deep learning(李宏毅)--(六)--loss
一,关于分类问题及其损失函数的一些讨论。
在构建分类模型是,我们的最后一层往往是softmax函数(起到归一化的作用),如果是二分类问题也可以用sigmoid函数。
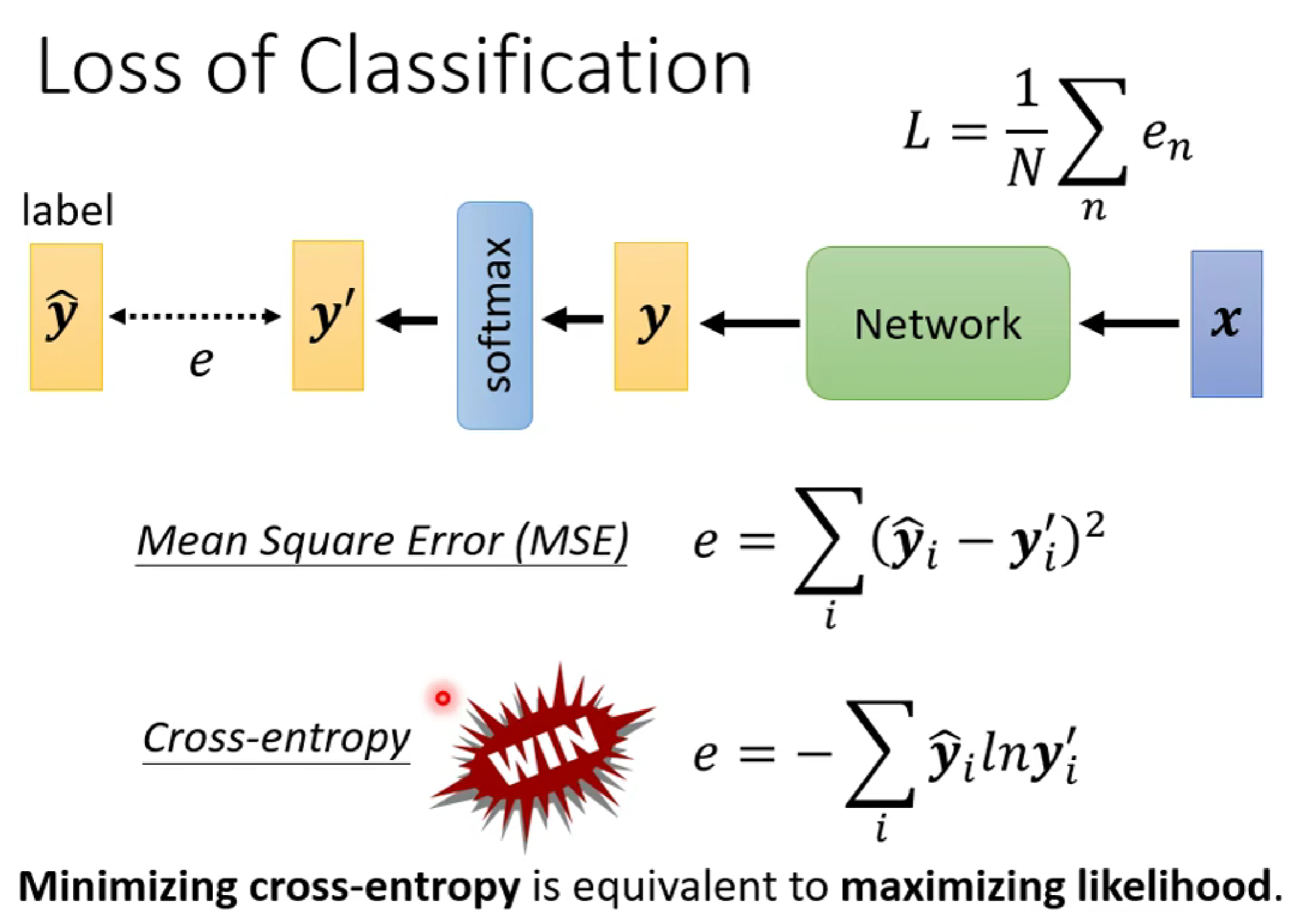
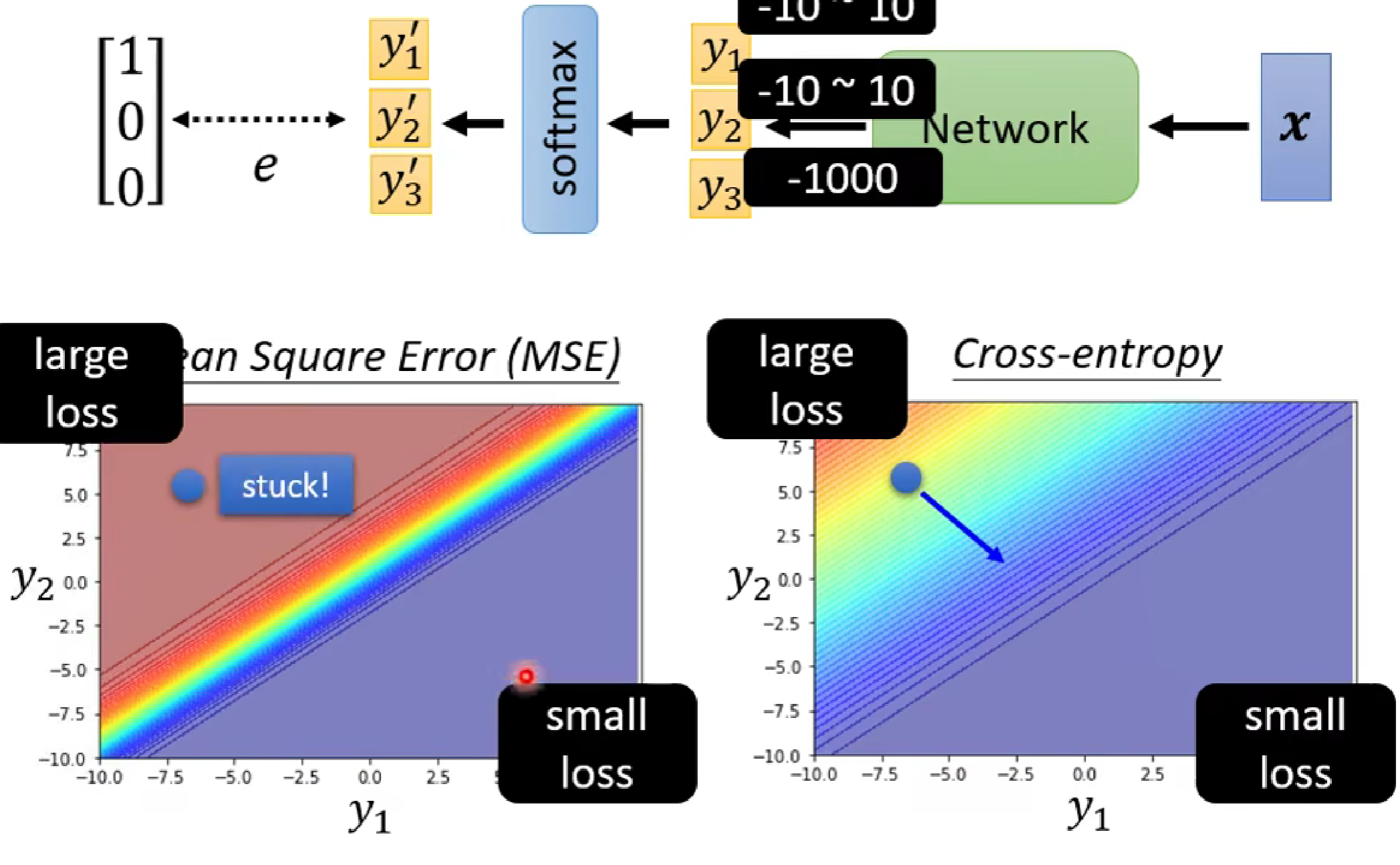
