Ultralytics代码详细解析(四:engine->trainer.py 训练部分代码详解)
目录
- 引言
- 一、框架
- 二、
- 1. train()
- 2. _do_train()
- 3. _setup_train()
- 4. final_eval()
- 参考链接
- 感谢
引言
这一篇开讲代码,一方面为了理清代码思路、方便后续自己优化和修改功能,一方面为了提升python技能。该篇先从训练部分代码开始讲解,这毕竟是核心。
注:训练部分是指 Ultralytics代码详细解析(三:engine->trainer.py主框架)中的2.2节所涉及到的函数
一、框架

二、
1. train()
下面的代码每行都带有注释呦~~~
def train(self):"""训练入口函数,处理设备分配和分布式训练启动"""# 判断设备参数是否为非空字符串if isinstance(self.args.device, str) and len(self.args.device):# 计算GPU数量(用逗号分隔的设备ID数量)world_size = len(self.args.device.split(","))# 判断设备参数是否为列表或元组elif isinstance(self.args.device, (tuple, list)):# 直接获取列表长度作为GPU数量world_size = len(self.args.device)# 判断是否使用CPU或Apple MPS(Metal Performance Shaders)elif self.args.device in {"cpu", "mps"}:# 非GPU设备world_size设为0world_size = 0# 检查CUDA是否可用(未指定设备或指定为数字编号时)elif torch.cuda.is_available():# 默认使用单GPU(设备0)world_size = 1# 其他情况(无可用GPU且未指定设备)else:# 回退到CPU模式world_size = 0# 判断是否需要启动多进程分布式训练(GPU数量>1且不是从进程)if world_size > 1 and "LOCAL_RANK" not in os.environ:# 检查矩形训练参数是否开启if self.args.rect:# 打印警告并强制关闭(矩形训练与多GPU不兼容)LOGGER.warning("'rect=True' is incompatible with Multi-GPU training, setting 'rect=False'")self.args.rect = False# 检查是否启用自动批大小(batch<1)if self.args.batch < 1.0:# 打印警告并设置默认batch大小LOGGER.warning("'batch<1' for AutoBatch is incompatible with Multi-GPU training, setting default 'batch=16'")self.args.batch = 16# 生成分布式训练命令(torchrun命令)cmd, file = generate_ddp_command(world_size, self)try:# 打印完整的DDP执行命令LOGGER.info(f"{colorstr('DDP:')} debug command {' '.join(cmd)}")# 启动子进程执行分布式训练subprocess.run(cmd, check=True)except Exception as e:# 异常时抛出错误raise efinally:# 无论是否异常都执行清理(释放端口等资源)ddp_cleanup(self, str(file))# 单卡/CPU训练或分布式从进程执行路径else:# 进入实际训练流程self._do_train(world_size)
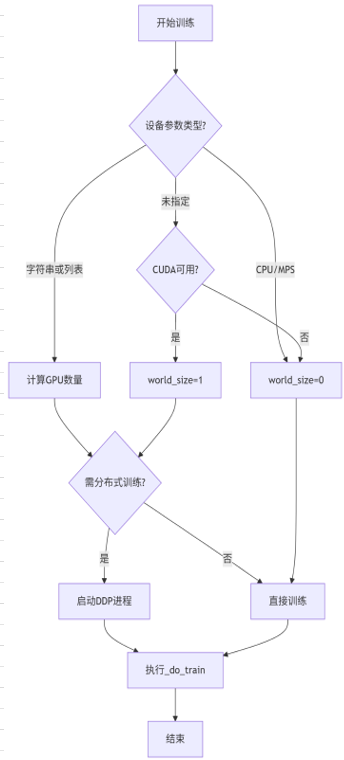
2. _do_train()
def _do_train(self, world_size=1):"""执行模型训练的主循环,支持单机/分布式训练"""# 如果是分布式训练(world_size > 1),初始化DDP环境if world_size > 1:self._setup_ddp(world_size)# 初始化训练环境(优化器/数据加载器等)self._setup_train(world_size)# 计算总批次数(一个epoch的迭代次数)nb = len(self.train_loader)# 计算warmup的迭代次数(至少100次)nw = max(round(self.args.warmup_epochs * nb), 100) if self.args.warmup_epochs > 0 else -1# 初始化 优化步计数器last_opt_step = -1# 记录训练开始时间self.epoch_time = Noneself.epoch_time_start = time.time()self.train_time_start = time.time()# 执行训练开始回调self.run_callbacks("on_train_start")# 打印训练配置信息LOGGER.info(f"Image sizes {self.args.imgsz} train, {self.args.imgsz} val\n"f"Using {self.train_loader.num_workers * (world_size or 1)} dataloader workers\n"f"Logging results to {colorstr('bold', self.save_dir)}\n"f"Starting training for " + (f"{self.args.time} hours..." if self.args.time else f"{self.epochs} epochs..."))