【跨国数仓迁移最佳实践2】MaxCompute SQL执行引擎对复杂类型处理全面重构,保障客户从BigQuery平滑迁移
本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第二篇,跨国数仓迁移背后 MaxCompute 的统一存储格式创新。
注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
业务背景和痛点
随着大数据与AI时代的快速发展,全球数据总量已经突破了百ZB量级,其中半结构化(Json等)和嵌套数据结构(PB等)占比超50%,传统技术处理此类数据,面临存储成本高,计算效率低等问题日益凸显,亟需高效的性能优化技术。当前主流大数据处理引擎框架普通采用复杂数据类型(struct、map、array)来灵活处理半结构化等数据,相关功能支持和处理性能成为现代数据架构技术竞争焦点。
Google BigQuery和阿里云MaxCompute作为全球领先的商业化数据处理平台,均历经十余年产品和技术迭代。其中MaxCompute日均处理EB级数据和数千万作业,服务覆盖了全球多行业客户,因此也一直在持续丰富复杂类型的功能完备和性能优化。在GOTO项目从BigQuery迁移至MaxCompute的过程中,复杂数据类型的处理能力对标成为关键任务,需确保功能和性能持平甚至超越BigQuery,以实现作业平滑迁移与资源成本优化。
技术现状
简单介绍三种典型复杂数据类型特征和使用场景:
- Array类型: 一组同类型元素的集合(如array<bigint>),支持下标索引访问元素,广泛应用于存储和处理列表形式的数据,例如商品列表,多值属性等
- Map类型:键值对集合(如map<bigint, string>),支持通过键直接访问值,典型场景包括动态属性、键值配置等
- Struct类型: 包含多个字段的复合类型(如struct<id:bigint, value:string>),每个字段具有独立名称和类型,支持通过字段名访问元素,常用于用户画像标签、订单信息等
