分支和循环语句
C语言是结构化的程序设计语言
C语言有3种结构:顺序结构,选择结构,循环结构
今天给大家介绍分支和循环语句,也就是选择和循环结构
什么是语句?
分支语句(选择结构)
if 语句
语法结构:
if(表达式)语句;if(表达式)语句1;
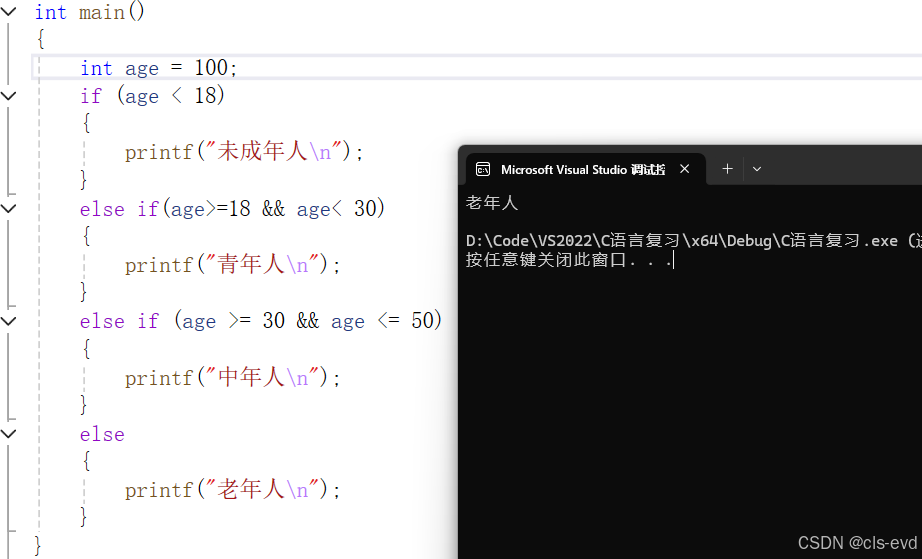
else语句2;//多分支
if(表达式1)语句1;
else if(表达式2)语句2;
else语句3;eg1:
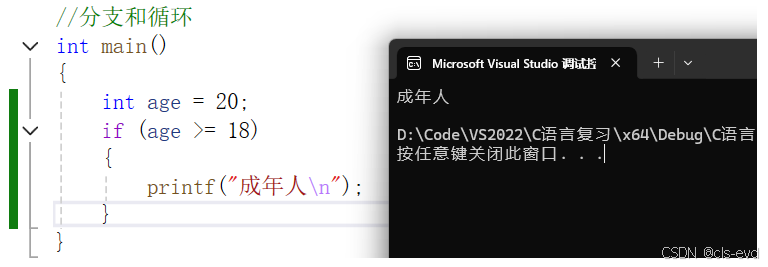
eg2:单分支
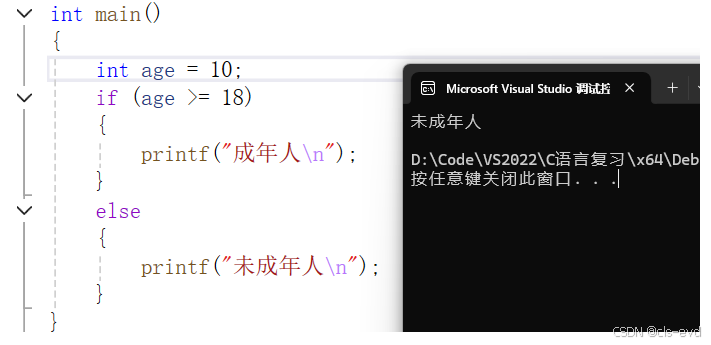
eg3:多分支
在C语言中如何表示真假?
0表示假,非0表示真。
代码块
如果条件成立,要执行多条语句,怎应该使用代码块?

这里一个{ }就是一个代码块
悬空else
现在有这样的一段代码,问他的执行结果是什么?

实际情况他是不执行的
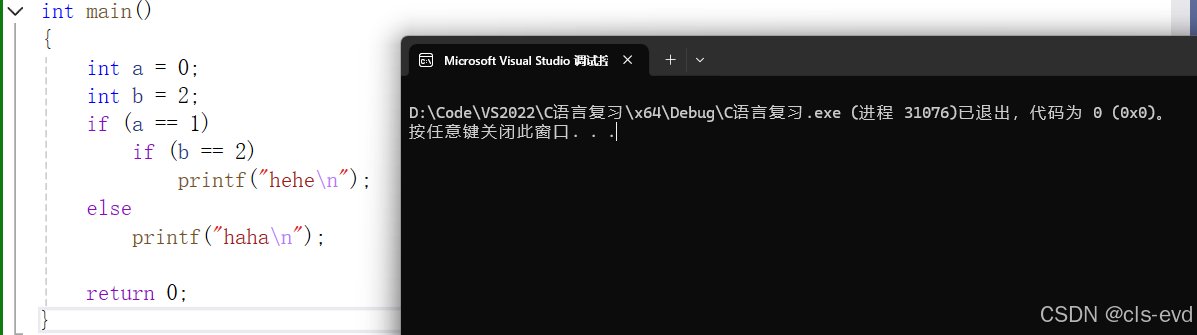
可能有些人认为这段代码执行打印haha,认为if 和 else是相互匹配的,但是实际上这个else 压根就不是和 if(a==1)匹配的,这个else是和if(b==2)匹配的。所以这段代码的结果是啥都不打印。else是和离他最近的一个if所匹配的。
而且这段代码可以通过好的书写习惯变得更加通俗易懂,如果写成这样就不会令人所误会

if书写形式的对比
//代码1
if (condition)
{return x;
}
return y;
//代码2
if(condition)
{return x;
}
else
{return y;
}//代码3
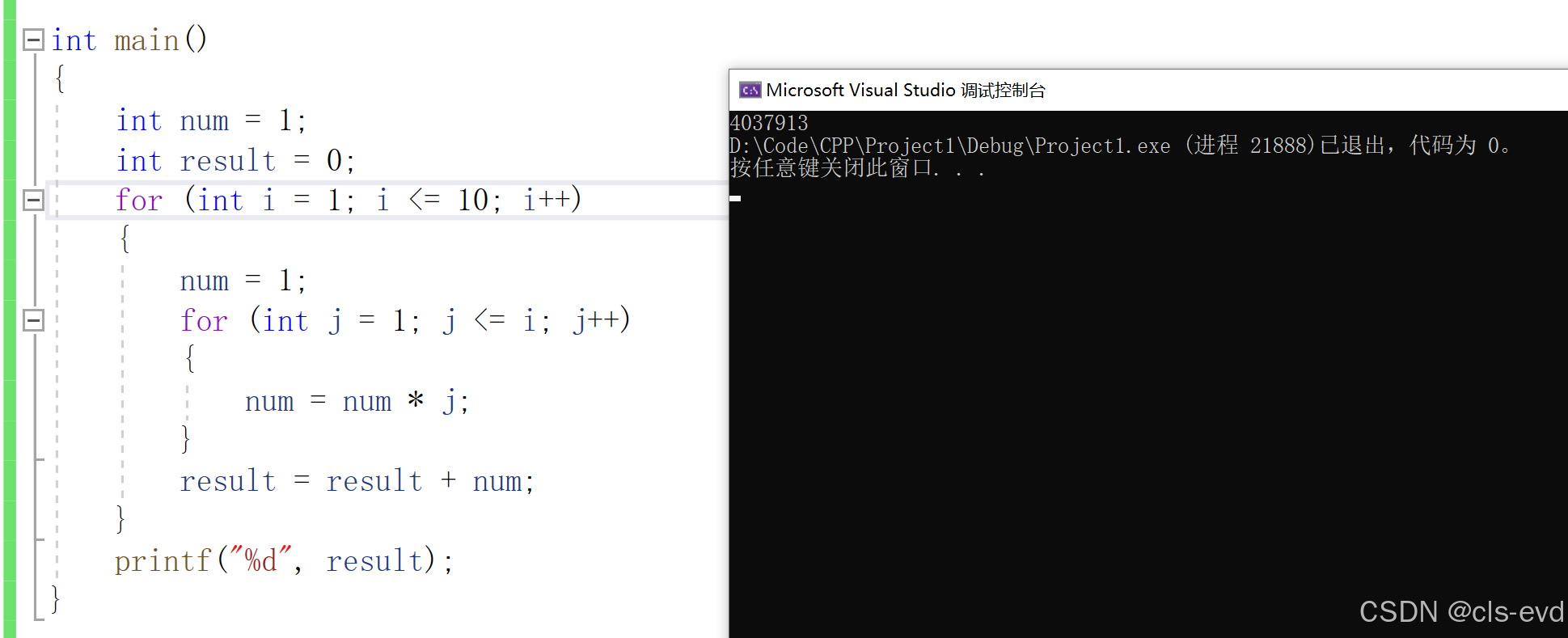
int num = 1;
if(num == 5)
{printf("hehe\n");
}
//代码4
int num = 1;
if(5 == num)
{printf("hehe\n");
}这几个代码中,代码1和代码2表达的意思都是相同的,代码3和代码4表达的意思是相同的。但是相对来说代码2和代码4更好,因为代码2表达的更加清晰。代码4可以规避将==写成=(赋值)的错误
switch语句
switch语句也是一种分支语句。 常常用于多分支的情况。
比如:
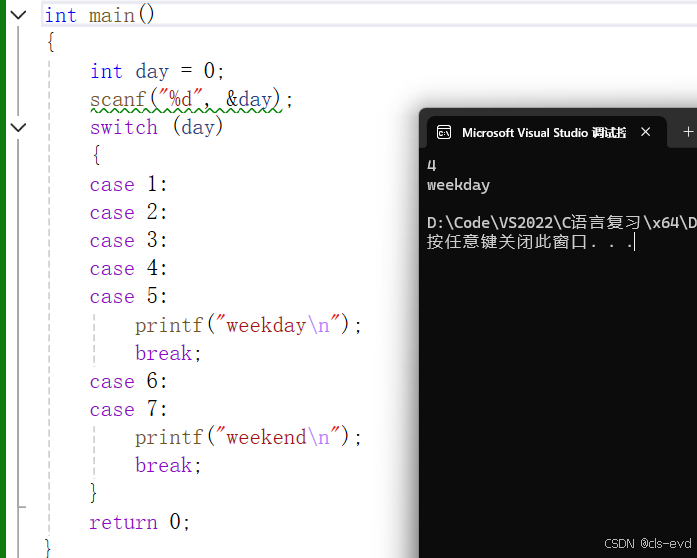
输入1,输出星期一
输入2,输出星期二
输入3,输出星期三
输入4,输出星期四
输入5,输出星期五
输入6,输出星期六
输入7,输出星期七
那我没写成 if...else if ...else if 的形式太复杂,那我们就得有不一样的语法形式。 这就是 switch 语句。
switch(整型表达式)
{语句项;
}//是一些case语句:
//如下:
case 整形常量表达式:语句;
这里注意的点就是switch()这给括号里面是整形表达式,case 旁边是整型常量表达式
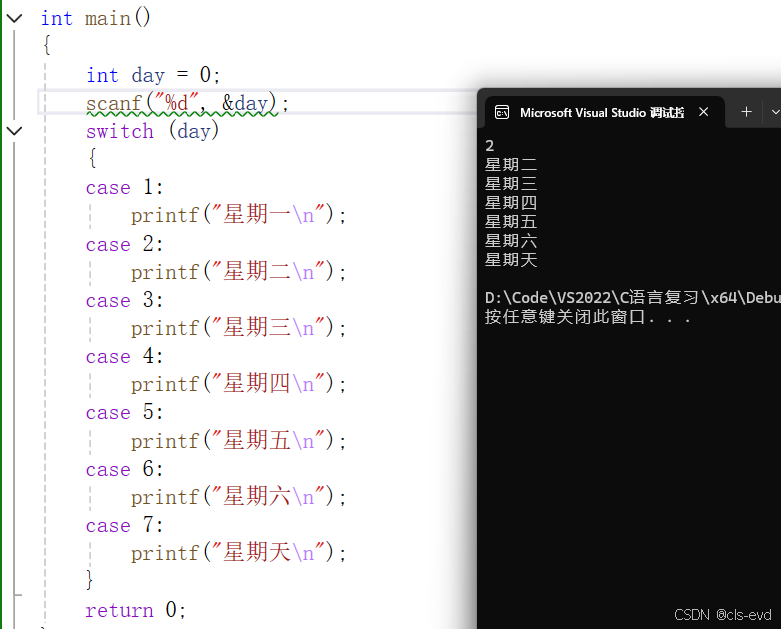
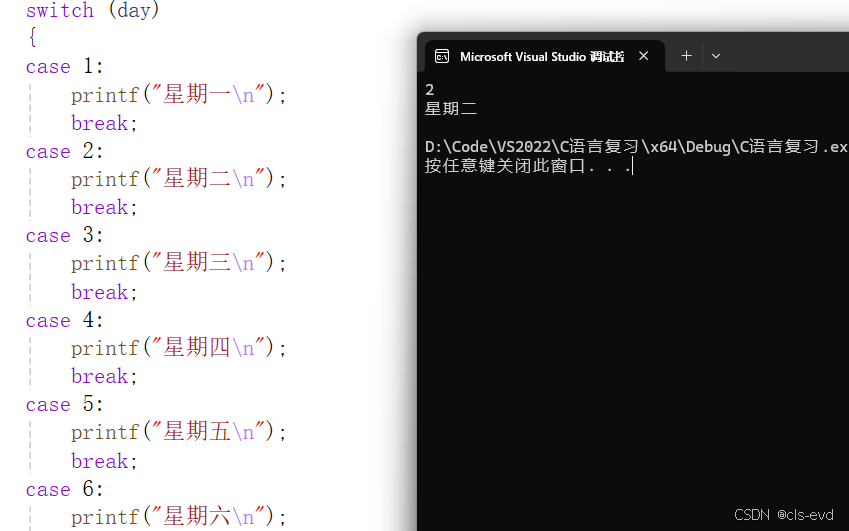
在switch语句中的 break
eg: 这段代码中我们发现如果输入2就会执行全部的case,不是我们所期望的,输入2执行case2,这个时候break就派上用场了,break的作用就是执行case后,直接跳出switch语句
改进
eg2: 如果我们将day改成float类型是会直接报错的,他必须是整形
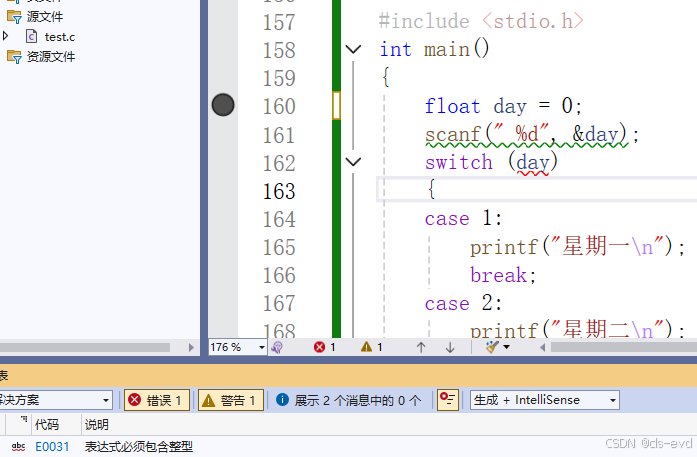
eg3: 我们将case 旁的写成变量是不行的,它必须是整型常量表达式
break语句的实际效果是把语句列表划分为不同的部分。
编程好习惯
default子句
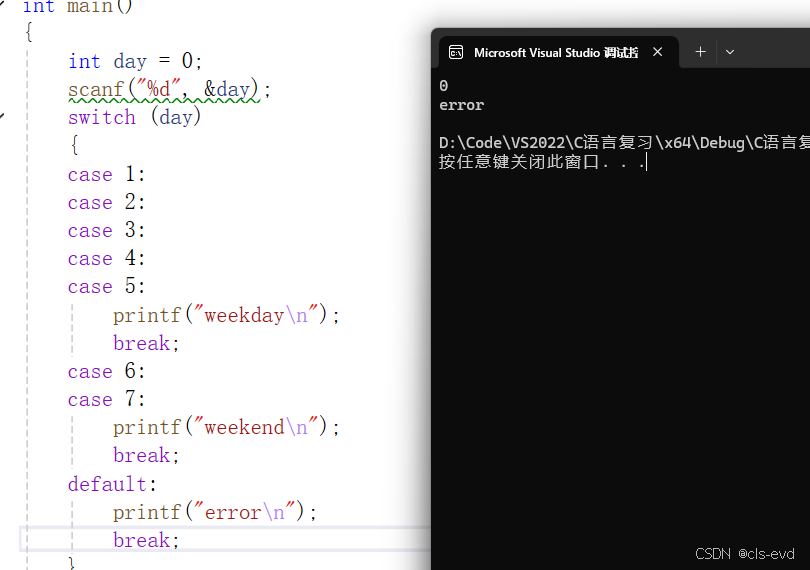
如果表达的值与所有的case标签的值都不匹配怎么办?
其实也没什么,结构就是所有的语句都被跳过而已。 程序并不会终止,也不会报错,因为这种情况在C中并不认为适合错误。
但是,如果你并不想忽略不匹配所有标签的表达式的值时该怎么办呢?
你可以在语句列表中增加一条default子句,把下面的标签 default: 写在任何一个case标签可以出现的位置。 当 switch表达式的值并不匹配所有case标签的值时,这个default子句后面的语句就会执行。
所以,每个switch语句中只能出现一条default子句。 但是它可以出现在语句列表的任何位置,而且语句流会像贯穿一个case标签一样贯穿default子句
在每个 switch 语句中都放一条default子句是个好习惯,甚至可以在后边再加一个 break。
练习
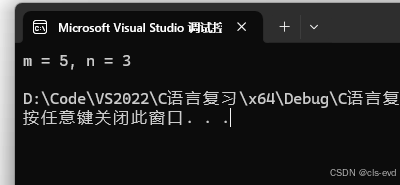
这段代码输出什么?
#include <stdio.h>
int main()
{int n = 1;int m = 2;switch (n){case 1:m++;case 2:n++;case 3:switch (n){//switch允许嵌套使用case 1:n++;case 2:m++;n++;break;}case 4:m++;break;default:break;}printf("m = %d, n = %d\n", m, n);return 0;
} 
循环语句
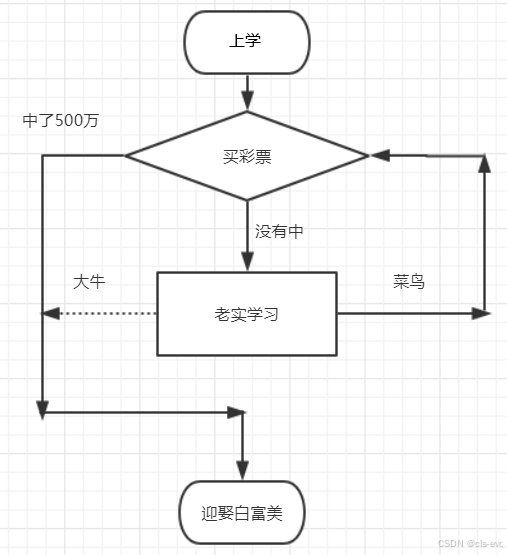
比如你开上学后就开始买彩票,如果中了500万循环直接终止,迎娶白富美。如果没有中的话,就老实学习,知道中了500万或者成为大牛才终止循序
while循环
if(条件)语句;
当条件满足的情况下,if语句后的语句执行,否则不执行。但是这个语句只会执行一次。
//while 语法结构
while(表达式)循环语句;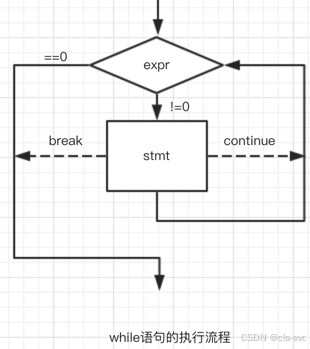
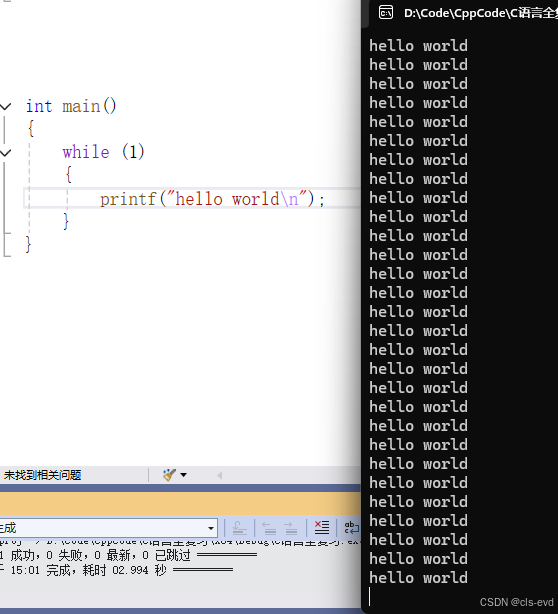
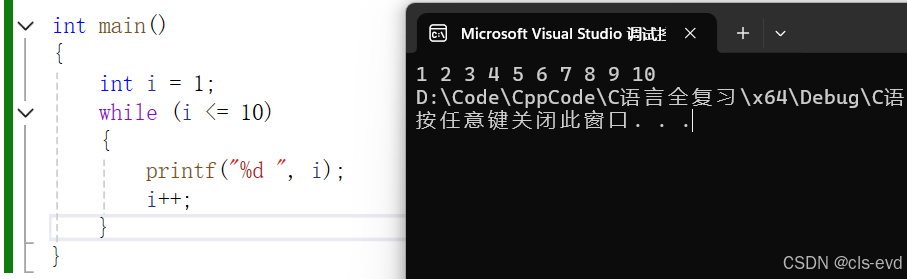
例如最简单的一个while循环,无线循环执行打印hello world操作
while语句中的break和continue
break介绍