# 如果启用close_mosaic,计算关闭mosaic增强的批次索引if self.args.close_mosaic:base_idx = (self.epochs - self.args.close_mosaic) * nbself.plot_idx.extend([base_idx, base_idx + 1, base_idx + 2])# 初始化epoch计数器epoch = self.start_epoch# 清空优化器梯度(防止恢复训练时梯度累积)self.optimizer.zero_grad()# 主训练循环while True:self.epoch = epoch# 执行epoch开始回调self.run_callbacks("on_train_epoch_start")# 忽略学习率调度器的警告with warnings.catch_warnings():warnings.simplefilter("ignore")# 更新学习率self.scheduler.step()# 设置模型为训练模式self._model_train()# 分布式训练时设置sampler的epochif RANK != -1:self.train_loader.sampler.set_epoch(epoch)# 准备进度条pbar = enumerate(self.train_loader)# 如果到达关闭mosaic的epoch,调整数据加载器if epoch == (self.epochs - self.args.close_mosaic):self._close_dataloader_mosaic()self.train_loader.reset()# 主进程显示进度条if RANK in {-1, 0}:LOGGER.info(self.progress_string())pbar = TQDM(enumerate(self.train_loader), total=nb)# 初始化损失记录self.tloss = None# 批次循环for i, batch in pbar:# 执行批次开始回调self.run_callbacks("on_train_batch_start")# Warmup阶段处理ni = i + nb * epoch # 累计迭代次数if ni <= nw:# 动态调整accumulate次数xi = [0, nw]self.accumulate = max(1, int(np.interp(ni, xi, [1, self.args.nbs / self.batch_size]).round()))# 调整学习率和动量for j, x in enumerate(self.optimizer.param_groups):x["lr"] = np.interp(ni, xi, [self.args.warmup_bias_lr if j == 0 else 0.0, x["initial_lr"] * self.lf(epoch)])if "momentum" in x:x["momentum"] = np.interp(ni, xi, [self.args.warmup_momentum, self.args.momentum])# 前向传播(使用自动混合精度)with autocast(self.amp):batch = self.preprocess_batch(batch)loss, self.loss_items = self.model(batch)self.loss = loss.sum()# 分布式训练时梯度求和if RANK != -1:self.loss *= world_size# 计算平均损失self.tloss = ((self.tloss * i + self.loss_items) / (i + 1) if self.tloss is not None else self.loss_items)# 反向传播self.scaler.scale(self.loss).backward()# 参数更新(达到accumulate次数时执行)if ni - last_opt_step >= self.accumulate:self.optimizer_step()last_opt_step = ni# 时间限制停止检查if self.args.time:self.stop = (time.time() - self.train_time_start) > (self.args.time * 3600)if RANK != -1:# 分布式环境下广播停止信号broadcast_list = [self.stop if RANK == 0 else None]dist.broadcast_object_list(broadcast_list, 0)self.stop = broadcast_list[0]if self.stop:break# 主进程日志记录if RANK in {-1, 0}:loss_length = self.tloss.shape[0] if len(self.tloss.shape) else 1pbar.set_description(("%11s" * 2 + "%11.4g" * (2 + loss_length)) % (f"{epoch + 1}/{self.epochs}",f"{self._get_memory():.3g}G",*(self.tloss if loss_length > 1 else torch.unsqueeze(self.tloss, 0)),batch["cls"].shape[0],batch["img"].shape[-1],))self.run_callbacks("on_batch_end")# 可视化采样if self.args.plots and ni in self.plot_idx:self.plot_training_samples(batch, ni)# 执行批次结束回调self.run_callbacks("on_train_batch_end")# 记录当前学习率self.lr = {f"lr/pg{ir}": x["lr"] for ir, x in enumerate(self.optimizer.param_groups)}# 执行epoch结束回调self.run_callbacks("on_train_epoch_end")# 主进程操作if RANK in {-1, 0}:final_epoch = epoch + 1 >= self.epochs# 更新EMA模型的属性self.ema.update_attr(self.model, include=["yaml", "nc", "args", "names", "stride", "class_weights"])# 验证阶段(满足条件时执行)if self.args.val or final_epoch or self.stopper.possible_stop or self.stop:self._clear_memory(threshold=0.5)self.metrics, self.fitness = self.validate()# 保存指标self.save_metrics(metrics={**self.label_loss_items(self.tloss), **self.metrics, **self.lr})# 检查早停条件self.stop |= self.stopper(epoch + 1, self.fitness) or final_epochif self.args.time:self.stop |= (time.time() - self.train_time_start) > (self.args.time * 3600)# 模型保存if self.args.save or final_epoch:self.save_model()self.run_callbacks("on_model_save")# 学习率调度器更新t = time.time()self.epoch_time = t - self.epoch_time_startself.epoch_time_start = t# 时间模式下的epoch数调整if self.args.time:mean_epoch_time = (t - self.train_time_start) / (epoch - self.start_epoch + 1)self.epochs = self.args.epochs = math.ceil(self.args.time * 3600 / mean_epoch_time)self._setup_scheduler()self.scheduler.last_epoch = self.epochself.stop |= epoch >= self.epochs# 执行fit结束回调self.run_callbacks("on_fit_epoch_end")# 清理显存(使用率>50%时)self._clear_memory(0.5)# 分布式环境下的停止信号同步if RANK != -1:broadcast_list = [self.stop if RANK == 0 else None]dist.broadcast_object_list(broadcast_list, 0)self.stop = broadcast_list[0]# 终止训练检查if self.stop:breakepoch += 1# 训练结束处理(仅主进程)if RANK in {-1, 0}:# 计算总训练时间seconds = time.time() - self.train_time_startLOGGER.info(f"\n{epoch - self.start_epoch + 1} epochs completed in {seconds / 3600:.3f} hours.")# 最终评估self.final_eval()# 绘制指标图表if self.args.plots:self.plot_metrics()# 执行训练结束回调self.run_callbacks("on_train_end")# 清理资源self._clear_memory()unset_deterministic()self.run_callbacks("teardown")
