在“真实” tcp 上的虚拟连接,amqp 命令都是通过信道发送出去的,每个信道都会有一个唯一的 id,不论是发布消息,订阅队列都是通过这个信道完成的。
九、消费者接收消息过程?
-
建立连接和通道
-
声明队列(可选)
-
设置QoS(服务质量控制)
-
注册消费者
-
消息处理
-
发送确认(ACK/NACK)
-
处理失败消息
十、springboot项目中如何使用mq?
3.1引入jar包
spring-boot-starter-amqp.jarspring-boot-starter-web.jar
3.2application.yml配置
连接rabbitmq下相关信息
host
port
username
password
virtualHost
3.3使用rabbitmq模版工具类 rabbitTemplate amqpTemplate
发送消息方法
send接收消息 注解controller控制层类上,添加注解可以实时接收消息@RabbitListener
receive
3.4细化
项目启动时,自动创建交换机、创建队列、指定交换机和队列的绑定
十一、如何保障消息不丢失?
1、发送阶段:发送阶段保障消息到达交换机 事务机制|confirm确认机制
2、存储阶段:持久化机制 交换机持久化、队列的持久化、消息内容的持久化
3、消费阶段:消息的确认机制 自动ack|手动ack
接收方消息确认机制
自动ack|手动ack
spring:rabbitmq:host: 主机号port: 5672username: adminpassword: 123456virtual-host: /yan3listener:simple:acknowledge-mode: manualdirect:acknowledge-mode: manualpackage com.hl.rabbitmq01.web;
import com.rabbitmq.client.Channel;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@RestController
@RequestMapping("/c")
public class ConsumerController {
@RabbitListener(queues = {"topicQueue01"})public void receive(Message message, Channel channel) throws IOException {String msg = new String(message.getBody());System.out.println(msg);//业务逻辑 比如传入订单id,根据订单id,减少库存、支付等,// 如果操作成功,确认消息(从队列移除),如果操作失败,手动拒绝消息if(msg.length() >= 5){//确认消息channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);}else{//拒绝消息 not ack// 第三个参数:requeue:重回队列。如果设置为true,则消息重新回到queue,broker会重新发送该消息给消费端channel.basicNack(message.getMessageProperties().getDeliveryTag(),false,false);
// channel.basicReject(message.getMessageProperties().getDeliveryTag(),true);}
}
}消息的持久化机制
交换机的持久化
队列的持久化
消息内容的持久化
package com.hl.rabbitmq01.direct;
import com.hl.rabbitmq01.util.MQUtil;
import com.rabbitmq.client.BuiltinExchangeType;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.MessageProperties;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/*
生产者 javaSE方式简单测试
发布订阅-------direct模型
生产者----消息队列----消费者*/
public class Producer {public static void main(String[] args) throws IOException, TimeoutException {//1、创建连接Connection connection = MQUtil.getConnection();//2、基于连接,创建信道Channel channel = connection.createChannel();//3、基于信道,创建队列/*参数:1. queue:队列名称,如果没有一个名字叫simpleQueue01的队列,则会创建该队列,如果有则不会创建2. durable:是否持久化,当mq重启之后,消息还在3. exclusive:* 是否独占。只能有一个消费者监听这队列4。当Connection关闭时,是否删除队列autoDelete:是否自动删除。当没有Consumer时,自动删除掉5. arguments:参数。