1 2 3 41 2 3 4 51 2 3 4 5 6 7 8 9 101 2 3 4 6 7 8 9 10
答案:
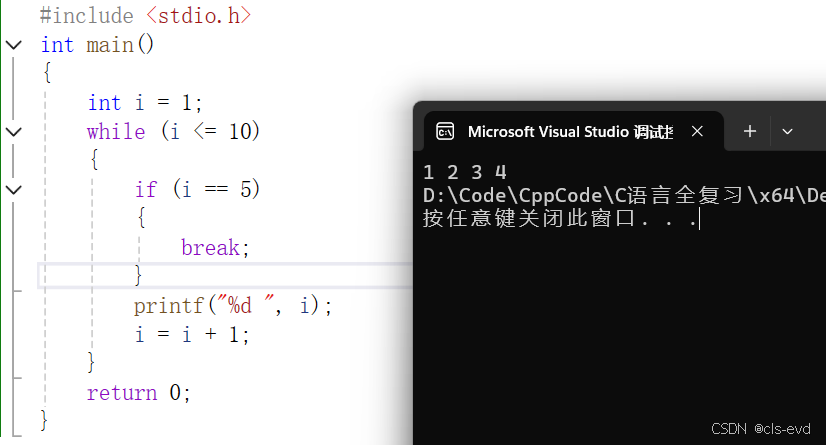
我们看到
continue介绍

1 2 3 41 2 3 4 51 2 3 4 5 6 7 8 9 101 2 3 4 6 7 8 9 10
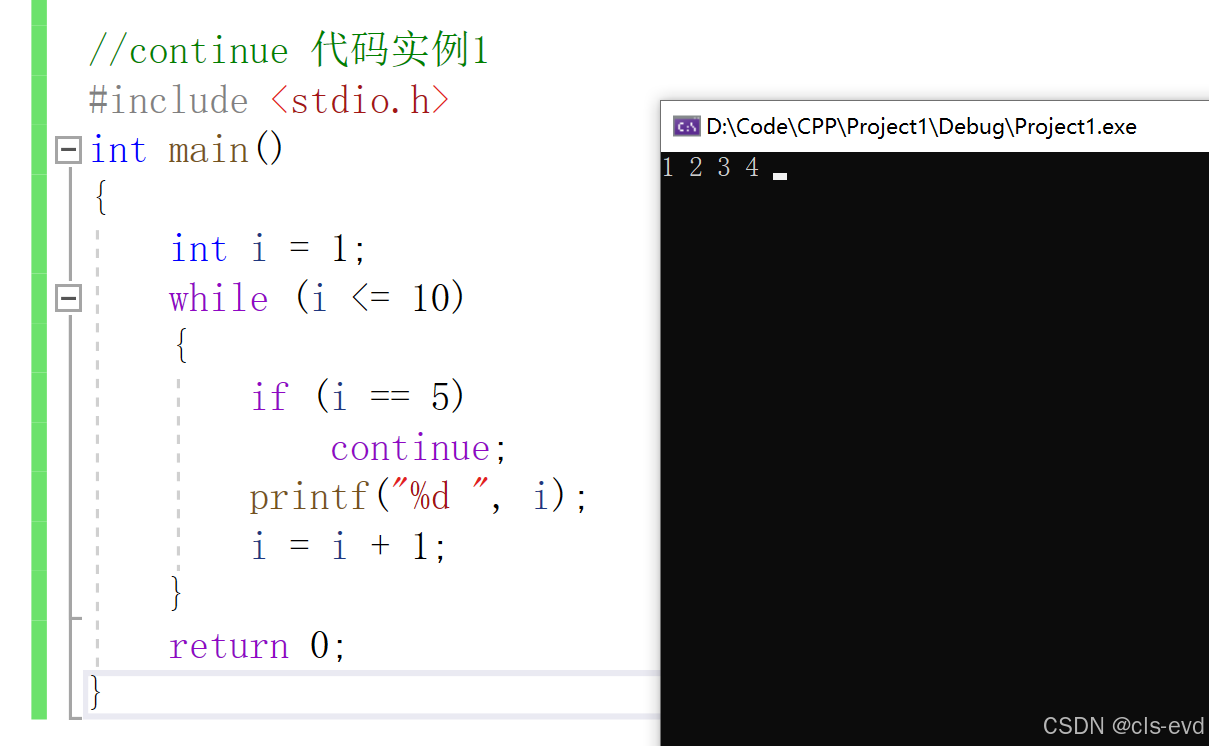
continue是用于终止本次循环的,也就是本次循环中continue后边的代码不会再执行,而是直接
跳转到while语句的判断部分。进行下一次循环的入口判断.


