为什么IoTDB成为物联网场景的技术优选?
在物联网、工业监控等领域,时序数据的高效管理成为技术架构设计的关键环节。时序数据库作为专门处理带时间戳数据的系统,其选型需兼顾性能、兼容性与场景适配性。本文将从技术角度解析 IoTDB 的设计理念与实践方法,为时序数据库选型提供参考。
目录
一、IoTDB 概述
二、时序数据库选型核心指标解析
三、架构设计精要
四、在工业场景的应用实践
五、开发实践
一、IoTDB 概述
IoTDB 是一款针对时序数据特性优化的开源数据库,其核心设计目标是解决大规模时序数据的存储、查询与管理问题。与通用数据库不同,它从数据模型到存储引擎均围绕时序数据的高写入、高查询、高压缩特性展开,适用于物联网设备监控、工业生产参数记录、环境监测等场景。
在数据组织方式上,IoTDB 采用面向设备层级的建模思路,可自然映射工业场景中的 "厂区 - 车间 - 设备 - 传感器" 层级关系,减少数据关联查询的复杂度。这种设计使其在多设备、多测点的场景中能保持高效的数据读写性能。
二、时序数据库选型核心指标解析
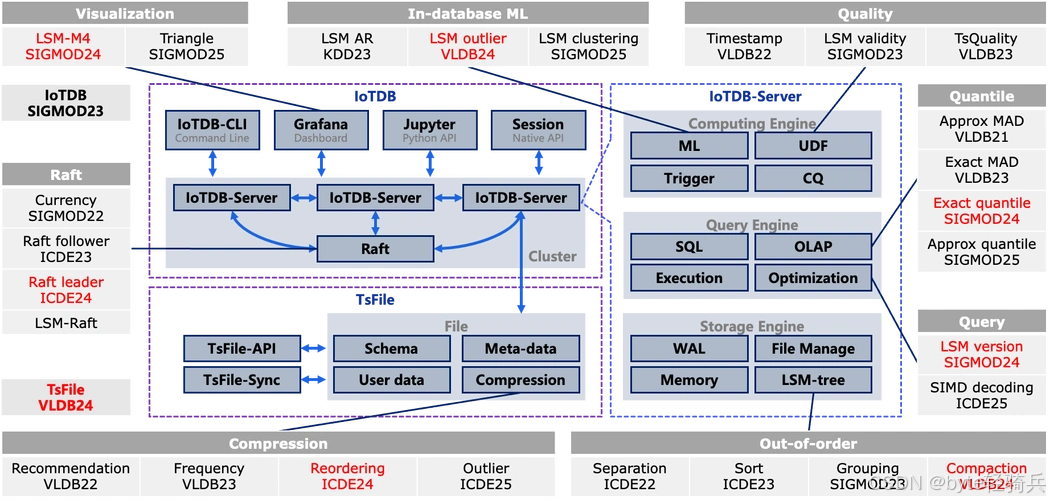
时序数据库的选型需结合业务场景的实际需求,工业物联网领域应重点关注以下技术指标:
1. 数据写入能力
工业场景中,十万级以上设备并发上报数据是常见需求,写入性能需满足:
- 高吞吐量:支持每秒百万级测点数据写入,且在流量峰值时无数据丢失
- 乱序容忍:因网络延迟导致的时间戳乱序数据可正确存储,无需额外预处理
- 边缘适配:轻量级版本可在边缘节点(如嵌入式设备)运行,支持离线数据缓存
2. 查询性能
实时监控与历史数据分析对查询有不同要求:
- 实时查询:单设备单指标的最新值查询响应时间需在毫秒级
- 聚合计算:支持多设备多指标的时间窗口聚合(如 5 分钟均值),计算延迟控制在秒级内
- 历史回溯:对 3-5 年前的归档数据查询,需避免全表扫描,通过索引快速定位
3. 存储效率
工业数据需长期留存,存储成本至关重要:
- 压缩比:数值型数据压缩比应不低于 10:1,状态型数据(如开关量)需支持 bitmap 压缩
- 分层存储:可自动将超过 3 个月的冷数据迁移至对象存储,热数据保留在 SSD
- 生命周期管理:支持按时间策略自动删除过期数据,释放存储空间
4. 系统可靠性
生产环境对可靠性要求严苛:
- 数据一致性:多副本机制确保节点故障时数据不丢失,恢复后自动同步
- 集群扩展:支持在线扩容,新增节点可自动分担读写压力
- 故障恢复:节点故障后恢复时间不超过 5 分钟,且不影响业务连续性
三、架构设计精要
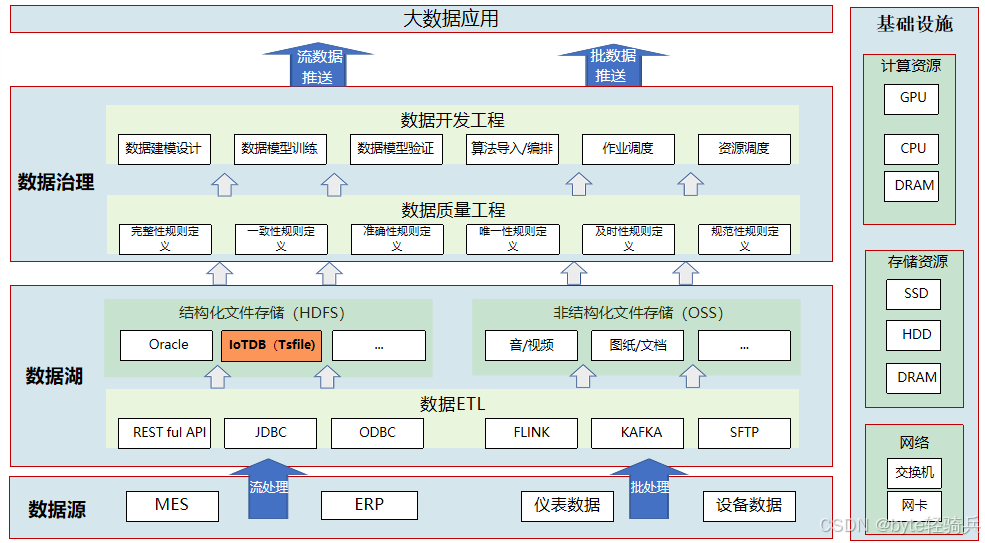
1. 数据模型:树状层级结构
IoTDB 的元数据采用树状组织,每个节点代表一个设备或测点,如 "root.plant.line1.machine1.temperature" 可清晰表达温度测点的所属关系。这种结构带来两个优势:
- 天然支持设备分组查询,如 "SELECT * FROM root.plant.line1" 可获取整条生产线的所有数据
