【深度学习】神经网络过拟合与欠拟合-part5
八、过拟合与欠拟合
训练深层神经网络时,由于模型参数较多,数据不足的时候容易过拟合,正则化技术就是防止过拟合,提升模型的泛化能力和鲁棒性 (对新数据表现良好 对异常数据表现良好)
1、概念
1.1过拟合
在训练模型数据拟合能力很强,表现很好,在测试数据上表现很差
原因
数据不足;模型太复杂;正则化强度不足
1.2 欠拟合
模型学习能力不足,无法捕捉数据中的关系
1.3 如何判断
过拟合:训练时候误差低,验证时候误差高 说明过度拟合了训练数据中的噪声或特定模式
欠拟合:训练和测试的误差都高,说明模型太简单,无法捕捉到复杂模式
2.解决欠拟合
增加模型复杂度,增加特征,减少正则化强度,训练更长时间
3.解决过拟合
考虑损失函数,损失函数的目的是使预测值与真实值无限接近,如果在原来的损失函数上添加一个非0的变量
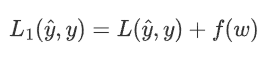
其中f(w)是关于权重w的函数,f(w)>0
要使L1变小,就要使L变小的同时,也要使f(w)变小。从而控制权重w在较小的范围内。
3.1 L2正则化
L2在损失函数中添加权重参数的平方和来实现,目标是惩罚过大的参数
3.1.1 数字表示
损失函数L(tθ),其中θ表示权重参数,加入L2正则化后
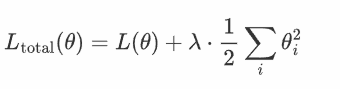
其中:
L(θ) 是原始损失函数(比如均方误差、交叉熵等)。
λ是正则化强度,控制正则化的力度。
θi 是模型的第 i 个权重参数。
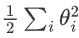 是所有权重参数的平方和,称为 L2 正则化项。
是所有权重参数的平方和,称为 L2 正则化项。
3.1.2 梯度更新
L2正则下,梯度更新时,不仅考虑原始损失函数梯度,还要考虑正则化的影响
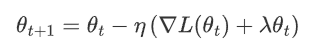
其中:
η 是学习率。
![]() 是损失函数关于参数 \theta_t 的梯度。
是损失函数关于参数 \theta_t 的梯度。
![]() 是 L2 正则化项的梯度,对应的是参数值本身的衰减。
是 L2 正则化项的梯度,对应的是参数值本身的衰减。
很明显,参数越大惩罚力度就越大,从而让参数逐渐趋向于较小值,避免出现过大的参数。
3.1.4 代码
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 设置种子
torch.manual_seed(42)# 随机数据
n_samples = 100
n_features = 20
x = torch.randn(n_samples, n_features)
y = torch.randn(n_samples,1)# 定义全链接神经网络
class SimpleNet(nn.Module):def __init__(self):super(SimpleNet,self).__init__()self.fc1 = nn.Linear(n_features,50)self.fc2 = nn.Linear(50,1)def forward(self,x):x = torch.relu(self.fc1(x))return self.fc2(x)
# 训练函数
def train_model(use_l2 = False,weight_decay = 0.01,n_epoches = 100):model = SimpleNet()criterion = nn.MSELoss()# 选择优化器if use_l2:optimizer = optim.SGD(model.parameters(),lr = 0.01,weight_decay = weight_decay)else:optimizer = optim.SGD(model.parameters(),lr = 0.01,)train_losses = []for epoch in range(n_epoches):optimizer.zero_grad()outputs = model(x)loss = criterion(outputs,y)loss.backward()optimizer.step()train_losses.append(loss.item())if(epoch+1) % 10 == 0:print(F":Epoches[{epoch+1}/{n_epoches},Loss:{loss.item():.4f}]")return train_losses# 训练比较两种模型
train_losses_no_l2 = train_model(use_l2 = False)
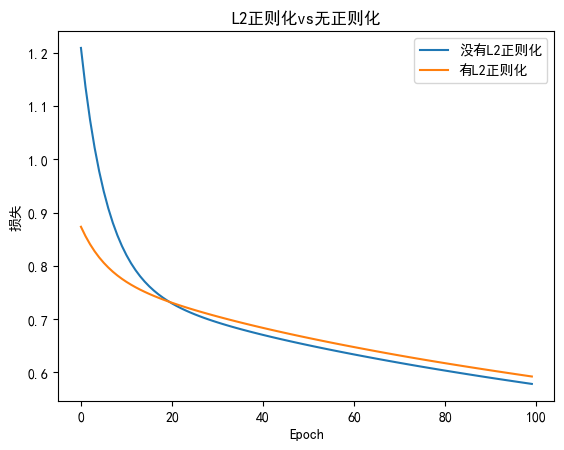
train_losses_with_l2 = train_model(use_l2 = True,weight_decay=0.01)# 绘制损失曲线
plt.plot(train_losses_no_l2,label = "没有L2正则化")
plt.plot(train_losses_with_l2,label = "有L2正则化")
plt.xlabel("Epoch")
plt.ylabel("损失")
plt.title('L2正则化vs无正则化')
plt.legend()
plt.show()
3.2 L1正则化
通过在损失函数中添加权重参数的绝对值来之和来约束模型复杂度
3.2.1 数学表示
设模型的原始损失函数为 L(θ),其中θ表示模型权重参数,则加入 L1 正则化后的损失函数表示为:
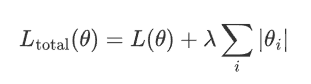
其中:
L(θ) 是原始损失函数。
λ是正则化强度,控制正则化的力度。
