基于pytorch深度学习笔记:1.LeNetAlexNet
本文来学习两个元老级别的神经网络结构:LeNet和AlexNet,两者都是专门针对图像的卷积神经网络,我们将通过这两个网络深入了解细节网络参数和如何在pytorch框架中完成对于文章中网络的复现搭建。
LeNet
LeNet是1989年由贝尔实验室的研究员Yann LeCun提出的网络架构,最早是用于处理手写数字识别。可以认为是最早的卷积神经网络的应用,时至今日也被用于初学者的入门学习。
1.LeNet的网络架构
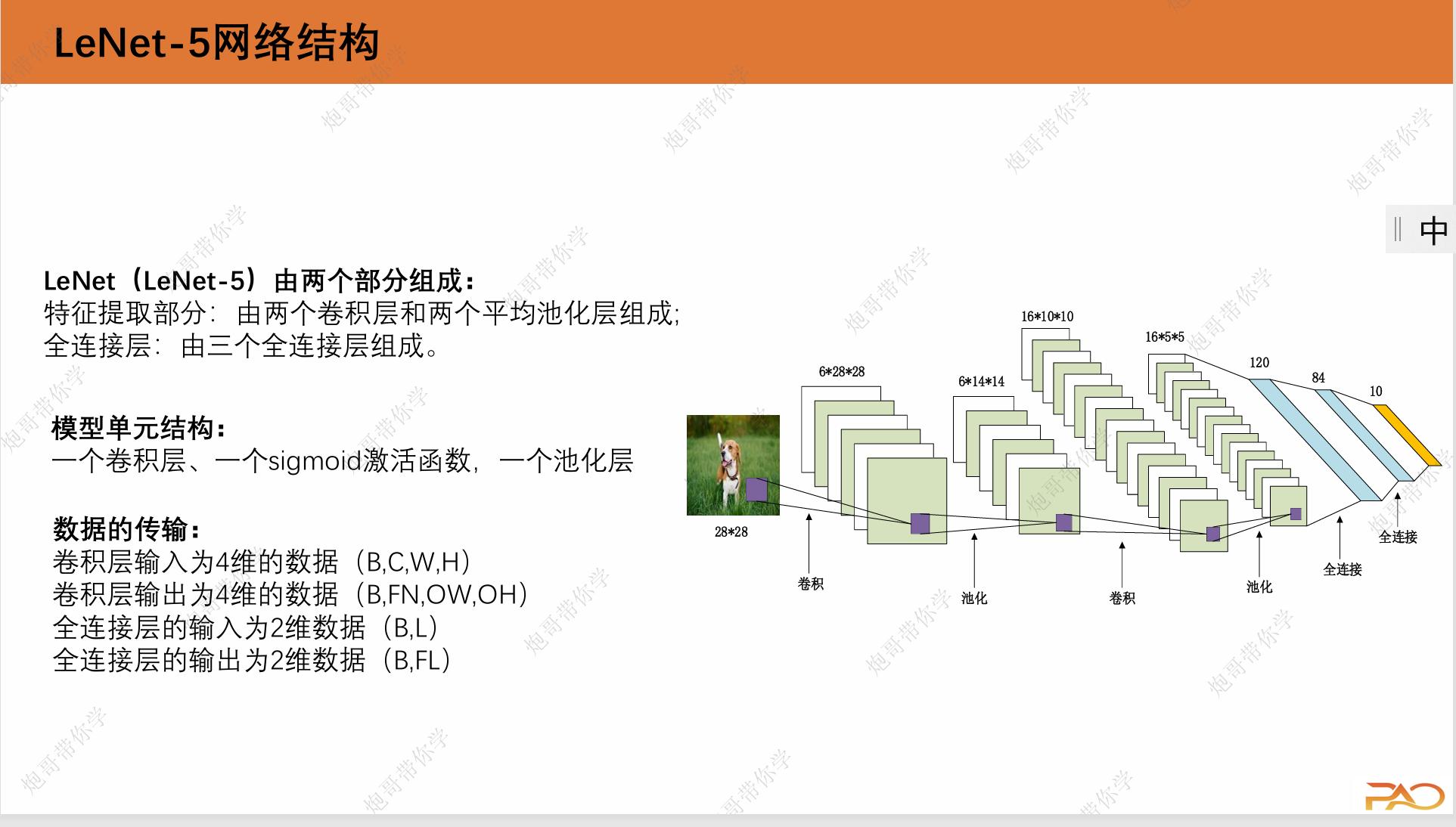
如上图所示,LeNet的网络架构由特征提取部分:两个卷积层和两个平均池化层以及全连接层:三个全连接层,右图所示的是图像数据处理过程中的形态变化过程。LeNet网络也叫LeNet-5,原因是它有5个有参数的网络层。这里可能有同学会有一个问题,也是我初学的时候经常会想的一个问题:神经网络的网络架构是怎么确定的?是否有一个明确的理论指导去优化它?这个答案其实是稍微有点令人失望的,大部分情况下,网络架构的优化更偏向于工程的经验,换言之,很多时候网络架构是“试”出来的,这也就是为什么我们经常看到搞深度学习的称其为“炼丹”或者“黑盒子”,因为这其中的优化可解释性确实不强,可解释性也是现在深度学习火热发展的一个方向。
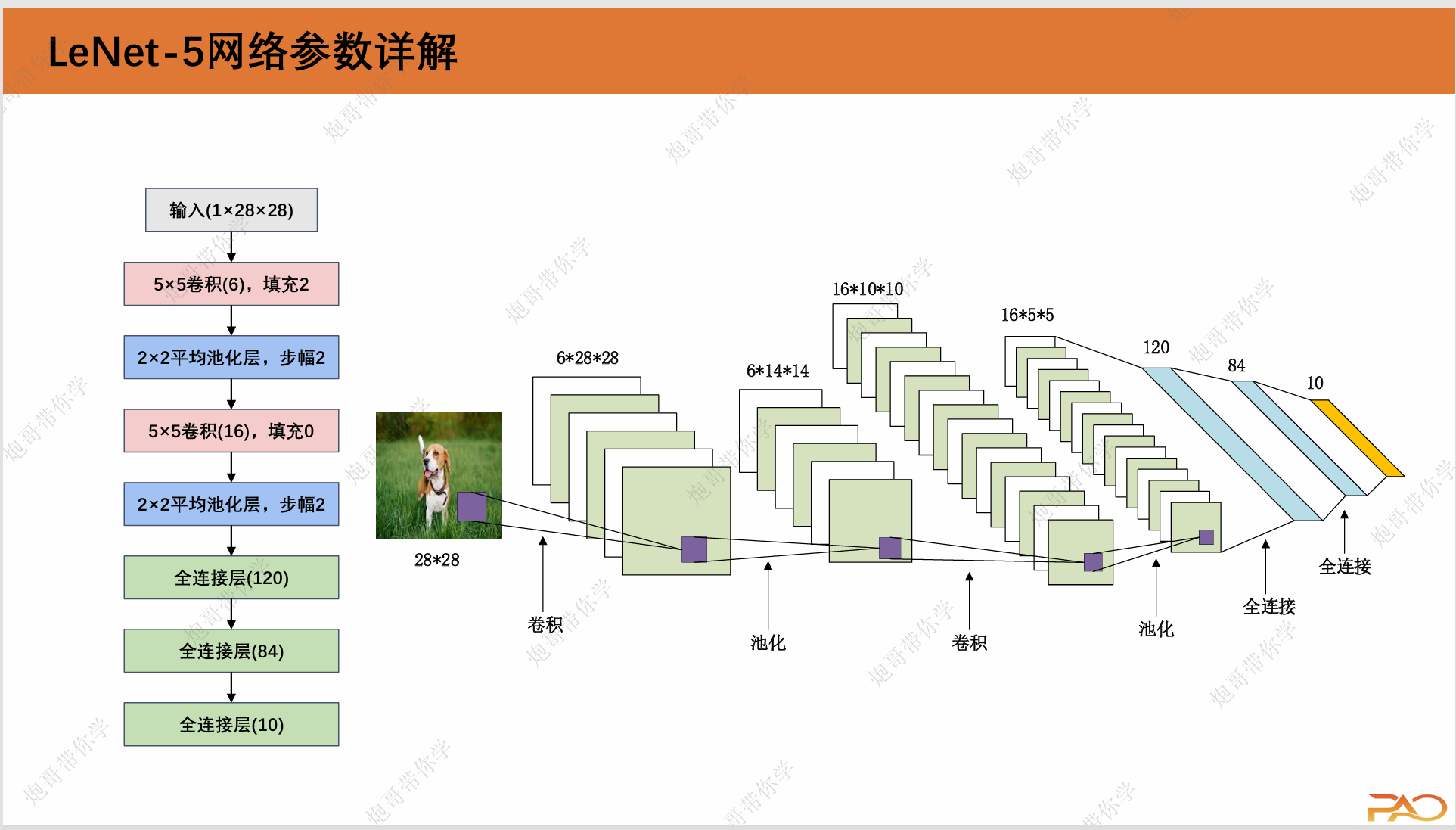
2.LeNet的网络参数
LeNet网络架构如下图所示:

3.LeNet的pytorch代码实现:
import torch
from torch import nn
from torchsummary import summaryclass LeNet(nn.Module):def __init__(self):super(LeNet,self).__init__()self.c1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5,padding=2)self.sig = nn.Sigmoid()self.s2 = nn.AvgPool2d(kernel_size=2,stride=2)self.c3 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5)self.s4 = nn.AvgPool2d(kernel_size=2,stride=2)self.flatten = nn.Flatten()self.f5 = nn.Linear(400,120)self.f6 = nn.Linear(120, 84)self.f7 = nn.Linear(84, 10)def forward(self,x):x = self.sig(self.c1(x))x = self.s2(x)x = self.sig(self.c3(x))x = self.s4(x)x = self.flatten(x)x = self.f5(x)x = self.f6(x)x = self.f7(x)return xif __name__ =="__main__":device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = LeNet().to(device)print(summary(model,(1,28,28)))这里同时也给出模型的训练和测试代码,这部分是通用的,所有的网络架构都可以用下面两个代码进行训练和测试,只需要改变一些名字即可,我将在这里给出并对一些超参数进行解释,后面不再赘述。
model_train:
import copy
import time
import torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import torch.utils.data as Data
import numpy as np
import matplotlib.pyplot as plt
from model import LeNet
import torch.nn as nn
import pandas as pddef train_val_data_process():train_data = FashionMNIST(root='./data',train=True,transform=transforms.Compose([transforms.Resize(size=28), transforms.ToTensor()]),download=True)train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])train_dataloader = Data.DataLoader(dataset=train_data,batch_size=32,shuffle=True,num_workers=0)val_dataloader = Data.DataLoader(dataset=val_data,batch_size=32,shuffle=True,num_workers=0)return train_dataloader, val_dataloaderdef train_model_process(model, train_dataloader, val_dataloader, num_epochs):# 设定训练所用到的设备,有GPU用GPU没有GPU用CPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 使用Adam优化器,学习率为0.001optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 损失函数为交叉熵函数criterion = nn.CrossEntropyLoss()# 将模型放入到训练设备中model = model.to(device)# 