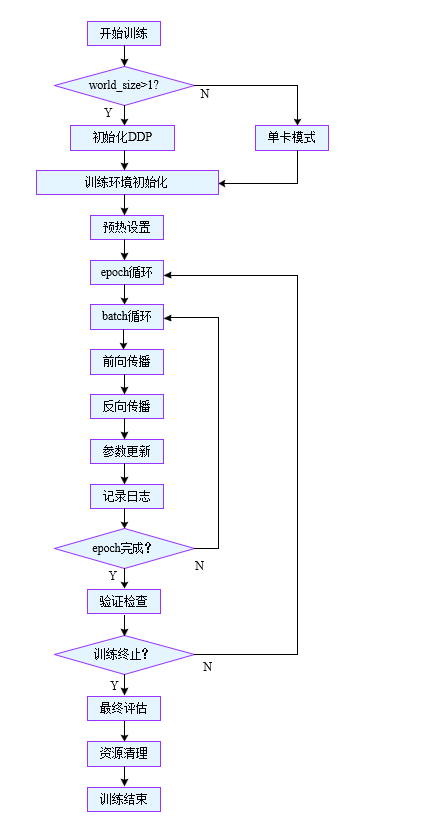
3. _setup_train()
def _setup_train(self, world_size):"""初始化训练环境,包括模型、数据加载器、优化器等"""# 执行预训练开始前的回调函数self.run_callbacks("on_pretrain_routine_start")# 加载或创建模型,并返回检查点信息ckpt = self.setup_model()# 将模型移动到指定设备(GPU/CPU)self.model = self.model.to(self.device)# 设置模型属性(如类别名等)self.set_model_attributes()# 处理需要冻结的层# 解析freeze参数,支持列表或整数形式freeze_list = (self.args.freezeif isinstance(self.args.freeze, list)else range(self.args.freeze)if isinstance(self.args.freeze, int)else [])# 始终冻结的层(如DFL层)always_freeze_names = [".dfl"]# 构建完整的冻结层名称列表freeze_layer_names = [f"model.{x}." for x in freeze_list] + always_freeze_namesself.freeze_layer_names = freeze_layer_names# 遍历模型所有参数for k, v in self.model.named_parameters():# 对冻结层设置requires_grad=Falseif any(x in k for x in freeze_layer_names):LOGGER.info(f"Freezing layer '{k}'")v.requires_grad = False# 对非冻结但原本未启用的浮点参数启用梯度elif not v.requires_grad and v.dtype.is_floating_point:LOGGER.warning(f"setting 'requires_grad=True' for frozen layer '{k}'")v.requires_grad = True# 检查是否启用混合精度训练(AMP)self.amp = torch.tensor(self.args.amp).to(self.device)# 在主进程上验证AMP可用性if self.amp and RANK in {-1, 0}:# 备份回调函数(因为check_amp会重置)callbacks_backup = callbacks.default_callbacks.copy()self.amp = torch.tensor(check_amp(self.model), device=self.device)# 恢复回调函数callbacks.default_callbacks = callbacks_backup# 分布式训练时广播AMP标志if RANK > -1 and world_size > 1:dist.broadcast(self.amp.int(), src=0)# 转换AMP标志为布尔值self.amp = bool(self.amp)# 初始化梯度缩放器(用于混合精度训练)self.scaler = (torch.amp.GradScaler("cuda", enabled=self.amp) if TORCH_2_4 else torch.cuda.amp.GradScaler(enabled=self.amp)# 分布式训练时包装模型if world_size > 1:self.model = nn.parallel.DistributedDataParallel(self.model, device_ids=[RANK], find_unused_parameters=True)# 检查输入图像尺寸# 计算网格大小(基于模型stride)gs = max(int(self.model.stride.max() if hasattr(self.model, "stride") else 32), 32)# 验证图像尺寸合法性self.args.imgsz = check_imgsz(self.args.imgsz, stride=gs, floor=gs, max_dim=1)self.stride = gs # 用于多尺度训练# 自动调整batch大小(单GPU模式)if self.batch_size < 1 and RANK == -1:self.args.batch = self.batch_size = self.auto_batch()# 