论文笔记: Holistic Semantic Representation for Navigational Trajectory Generation
2025 AAAI
1 intro
- 随着全球定位系统(GPS)与地理信息系统(GIS)的快速发展,人类出行轨迹数量迅猛增长,极大推动了时空数据挖掘相关研究的进展,例如城市规划、商业选址以及出行时间估计
- 然而,由于隐私问题、政府监管)以及数据处理成本等诸多障碍,研究人员难以获得高质量的真实轨迹数据。
- 一种具有前景的替代方案,既满足隐私要求,又能生成多样化的高保真轨迹
- 这类轨迹能够产出与真实数据相似的分析结果,从而支持更广泛的研究与应用需求
- 除了传统的统计方法之外,深度学习也通过将人类出行的细粒度语义编码为高维表示,显著提升了轨迹生成的能力
- 已有一系列轨迹生成方法利用 RNN 和 CNN 来捕捉轨迹中的时空特征,同时结合各类生成模型,如变分自编码器(VAE)、生成对抗网络(GAN)以及扩散模型
- 此外,另一类方法则通过嵌入道路网络的拓扑语义,将时空点之间的连通性纳入轨迹生成过程中
- 然而,由于经验丰富的司机往往能识别通往目的地的最快路径,现有方法在生成轨迹时常常忽略目的地对轨迹的影响,导致生成轨迹与实际情况偏离
- 目前仅有 TS-TrajGen在轨迹生成中同时引入了起点与终点信息,并基于 A* 算法进行建模
- 然而,TS-TrajGen 严格遵循 A* 算法原则,在双塔结构中分别建模轨迹层与道路层语义,限制了语义共享与端到端学习能力
- ——>论文提出了一种**整体语义表示(HOlistic SEmantic Representation,HOSER)**框架,用于导航轨迹生成
- 该方法采用自底向上的策略,首先通过将道路网络划分为分层拓扑结构,提取长程道路语义
- 接着,轨迹表示以多粒度方式编码,融合了时空动态与道路级语义
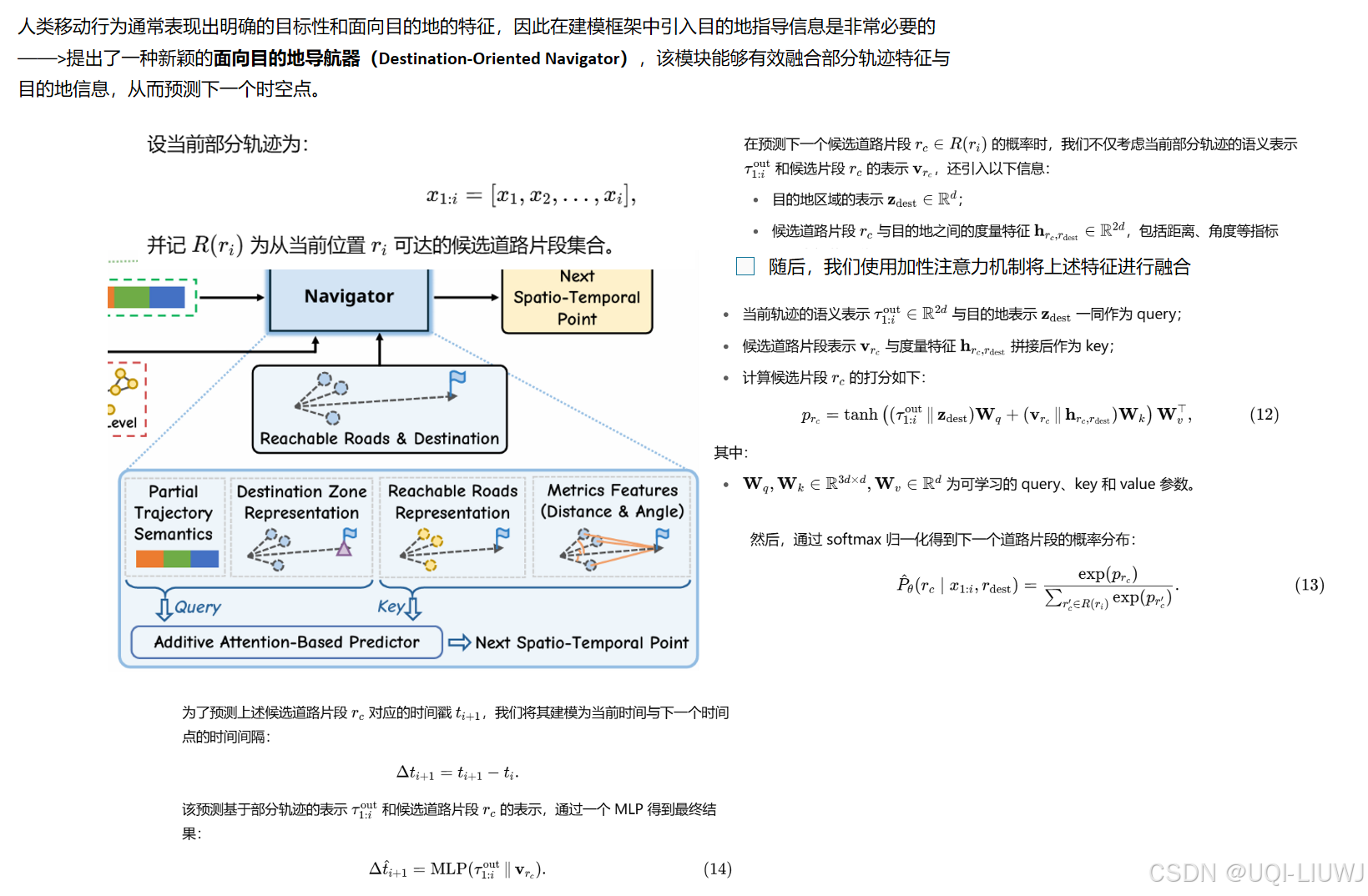
- 最终,在生成过程中,我们同时利用部分轨迹的语义上下文与目的地语义引导轨迹生成。
- 在生成阶段,HOSER 通过逐步生成的轨迹与目标位置,不断预测候选道路片段的概率
2 Preliminary