复制当前模型的参数best_model_wts = copy.deepcopy(model.state_dict())# 初始化参数# 最高准确度best_acc = 0.0# 训练集损失列表train_loss_all = []# 验证集损失列表val_loss_all = []# 训练集准确度列表train_acc_all = []# 验证集准确度列表val_acc_all = []# 当前时间since = time.time()for epoch in range(num_epochs):print("Epoch {}/{}".format(epoch, num_epochs-1))print("-"*10)# 初始化参数# 训练集损失函数train_loss = 0.0# 训练集准确度train_corrects = 0# 验证集损失函数val_loss = 0.0# 验证集准确度val_corrects = 0# 训练集样本数量train_num = 0# 验证集样本数量val_num = 0# 对每一个mini-batch训练和计算for step, (b_x, b_y) in enumerate(train_dataloader):# 将特征放入到训练设备中b_x = b_x.to(device)# 将标签放入到训练设备中b_y = b_y.to(device)# 设置模型为训练模式model.train()# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测output = model(b_x)# 查找每一行中最大值对应的行标pre_lab = torch.argmax(output, dim=1)# 计算每一个batch的损失函数loss = criterion(output, b_y)# 将梯度初始化为0optimizer.zero_grad()# 反向传播计算loss.backward()# 根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值的作用optimizer.step()# 对损失函数进行累加train_loss += loss.item() * b_x.size(0)# 如果预测正确,则准确度train_corrects加1train_corrects += torch.sum(pre_lab == b_y.data)# 当前用于训练的样本数量train_num += b_x.size(0)for step, (b_x, b_y) in enumerate(val_dataloader):# 将特征放入到验证设备中b_x = b_x.to(device)# 将标签放入到验证设备中b_y = b_y.to(device)# 设置模型为评估模式model.eval()# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测output = model(b_x)# 