MaxCompute支持复杂类型的现有能力和瓶颈:
- 存储层:支持复杂类型列式存储(Aliorc文件格式),显著降低存储成本,具体用法参考官网介绍。
- 计算层: 支持行式复杂类型数据处理。尽管功能完备,但性能仍有较大优化空间。
由此可见,一条复杂类型数据处理,需经历列式读取,换转成行式计算,再转换成列式写入,多次转换开销巨大,并且大部分算子行式处理数据性能也较差,导致部分场景性能相比BigQuery存在一定的差距。
为彻底解决优化这些痛点,MaxCompute SQL执行引擎对复杂类型处理进行了全面重构,整体支持复杂类型列式的内存存储结构,对各个算子进行深度适配优化,整体处理性能实现质的飞跃,部分场景提升超10倍,基本追平Bigquery对复杂类型的计算处理性能,且在某些场景实现性能超越,最终保障了GOTO项目海量作业的平滑迁移,同时大幅节省计算资源。
技术方案简述
这里主要介绍两个核心优化重构,一个是复杂数据类型的计算优化重构,另一个是Unnest with subquery的框架优化重构,这两项优化在复杂类型场景普遍都带来1-10倍以上的性能提升。
列式复杂数据类型的计算优化重构
优化分成两个阶段:
- 各算子基于当前行式复杂类型结构持续优化计算逻辑,减少不必要的拷贝和计算。
- 将行式结果彻底改造成列式结构,并适配各算子列式计算模式。
行式复杂类型浅拷贝优化
现有算子接收到行式复杂类型的输入数据,进行计算后输出,需全量数据深拷贝,对于数据量大的复杂类型,开销极高。因此数据结构和处理过程进行深入优化,支持绝大部份处理流程进行浅拷贝优化,只要数据不发生变更,只需拷贝数据引用即可,不涉及数据本身的拷贝,优化覆盖表达式/聚合/Join/Window等主要算子,部分场景提升高达100倍+,效果显著。
复杂类型列式内存结构和计算优化重构
虽然行式优化取得了不少进展,但部分痛点依然存在,比如计算过程效率低下,无法高效适配向量化计算;计算过程中子元素列裁剪无法生效;每行数据的内存结构复杂,且需存储重复的辅助结构,严重制约整体计算性能。