准备数据加载器# 计算每个进程的batch大小batch_size = self.batch_size // max(world_size, 1)# 训练集数据加载器self.train_loader = self.get_dataloader(self.data["train"], batch_size=batch_size, rank=LOCAL_RANK, mode="train")# 主进程准备验证集if RANK in {-1, 0}:# 验证集数据加载器(batch可能加倍)self.test_loader = self.get_dataloader(self.data.get("val") or self.data.get("test"),batch_size=batch_size if self.args.task == "obb" else batch_size * 2,rank=-1,mode="val")# 初始化验证器self.validator = self.get_validator()# 准备评估指标metric_keys = self.validator.metrics.keys + self.label_loss_items(prefix="val")self.metrics = dict(zip(metric_keys, [0] * len(metric_keys)))# 初始化EMA(指数移动平均)模型self.ema = ModelEMA(self.model)# 绘制训练标签(如果启用)if self.args.plots:self.plot_training_labels()# 配置优化器# 计算梯度累积步数self.accumulate = max(round(self.args.nbs / self.batch_size), 1)# 调整权重衰减率weight_decay = self.args.weight_decay * self.batch_size * self.accumulate / self.args.nbs# 计算总迭代次数iterations = math.ceil(len(self.train_loader.dataset) / max(self.batch_size, self.args.nbs)) * self.epochs# 构建优化器self.optimizer = self.build_optimizer(model=self.model,name=self.args.optimizer,lr=self.args.lr0,momentum=self.args.momentum,decay=weight_decay,iterations=iterations)# 设置学习率调度器self._setup_scheduler()# 初始化早停机制self.stopper, self.stop = EarlyStopping(patience=self.args.patience), False# 恢复训练状态(如果存在检查点)self.resume_training(ckpt)# 设置调度器的初始epochself.scheduler.last_epoch = self.start_epoch - 1# 执行预训练结束回调self.run_callbacks("on_pretrain_routine_end")
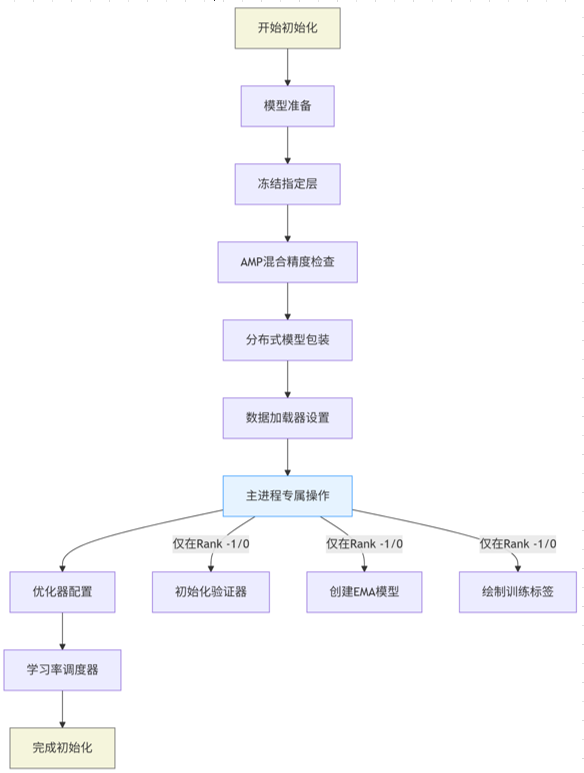
4. final_eval()
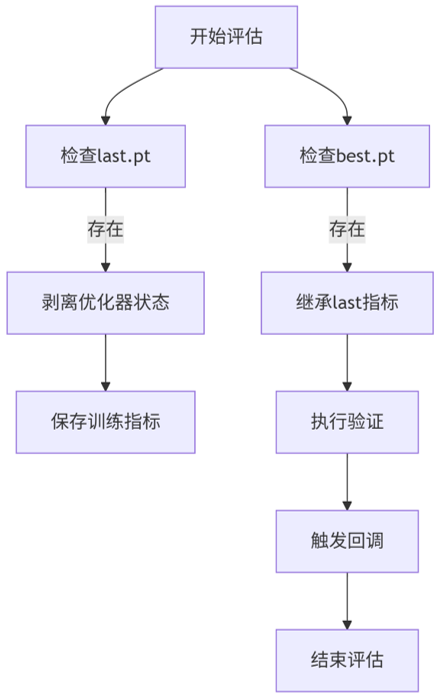
def final_eval(self):"""执行最终模型评估,包括最佳模型和最后模型的验证"""# 初始化检查点字典,用于存储模型信息ckpt = {}# 遍历最后模型(last.pt)和最佳模型(best.pt)for f in self.last, self.best:# 检查模型文件是否存在if f.exists():# 处理最后模型(last.pt)if f is self.last:# 移除优化器状态以减少文件大小ckpt = strip_optimizer(f)# 处理最佳模型(best.pt) elif f is self.best:# 定义需要从last.pt继承的键k = "train_results"# 移除优化器状态,可选更新训练指标strip_optimizer(f, updates={k: ckpt[k]} if k in ckpt else None)# 打印验证日志LOGGER.info(f"\nValidating {f}...")# 同步绘图参数设置self.validator.args.plots = self.args.plots# 使用验证器评估最佳模型self.metrics = self.validator(model=f)# 移除fitness指标(避免影响后续分析)self.metrics.pop("fitness", None)# 执行epoch结束回调self.run_callbacks("on_fit_epoch_end")
参考链接
无
感谢
终于出了第四篇
经过了周日单休和周一综合征…
俗话说的好
光学不练假把式
下一篇那就整起来练习吧
巩固巩固
感谢你特别邀请
来见证我的博文
我时刻提醒自己 别逃避~~~