查找每一行中最大值对应的行标pre_lab = torch.argmax(output, dim=1)# 计算每一个batch的损失函数loss = criterion(output, b_y)# 对损失函数进行累加val_loss += loss.item() * b_x.size(0)# 如果预测正确,则准确度train_corrects加1val_corrects += torch.sum(pre_lab == b_y.data)# 当前用于验证的样本数量val_num += b_x.size(0)# 计算并保存每一次迭代的loss值和准确率# 计算并保存训练集的loss值train_loss_all.append(train_loss / train_num)# 计算并保存训练集的准确率train_acc_all.append(train_corrects.double().item() / train_num)# 计算并保存验证集的loss值val_loss_all.append(val_loss / val_num)# 计算并保存验证集的准确率val_acc_all.append(val_corrects.double().item() / val_num)print("{} train loss:{:.4f} train acc: {:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))print("{} val loss:{:.4f} val acc: {:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))if val_acc_all[-1] > best_acc:# 保存当前最高准确度best_acc = val_acc_all[-1]# 保存当前最高准确度的模型参数best_model_wts = copy.deepcopy(model.state_dict())# 计算训练和验证的耗时time_use = time.time() - sinceprint("训练和验证耗费的时间{:.0f}m{:.0f}s".format(time_use//60, time_use%60))# 选择最优参数,保存最优参数的模型torch.save(best_model_wts, "D:/360MoveData/Users/86188/Desktop/pytorch/LeNet/best_model.pth")train_process = pd.DataFrame(data={"epoch":range(num_epochs),"train_loss_all":train_loss_all,"val_loss_all":val_loss_all,"train_acc_all":train_acc_all,"val_acc_all":val_acc_all,})return train_processdef