*/channel.queueDeclare("directQueue01", true, false, false, null);channel.queueDeclare("directQueue02", false, false, false, null);/*声明交换机参数1:交换机名称参数2:交换机类型*/channel.exchangeDeclare("directExchange01", BuiltinExchangeType.DIRECT,true);/*绑定交换机和队列参数1:队列名参数2:交换机名称参数3:路由key 广播模型 不支持路由key ""*/channel.queueBind("directQueue01","directExchange01","error");channel.queueBind("directQueue02","directExchange01","error");channel.queueBind("directQueue02","directExchange01","info");channel.queueBind("directQueue02","directExchange01","trace");//发送消息到消息队列/*参数:1. exchange:交换机名称。简单模式下交换机会使用默认的 ""2. routingKey:路由名称,简单模式下路由名称使用消息队列名称3. props:配置信息4. body:发送消息数据*/
channel.basicPublish("directExchange01","user", MessageProperties.PERSISTENT_TEXT_PLAIN,("Hello World ").getBytes());
//4、关闭信道,断开连接channel.close();connection.close();}
}package com.hl.rabbitmq01.web;
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.MessageProperties;
import org.springframework.amqp.core.AmqpTemplate;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
@RestController
@RequestMapping("/p")
public class ProducerController {@Autowiredprivate AmqpTemplate amqpTemplate;@Autowiredprivate RabbitTemplate rabbitTemplate;
@RequestMapping("/send")public void send(@RequestParam(defaultValue = "user") String key,@RequestParam(defaultValue = "hello") String msg) throws IOException {//amqpTemplate.convertAndSend("topicExchange", key, msg);
// rabbitTemplate.convertAndSend("topicExchange",key,msg);Channel channel = rabbitTemplate.getConnectionFactory().createConnection().createChannel(false); //false 非事务模式运行 无需手动提交channel.basicPublish("topicExchange", key,MessageProperties.PERSISTENT_TEXT_PLAIN,msg.getBytes());}
}
/*
创建交换机*/
@Bean
public TopicExchange topicExchange(){return ExchangeBuilder.topicExchange("topicExchange").durable(true) //是否支持持久化机制.build();
}
/*
创建队列*/
@Bean
public Queue queue(){return QueueBuilder.durable("topicQueue01").build();
}发送方的消息确认机制
1、事务机制
消耗资源
RabbitMQ中与事务有关的主要有三个方法:
-
txSelect() 开始事务
-
txCommit() 提交事务
-
txRollback() 回滚事务
txSelect主要用于将当前channel设置成transaction模式,txCommit用于提交事务,txRollback用于回滚事务。
当我们使用txSelect提交开始事务之后,我们就可以发布消息给Broke代理服务器,如果txCommit提交成功了,则消息一定到达了Broke了,如果在txCommit执行之前Broker出现异常崩溃或者由于其他原因抛出异常,这个时候我们便可以捕获异常通过txRollback方法进行回滚事务了。
示例
@RestController
public class RabbitMQController {
@Autowiredprivate RabbitTemplate rabbitTemplate;
@RequestMapping("/send")public String sendMessage(String message){rabbitTemplate.setChannelTransacted(true); //开启事务操作rabbitTemplate.execute(channel -> {try {channel.txSelect();//开启事务
