KOSMOS-2: 将多模态大型语言模型与世界对接
温馨提示:
本篇文章已同步至"AI专题精讲" KOSMOS-2: 将多模态大型语言模型与世界对接
摘要
我们介绍了 KOSMOS-2,一种多模态大型语言模型(MLLM),赋予了模型感知物体描述(例如,边界框)并将文本与视觉世界对接的新能力。具体而言,我们将引用表达式表示为 Markdown 中的链接形式,即 “文本片段”,其中物体描述是位置标记的序列。通过与多模态语料库的结合,我们构建了大规模的图像-文本对(称为 GRIT)数据,用于训练模型。除了现有的 MLLM 能力(例如,感知一般模态、遵循指令和执行上下文学习)外,KOSMOS-2 将对接能力集成到下游应用中。我们在广泛的任务上评估了 KOSMOS-2,包括:(i)多模态对接,例如引用表达式理解和短语对接;(ii)多模态引用,例如引用表达式生成;(iii)感知-语言任务;以及(iv)语言理解与生成。本研究为人体化 AI 的发展奠定了基础,并揭示了语言、多模态感知、行动和世界建模之间的大融合,这是迈向人工通用智能的关键步骤。代码和预训练模型可在 https://aka.ms/kosmos-2 获取。


1 引言
多模态大型语言模型(MLLMs)[HSD+22, ADL+22, HDW+23, DXS+23, Ope23] 在广泛的任务中成功地作为通用接口发挥了作用,包括语言、视觉和视觉-语言任务。MLLMs 可以感知一般模态,包括文本、图像和音频,并在zero-shot 和few-shot 设置下生成自由形式的文本响应。
在本工作中,我们解锁了多模态大型语言模型的对接能力。对接能力为视觉-语言任务提供了更便捷和高效的人机交互。它使用户能够直接指向图像中的物体或区域,而不是输入详细的文本描述来引用该物体,模型可以理解该图像区域及其空间位置。对接能力还使得模型能够以视觉答案(即边界框)作出响应,这支持更多的视觉-语言任务,如引用表达式理解。与仅使用文本的响应相比,视觉答案更准确,解决了共指歧义问题。此外,对接能力能够将生成的自由形式文本响应中的名词短语和引用表达式与图像区域相链接,从而提供更准确、更有信息性和更全面的答案。
我们介绍了 KOSMOS-2,这是一个具有对接能力的多模态大型语言模型,建立在 KOSMOS-1 基础上。KOSMOS-2 是一个基于 Transformer 的因果语言模型,使用下一个单词预测任务进行训练。为了启用对接能力,我们构建了一个大规模的图像-文本对数据集,并将其与 KOSMOS-1 中的多模态语料库结合,用于训练模型。这个对接的图像-文本对是基于 LAION-2B [SBV+22] 和 COYO-700M [BPK+22] 的图像-文本对子集构建的。我们构建了一个管道,提取并将文本片段(即名词短语和引用表达式)与其对应的图像区域的空间位置(例如,边界框)相链接。我们将边界框的空间坐标转换为一系列位置标记,然后将其附加到相应的文本片段后面。数据格式充当“超链接”,将图像的物体或区域与标题连接起来。
实验结果表明,KOSMOS-2 不仅在 KOSMOS-1 中评估的语言和视觉-语言任务上取得了竞争力的表现,而且在对接任务(短语对接和引用表达式理解)以及引用任务(引用表达式生成)上也取得了显著的成绩。如图 2 所示,集成对接能力使得 KOSMOS-2 可以用于更多的下游任务,如对接图像字幕和对接视觉问答。
2 构建大规模对接图像-文本对(GRIT)
我们介绍了 GRIT2,这是一个大规模的对接图像-文本对数据集,基于 COYO-700M [BPK+22] 和 LAION-2B [SBV+22] 的图像-文本对子集构建。我们构建了一个管道,将文本片段(即名词短语和引用表达式)与其对应的图像区域链接。该管道主要由两个步骤组成:生成名词短语-边界框对和生成引用表达式-边界框对。我们在下面详细描述这些步骤:
步骤 1:生成名词短语-边界框对
给定一个图像-文本对,我们首先从标题中提取名词短语,并使用预训练的检测器将它们与图像区域关联。如图 3 所示,我们使用 spaCy [HMVLB20] 来解析标题(“a dog in a field of flowers”),并提取所有名词短语(“a dog”,“a field”和“flowers”)。我们排除一些难以在图像中识别的抽象名词短语,如“time”,“love”和“freedom”,以减少潜在的噪声。随后,我们将图像和从标题中提取的名词短语输入到预训练的对接模型(例如 GLIP [LZZ+22])中,以获得相应的边界框。应用非极大抑制算法,以去除与其他边界框有较高重叠的边界框,即使它们并不是针对同一名词短语。我们保留预测置信度高于 0.65 的名词短语-边界框对。如果没有保留任何边界框,我们将丢弃相应的图像-标题对。