2.1 道路网络(Road Network)
- 道路网络表示为一个有向图
表示道路片段的集合(节点)
表示相邻道路片段之间的交叉口(边)
- 这里道路片段被定义为节点而非边,这遵循了以往研究中的通用设定
2.2 轨迹(Trajectory)
- 将一条轨迹表示为一系列时空点序列
- 每个时空点
是一个包含道路片段 ID 和时间戳的二元组
- 该序列确保每个道路片段
都可从前一个片段
到达,对于所有
成立
- 每个时空点
2.3 轨迹生成(Trajectory Generation)
- 给定一组真实轨迹
,轨迹生成任务的目标是学习一个以参数
控制的生成模型
- 给定一个三元组作为条件:起始道路片段、起始时间和目标道路片段
- 模型
能够生成一条合成轨迹
,满足
且
- 给定一个三元组作为条件:起始道路片段、起始时间和目标道路片段
2.4 人类移动建模(Human Movement Modeling)
- 将生成高质量轨迹的问题转化为建模人类移动策略
- 其中a是采取的动作,s是当前状态
- 状态s包含当前部分轨迹
和目标位置
- 动作a表示移动到当前可达的下一个道路片段
- 状态s包含当前部分轨迹
- 该策略可以表示为
- 其中a是采取的动作,s是当前状态
- 轨迹生成过程可以视为寻找具有最大概率的最优轨迹
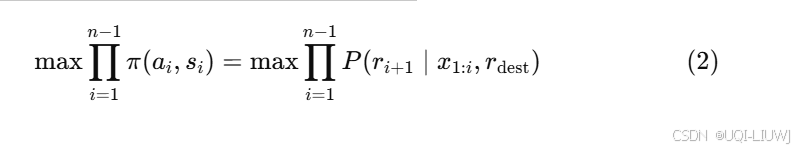
- 满足
- 任务是利用神经网络来估计移动策略
以及下一个时空点的时间戳
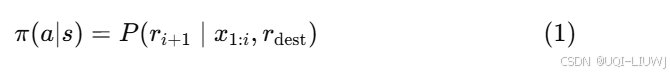
3 方法
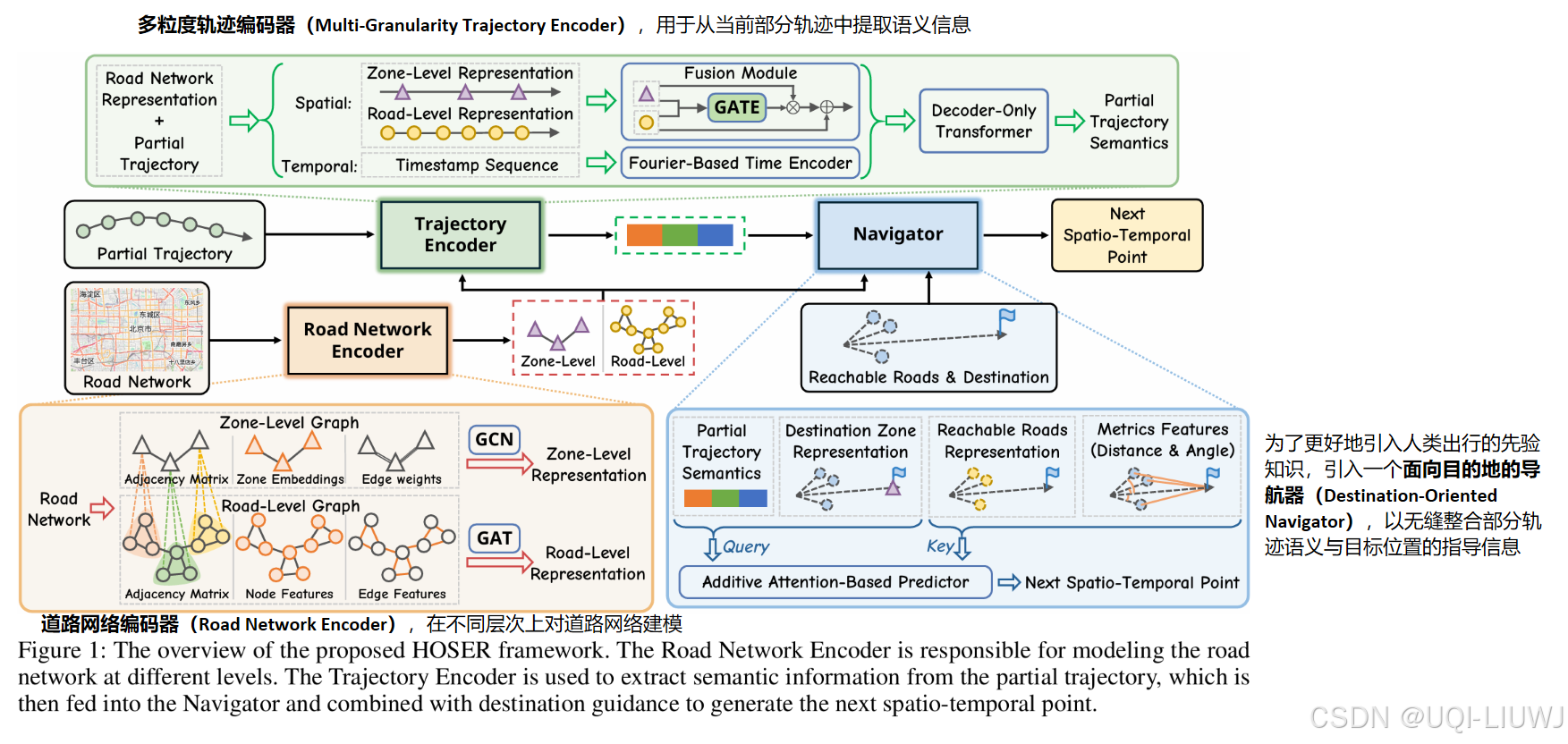
3.1 道路网络编码器(Road Network Encoder)
将道路网络中的道路片段作为图中的节点表示,相邻道路片段间的交叉口作为边进行建模。
道路网络编码器分别对道路片段和交叉口进行编码
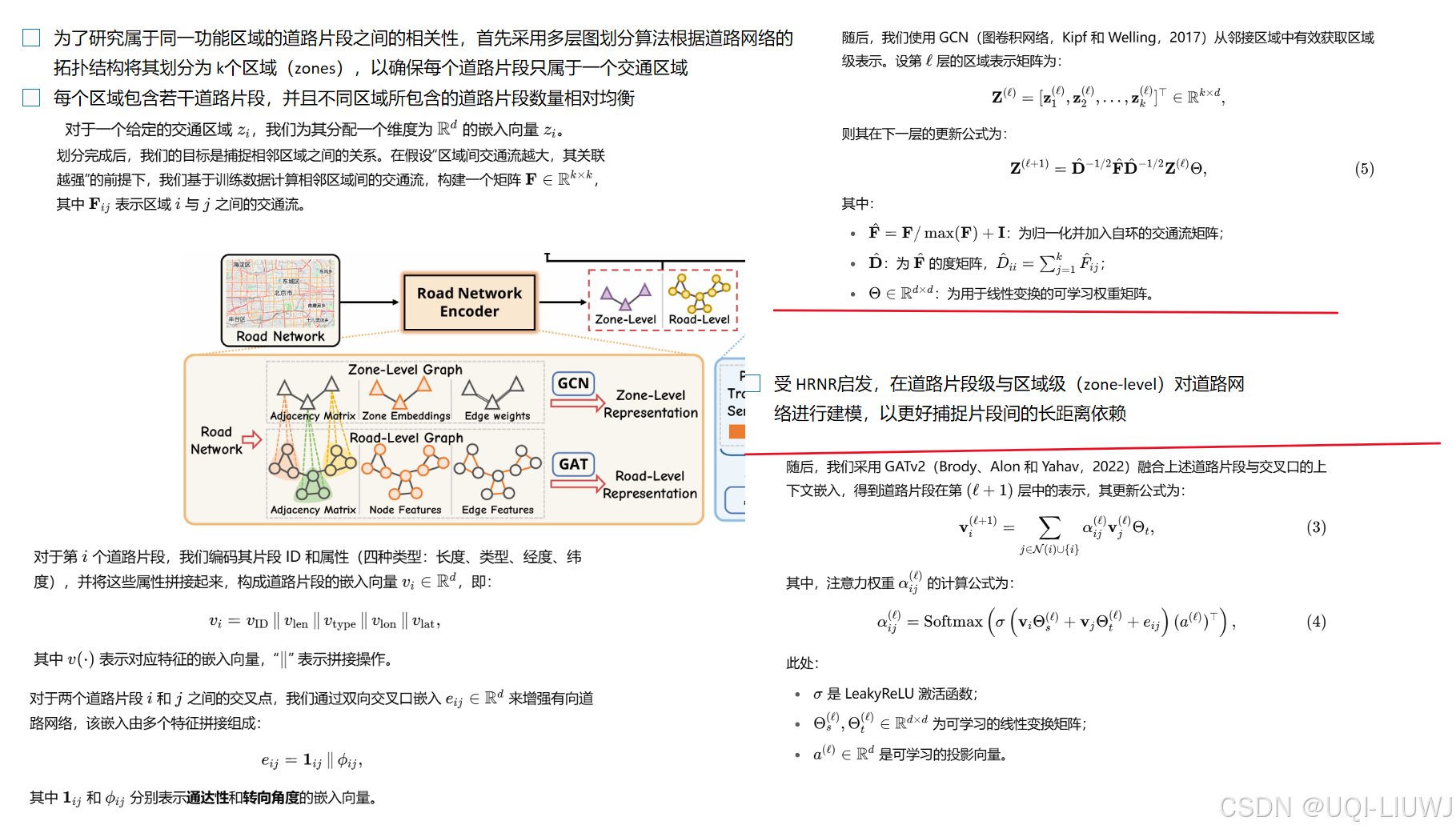
3.2 多粒度轨迹编码器(Multi-Granularity Trajectory Encoder)
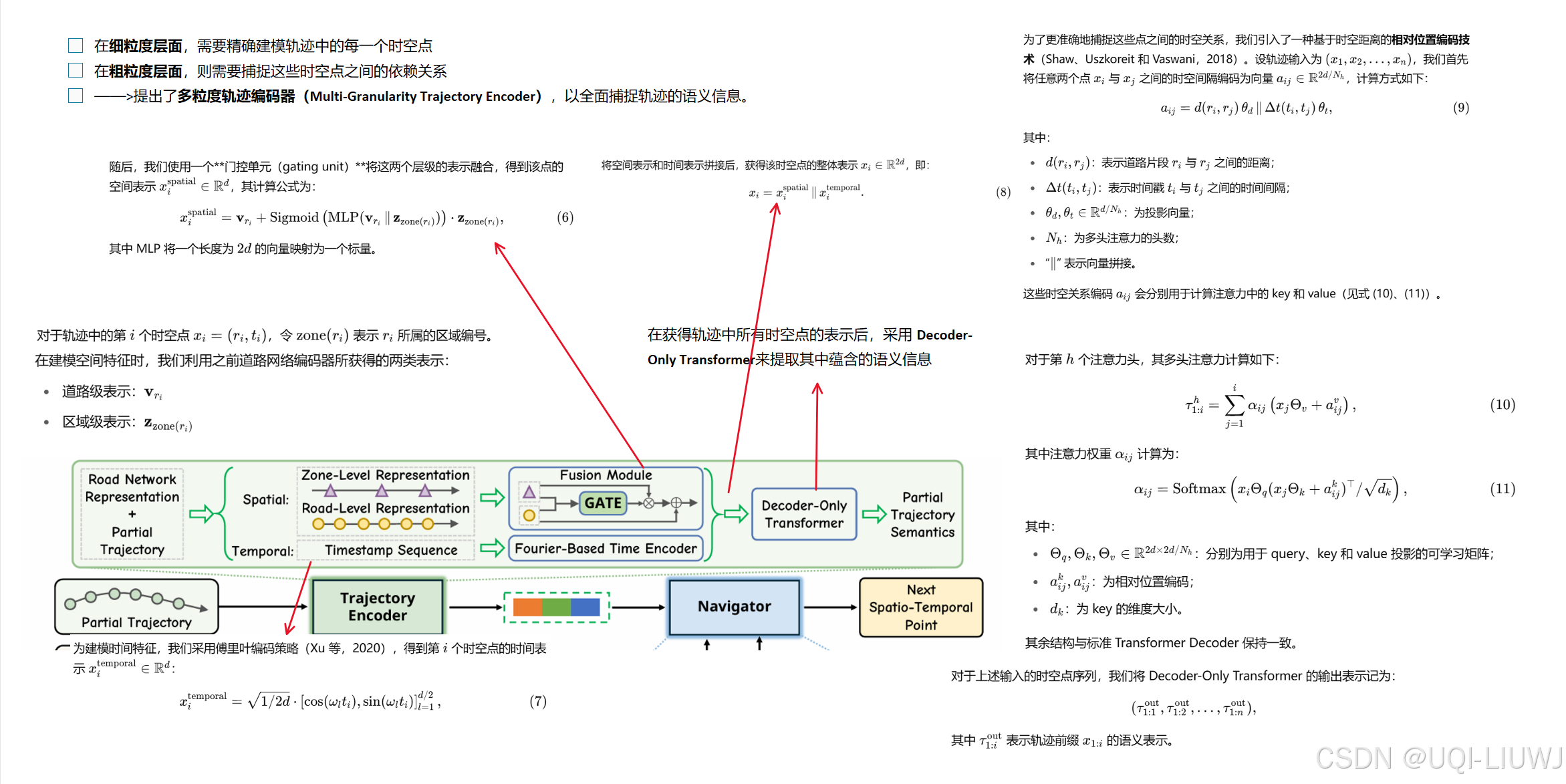