在loss函数的选择上,一般采用交叉熵损失函数(cross-entropy),为什么呢?因为交叉熵损失函数更容易使得optimisization到达低loss(如下图:cross-entropy的梯度图更为陡)
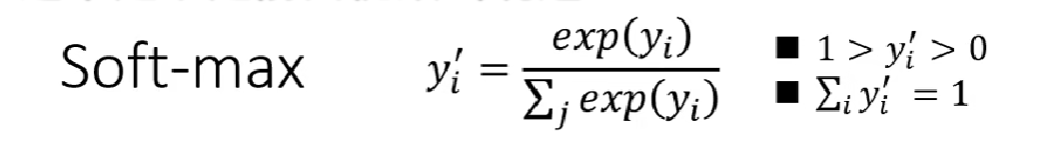
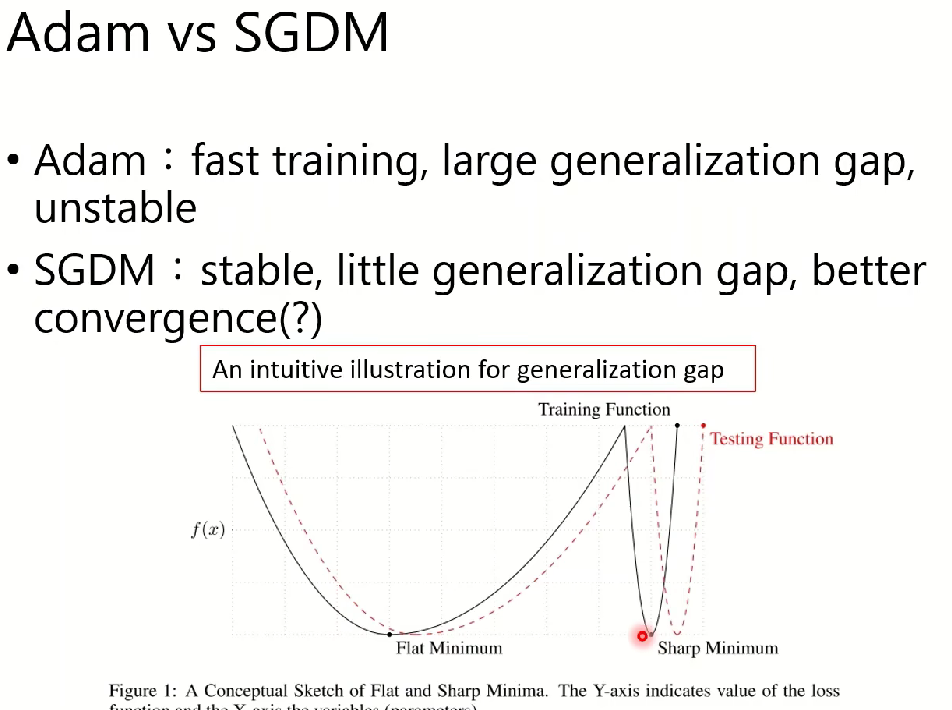