matplot_acc_loss(train_process):# 显示每一次迭代后的训练集和验证集的损失函数和准确率plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(train_process['epoch'], train_process.train_loss_all, "ro-", label="Train loss")plt.plot(train_process['epoch'], train_process.val_loss_all, "bs-", label="Val loss")plt.legend()plt.xlabel("epoch")plt.ylabel("Loss")plt.subplot(1, 2, 2)plt.plot(train_process['epoch'], train_process.train_acc_all, "ro-", label="Train acc")plt.plot(train_process['epoch'], train_process.val_acc_all, "bs-", label="Val acc")plt.xlabel("epoch")plt.ylabel("acc")plt.legend()plt.show()if __name__ == '__main__':# 加载需要的模型LeNet = LeNet()# 加载数据集train_data, val_data = train_val_data_process()# 利用现有的模型进行模型的训练train_process = train_model_process(LeNet, train_data, val_data, num_epochs=10)matplot_acc_loss(train_process)这里需要着重说明一下batch_size和num_worker两个参数,batch_size对应一种输入机制,它将图像先成批打包,再输入网络,batch_size这里对应的就是每次打包的照片有多少张,该参数设置得越高,训练速度会相应变快,但对应的gpu的压力会变大。另外num_worker对应的是几个线程同时进行工作,我的gpu比较弱(/(ㄒoㄒ)/),所以这里设置batch_size==32,num_worker==0(只有一个进程即主进程的意思),
如果大家运行时出现“页面文件不够大”的报错时可以参考这样的设置。
model_test:
import torch
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from model import LeNetdef test_data_process():test_data = FashionMNIST(root='./data',train=False,transform=transforms.Compose([transforms.Resize(size=28), transforms.ToTensor()]),download=True)test_dataloader = Data.DataLoader(dataset=test_data,batch_size=1,shuffle=True,num_workers=0)return test_dataloaderdef test_model_process(model, test_dataloader):# 设定测试所用到的设备,有GPU用GPU没有GPU用CPUdevice = "cuda" if torch.cuda.is_available() else 'cpu'# 讲模型放入到训练设备中model = model.to(device)# 初始化参数test_corrects = 0.0test_num = 0# 只进行前向传播计算,不计算梯度,从而节省内存,加快运行速度with torch.no_grad():for test_data_x, test_data_y in test_dataloader:# 将特征放入到测试设备中test_data_x = test_data_x.to(device)# 将标签放入到测试设备中test_data_y = test_data_y.to(device)# 设置模型为评估模式model.eval()# 前向传播过程,输入为测试数据集,输出为对每个样本的预测值output= model(test_data_x)# 查找每一行中最大值对应的行标pre_lab = torch.argmax(output, dim=1)# 如果预测正确,则准确度test_corrects加1test_corrects += torch.sum(pre_lab == test_data_y.data)# 将所有的测试样本进行累加test_num += test_data_x.size(0)# 计算测试准确率test_acc = test_corrects.double().item() / test_numprint("测试的准确率为:", test_acc)if __name__=="__main__":# 加载模型model = LeNet()model.load_state_dict(torch.load('best_model.pth'))# 加载测试数据test_dataloader = test_data_process()# 加载模型测试的函数test_model_process(model, test_dataloader)3.LeNet-5总结
1、卷积神经网络(CNN)是一类使用卷积层的网络。
2、在卷积神经网络中,组合使用卷积层、非线性激活函数sigmoid 和全连接层。
3、为了构造高性能的卷积神经网络,我们通常对卷积层进行排列, 逐渐降低其表示的空间分辨率,同时增加通道数。
4、在传统的卷积神经网络中,卷积块编码得到的表征在输出之前 需由一个或多个全连接层进行处理。
5、LeNet是最早发布的卷积神经网络之一,它的问世有开创意义