3.3 面向目的地的导航器(Destination-Oriented Navigator)
3.4 端到端学习(End-to-End Learning)
3.4.1 优化(Optimization)


3.4.2 生成(Generation)

4 实验
- 在三个真实世界的轨迹数据集上进行了大量实验
- 所有实验均在一块 NVIDIA RTX A6000 GPU 上完成
4.1 实验设置
4.1.1 数据集
- 在来自北京、波尔图(Porto)和旧金山的三个轨迹数据集上评估 HOSER 与多个基线方法的性能
- 每个数据集按 7:1:2 的比例随机划分为训练集、验证集和测试集
4.1.2 评估指标
- 从全局和局部两个角度比较 HOSER 与其他基线方法所生成轨迹与真实轨迹的相似度
全局视角:使用以下三个指标衡量轨迹的整体分布:
距离(Distance)
半径(Radius)
持续时间(Duration)
为获得量化结果,使用 Jensen-Shannon Divergence(JSD)评估这三个指标的分布相似性
局部视角:仅对具有相同起止点对(OD 对)的真实轨迹与生成轨迹进行比较,采用以下三个指标评估其相似性:
Hausdorff 距离
动态时间规整(DTW)
编辑距离(EDR)
4.1.3 baseline
传统方法:
Markov(Gambs, Killijian, and del Prado Cortez, 2012)
Dijkstra 算法(Dijkstra, 1959)
深度学习方法:
SeqGAN(Yu et al., 2017)
SVAE(Huang et al., 2019)
MoveSim(Feng et al., 2020)
TSG(Wang et al., 2021)
TrajGen(Cao and Li, 2021)
DiffTraj(Zhu et al., 2023b)
STEGA(Wang et al., 2024a)
TS-TrajGen(Jiang et al., 2023)
4.2 整体性能
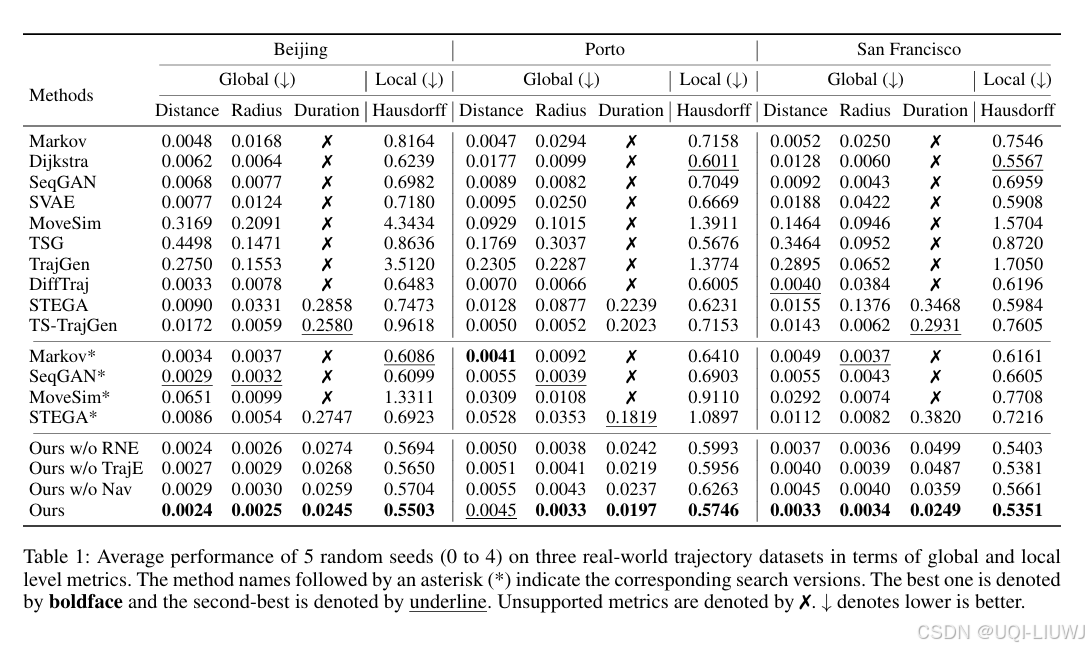
- 打*号的部分:
- 由于论文的方法和 TS-TrajGen 都采用基于搜索的策略,在给定 OD 对之间寻找最大概率路径,而非单纯依赖自回归方式逐点生成轨迹