二,对于Adam和SGDM梯度优化算法的比较
Adam:训练速度很快,但是收敛效果不佳
SGDM:训练速度平稳,收敛性较好
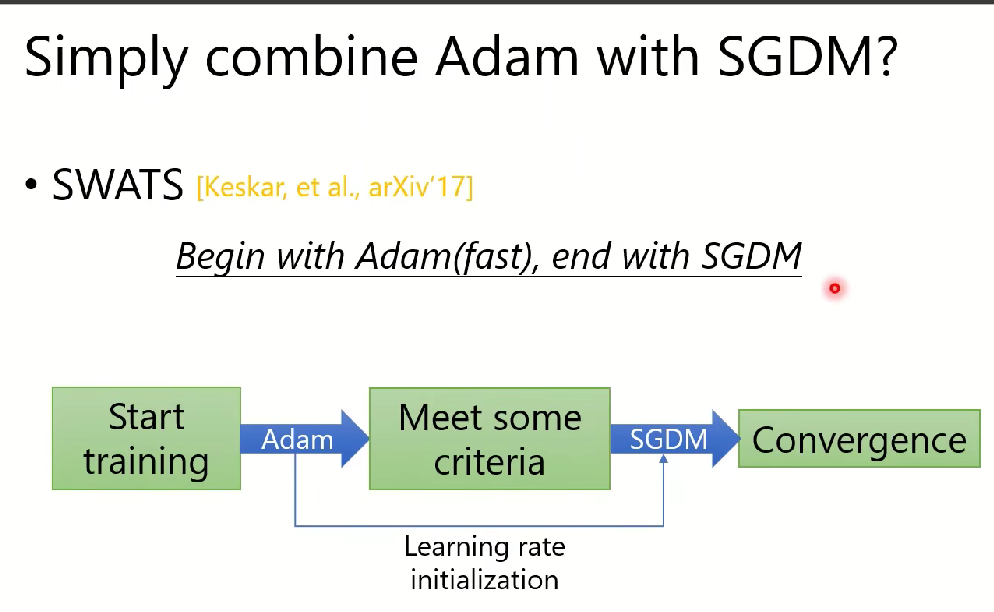
SWATS算法:Adam和SGDM算法的结合:(训练开始用Adam,在收敛时用SGDM)
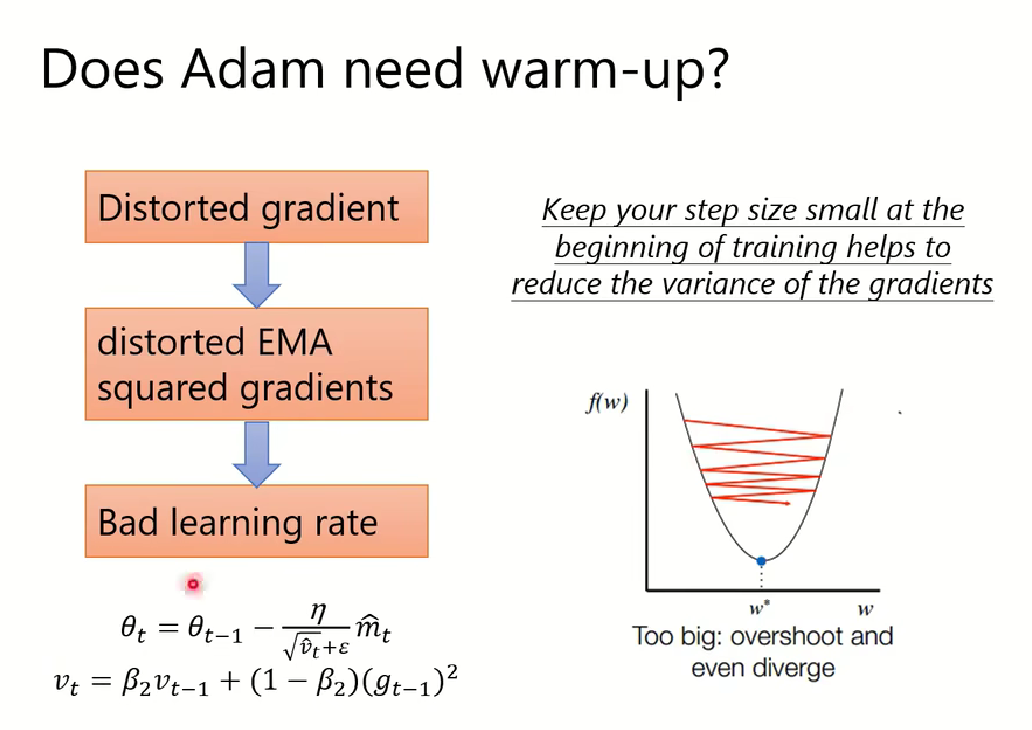
注意:使用Adam算法初始不稳定,需要进行预加热(Warm up) .
三,Radam算法与SWATS算法比较:

后面就有点听不懂了,以后了解更多再来听吧,做个记号。
(选修)To Learn More - Optimization for Deep Learning (2_2)_哔哩哔哩_bilibili
笔记先做到这hh,有的笨,当先了解了。