putchar 与getchar简介
他俩的作用就是一个从键盘读取一个字符,一个将字符输出到屏幕上,相当于scanf与printf
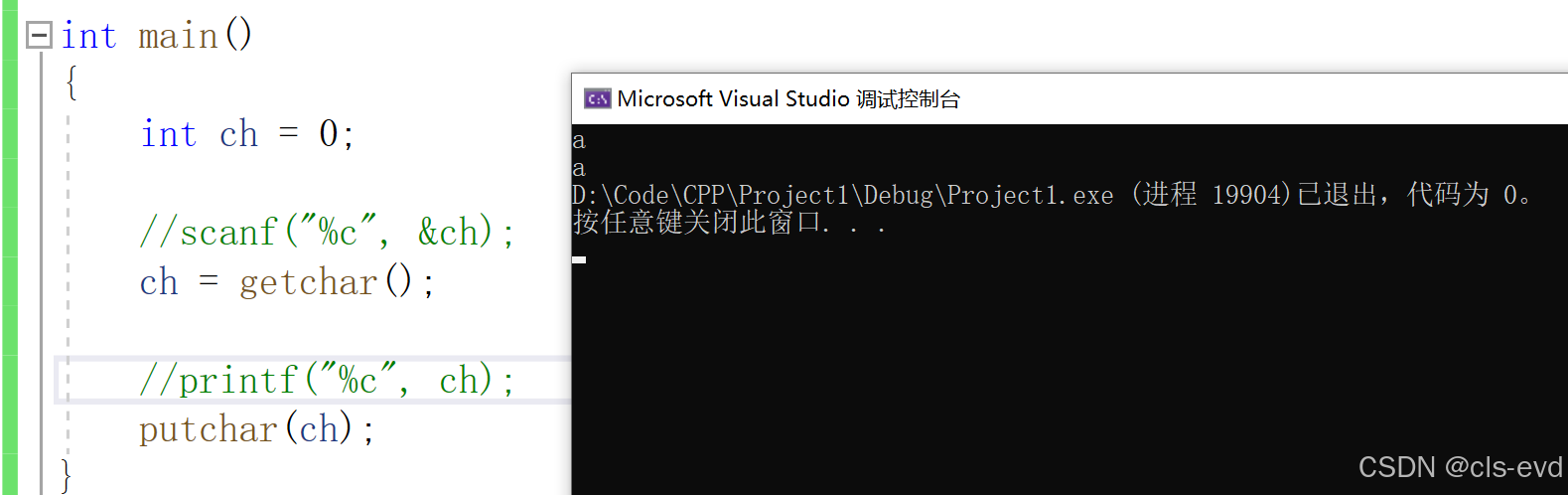
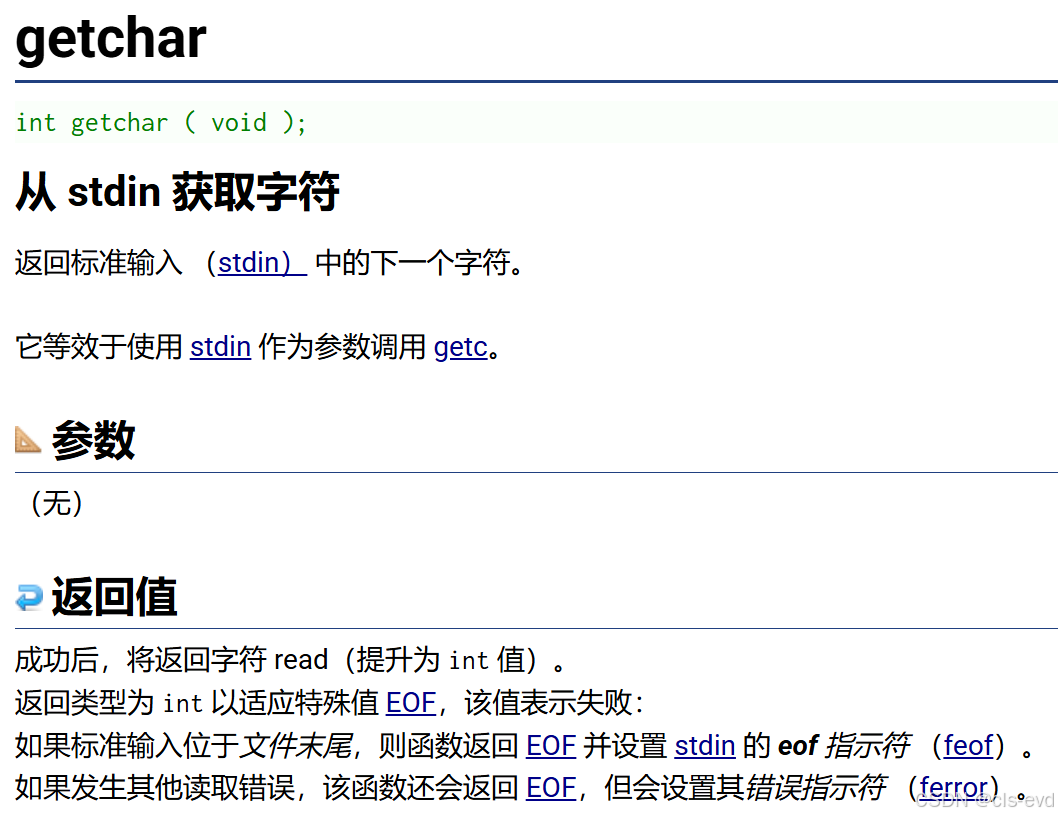
所以这段代码的意思就是你输入字符,然后我给你打印字符。另外就是可能有些人有一个疑问,eof的值不是-1吗,为啥当我运行程序的时候,我输入-1,仍然显示出来了,而不是将程序进行终止了?问题的核心在于理解
getchar()函数如何工作:
getchar()读取的是字符,不是数字
- 当你在键盘上输入
-1时,实际上输入的是两个字符:-和1- 字符
-的 ASCII 值是 45- 字符
1的 ASCII 值是 49- 这些都不等于 EOF(通常是 -1)

那这段代码的应用场景呢?
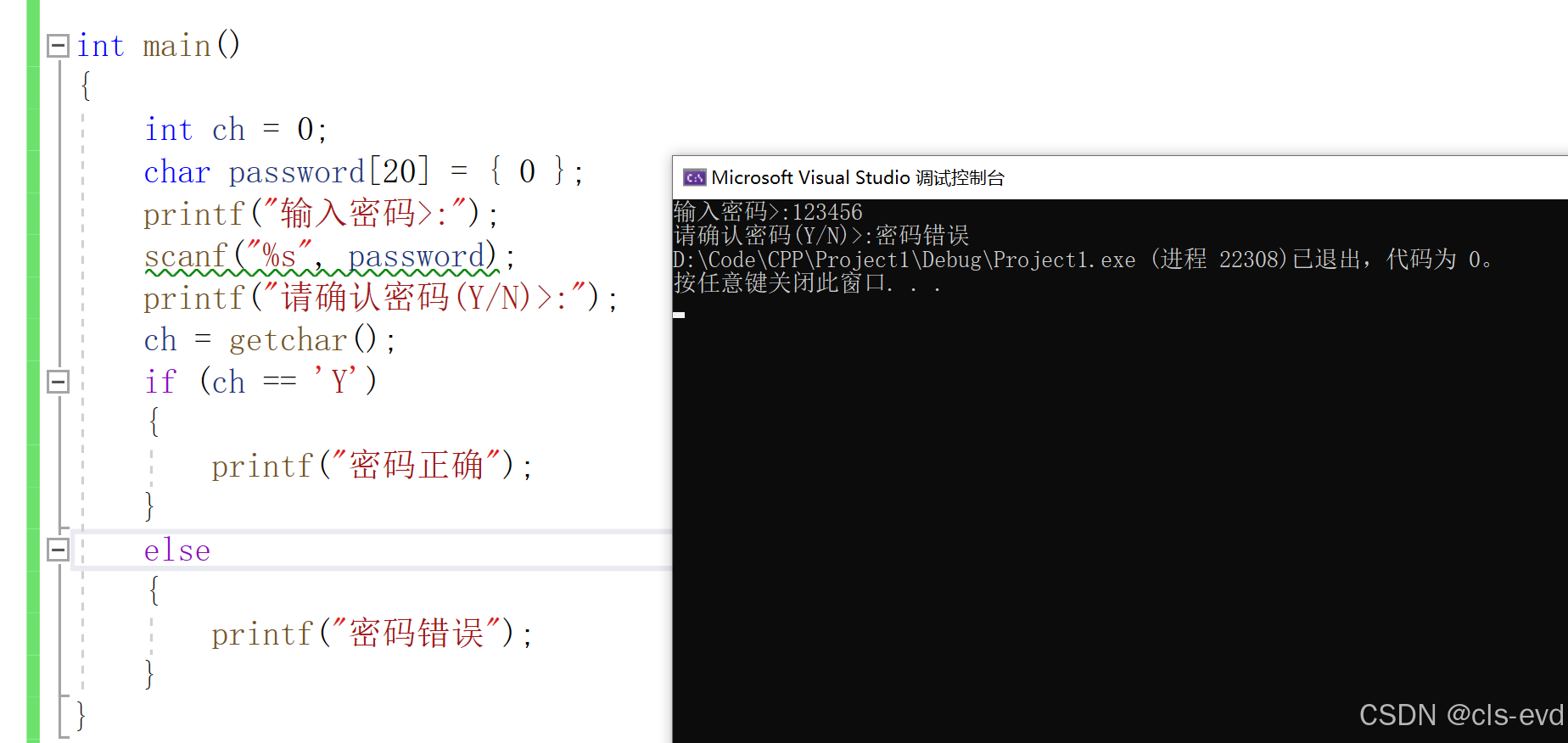
有这样的一段代码,但是当我们输入完密码,按下回车键以后,发现还没有进行确认密码,直接就给我们输出密码错误。这是怎么回事呢?
这是因为scanf与getchar读取数据的时候是从缓冲区里面进行去取的,虽然直观上来看是从键盘上进行读取的,但是实际上中间还存在一个输入缓冲区。

