网络原理——UDP
传输层有两个核心协议:1. TCP 2. UDP
TCP的特点:有链接 , 可靠传输 ,面向字节流 , 全双工 UDP的特点:无连接 ,不可靠传输 , 面向数据报 , 全双工
(其中的不可靠传输,在代码中是不容易体现出来的,可以理解为发送了数据,就不管了)
学习UDP之前,我们得再谈谈端口号。
端口号
端⼝号(Port)标识了⼀个主机上进⾏通信的不同的应⽤程序;
其中服务器的端口是程序员指定的(提前制定好,客户端才能访问到)
客户端的端口是系统自动分配的空闲端口(如果提前指定了,可能会和你客户端的其他程序冲突)
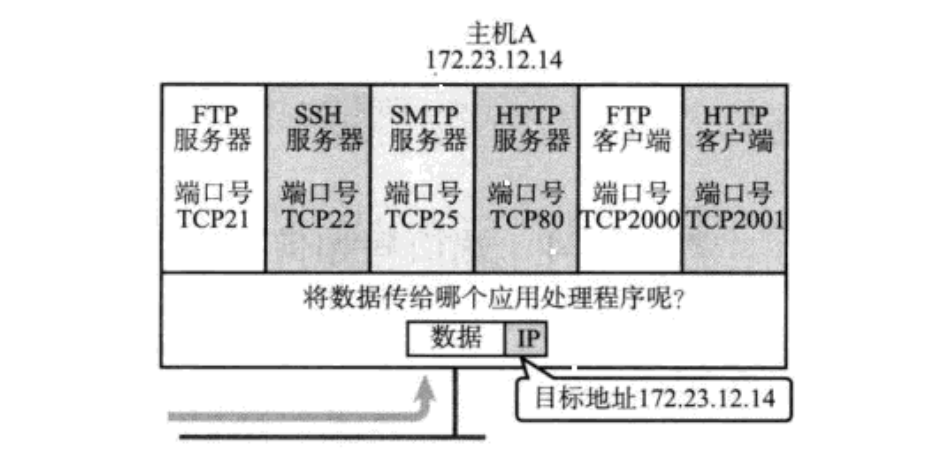
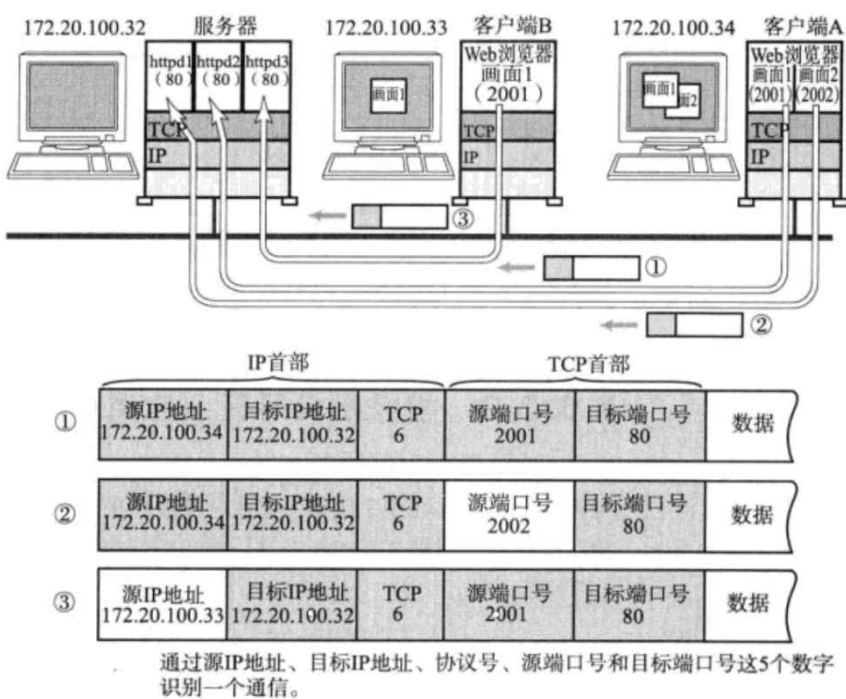
在TCP/IP协议中, ⽤ "源IP", "源端⼝号", "⽬的IP", "⽬的端⼝号", "协议号" 这样⼀个五元组来标识⼀个 通信(可以通过netstat -n查看);
端⼝号范围划分
端口号位两个字节,16比特位。一个端口号的取值范围,0 → 65535,实际上,一般把 1024 以下的端口保留,咱们写代码都是用 1024 → 65535 这个范围 。(如果设置端口号10W,就是非法的端口号)
- 0 - 1023: 知名端⼝号, HTTP, FTP, SSH等这些⼴为使⽤的应⽤层协议, 他们的端⼝号都是固定的.
- 1024 - 65535: 操作系统动态分配的端⼝号. 客⼾端程序的端⼝号, 就是由操作系统从这个范围分配的.
