SQL 调优第一步:EXPLAIN 关键字全解析
目录
一、Explain核心概念
二、实战
2.1 简述功能
🔍什么是查询块?
2.2 详细解析
2.2.1 id--查询块的唯一序号
2.2.2 select_type--该查询块的类型
2.2.3 table--本次访问的表(或别名)
2.2.4 type--访问方式(性能等级)
2.2.5 possible_keys--可供选择的索引列表
2.2.6 key--实际使用的索引
2.2.7 key_len--所用索引的字节长度
2.2.8 ref--与索引列等值匹配的列或常量
2.2.9 rows--预估需扫描的行数
2.2.10 Extra--额外执行信息
一、Explain核心概念
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,而不是直接运行,开发者就可以通过对模拟的分析再决定是加索引、改写 SQL,还是调整表结构。
🧠根据对explain结果的分析,可以得到以下结果:
全表的读取顺序 →
id+table:决定多表 JOIN 时先读哪张表、后读哪张表。数据读取操作的操作类型 →
type:system / const / ref / range / ALL 等。哪些索引可以使用 →
possible_keys:优化器候选索引列表。哪些索引被实际使用 →
key:真正被采用的索引。表之间的引用 →
ref:显示当前表用到了哪张表的哪一列做等值匹配。每张表有多少行被优化器查询 →
rows:估计要扫描的行数。
二、实战
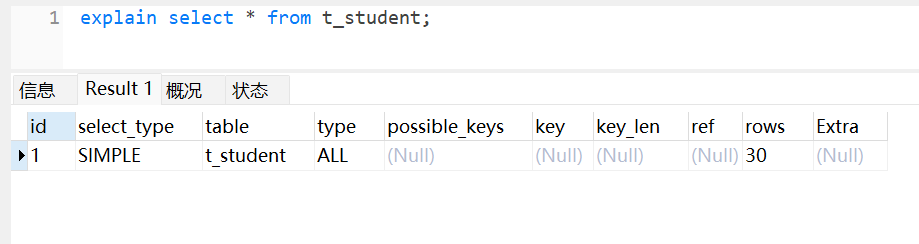
2.1 简述功能
| 字段 | 代表含义 |
|---|---|
| id | 查询块的唯一序号 |
| select_type | 该查询块的类型 |
| table | 本次访问的表(或别名) |
| type | 访问方式(性能等级) |
| possible_keys | 可供选择的索引列表 |
| key | 实际使用的索引 |
| key_len | 所用索引的字节长度 |
| ref | 与索引列等值匹配的列或常量 |
| rows | 预估需扫描的行数 |
| Extra | 额外执行信息 |
🔍什么是查询块?
查询块 = 语句树中每个独立 SELECT 的小节点。EXPLAIN 的 id 就是给这些节点按出现的先后顺序编号。
场景示例 包含几个查询块 SELECT * FROM t_student;1 SELECT * FROM t_student WHERE id IN (SELECT id FROM t_score);2(外层 1,子查询 1) SELECT * FROM t1 UNION SELECT * FROM t2;2(每个 UNION 分支 1) SELECT * FROM (SELECT * FROM t_student) AS s;2(派生表 1,外层 1)
2.2 详细解析
可以看出调用这个SQL语句后,得到了下面的行元素值,下面逐一分析:
2.2.1 id--查询块的唯一序号
💡详细说明
每个 SELECT 语句都会被分配一个唯一的 id
数字越大,执行顺序越靠前
id 相同表示这些查询块是同一级别的,执行顺序由上至下
id 为 NULL 表示这是一个结果集,不需要使用它来进行查询
2.2.2 select_type--该查询块的类型
💡详细说明
SIMPLE:简单查询(不包含子查询或 UNION)
PRIMARY:最外层的查询
SUBQUERY:子查询中的第一个 SELECT
DERIVED:派生表(FROM 子句中的子查询)
UNION:UNION 中第二个及以后的 SELECT
UNION RESULT:UNION 的结果
DEPENDENT SUBQUERY:依赖于外部查询的子查询
UNCACHEABLE SUBQUERY:结果不能被缓存的子查询
2.2.3 table--本次访问的表(或别名)
💡详细说明
- 显示表名或表的别名
如果是派生表,会显示为
<derivedN>,其中 N 是 id 值如果是 UNION 结果,会显示为
<unionM,N,...>
2.2.4 type--访问方式(性能等级)
💡详细说明(从最优到最差排序):
system:表只有一行记录(系统表)
const:通过主键或唯一索引一次就找到
eq_ref:关联查询中,使用主键或唯一索引关联
ref:使用非唯一索引扫描或唯一索引前缀扫描
fulltext:使用全文索引
ref_or_null:类似 ref,但包含 NULL 值的查询
index_merge:使用了索引合并优化
unique_subquery:IN 子查询中使用唯一索引
index_subquery:IN 子查询中使用非唯一索引
range:索引范围扫描
index:全索引扫描
ALL:全表扫描(最差情况)
2.2.5 possible_keys--可供选择的索引列表
💡详细说明:
显示可能应用在这张表中的索引
如果为 NULL,则表示没有可用的索引
实际查询时可能不会使用这些索引
2.2.6 key--实际使用的索引
💡详细说明:
显示 MySQL 实际决定使用的索引
如果为 NULL,则表示没有使用索引
可能出现在 possible_keys 中,也可能不出现(MySQL 优化器自行判断)
2.2.7 key_len--所用索引的字节长度
💡详细说明:
表示索引中使用的字节数
可计算查询中使用的索引长度(越短越好)
对于复合索引,可以判断使用了哪些部分
2.2.8 ref--与索引列等值匹配的列或常量
💡详细说明:
显示索引的哪一列被使用了
可能是一个常量(const)、列名或函数
如果为 NULL,表示没有引用
2.2.9 rows--预估需扫描的行数
💡详细说明:
MySQL 估计为了找到所需的行而要读取的行数
是一个预估值,不是精确值
对于 InnoDB 表,这个数字是估计值
2.2.10 Extra--额外执行信息
💡常见值及说明:
Using index:使用了覆盖索引(只需索引就能获取数据)
Using where:在存储引擎检索后再过滤
Using temporary:需要使用临时表
Using filesort:需要额外排序操作
Using join buffer:使用了连接缓存
Impossible WHERE:WHERE 子句始终为 false
Select tables optimized away:通过索引优化,可能不需要访问表