所以,这就会造成即使我们输入正确的密码,也直接会显示密码错误。该如何解决呢?
造成这种问题的原因,就是因为getchar在执行之前,缓冲区里面还存在数据,所以我们需要将缓冲区里面的数据进行清理干净。
有人说,直接在加一个getchar,这样不就行了吗,这种方法只能看似可以,实际是有局限性的
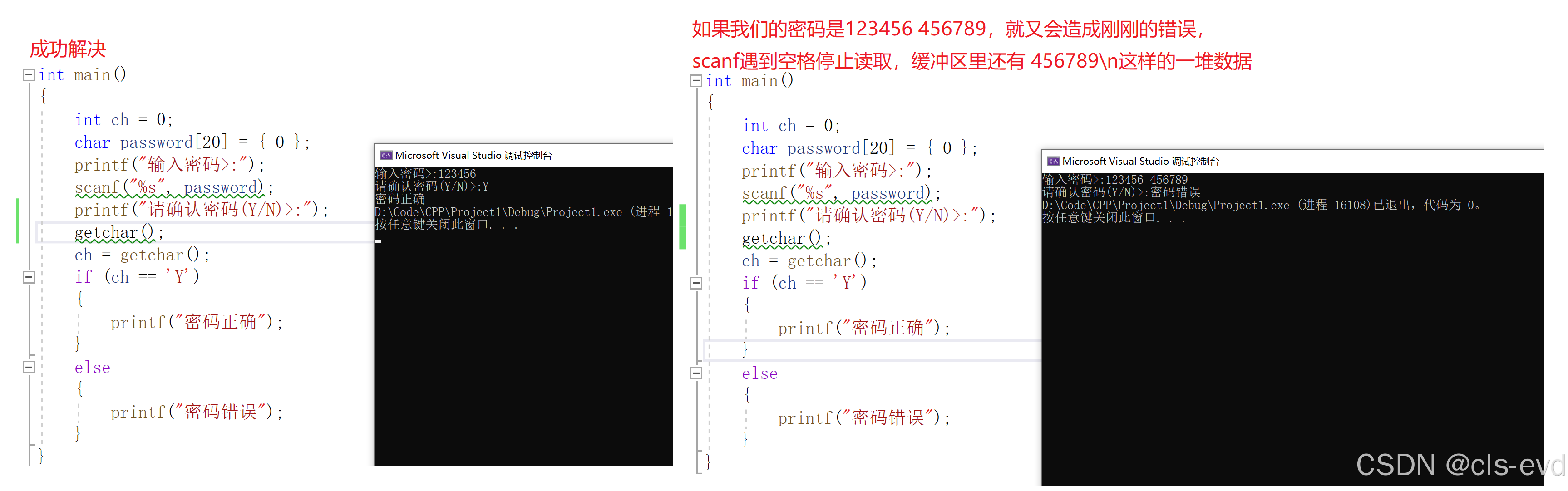
正确解决方法:同时这也是刚刚提到的那段代码的应用场景
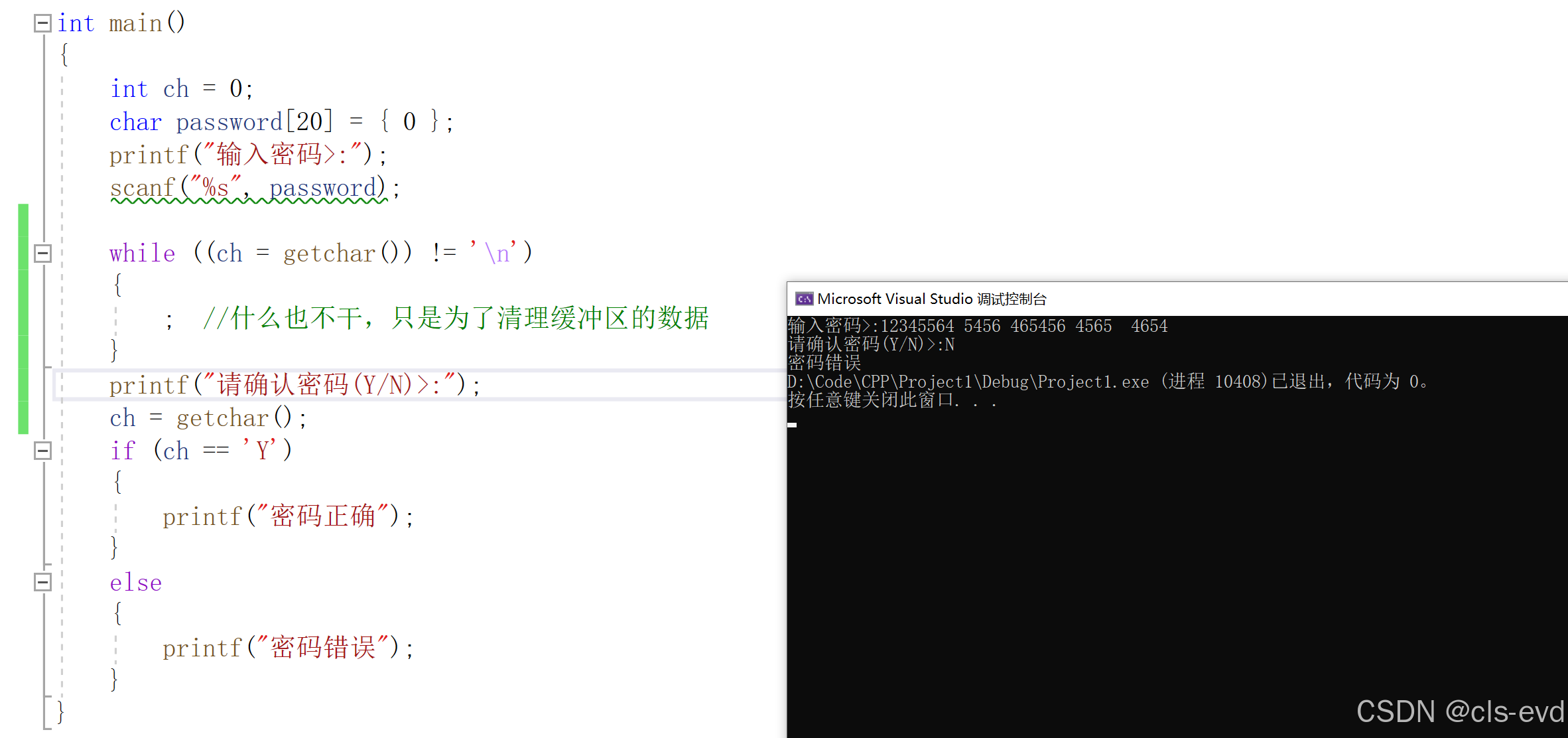
ps:如果我们想要我们的密码包含空格,我们就需要使用gets函数
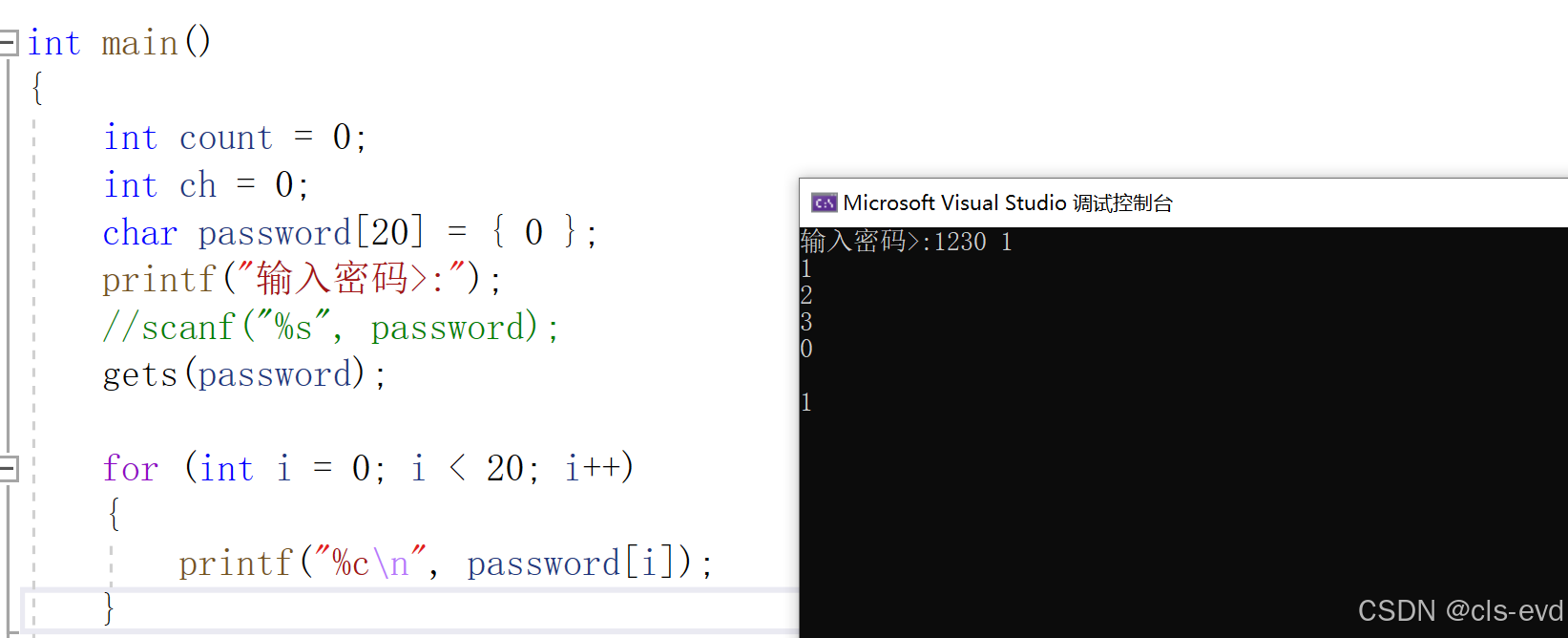
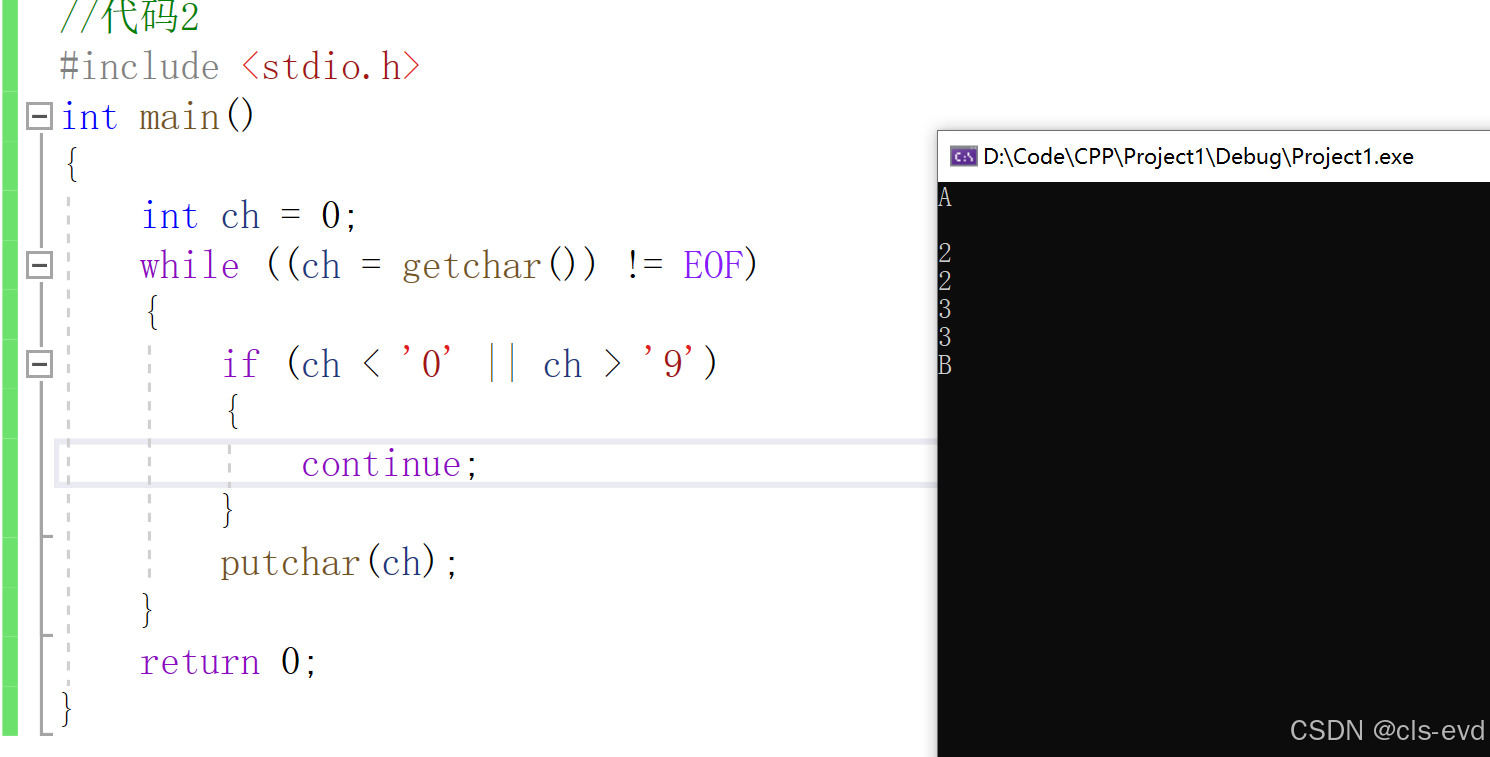
这段代码的意思是什么呢?

我们现在就很容易知道,这段代码的意思就是只输出0-9之间的字符,别的字符不输出
 小问题
小问题
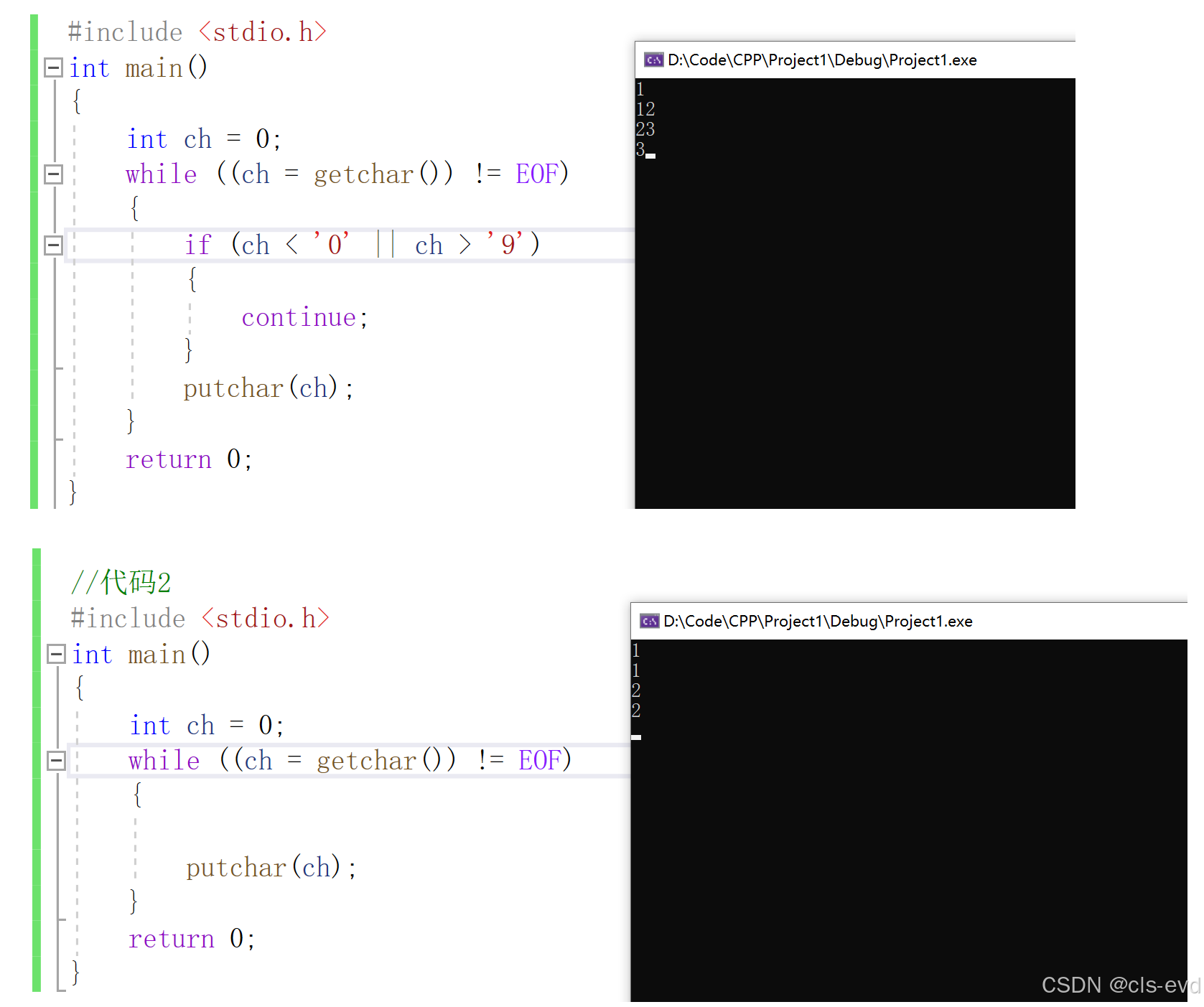
在执行两个代码的时候, 比如在执行代码1 ,我在第一行输入1以后,他就在第二行给我显示1,但是我还能继续在第一行输入,不会自动进行换行。 在执行代码2的时候,我在第一行输入1以后,他就在第二行给我显示1,并且自动换行,让我下次再第三行输入,这是为啥呢?
这是一个很好的观察!这种现象的原因与输入缓冲机制和字符处理方式有关:
代码1的行为分析
代码1中有这段逻辑:
if (ch < '0' || ch > '9')
{continue;
}
putchar(ch);当输入字符时:
- 输入
1→getchar()读取到'1',满足数字条件,putchar('1')输出1 - 按回车键 →
getchar()读取到'\n'(换行符),但因为不是数字,执行continue,跳过了putchar() - 由于换行符没有被输出,光标仍在同一行,可以继续输入
代码2的行为分析
代码2没有过滤逻辑:
while ((ch = getchar()) != EOF)
{putchar(ch);
}当输入字符时:
- 输入
1→getchar()读取到'1',putchar('1')输出1 - 按回车键 →
getchar()读取到'\n',putchar('\n')输出换行符 - 换行符被输出,所以光标移到下一行
关键区别:代码1过滤掉了换行符('\n'),所以不会自动换行;代码2会输出所有字符包括换行符,所以会自动换行到下一行。
这就是为什么代码1感觉"还能继续在第一行输入",而代码2会"自动换行在第三行输入"的原因。
for循环
for(表达式1;表达式2;表达式3)循环语句;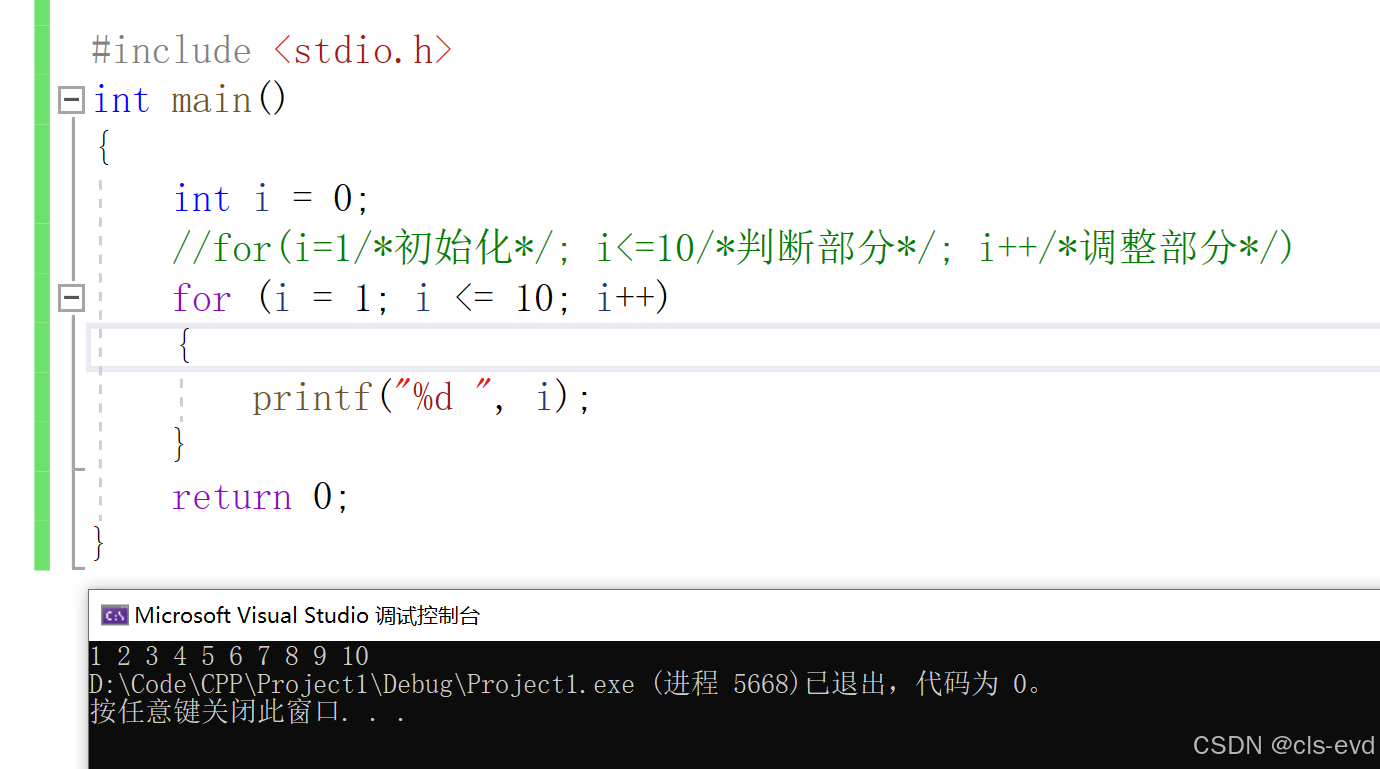
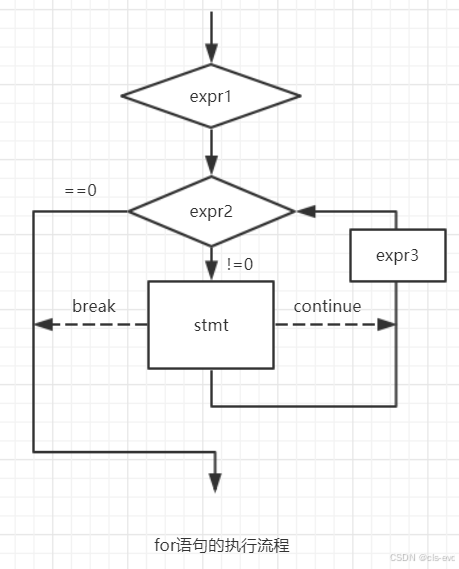

break和continue在for循环中
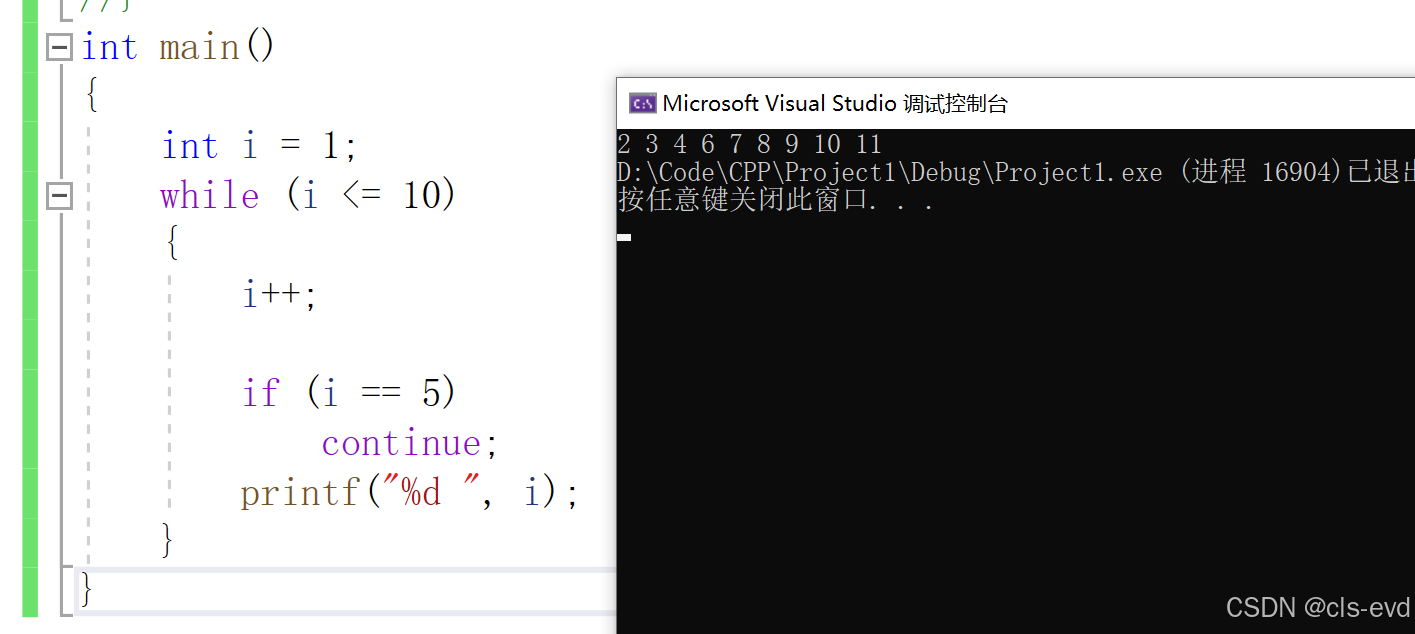
我们发现在for循环中也可以出现break和continue,他们的意义和在while循环中是一样的。 但是还是有些差异:
对于break来讲,与while循环中的break没有什么大的区别
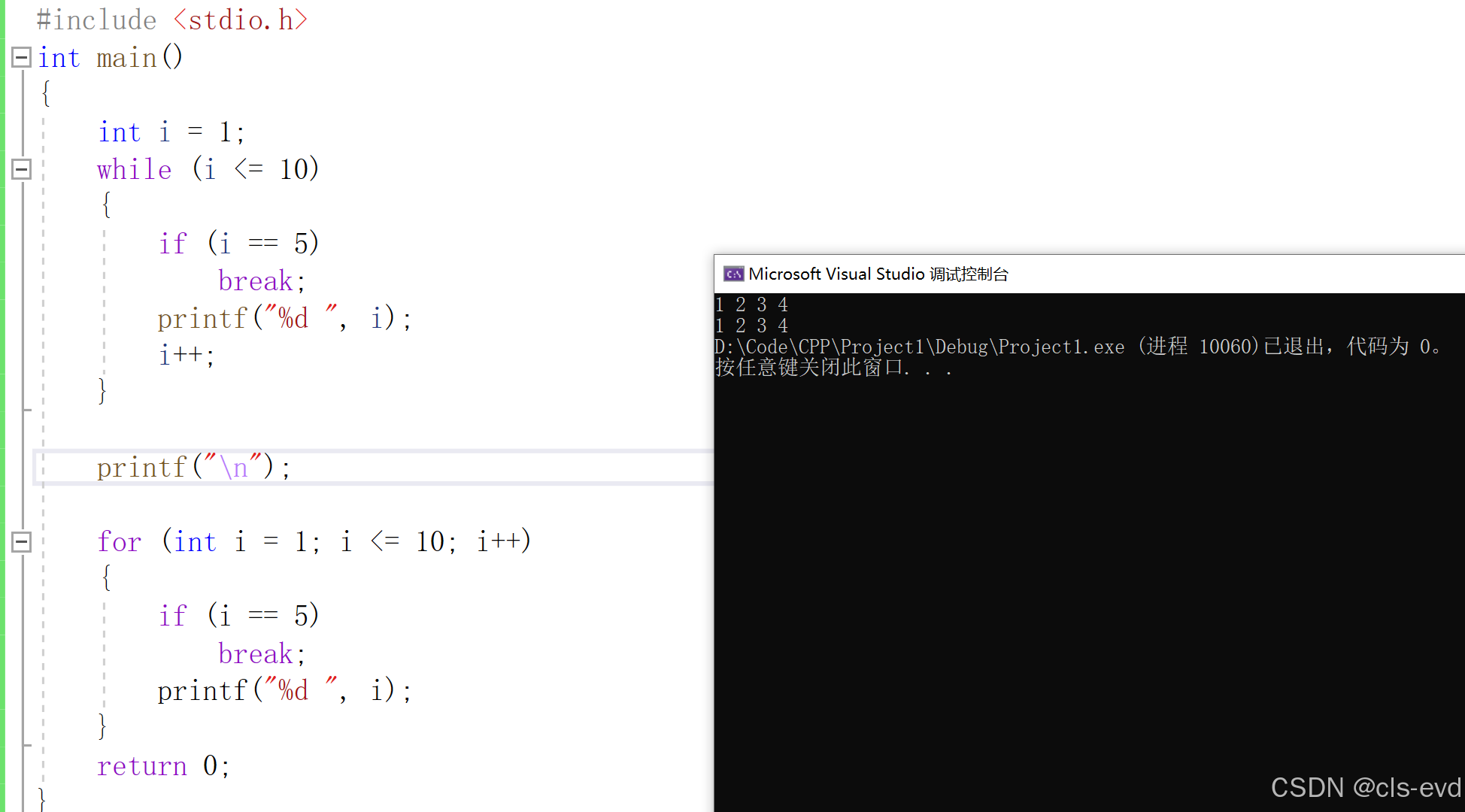
对于continue来讲,它俩就存在细微差别
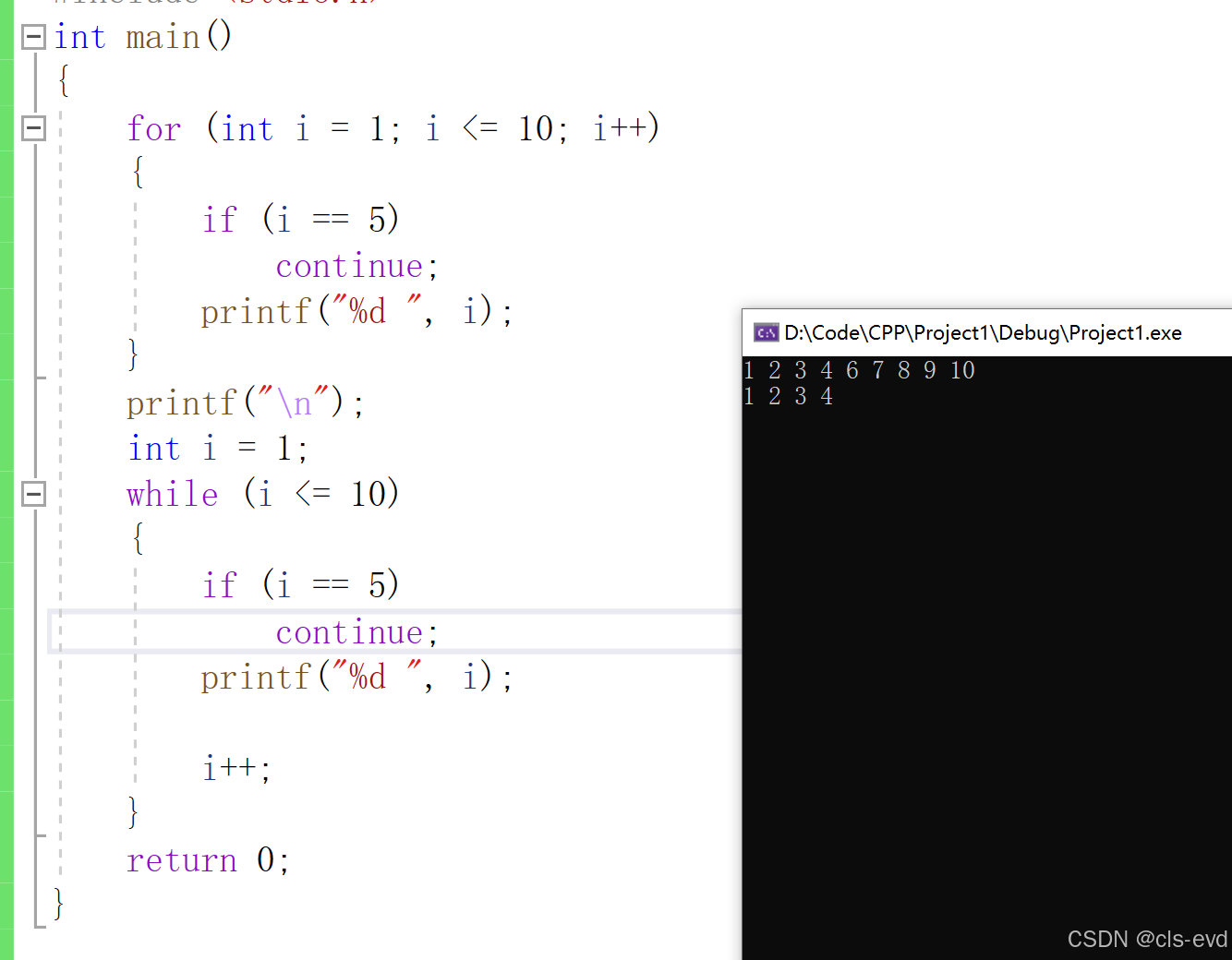
我们发现基本上是一致的代码,for循环就不会造成死循环,while就会造成死循环
这是因为for循环中的continue跳过了后面的代码,直接去了调整部分(也就是i++),调整循环变量,不容易造成死循环。
在while循环中,continue跳过continue后面的代码,直接去了判断部分,所以就造成了死循环
for语句的循环控制变量
一些建议:
1. 不可在for 循环体内修改循环变量,防止 for 循环失去控制。
2. 建议for语句的循环控制变量的取值采用“前闭后开区间”写法。
eg1:在for循环体内修改了循环变量
eg2:


一些for循环的变种
1.初始化,判断,调整3个部分都省略了

2.判断部分省略,意味条件恒为真
 虽然他们可以省略,但尽量还是不要省略。
虽然他们可以省略,但尽量还是不要省略。
eg: 这个代码就把初始化部分给省略了,代码本来的意思是想打印100个hehe,但是因为省略了初始化部分,当i=2的时候,j变成了10(并没有重置),终止打印hehe的操作,所以最终内部的for只循环了10次
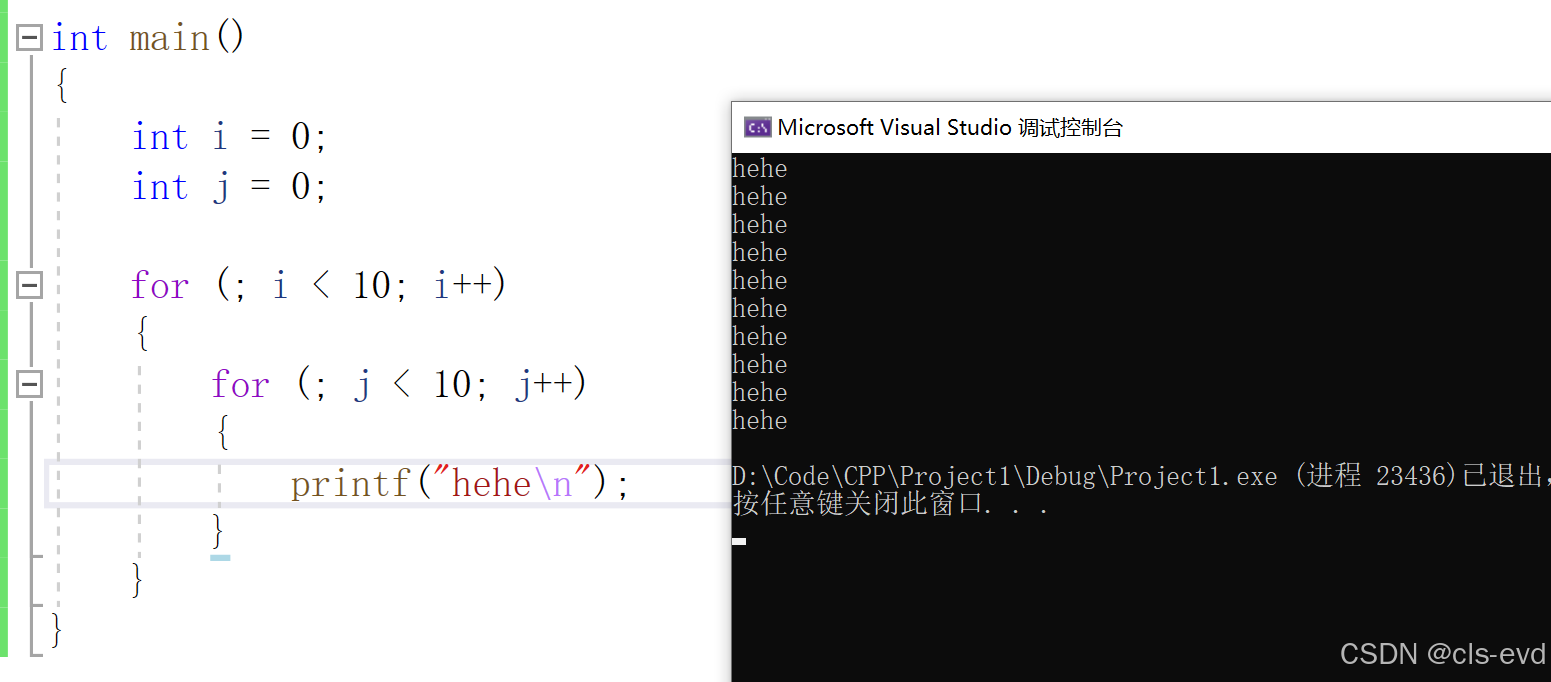 3.这些初始化,判断,调整的条件可以有多个
3.这些初始化,判断,调整的条件可以有多个

一道笔试题
 答案是0次,因为判断条件恒为假,所以压根就不会进行循环
答案是0次,因为判断条件恒为假,所以压根就不会进行循环
do...while()循环
do语句的语法
do循环语句;
while(表达式);执行流程
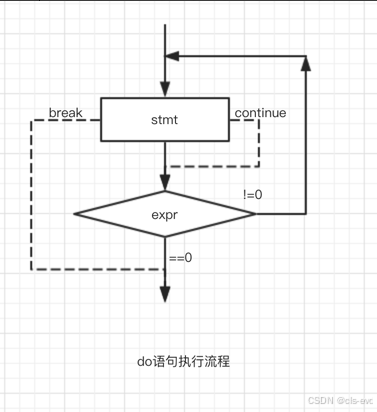
do语句的特点
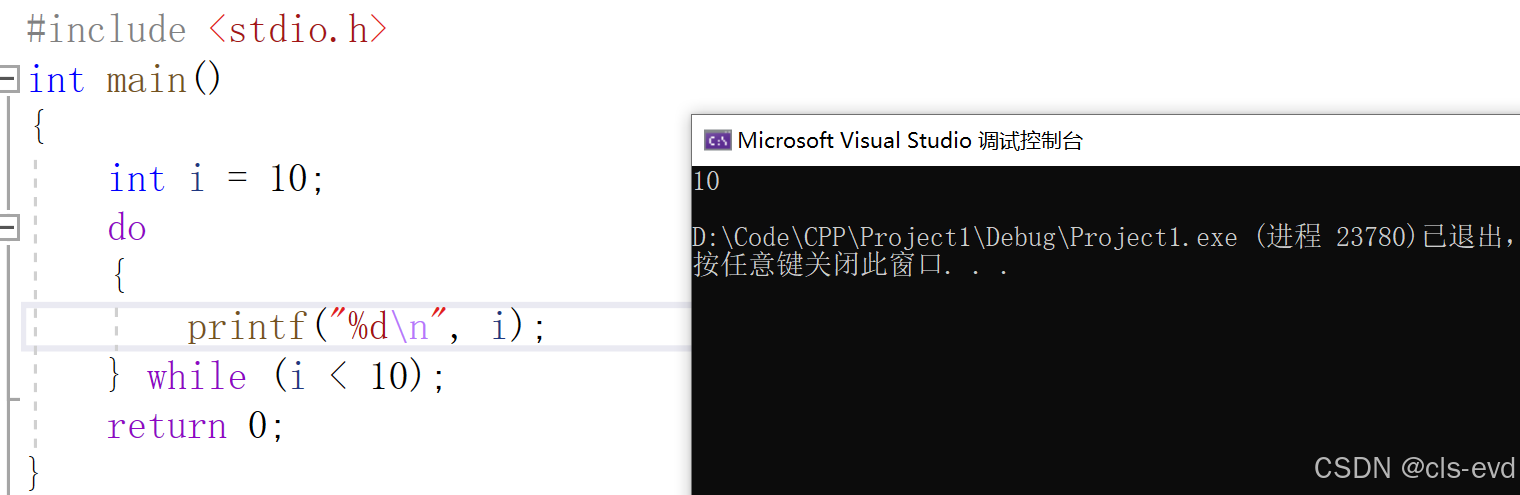
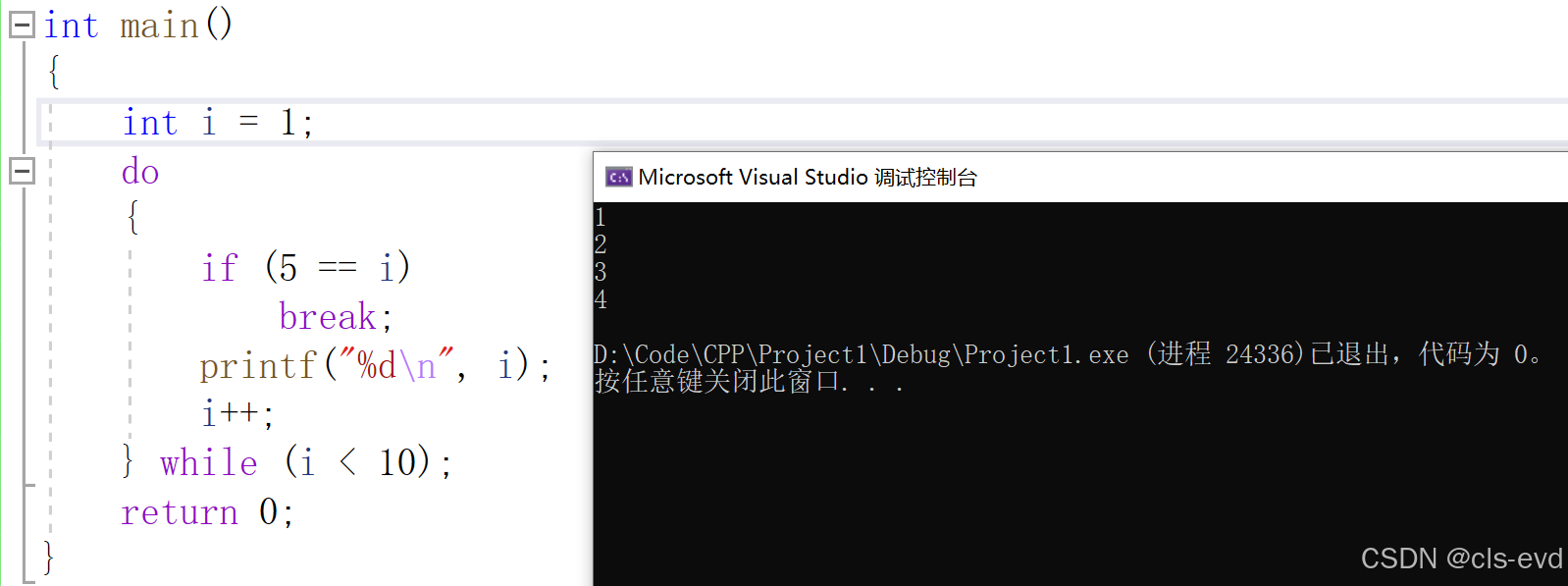
do while循环中的break和continue
do while和while 中的break与continue一致
break直接跳出循环
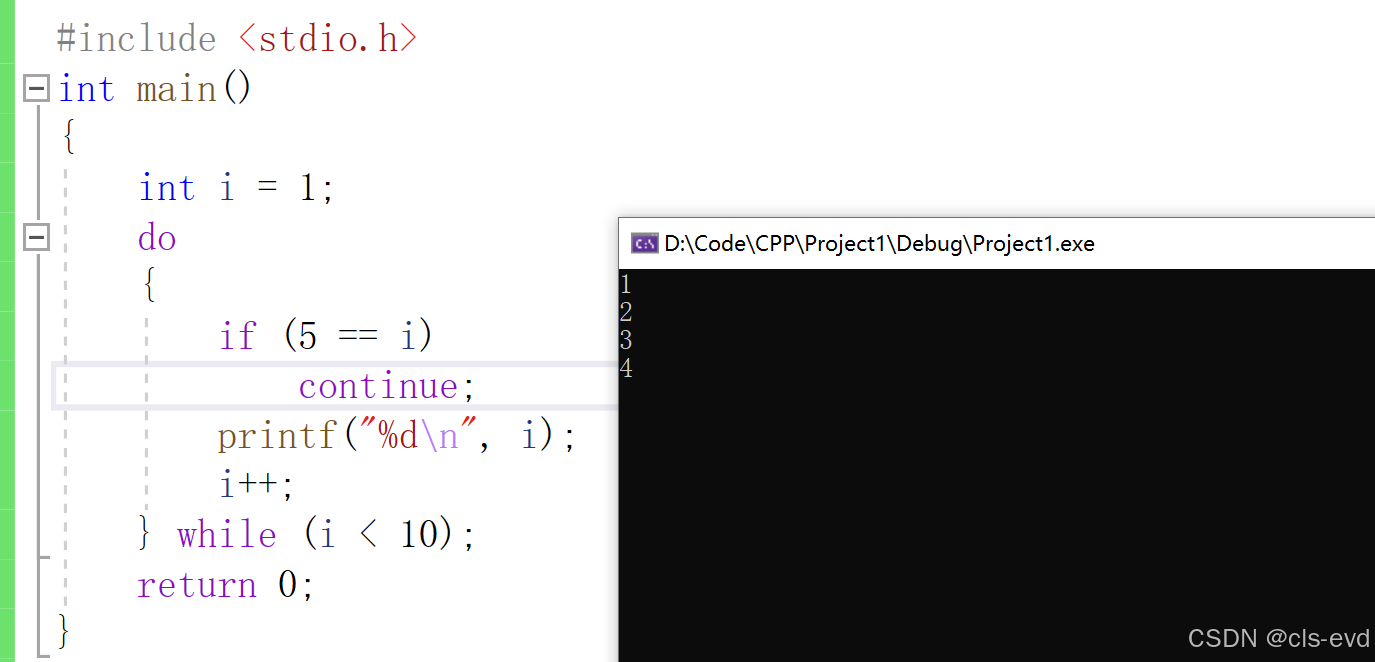
continue后一致无限循环
练习
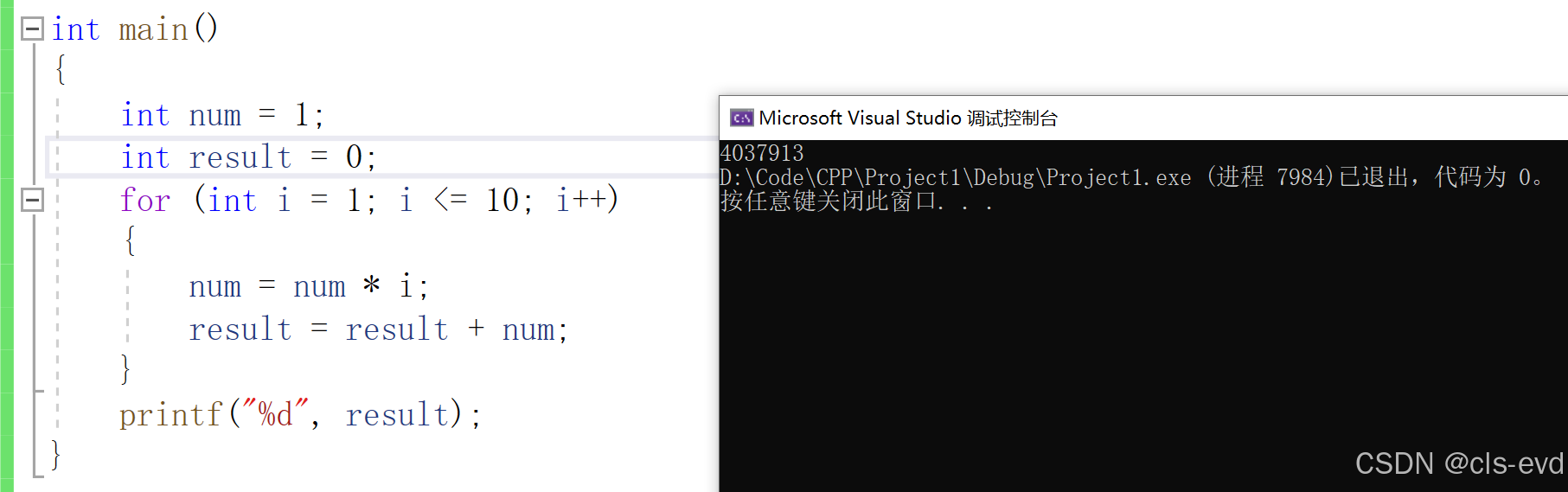
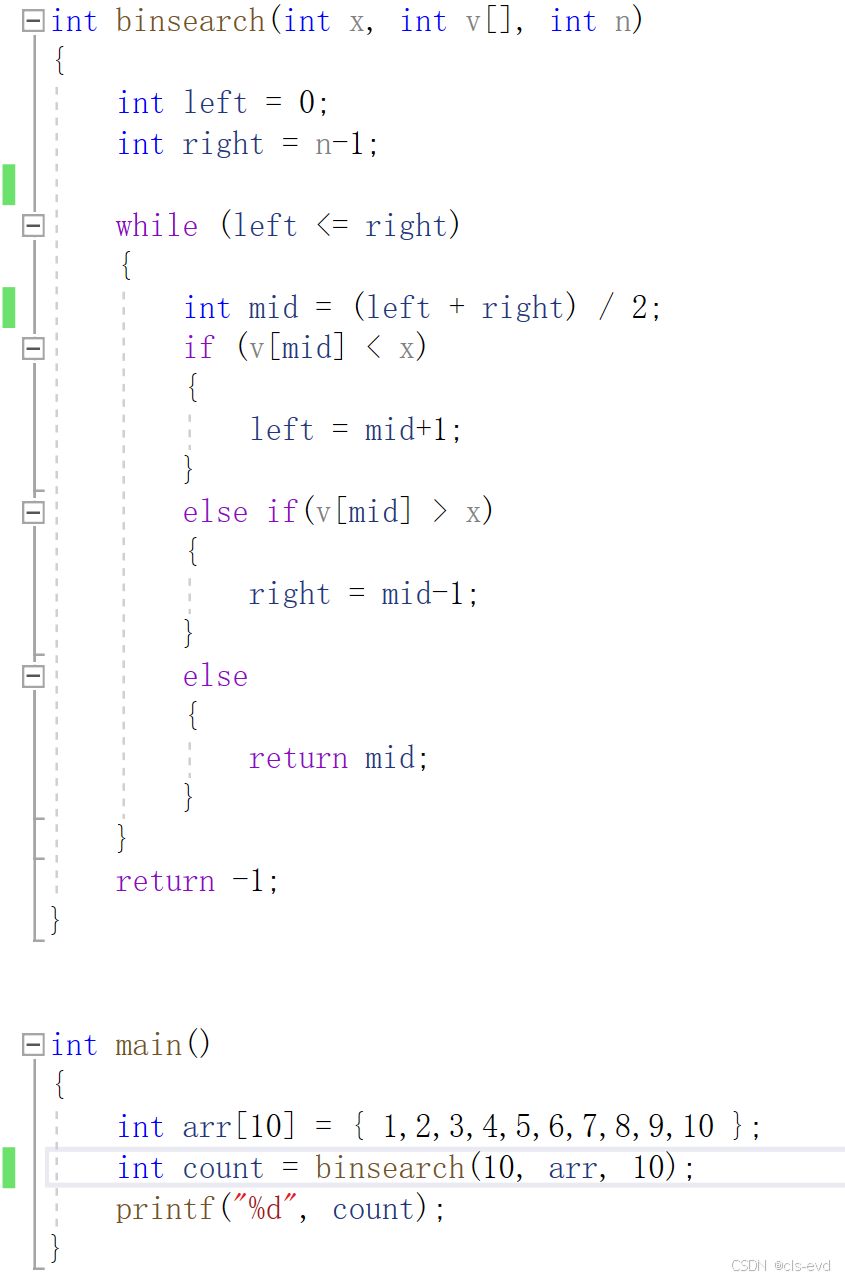
但是因为int是有范围的,严格意义上的n的阶乘是不能这么来写的,下面这段代码是有局限性的