AlexNet
在LeNet提出后,卷积神经网络在计算机视觉和机器学习领域中很有名气。但卷积神经网络并没有主导这些领域。这是因为虽然LeNet在小数据集上取得了很好的效果,但是在更大、更真实的数据集上训练卷积神经网络的性能和可行性还有待研究。事实上,在上世纪90年代初到2012年之间的大部分时间里,神经网络往往 被其他机器学习方法超越,如支持向量机。 而在2012年,ILSVRC大规模视觉识别挑战赛(Imagenet Large ScaleVisualRecognitionChallenge), AlexNet首次引入了深度卷积神经网络,并获得2012的大规模视觉识别挑战赛的冠军,这标志着深度学习在计算机视觉领域的崭露头角。可以说,AlexNet就是那个一拳打开了深度学习前景的网络。
1.AlexNet网络架构
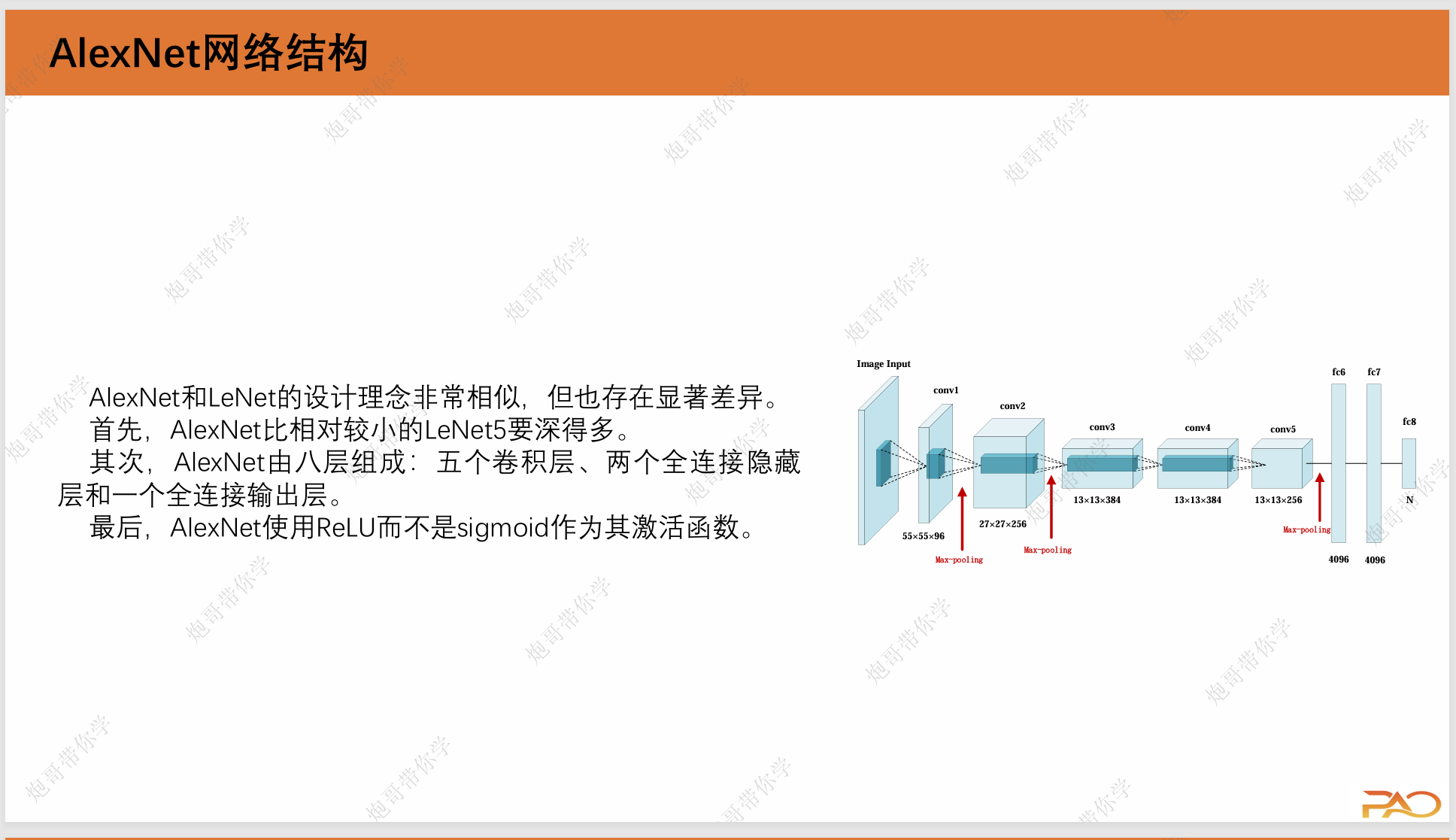
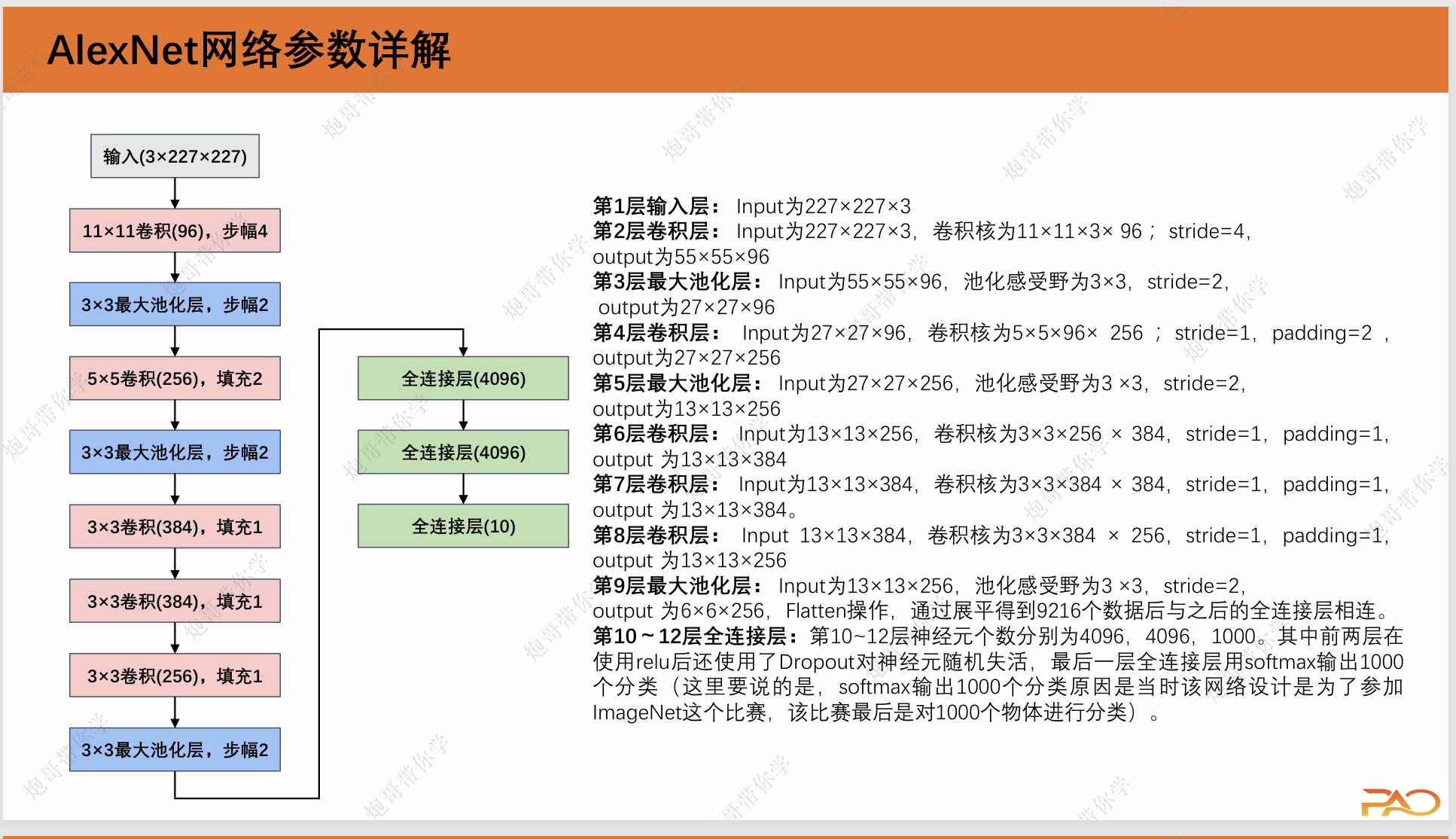
2.Alex网络参数详解
3.AlexNet中引入的一些重要技巧
3.1 Dropout
AlexNet由于参数量的增大,当处理一些简单任务时,很容易发生过拟合的现象,这个时候我们就需要引入这个Dropout机制,它实际上是我们人为地隐藏一部分神经元以达到这个降低参数量的效果。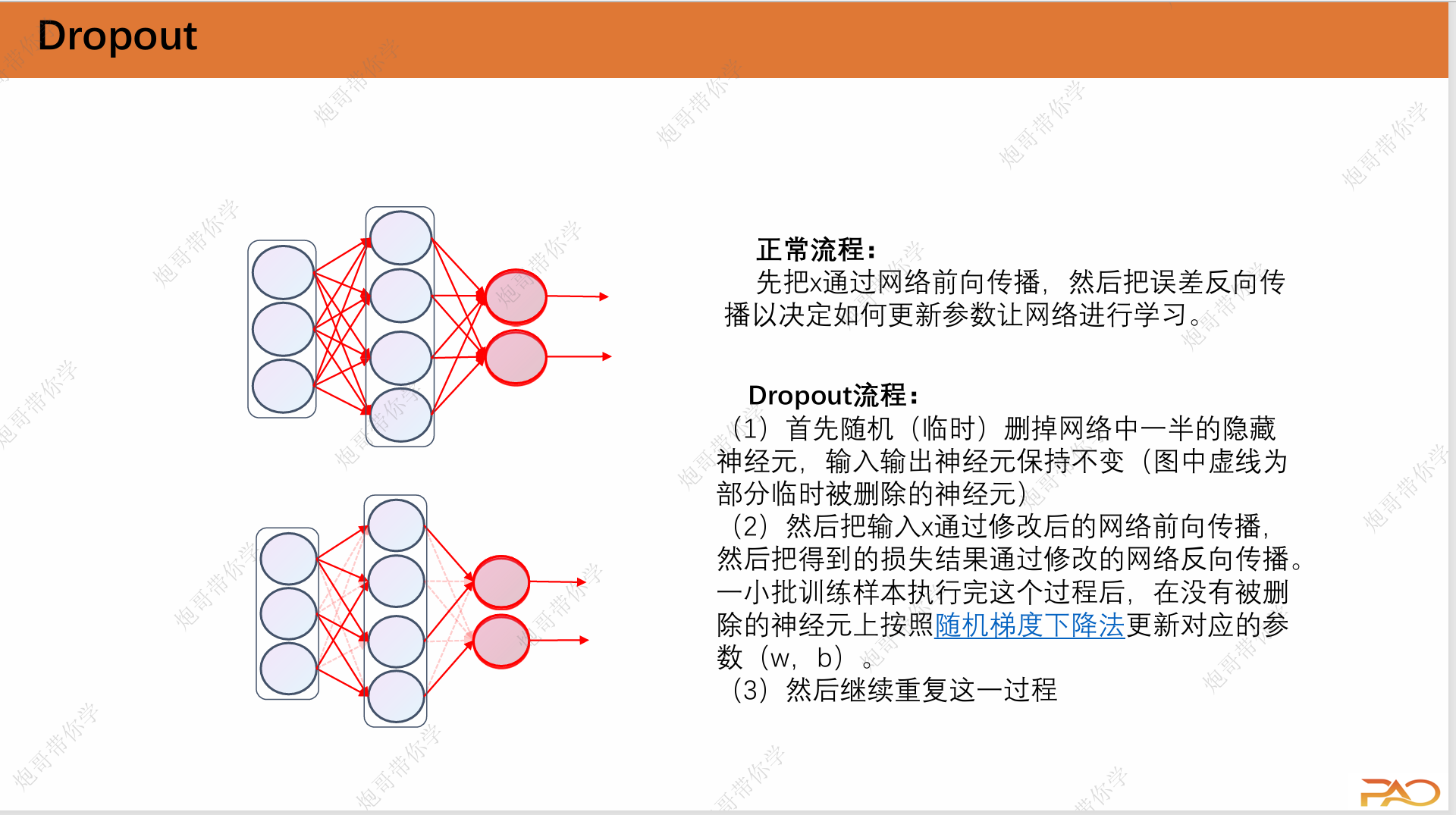
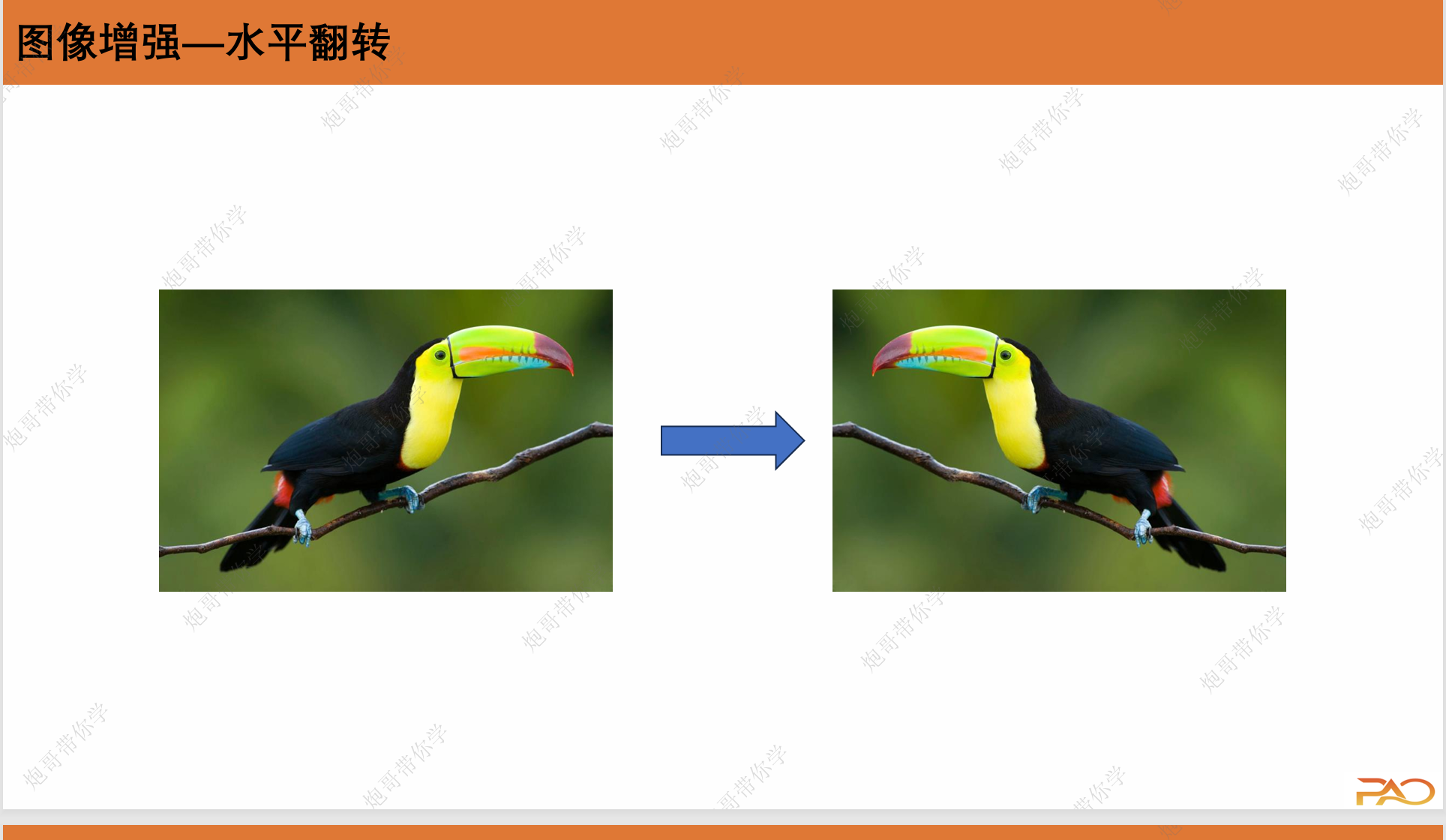
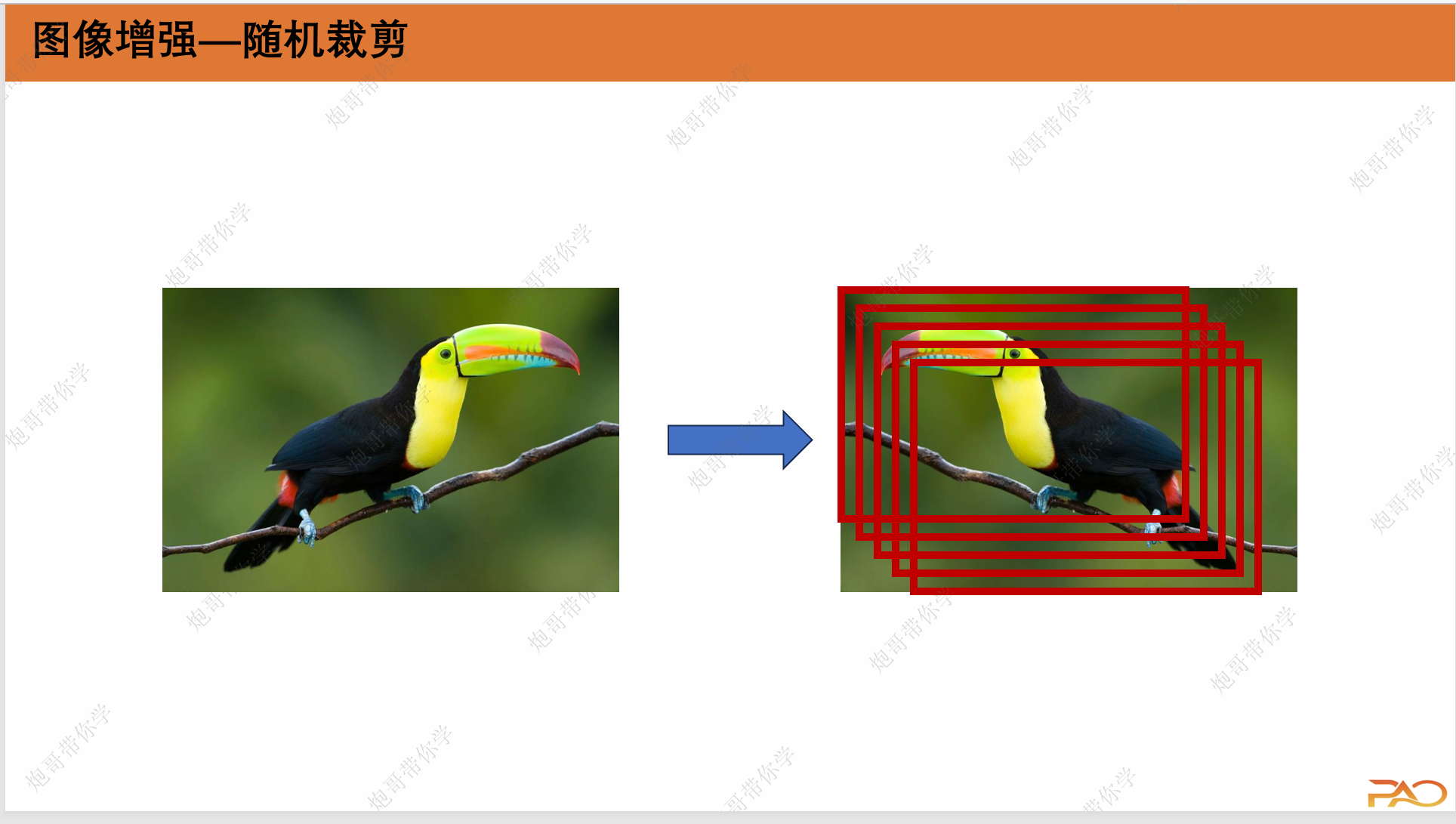
3.2 图像增强
这一部分是为了解决数据量较少的问题,我们通过对原片进行翻转、裁剪以及PCA等等手段对数据进行扩充。

4.AlexNet在pytorch中代码实现
import torch
from torch import nn
from torchsummary import summary
import torch.nn.functional as Fclass AlexNet(nn.Module):def __init__(self):super(AlexNet,self).__init__()self.ReLu = nn.ReLU()self.c1 = nn.Conv2d(in_channels=1, out_channels=96,kernel_size=11,stride=4)self.s2 = nn.MaxPool2d(kernel_size=3,stride=2)self.c3 = nn.Conv2d(in_channels=96,out_channels=256,kernel_size=5,padding=2)self.s4 = nn.MaxPool2d(kernel_size=3,stride=2)self.c5 = nn.Conv2d(in_channels=256,out_channels=384,kernel_size=3,padding=1)self.c6 = nn.Conv2d(in_channels=384,out_channels=384,kernel_size=3,padding=1)self.c7 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1)self.s8 = nn.MaxPool2d(kernel_size=3, stride=2)self.flatten = nn.Flatten()self.f1 = nn.Linear(6*6*256,4096)self.f2 = nn.Linear(4096,4096)self.f3 = nn.Linear(4096,10)def forward(self,x):x = self.ReLu(self.c1(x))x = self.s2(x)x = self.ReLu(self.c3(x))x = self.s4(x)x = self.ReLu(self.c5(x))x = self.ReLu(self.c6(x))x = self.ReLu(self.c7(x))x = self.s8(x)x = self.flatten(x)x = self.ReLu(self.f1(x))x = F.dropout(x,0.5)x = self.ReLu(self.f2(x))x = F.dropout(x,0.5)x = self.f3(x)return xif __name__ == "__main__":device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = AlexNet().to(device)print(summary(model,(1,227,227)))5.AlexNet总结
1、AlexNet和LeNet设计上有一脉相承之处,也有区别。为了适应 ImageNet中大尺寸图像,其使用了大尺寸的卷积核,从11×11到5×5 到3×3,AlexNet的卷积层和全连接层也带来更多的参数6000万,这一全新设计的CNN结构在图像分类领域取大幅超越传统机器学习,自此之后CNN在图像分类领域被广泛应用。
2、使用了Relu替换了传统的sigmoid或tanh作为激活函数,大大加快了收敛,减少了模型训练耗时。
3、使用了Dropout,提高了模型的准确度,减少过拟合,这一方式再后来也被广泛采用。
4、在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化, AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且 AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会 有重叠和覆盖,提升了特征的丰富性。
5、使用数据了2种数据扩增技术,大幅增加了训练数据,增加模型 鲁棒性,减少过拟合。
6、使用了LRN正则化、多GPU并行训练的模式(不过之后并没有被 广泛应用