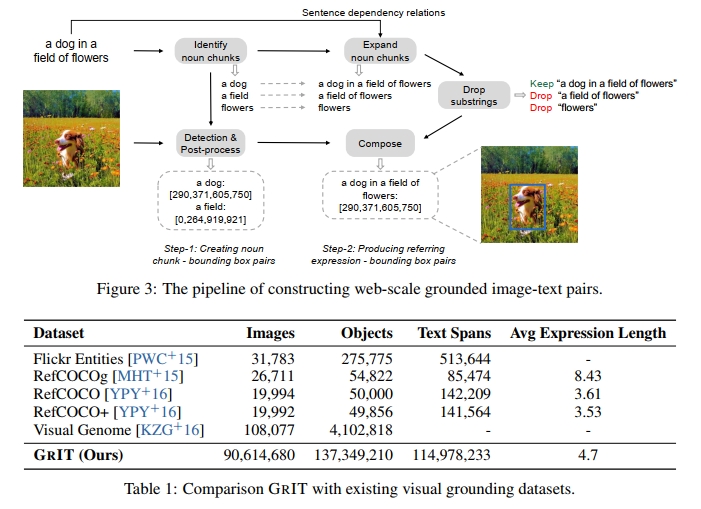
步骤 2:生成引用表达式-边界框对
为了赋予模型对复杂语言描述的对接能力,我们将名词短语扩展为引用表达式。具体来说,我们使用 spaCy 获取句子的依赖关系。然后,我们通过递归遍历名词短语在依赖树中的子节点,并将子节点的标记与名词短语连接,来扩展名词短语为引用表达式。我们不会将名词短语扩展为并列成分。如果名词短语没有子节点,我们会将其保留供下一个过程使用。图 3 中显示的例子中,名词短语 “a dog” 可以扩展为 “a dog in a field of flowers”,而名词短语 “a field” 可以扩展为 “a field of flowers”。
此外,我们只保留不被其他表达包含的引用表达式或名词短语。如图 3 所示,我们保留引用表达式 “a dog in a field of flowers”,并删除 “a field of flowers”(因为它是 “a dog in a field of flowers” 的蕴含),以及 “flowers”。我们将名词短语 (“a dog”) 的边界框分配给相应生成的引用表达式 (“a dog in a field of flowers”)。
最终,我们获得了大约 9100 万张图像、1.15 亿个文本片段和 1.37 亿个关联的边界框。我们将 GRIT 与现有公开可用的视觉对接数据集进行了比较,结果见表 1。GRIT 的数据样本显示在附录中。
3 KOSMOS-2: 一个具有关联的多模态大语言模型
KOSMOS-2 是一个具有关联能力的多模态大语言模型,相较于 KOSMOS-1,它集成了关联和引用能力。该模型可以接受用户通过边界框选择的图像区域作为输入,提供视觉答案(即边界框),并将文本输出与视觉世界进行对接。KOSMOS-2 采用与 KOSMOS-1 相同的模型架构和训练目标。我们将关联的图像-文本对加入训练数据,以赋予模型关联和引用能力。对于一个文本片段(例如名词短语和引用表达式)及其对应的边界框,我们将边界框的连续坐标离散化为一系列位置标记,并与文本标记以统一的方式进行编码。然后,我们通过一种“超链接”数据格式将位置标记和其对应的文本片段连接起来。模型被训练来建立图像区域和它们对应的位置信号之间的映射,并将图像区域与其关联的文本片段连接起来。
3.1 关联输入表示
给定一个文本片段及其在关联图像-文本对中的边界框,我们首先将边界框的连续坐标转化为一系列离散的位置信号 [CSL+21]。对于一个宽度为 W 和高度为 H 的图像,我们将宽度和高度分别均匀划分为 P 个部分。得到 P×PP × PP×P 个网格,每个网格由(W/P)×(H/P)( W / P ) \times ( H / P )(W/P)×(H/P) 个像素组成。对于每个网格,我们使用一个位置标记来表示该网格内的坐标。我们使用每个网格中心像素的坐标来确定图像上的边界框。总共引入 P×PP × PP×P 个位置标记,并将这些标记加入词汇表中,以便与文本进行统一建模。
边界框可以通过其左上角点(x1,y1).( x _ { 1 } , \; y _ { 1 } ) \, .(x1,y1). 和右下角点 (x2,y2).( x _ { 2 } , \ y _ { 2 } ) .(x2, y2). 来表示。我们将左上角和右下角的坐标分别离散化为位置标记。我们将左上角位置标记 、右下角位置标记 以及特殊边界标记 和 拼接起来,表示一个单独的边界框:“”。如果文本片段与多个边界框关联,我们使用特殊标记 将这些边界框的位置标记连接起来:“…”。
然后,我们将文本片段及其关联的位置标记以类似“超链接”的数据格式排列,像是 Markdown 格式。对于与单个边界框关联的文本片段,结果序列为:“ text span ”,其中 和 是指示文本片段开始和结束的特殊标记。该数据格式告诉模型,位于边界框内的图像区域与文本片段相关联。
对于图 1 中展示的示例,输入表示为:

其中,<s> 和 </s> 分别表示序列的开始和结束,<image> 和 </image> 表示图像嵌入的开始和结束。<grounding> 是一个特殊的标记,用于指示模型将文本输出与视觉世界进行关联。我们通过查找表将输入的文本标记和位置标记映射为嵌入向量。
与 KOSMOS-1 一样,我们使用一个视觉编码器(vision encoder)和一个重采样模块(resampler module)来获取输入图像的图像嵌入。
对于语言单模态数据、跨模态配对数据(即图像-文本对)以及交错多模态数据,我们使用与 KOSMOS-1 相同的输入表示方式。
3.2 基于锚定的多模态大语言模型