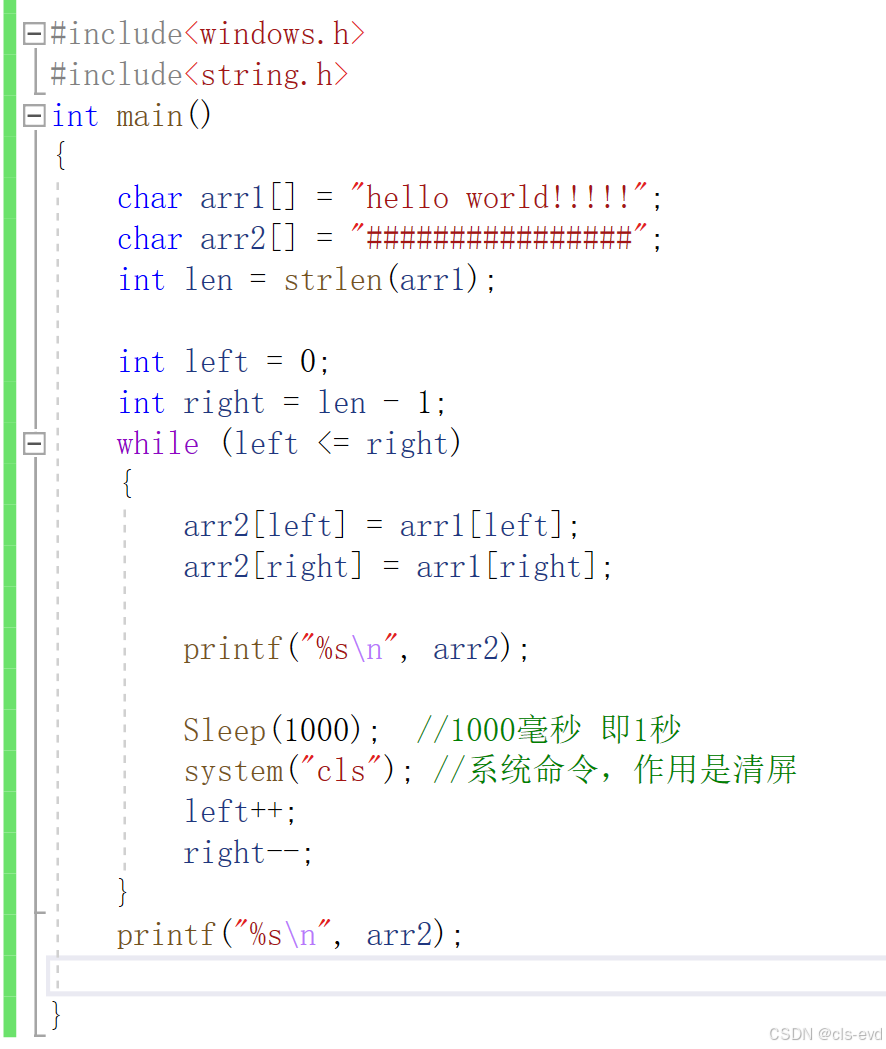
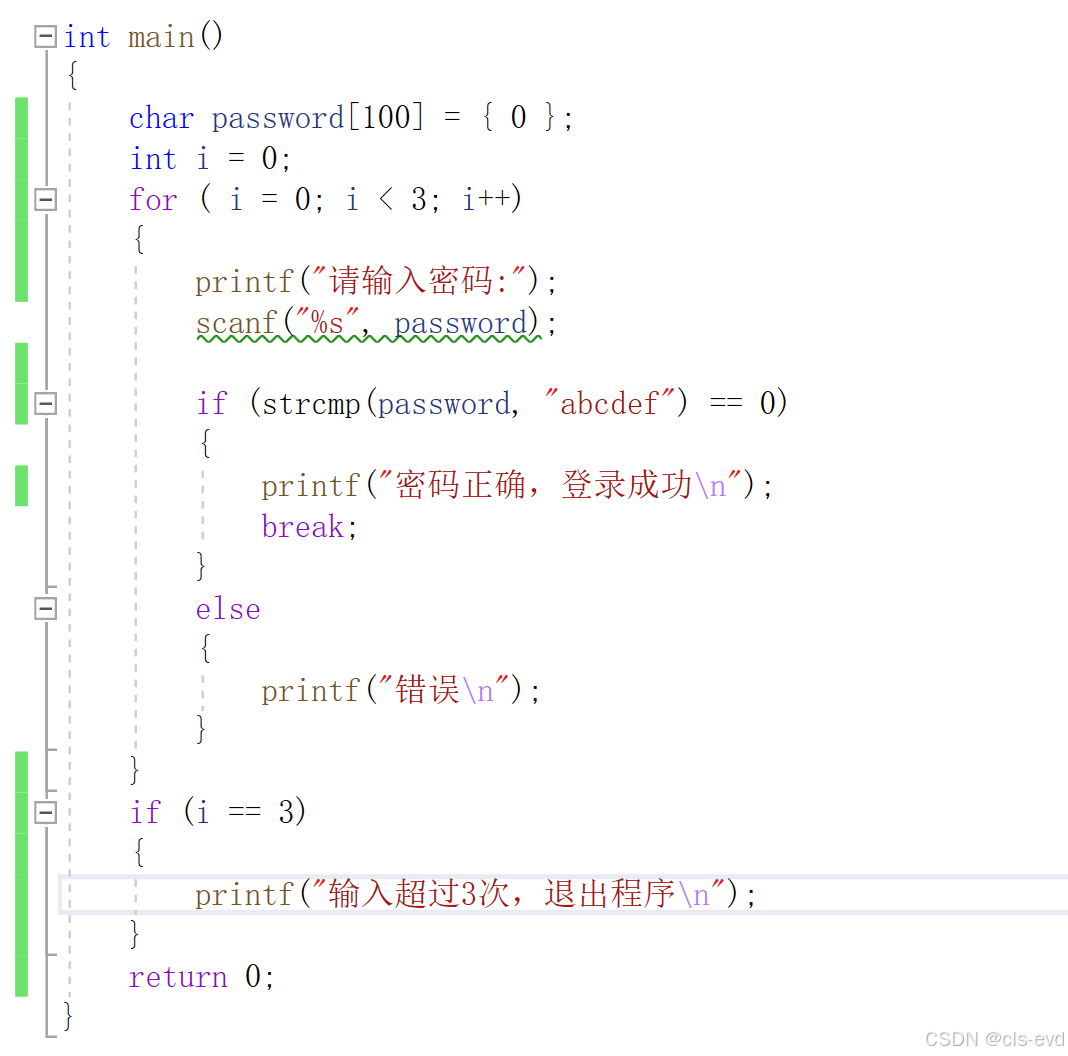
strcmp是比较字符串是否相等的一个函数,相同返回0.
goto语句
一个简单的goto程序,打印一个hehe,goto在跳转到again,然后在打印hehe,最终程序进入了死循环。 而且这个代码我们完全可以用for来进行代替,所以goto是可有可无的。