channel.basicPublish("Fanout_Exchange","",null,message.getBytes());
int i = 5/0;
channel.txCommit();//没有问题提交事务}catch (Exception e){e.printStackTrace();channel.txRollback();//有问题回滚事务}
return null;});
return "success";}
}消费者没有任何变化。
通过测试会发现,发送消息时只要Broker出现异常崩溃或者由于其他原因抛出异常,就会捕获异常通过txRollback方法进行回滚事务了,则消息不会发送,消费者就获取不到消息。
2、confirm确认机制
推荐
同步通知
channel.confirmSelect(); //开始confirm操作
channel.basicPublish("Fanout_Exchange","",null,message.getBytes());
if (channel.waitForConfirms()){System.out.println("发送成功");
}else{//进行消息重发System.out.println("消息发送失败,进行消息重发");
}异步通知
channel.confirmSelect();
channel.addConfirmListener(new ConfirmListener() {//消息正确到达broker,就会发送一条ack消息@Overridepublic void handleAck(long l, boolean b) throws IOException {System.out.println("发送消息成功");}
//RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息@Overridepublic void handleNack(long l, boolean b) throws IOException {System.out.println("发送消息失败,重新发送消息");}
});
channel.basicPublish("Fanout_Exchange","",null,message.getBytes());十二、死信交换机和死信队列
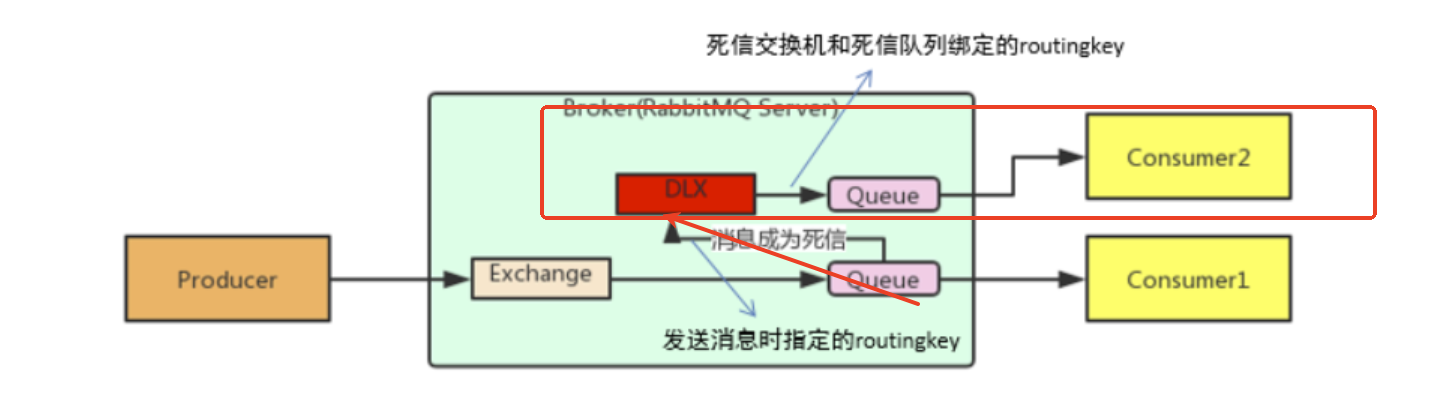
在实际开发项目时,在较为重要的业务场景中,要确保未被消费的消息不被丢弃(例如:订单业务),那为了保证消息数据的不丢失,可以使用RabbitMQ的死信队列机制,当消息消费发生异常时,将消息投入到死信队列中进行处理。
死信队列:RabbitMQ中并不是直接声明一个公共的死信队列,然后死信消息就会跑到死信队列中。而是为每个需要使用死信的消息队列配置一个死信交换机,当消息成为死信后,可以被重新发送到死信交换机,然后再发送给使用死信的消息队列。
死信交换机:英文缩写:DLX 。Dead Letter Exchange(死信交换机),死信交换机其实就是普通的交换机,通过给队列设置参数: x-dead-letter-exchange 和x-dead-letter-routing-key,来指向死信交换机
RabbitMQ规定消息符合以下某种情况时,将会成为死信
-
队列消息长度到达限制(队列消息个数限制);
-
消费者拒接消费消息,basicNack/basicReject,并且不把消息重新放入原目标队列,requeue=false;
-
原队列存在消息过期设置,消息到达超时时间未被消费;
死信消息会被RabbitMQ特殊处理,如果配置了死信队列,则消息会被丢到死信队列中,如果没有配置死信队列,则消息会被丢弃。
Map<String,Object> map = new HashMap<>();map.put("x-dead-letter-exchange","deadExchange");//当前队列和死信交换机绑定map.put("x-dead-letter-routing-key","user.#");//当前队列和死信交换机绑定的路由规则
// map.put("x-max-length",2);//队列长度map.put("x-message-ttl",10000);//队列消息过期时间,时间ms
// return QueueBuilder.durable("topicQueue01").build();return QueueBuilder.durable("topicQueue").withArguments(map).build();十三、延迟队列简介
延迟队列,即消息进入队列后不会立即被消费,只有到达指定时间后,才会被消费。

RabbitMQ中没有延迟队列,但是可以用ttl+死信队列方式和延迟插件两种方式来实现
ttl+死信队列
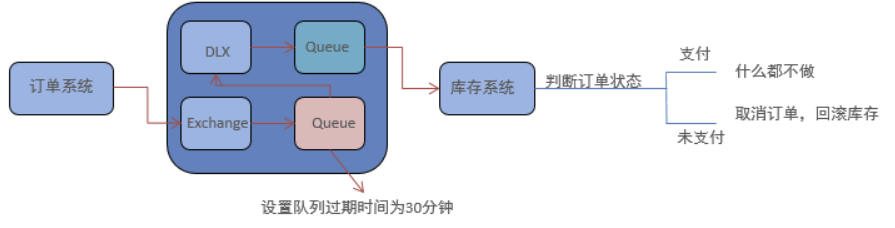
ttl+死信队列代码在讲死信队列时已经实现,这个不再阐述。
延迟插件
人们一直在寻找用RabbitMQ实现延迟消息的传递方法,到目前为止,公认的解决方案是混合使用TTL和DLX。rabbitmq_delayed_message_exchange插件就是基于此来实现的,RabbitMQ延迟消息插件新增了一种新的交换器类型,消息通过这种交换器路由就可以实现延迟发送。
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases