python网络爬虫(第二步:安装浏览器驱动,驱动浏览器加载网页、批量下载资源)
python网络爬虫(第二步:安装浏览器驱动,驱动浏览器加载网页、批量下载资源)
(学习第一步在这里)
python网络爬虫(第一步:网络爬虫库、robots.txt规则(防止犯法)、查看获取网页源代码)-CSDN博客
安装浏览器驱动
一:
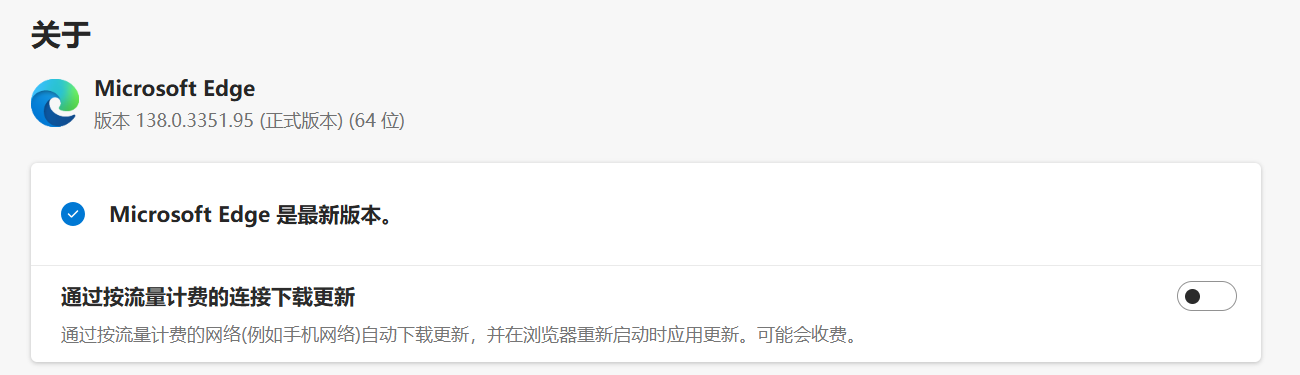
查看浏览器版本:
二:
安装对应版本驱动器
Microsoft Edge WebDriver | Microsoft Edge Developer
打开往下翻
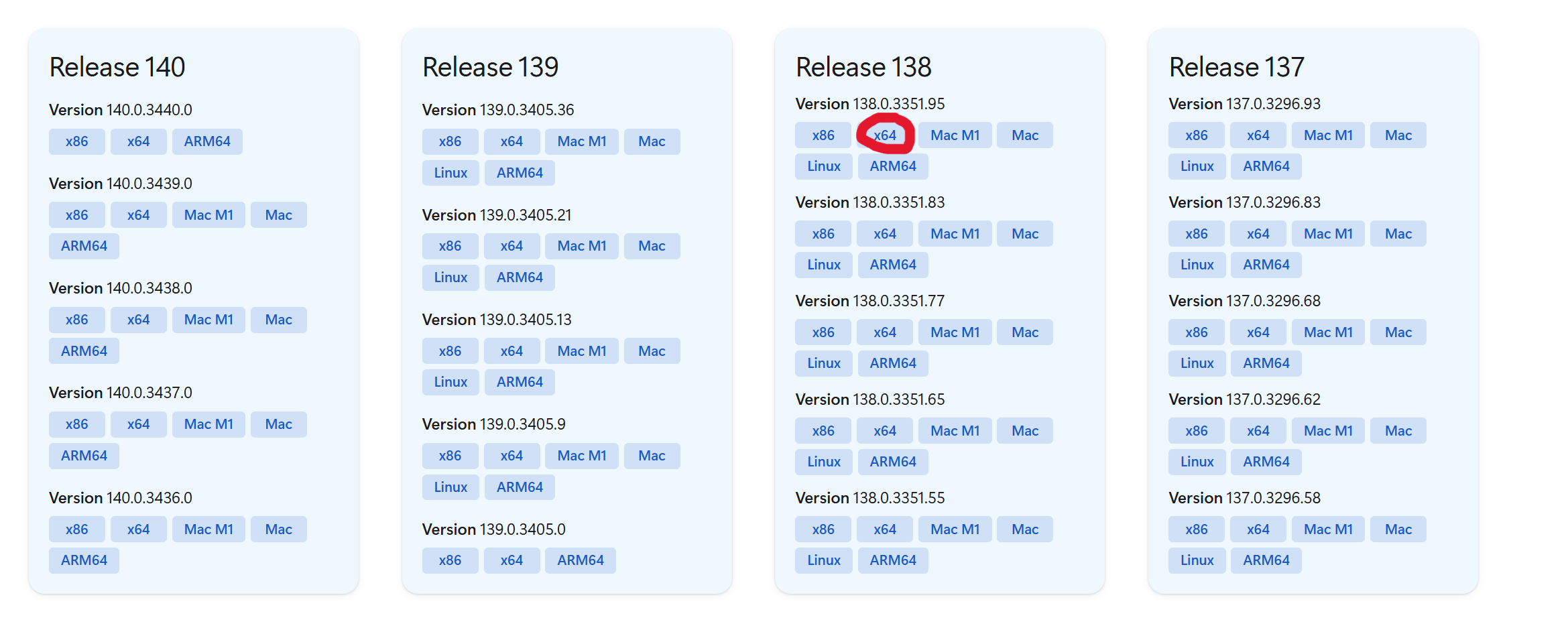
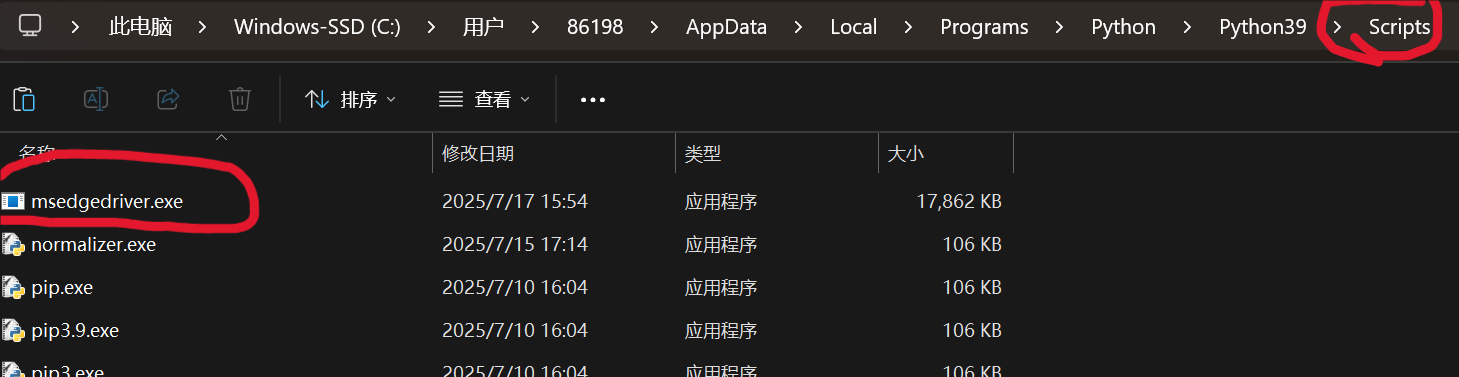
下载好后解压,复制文件夹内的.exe文件粘贴到 你的python的Scripts文件夹路径中即可
正式学习爬虫
加载网页
代码 1
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("http://www.baidu.com")
input("")
运行结果:启动 Edge 浏览器并打开百度首页,程序等待用户输入后退出。
代码解析:配置 Edge 浏览器路径,创建 WebDriver 实例,打开指定 URL,input ("") 用于保持浏览器打开状态。
代码 2
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn//periodical')
input("")运行结果:启动 Edge 浏览器并打开人民邮电出版社期刊页面,等待用户输入后退出。
代码解析:同代码1,仅 URL 不同,打开的是出版社期刊页面。
打开新标签页
代码
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files\Google\Edge\Application\edge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/')
driver.execute_script("window.open('https://www.ptpress.com.cn/login','_blank');")
driver.execute_script("window.open('https://www.shuyishe.com/','_blank');")
driver.execute_script("window.open('https://www.shuyishe.com/course','_blank');")
input("")
运行结果:启动 Edge 浏览器,先打开出版社首页,再依次在新标签页中打开登录页、书艺社首页和课程页,等待用户输入后退出。

代码解析:通过 execute_script 执行 JavaScript 代码,使用 window.open 方法在新标签页打开指定 URL。
获取渲染后的网页代码
代码
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files\Google\Edge\Application\edge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/')
print(driver.page_source)
input("")
运行结果:启动 Edge 浏览器打开出版社首页,打印浏览器渲染后的完整 HTML 源代码,等待用户输入后退出。
代码解析:通过 page_source 属性获取浏览器当前页面的源代码,适用于获取动态加载内容。
批量下载网页中的资源
代码
from selenium import webdriver
from selenium.webdriver.edge.options import Options
import re
import requestsedge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/search?keyword=C")
imgs = re.findall(r'<img src="(.+?jpg)">', driver.page_source)
a=1
for i in imgs:f = open('imgs/'+str(a)+'.jpg', 'wb')a+=1img = requests.get(i)f.write(img.content)f.close()运行结果:启动 Edge 浏览器打开 C 语言相关搜索结果页,从页面源代码中提取所有 jpg 图片 URL,下载并保存到本地 imgs(提前创建) 文件夹中。
代码解析:使用正则表达式从页面源代码中提取图片 URL,通过 requests 库下载图片并保存到本地文件。
(学习第一步在这里)
python网络爬虫(第一步:网络爬虫库、robots.txt规则(防止犯法)、查看获取网页源代码)-CSDN博客