认识知名端⼝号(Well-Know Port Number)
有些服务器是⾮常常⽤的, 为了使⽤⽅便, ⼈们约定⼀些常⽤的服务器, 都是⽤以下这些固定的端⼝号:
- ssh服务器, 使⽤22端⼝
- ftp服务器, 使⽤21端⼝
- telnet服务器, 使⽤23端⼝
- http服务器, 使⽤80端⼝
- https服务器, 使⽤443
我们⾃⼰写⼀个程序使⽤端⼝号时, 要避开这些知名端⼝号
UDP协议
UDP协议端格式
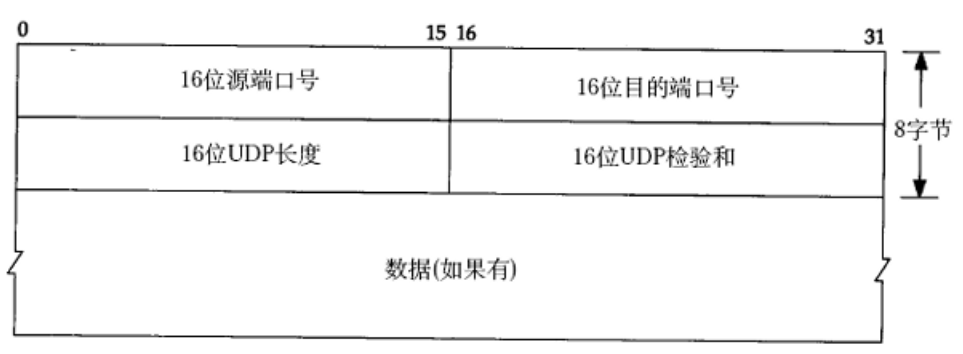
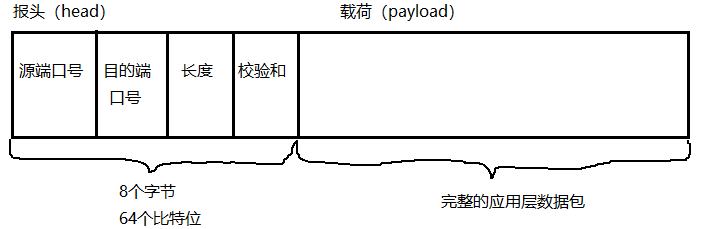
上图也可以这样子来表示:(HTTP的报头是文本格式的,UDP/TCP/IP的报头是二进制的)
16位UDP⻓度, 表⽰整个数据报(报头 + 载荷)的最⼤⻓度,长度属性,也是两个字节,表示范围是 0 → 65535 ,64kb(64kb放到30年前,当时已经很充裕了,放到现在,就是非常小的数字,随便一个图片就是几个MB);
- 此时就会产生一个问题:如何传输一个大的数据呢?
应用层代码做拆包操作。
一个大的应用层广告数据包,拆成多个小的包,使用多个UDP数据报传输。但这个工作量是比较大的,需要写大量的逻辑,实现此处的分包组包功能并且需要进行复杂的验证
TCP协议,没有数据包长度的限制。
- 此时就会产生一个问题:如何传输一个大的数据呢?
校验和:验证数据是否发生修改的手段。
如果说HTTPS的数字签名,是为了防止黑客篡改(防人),那么UDP的校验和,不是为了防人,和安全性无关,而是为了防止出现传输过程中的“比特翻转”
比特翻转:
二进制位 0→1 , 1→0 (光信号,电信号,电磁波受到外界干扰,可能回事高低电平/高低频光信号发生改变)
具体流程:
发送之前,先计算一个校验和,把整个数据包的数据都带入。
把数据和校验和一起发送给对端。
接收方收到之后重新计算一下校验和,和收到的校验和进行对比(UDP发现校验和不一致,就会直接丢弃,不会重发,如果想重发,要么使用 TCP,要么自己在写应用层代码中,自己来实现)
(UDP 的校验和使用了CRC方式来进行校验(循环冗余校验)把每个字节(除了校验和位置的部分之外),都当作整数,进行累加,溢出也没关系,继续加最终得到结果,crc校验和,传输到对端,数据出现错误了,对端再次计算的校验和,就会和第一个校验和不一样了)
(这里认为,两个原始数据相同,使用相同的校验和算法,得到个校验和也是相同的[ok]
反之,如果两个校验和相同,原始数据一定也相同[可能存在变数],例如:前一个字节出现bit 翻转,刚好小了1,后一个字节也出现bit翻转,刚好大了1,最终加到一起,校验和就是一样的)
本来比特翻转就是小概率事件,恰好两个翻转抵消了影响,更是小之又小的概率了。
UDP总长度最大是64KB,表述的时候这两种都对:
- UDP总长度达到 64KB 上限。
- UDP携带的载荷长度达到 64KB 上限(UDP报头,只有8个字节,8字节相对于64KB来说,非常小的数字, 65535-8 ⇒ 65528近似看成 64KB,也是没问题的)