- 元数据与数据存储分离,减少重复存储,提升查询效率
2. 存储引擎:TsFile 与 IoTLSM 协同设计
TsFile 是 IoTDB 自研的时序数据存储格式,采用列式存储与时间对齐方式:
- 同一测点的时序数据连续存储,减少磁盘寻道时间
- 内置多级索引,支持按时间范围快速定位数据块
IoTLSM(IoTDB Log-Structured Merge Tree)则负责内存与磁盘的数据交换:
- 写入数据先进入内存 MemTable,满足高吞吐需求
- 达到阈值后异步刷盘,避免阻塞写入操作
- 后台进行文件合并,减少小文件数量,优化查询性能
3. 边缘 - 云端协同架构
IoTDB 支持三级部署模式,适应工业场景的分布式架构:
| 部署层级 | 资源需求 | 核心功能 | 数据同步方式 |
| 端侧 | 内存 < 64MB | 数据本地缓存、预处理 | 定时批量同步至边缘节点 |
| 边缘侧 | 内存 1-8GB | 区域数据聚合、边缘计算 | 增量同步至云端集群 |
| 云端 | 集群部署 | 全局数据管理、复杂分析 | 多副本冗余存储 |
通过内置的 SyncTool 工具,可配置数据过滤规则,仅上传关键数据,减少网络传输量。
四、在工业场景的应用实践
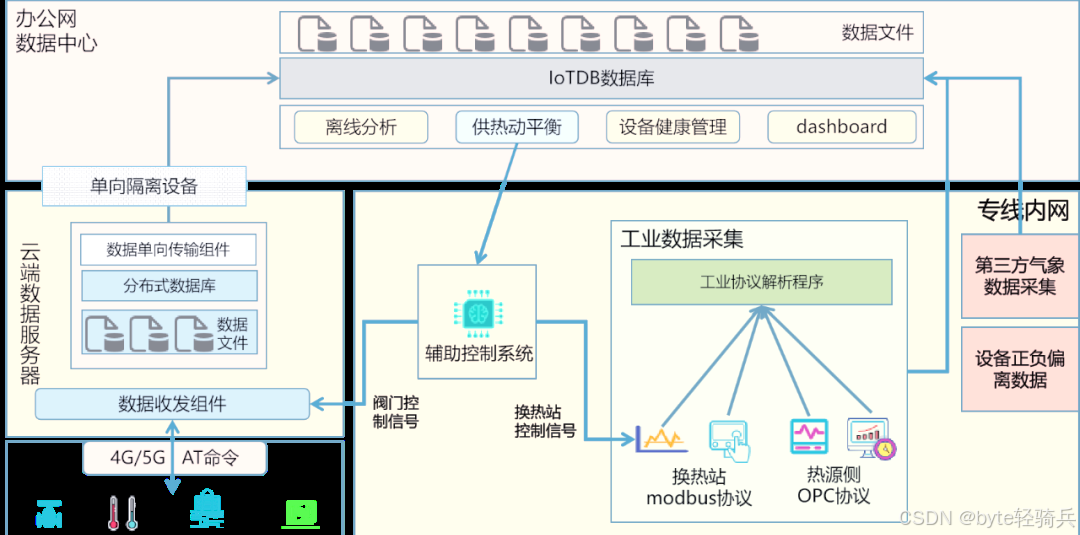
IoTDB 适用于多种场景,如工业物联网、智能城市、智能家居等。在工业物联网中,它可以用于存储和分析设备的运行数据,实现设备的状态监控、故障预测等功能;在智能城市中,能够对交通流量、环境监测等数据进行管理和分析,为城市管理提供决策支持。
Apache IoTDB_国产开源时序数据库_时序数据管理服务商-天谋科技Timecho
五、开发实践
1. 环境部署
单机版安装步骤:
- 下载安装包:访问发行版本 | IoTDB Website 选择对应版本(推荐 1.2.0 及以上)
- 解压文件:tar -zxvf apache-iotdb-1.2.0-all-bin.tar.gz
- 启动服务:
# Linux/Mac cd apache-iotdb-1.2.0-all-bin/sbin ./start-standalone.sh # Windows cd apache-iotdb-1.2.0-all-bin\sbin\windows start-standalone.bat
连接客户端:
./start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root2. 基础操作示例
创建时序数据模型:
-- 创建设备节点(车间-生产线-设备)
CREATE TIMESERIES root.auto.line1.robot1.temp WITH DATATYPE=FLOAT, ENCODING=RLE
CREATE TIMESERIES root.auto.line1.robot1.pressure WITH DATATYPE=INT32, ENCODING=TS_2DIFF插入与查询数据:
-- 插入数据(时间戳精确到毫秒)
INSERT INTO root.auto.line1.robot1(timestamp, temp, pressure)
VALUES(1688888888000, 23.5, 1024),(1688888889000, 23.7, 1025)-- 查询最近10条数据
SELECT temp, pressure FROM root.auto.line1.robot1 LIMIT 103. Java SDK 开发示例
// 引入Maven依赖
<dependency><groupId>org.apache.iotdb</groupId><artifactId>iotdb-jdbc</artifactId><version>1.2.0</version>
</dependency>// 核心代码
public class IoTDBDemo {public static void main(String[] args) throws SQLException {// 建立连接Connection connection = DriverManager.getConnection("jdbc:iotdb://127.0.0.1:6667/", "root", "root");// 插入数据try (PreparedStatement stmt = connection.prepareStatement("INSERT INTO root.auto.line1.robot1(timestamp, temp) VALUES(?, ?)")) {stmt.setLong(1, System.currentTimeMillis());stmt.setFloat(2, 24.1f);stmt.execute();}// 查询数据try (Statement stmt = connection.createStatement()) {ResultSet rs = stmt.executeQuery("SELECT temp FROM root.auto.line1.robot1 WHERE time > NOW() - 1h");while (rs.next()) {System.out.println("Time: " + rs.getLong(1) + ", Temp: " + rs.getFloat(2));}}connection.close();}
}在时序数据库选型中,IoTDB 的自研 TsFile 存储格式、树状数据模型和边缘云协同架构,使其在性能、成本和易用性方面形成了自身特点。随着《工业数据库规范》标准的落地,作为参与制定单位,IoTDB 相关技术规范有望推动国产时序数据库在更多行业的应用。
在工业物联网领域,时序数据技术正在重塑设备管理与工业安全的模式。IoTDB 作为其中的一种技术选择,其在关键行业的实践案例,为时序数据的高效管理提供了可参考的方案。
参考文献:
社区版下载:发行版本 | IoTDB Website
企业级支持:https://timecho.com