为了显著提升性能,彻底改造复杂类型内存存储和计算框架,由行式转为列式内存结构,推动各个算子采用高效的列式计算思想适配优化,整体性能得到质的飞跃,部分场景提速超10倍。
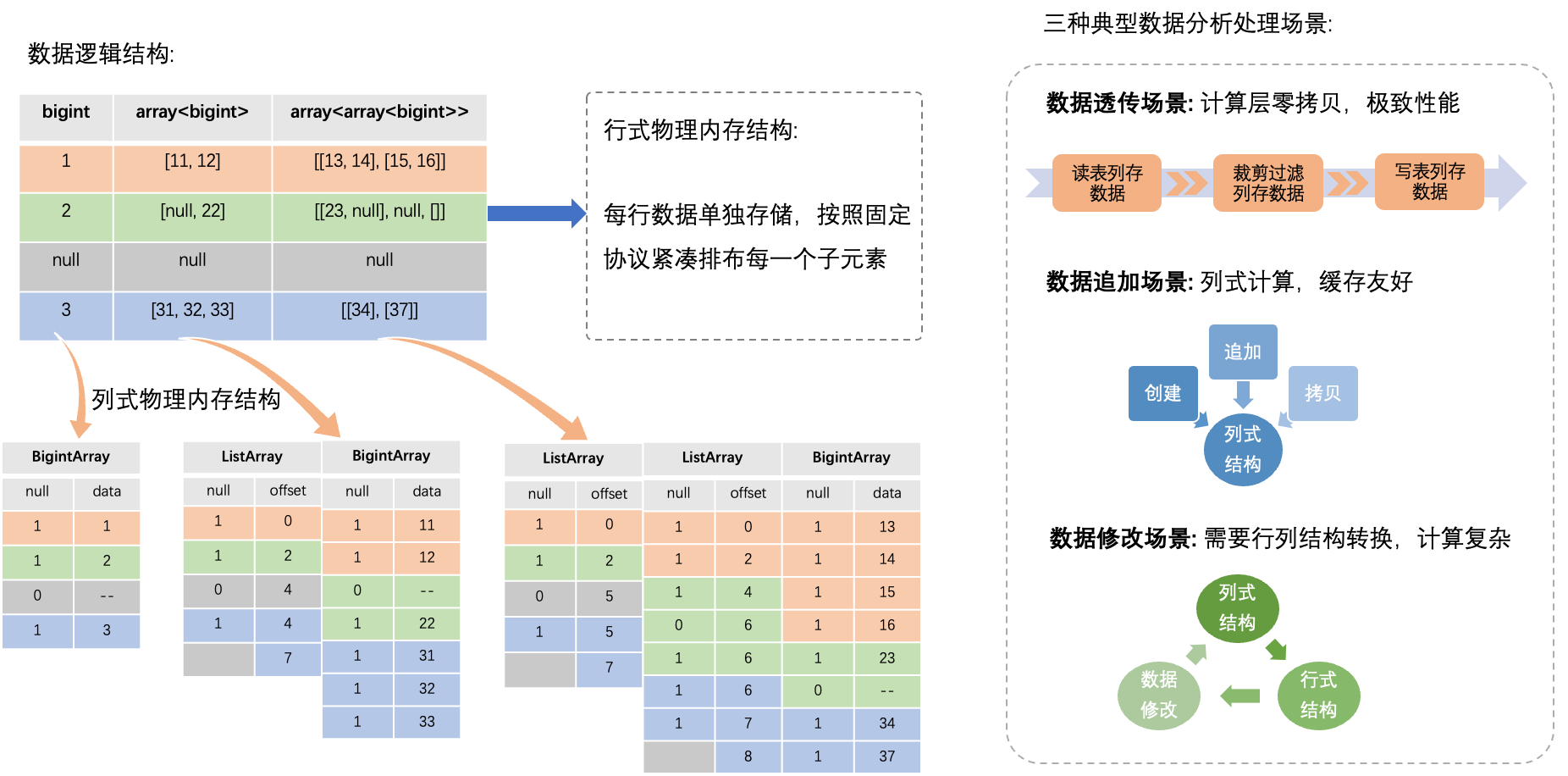
列式内存结构重构
如上图所示,重构之后,每行复杂类型数据不再单独存储,而且采用类arrow结构,对于Batch(多行数据集合)中某一列复杂类型,相同位置的子元素连续内存存储,因此每个Batch仅需存储一份辅助结构(如列名等),有效节省内存空间,而且子元素数据连续存储,内存访问效率也显著提升。
算子适配列式复杂类型计算
列式结果改造完成后,各SQL算子需进一步适配优化,由于行式和列式计算方式差异显著,此部分优化近乎完全重构,并针对不同场景进行了精细化适配。
列式复杂类型计算模式可分为以下三类:
- 数据透传模式: 数据从源表列式读取后,中间处理无变更,全程零拷贝传输,最后直接列式写入目标表,性能优化到极致。常见于数据搬迁,简单列裁剪数据清洗等场景。
- 数据追加模式: 算子一次性处理复杂类型数据后顺序输出到列式结构中,不会再次修改,可有效利用内存缓存优化和向量化处理提升整体性能。常见于表达式/Window/Join等主要算子。
- 数据修改模式: 算子需多次随机修改复杂类型数据,此模式不太适合列式内存结构,其存储的多行数据内存是连续的,如果随机修改中间某一行数据,可能破坏后继其他行数据的内存结构,因此此场景需退化成行式处理。常见于聚合函数处理等少数算子。
Unnest with subquery 的框架优化重构
BigQuery的Unnest(array)操作极为常见,输入参数通常是一个Array复杂类型,负责把Array中每一个子元素展开为一个单独行进行输出,GOTO项目大量任务使用此操作,迁移到MaxCompute之后,由于缺乏原生支持,需自动转换成等效的Lateral View + Explode操作来执行。但当Unnest嵌套于SQL子查询等较为复杂用法时,MaxCompute处理会变得极其复杂,性能急剧下降。