- 对部分基线模型进行了修改,将其改为基于搜索的范式,以探究该策略对轨迹生成效果的影响
- 转换为搜索范式后,它们的性能在一定程度上得到了提升
- 然而,由于这些方法并未全面建模人类移动语义,而只是依赖部分轨迹去预测下一个时空点,它们与论文方法之间仍存在性能差距。
4.3 可视化分析
- 对包括 距离(Distance)、半径(Radius) 和 持续时间(Duration) 在内的指标分布进行了可视化
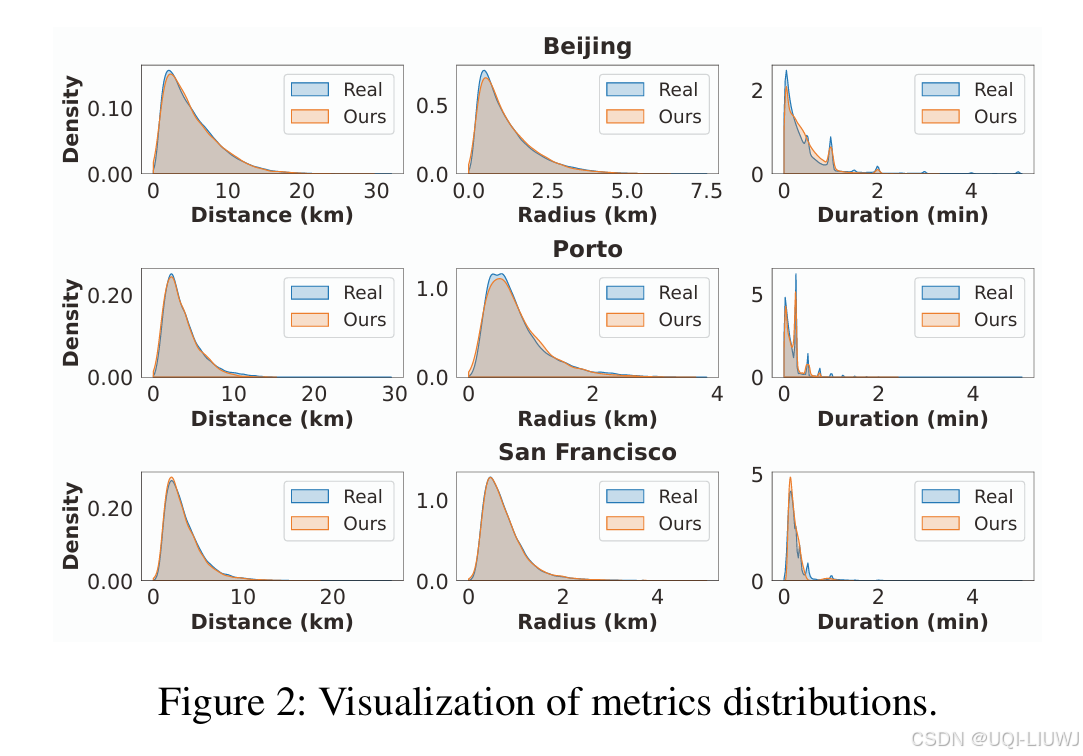
在 Distance 和 Radius 两个指标上,生成数据不仅捕捉到了分布峰值,还很好地对齐了真实数据的长尾分布;
在 Duration 指标上,合成数据成功复现了真实数据中的多峰特征,进一步验证了其可靠性。
此外,我们还对真实轨迹与生成轨迹本身进行了可视化,以便更直观地对比两者的形态
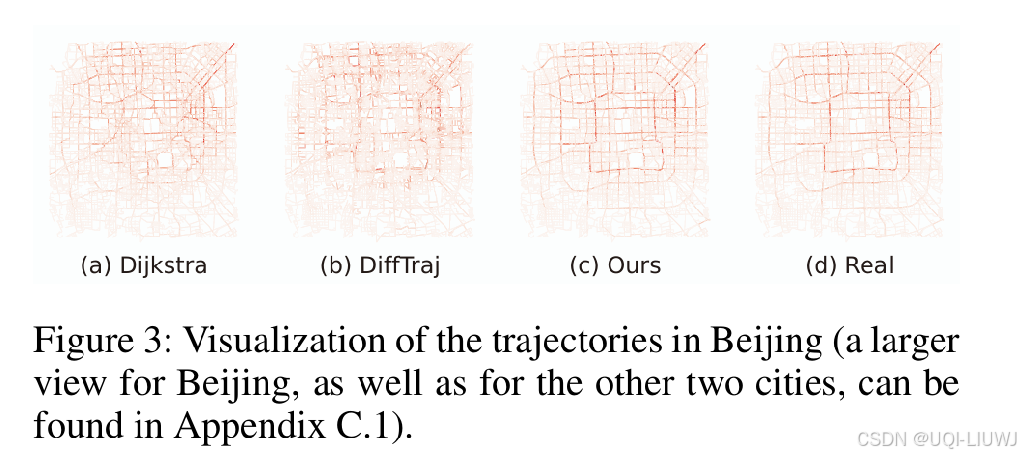