比如说下面这种情况,我有三层循环,我想直接从最内层的循环中跳出去,就可以使用goto语句,break只能跳出当前循环。
for(...)for(...){for(...){if(disaster)goto error;}}… error:if(disaster)// 处理错误情况
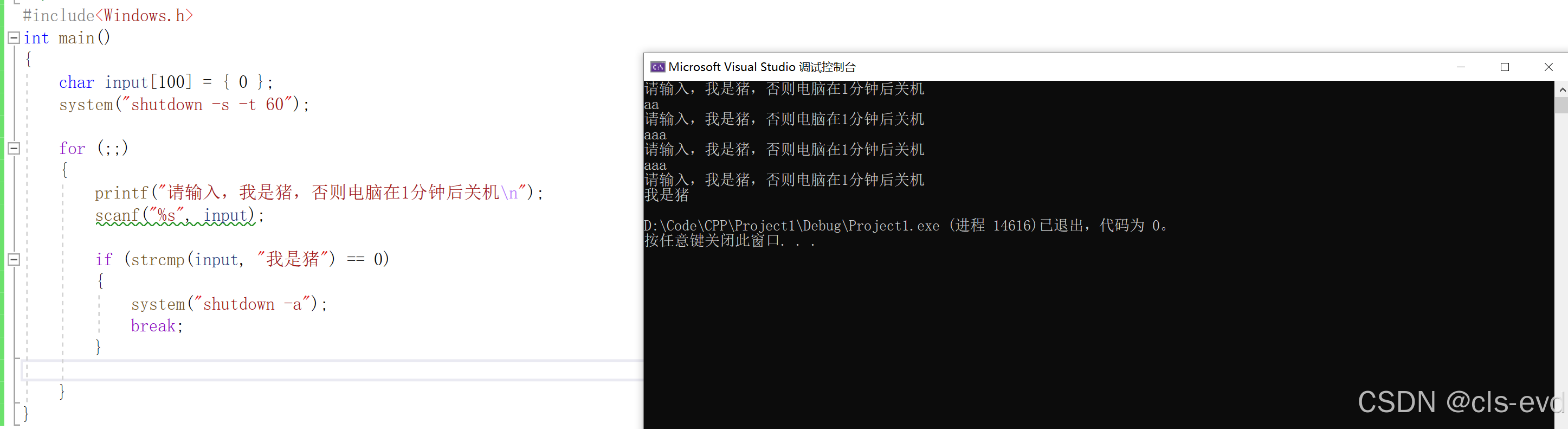
一个关机程序:如果想整蛊你的朋友,请把debug改成release,然后把在release下编译好的程序发给你的朋友。
使用goto版,system就是系统调用,在Windows终端输入的指令
不使用goto版本,其实就是用循环代替goto
猜数字游戏
rand,srand,time函数的使用
rand函数是一个随机数生产的函数,但是我们直接使用,就会发现它每次生产的数字都是一样的
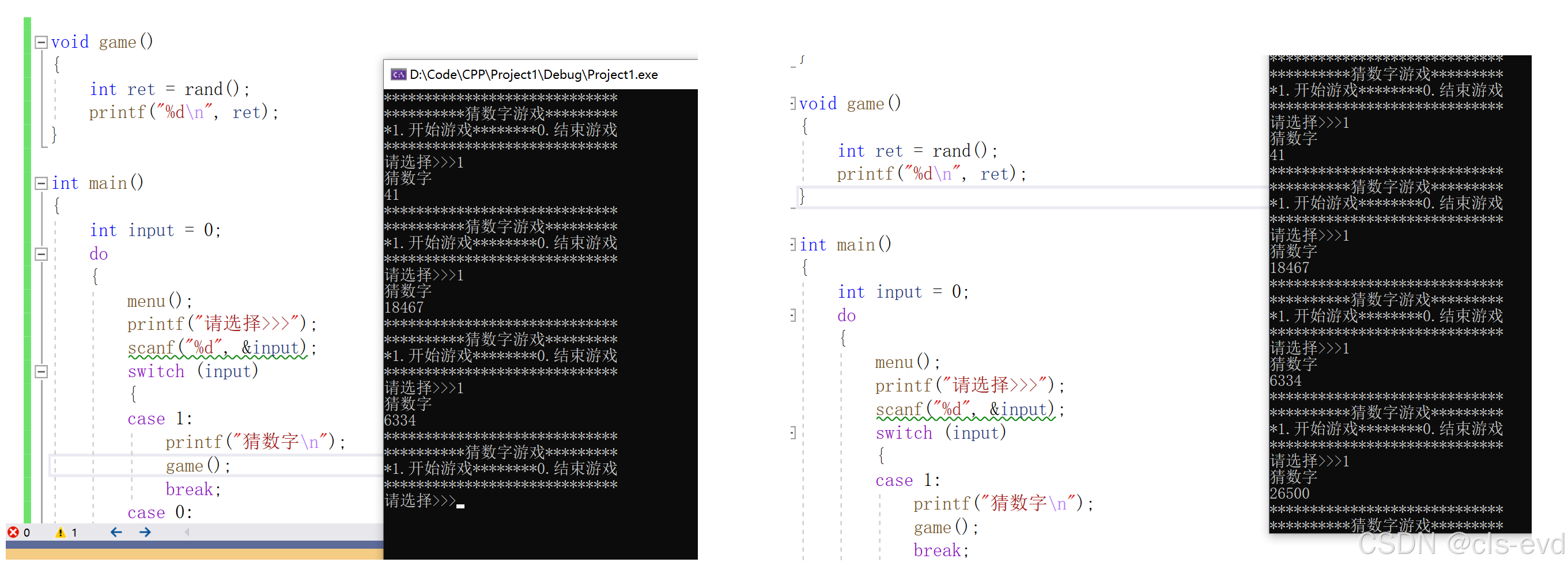
这时候就需要对rand进行一个初始化,需要用到srand函数
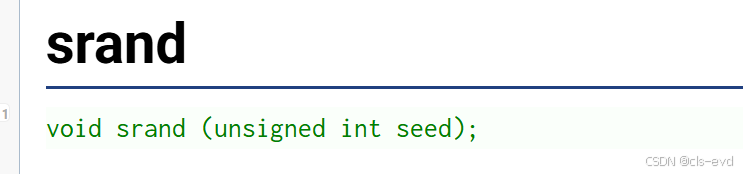
srand的作用就是设置rand的起点
我们可以看到随着srand的参数不同,生成的随机数确实发生了变化
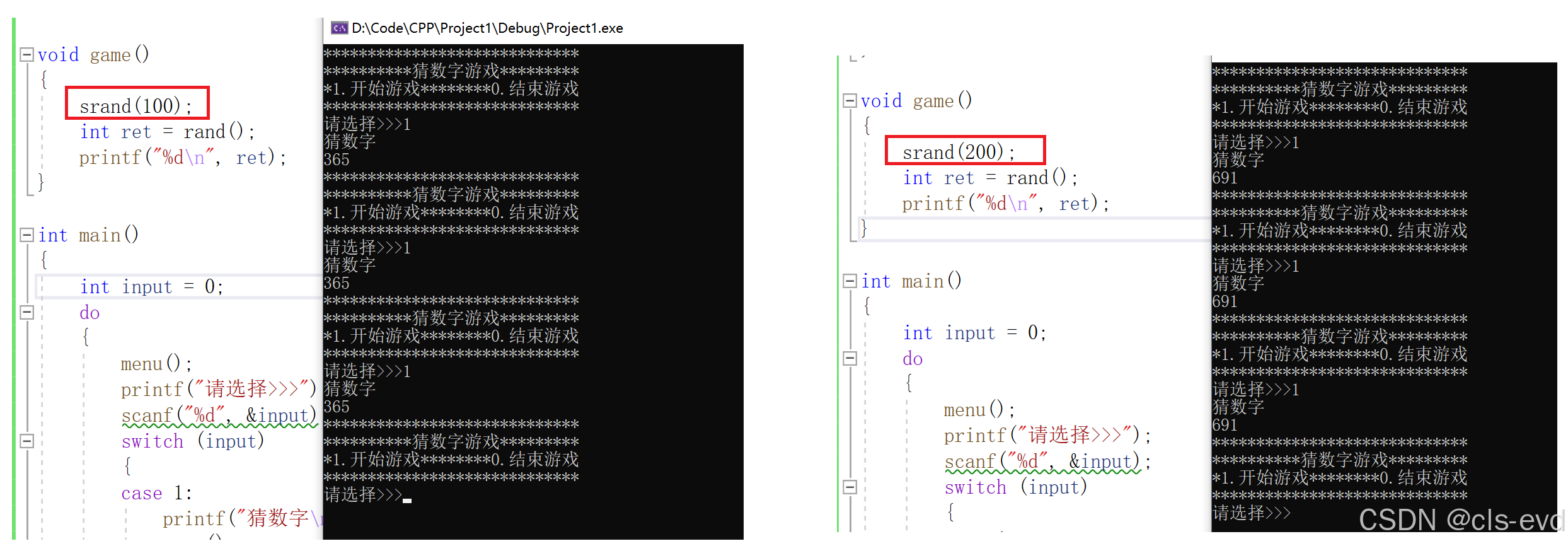
因此要想让ret不断的变化,就必须保证srand里面也是一个随机数,这貌似与我们正在做的形成了一个悖论,我们想要的就是一个随机数,而srand的参数也需要一个随机数。
这个时候就需要用到时间戳,时间戳(Timestamp)是指从格林威治时间1970年1月1日00时00分00秒起至现在的总秒数。这个概念在计算机科学和信息技术中非常重要,因为它为数据提供了一个独特的时间参考。时间戳通常用于记录事件发生的确切时间,是一种时间记录的方式,可以用来验证数据在某个特定时间点之前已经存在。
因此时间戳是每时每刻都在不断变化的,所以他就是一个很好的随机数。
C语言中的时间戳,指针直接填空指针即可
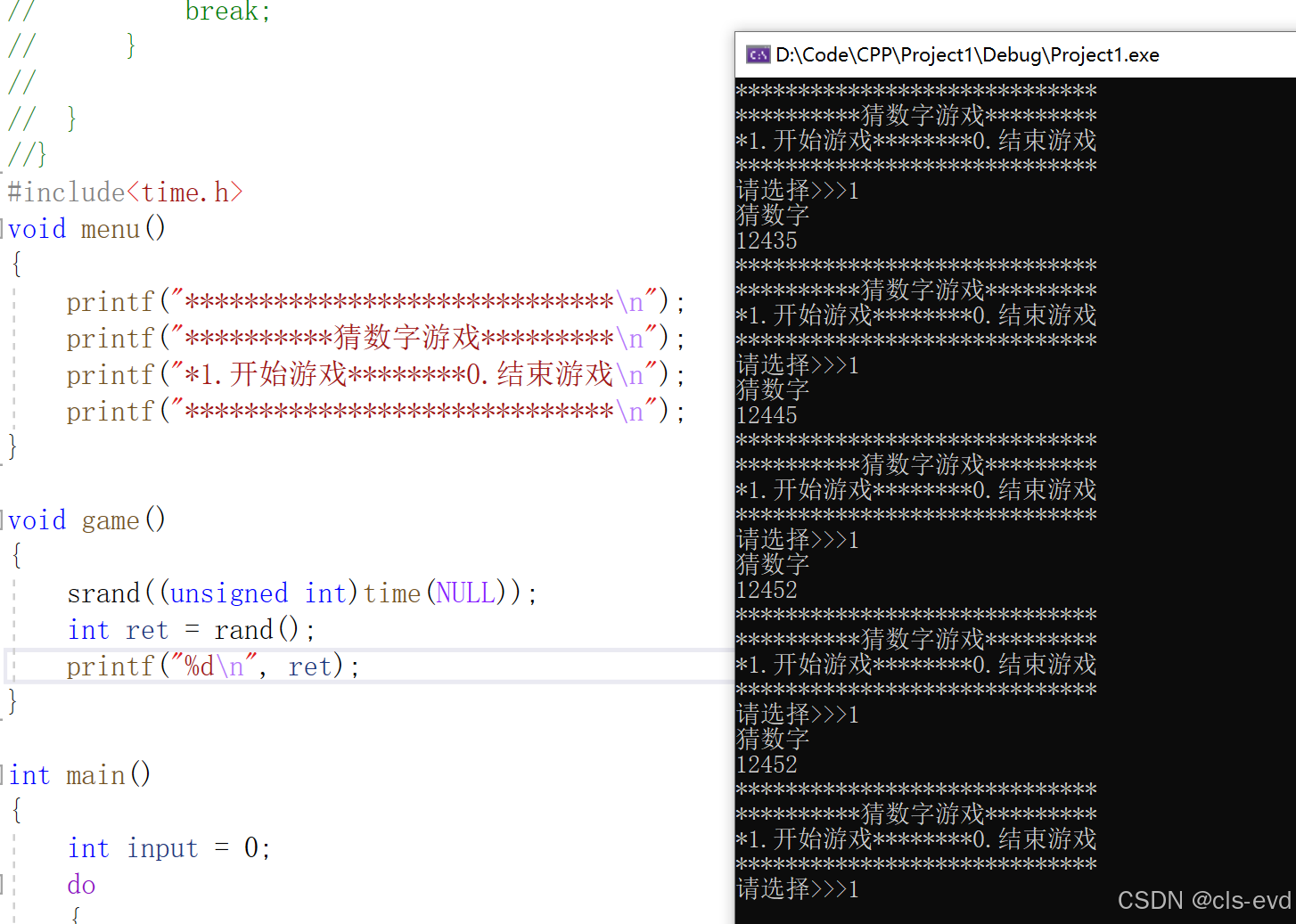
我们看到现在生成的随机数就在不断的变化,同时我们也发现了一个新的问题,如果快速的输入1,生成的数字就是一样的,这倒也不难理解,因为连续输入1的间隙小于1秒的话,时间戳不变,所以生成的数字是一样的。所以我们就可以把srand放到主函数里,只初始化一次随机数的种子,这样就可以保证每次调用game()的时候,生成的随机数都是不一样的。
具体解释:
伪随机数生成器的工作原理
// 内部有一个"当前状态"变量
static unsigned long next = 1; // 这是内部状态// srand() 的作用:重置这个状态
void srand(unsigned int seed) {next = seed;
}// rand() 的作用:基于当前状态计算下一个数,并更新状态
int rand() {next = next * 1103515245 + 12345; // 更新状态return (next / 65536) % 32768; // 返回随机数
}情况1:每次调用都srand() - 会产生相同随机数
时间: 14:30:25 (时间戳: 1642334625)
用户按1 -> game() -> srand(1642334625) -> 状态重置为1642334625 -> rand() -> 返回12345
时间: 14:30:25 (还是同一秒!时间戳: 1642334625)
用户又按1 -> game() -> srand(1642334625) -> 状态又重置为1642334625 -> rand() -> 又返回12345
情况2:只在开始时srand() - 会产生不同随机数
程序启动: 14:30:25
main() -> srand(1642334625) -> 状态设置为1642334625
用户按1 -> game() -> rand() -> 状态从1642334625变化 -> 返回12345
内部状态现在变成了: 1854928421
用户又按1 -> game() -> rand() -> 状态从1854928421变化 -> 返回67890
内部状态现在变成了: 794738462
始终是rand()中的next在变化!所以只初始化一次srand()就可以解决这个问题
完整代码
#include<time.h>
void menu()
{printf("*****************************\n");printf("**********猜数字游戏*********\n");printf("*1.开始游戏********0.结束游戏\n");printf("*****************************\n");
}void game()
{int guess = 0;int ret = rand()%100+1; //0-100//printf("%d\n", ret);for (;;){printf("请猜数字>:");scanf("%d", &guess);if (guess< ret){printf("猜小了\n");}else if (guess > ret){printf("猜大了\n");}else{printf("猜对了\n");break;}}
}int main()
{srand((unsigned int)time(NULL));int input = 0;do{menu();printf("请选择>>>");scanf("%d", &input);switch (input){case 1:printf("猜数字\n");game();break;case 0:printf("退出游戏\n");break;default:printf("输入错误,请重新输入\n");break;}} while (input);
}