下面举个例子:
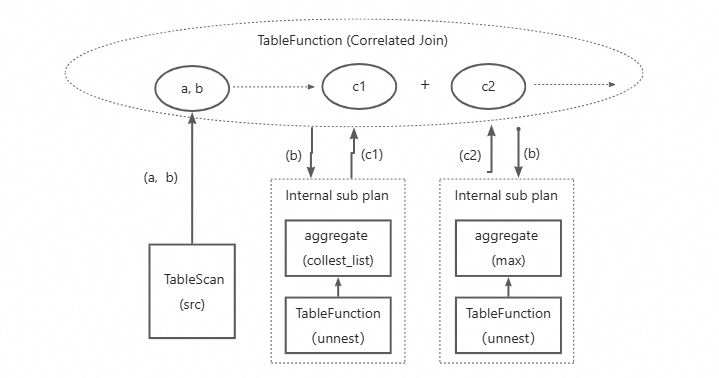
create table src(a bigint, b array<struct<c:bigint, d:string>>);select(select max(c) from unnest(b)),a+100,(select collest_list(d) from unnest(b) where d='test')
from src; 上述SQL示例中,MaxCompute执行时会转换成如下Plan来执行(示意图):

可见此Plan主要存在如下问题:
- 同一源表多次读取
- 相同unnest操作重复执行
- 需多次复杂Join拼接数据
因此如需大幅提升性能,需在语法解析,Plan构建,算子计算等各流程对此场景完全重构优化。
SQL Plan优化
为了优化上述三个问题,重构优化后的Plan如下图所示(示意图),
- 仅读取一次源表,按需把读取数据列推送至各Subquery计算
- 定义新的CorrelatedJoin操作,负责把每个Subquery定义成一个单独的internal subplan,然后按行对齐和拼接每个Subquery的计算输出列,整行输出,消除计算量很重的多次Join操作
- 定义新的internal subplan结构,本质是一棵OperatorTree, 并做针对性的Plan优化改造,如消除shuffle操作
- 对于多个subquery中相同Unnest操作,支持子树合并,消除冗余的unnest操作(在优化中)。
经过上述优化后,基本可解决之前的性能痛点,贴近性能最佳的计算Plan,后续还需要SQL执行层进行计算适配。
SQL执行层优化
主要负责执行物理Plan,并发处理数据,输出结果,优化重构主要分以下几步:
- 适配优化后的新物理Plan,解析为可执行算子
- 实现新CorrelatedJoin算子,负责驱动internal subplan执行,并且把各subplan执行的结果按行对齐和高效拼接,然后输出整行结果到后续算子执行
- 实现新的internal subplan数据处理框架,需支持按照每行复杂类型进行一次性处理和输出的语义,跟通用算子执行框架差异显著。
上线效果和业务价值
提升效果案例
列式复杂类型重构优化性能提升案例
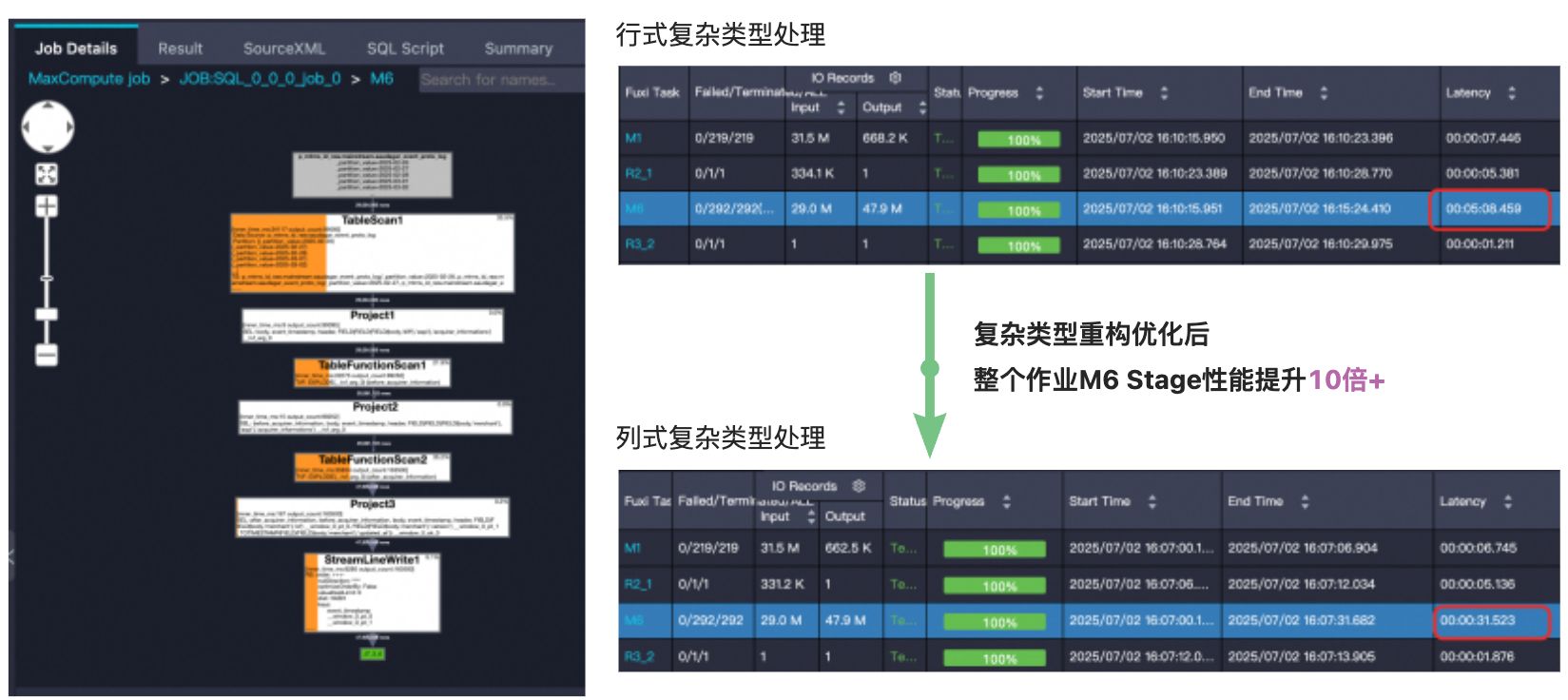
上图示例展示的是用户某个作业的其中一个Stage M6的处理过程,TableScan1从源表中读取了多层嵌套的复杂类型数据,经过了TableScan / Project / TableFunction / Shuffle等算子处理,基于行式复杂类型结构进行处理,M6 Stage整体耗时超过5分钟,切换到优化后的列式复杂类型处理,整体Stage耗时缩短到31秒,速度提升了10倍+,效果极为显著。
Unnest with subquery重构优化性能提升案例
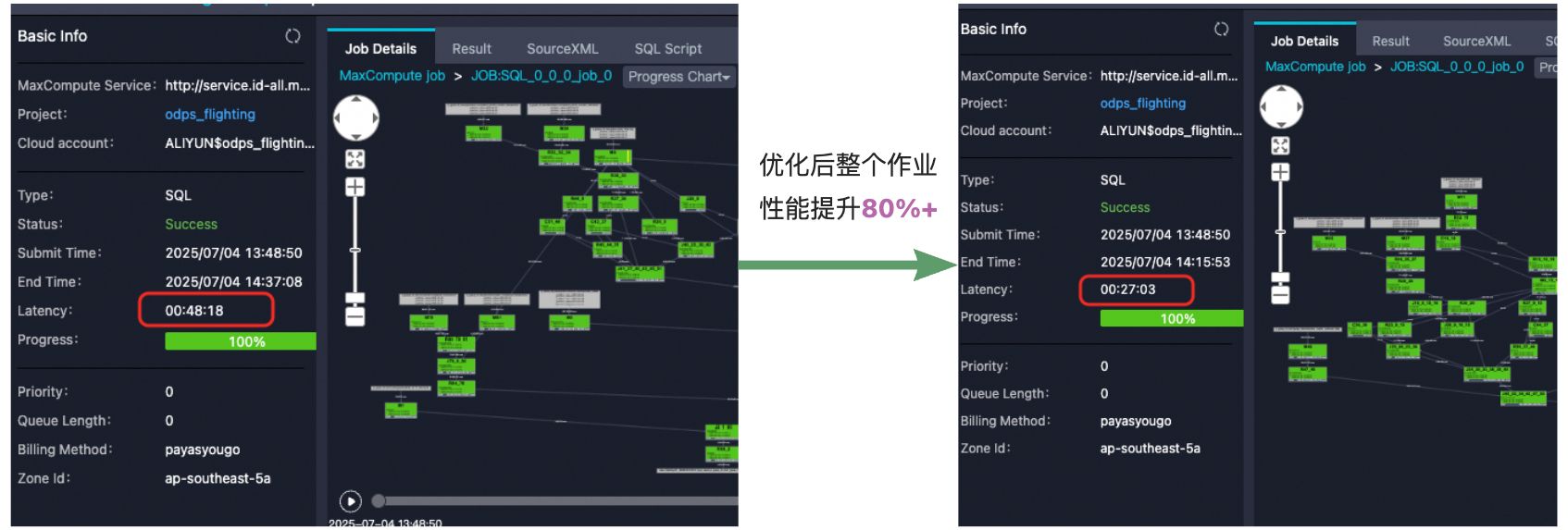
上图示例展示了用户某个作业经过Unnest With subquery重构优化后,整体作业性能提升了80%+,由于整体sql比较复杂,这个优化只涉及到其中部分stage,其中命中优化的算子提速3倍+,效果极为显著。
业务价值
GOTO整体项目,包含复杂类型的表数量超4万张,日均处理复杂类型的SQL作业超20万+,通过上述优化重构之后,大部分SQL性能提升20%~10倍+,日均减少2000+ Cpu Core消耗,极大的助力了GOTO项目按时保质的从Bigquery平滑迁移到MaxCompute,实现降本增效的目标。
后续会持续完善打磨列式复杂类型在各个场景的数据处理优化,并全面推广到MaxCompute平台所有业务场景中,预计全域上百万作业将显著受益,大幅节省业务计算成本,技术普惠到所有用户。