在 KOSMOS-1 的基础上,KOSMOS-2 通过引入锚定(grounding)和指代(referring)能力,增强了多模态大语言模型。KOSMOS-2 同样采用基于 Transformer 的因果语言模型(causal language model)作为主干结构,并通过下一 token 预测任务进行训练。
除了在 KOSMOS-1 中使用的多模态语料(包括文本语料、图像-字幕对以及图文交错数据),我们在训练中加入了锚定的图文对。训练损失只考虑离散 token,例如文本 token 和位置 token。模型可以通过位置 token 和整张图像来学习定位和理解图像区域,将文本片段与图像区域关联起来,并使用位置 token 输出图像区域的边界框(bounding boxes)。
KOSMOS-2 展示了新的锚定与指代能力。指代能力使我们能够通过边界框指出图像中的特定区域。KOSMOS-2 可以通过边界框的坐标理解用户所指的图像区域。指代能力提供了一种新的交互方式。不同于以往只能输出文本的多模态大语言模型(MLLMs)[ADL+22, HSD+22, HDW+23],KOSMOS-2 不仅可以提供视觉答案(即边界框),还能将文本输出锚定到图像上。锚定能力使模型能够提供更加准确、信息丰富且全面的响应。除了在 KOSMOS-1 中评估的视觉、语言和图文任务之外,该模型还可用于更多下游任务,例如锚定图像字幕生成、锚定视觉问答(VQA)、指代表达理解与生成等任务。
3.3 模型训练
训练设置
我们在新增的锚定图文对、单模态文本语料、图像-字幕对以及图文交错数据上训练模型。训练过程中的 batch size 为 419K 个 token,其中包括 185K 个来自文本语料的 token,215K 个来自原始及锚定图像-字幕对的 token,以及 19K 个来自图文交错数据的 token。我们将 KOSMOS-2 训练 60K 步,相当于约 250 亿个 token。优化器采用 AdamW,β = (0.9, 0.98),权重衰减(weight decay)设置为 0.01,dropout 率为 0.1。学习率在前 375 个 warm-up 步骤中线性上升至 2e-4,之后再线性衰减至 0。模型训练使用了 256 张 V100 GPU,整个训练过程约耗时一天。为了让模型能够识别何时将文本输出锚定到视觉世界中,我们在训练时会在锚定的字幕前加上 <grounding> token。
延续 KOSMOS-1 的设计,视觉编码器由 24 层构成,hidden size 为 1024,前馈网络(FFN)的中间层大小为 4096。多模态大语言模型部分采用 24 层 MAGNETO Transformer [WMH+22, MWH+22],其 hidden size 为 2048,注意力头数为 32,前馈网络中间层大小为 8192。可训练参数总量约为 16 亿。图像分辨率设为 224×224,patch 大小为 14×14。我们将图像的宽度与高度各划分为 32 个 bin,每个 bin 包含 7×7 像素,总共添加了 32×32 个位置 token 到词表中。KOSMOS-2 的初始化使用了 KOSMOS-1 的权重,新增的位置 token 的词嵌入随机初始化。在训练和指令微调过程中,我们更新所有参数。
指令微调(Instruction Tuning)
在模型训练完成后,我们对 KOSMOS-2 进行指令微调,使其更好地对齐人类指令。我们将视觉-语言指令数据集(如 LLaVA-Instruct [LLWL23])与语言指令数据集(如 Unnatural Instructions [HSLS22] 和 FLANv2 [LHV+23])结合起来,对模型进行微调。此外,我们还通过 GRIT 中的边界框与表达对(例如名词短语和指代表达)构造锚定的指令数据。对于表达-边界框对,我们使用“<p> expression </p>”作为输入指令,提示模型生成边界框对应的位置 token。我们还使用如“<p> It </p><box><loc1><loc2></box> is”的提示方式,要求模型根据边界框生成相应的表达。更多模板示例见附录中的表 B。
4 评估
我们首先在多模态grounding任务和多模态referring任务上评估KOSMOS-2,以验证其新增能力,然后在KOSMOS-1中评估过的语言任务和感知-语言任务上测试该模型。
- 多模态grounding
– 短语grounding
– 指代表达理解 - 多模态referring
– 指代表达生成 - 感知-语言任务
– 图像描述
– 视觉问答 - 语言任务
– 语言理解
– 语言生成

温馨提示:
阅读全文请访问"AI深语解构" KOSMOS-2: 将多模态大型语言模型与世界对接