Dijkstra 算法直接使用 OD 对之间的最短路径来生成轨迹,因此其道路片段的访问频率分布较为均匀
DiffTraj 未能充分考虑道路网络的拓扑结构,导致生成轨迹与真实数据之间存在明显差异;
论文的方法几乎完美还原了原始轨迹,与真实数据高度吻合,显示出相比其他方法的显著提升
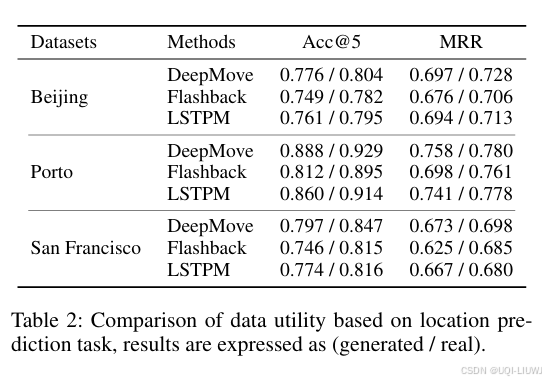
4.4 生成数据的实用性
- 由于生成轨迹最终的用途是分析人类出行模式,因此其应用价值决定了轨迹生成方法是否可行。
- 通过一个广泛使用的位置预测任务来评估所生成轨迹的实用性
使用真实数据和生成数据分别训练了三种先进的位置预测模型:
DeepMove(Feng et al., 2018)
Flashback(Yang et al., 2020)
LSTPM(Sun et al., 2020)
- DeepMove 和 LSTPM 在合成数据与真实数据上的表现基本相当,而 Flashback 略有偏差,原因在于其对时间戳信息的依赖性较强,表明仍存在改进空间
- 尽管如此,这些结果仍然表明:生成轨迹具备作为真实数据替代品的潜力