|θi| 是模型第i 个参数的绝对值。
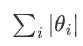 是所有权重参数的绝对值之和,这个项即为 L1 正则化项。
是所有权重参数的绝对值之和,这个项即为 L1 正则化项。
3.2.2 梯度更新
L1的正则化下 梯度更新公式
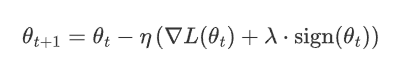
其中:
η是学习率。
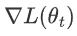 是损失函数关于参数 \theta_t 的梯度。
是损失函数关于参数 \theta_t 的梯度。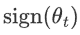 是参数 \theta_t 的符号函数,表示当 \theta_t 为正时取值为 1,为负时取值为 -1,等于 0 时为 0。
是参数 \theta_t 的符号函数,表示当 \theta_t 为正时取值为 1,为负时取值为 -1,等于 0 时为 0。
L1正则化依赖参数的绝对值,梯度更新不说简单的线性缩小,而是通过符号函数来调整参数的方向,这就是为什么L1正则化促使参数变为0
3.2.3 作用
稀疏性:L1 正则化的一个显著特性是它会促使许多权重参数变为 零。这是因为 L1 正则化倾向于将权重绝对值缩小到零,使得模型只保留对结果最重要的特征,而将其他不相关的特征权重设为零,从而实现 特征选择 的功能。
防止过拟合:通过限制权重的绝对值,L1 正则化减少了模型的复杂度,使其不容易过拟合训练数据。相比于 L2 正则化,L1 正则化更倾向于将某些权重完全移除,而不是减小它们的值。
简化模型:由于 L1 正则化会将一些权重变为零,因此模型最终会变得更加简单,仅依赖于少数重要特征。这对于高维度数据特别有用,尤其是在特征数量远多于样本数量的情况下。
特征选择:因为 L1 正则化会将部分权重置零,因此它天然具有特征选择的能力,有助于自动筛选出对模型预测最重要的特征。
3.2.4 与L2对比
L1 正则化 更适合用于产生稀疏模型,会让部分权重完全为零,适合做特征选择。
L2 正则化 更适合平滑模型的参数,避免过大参数,但不会使权重变为零,适合处理高维特征较为密集的场景。
3.3 Dropout
每次训练迭代中,一部分神经元被丢弃(p为丢弃概率)
被选中的神经元不参与传播
在测试阶段,所有的神经元都参与计算,但对权重进行缩放(1-p),以保持输出的期望值一致
Dropout是一种训练过程中随机丢弃部分神经元的计算,减少神经元之间的依赖防止模型过于复杂,避免过拟合
3.3.1 实现
import torch
import torch.nn as nndropout = nn.Dropout(p=0.5)
x = torch.randint(0, 10, (5, 6),dtype=torch.float)
print(x)print(dropout(x))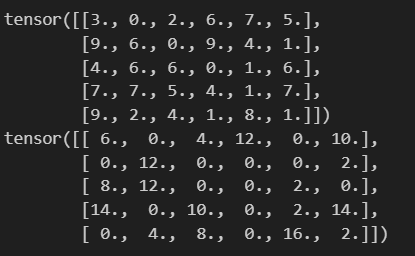
Dropout过程:
按照指定概率把部分神经元值设为0
为避免该操作带来的影响,需要对非0的元素使用缩放因子1/(1-p)进行强化
假设某个神经元的输出为 x,Dropout 的操作可以表示为:
在训练阶段:

在测试阶段:
y=x
为什么要使用缩放因子1/(1-p)?
在训练阶段,Dropout 会以概率 p随机将某些神经元的输出设置为 0,而以概率 1−p 保留这些神经元。
假设某个神经元的原始输出是 x,那么在训练阶段,它的期望输出值为:
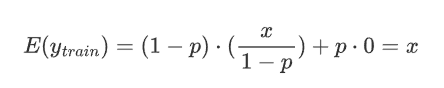
通过这种缩放,训练阶段的期望输出值仍然是 x,与没有 Dropout 时一致。
3.3.2 权重影响
import torch
import torch.nn as nn
from PIL import Image
from torchvision import transforms
import os
from matplotlib import pyplot as plt
torch.manual_seed(42)def load_img(path,resize = (224,224)):pil_img = Image.open(path).convert('RGB')print("Original Image Size: ", pil_img.size)transform = transforms.Compose([transforms.Resize(resize),transforms.ToTensor()])return transform(pil_img)# dirpath = os.path.dirname(__file__)
# path = os.path.join(dirpath,"img","100.jpg")
path = "./100.jpg"trans_img = load_img(path)
trans_img = trans_img.unsqueeze(0)
dropout = nn.Dropout2d(p=0.2)
drop_img = dropout(trans_img)
trans_img = trans_img.squeeze(0).permute(1,2,0).numpy()
drop_img = drop_img.squeeze(0).permute(1,2,0).numpy()drop_img = drop_img.clip(0,1)
fig = plt.figure(figsize = (10,5))ax1 = fig.add_subplot(1,2,1)
ax1.imshow(trans_img)ax2 = fig.add_subplot(1,2,2)
ax2.imshow(drop_img)plt.show()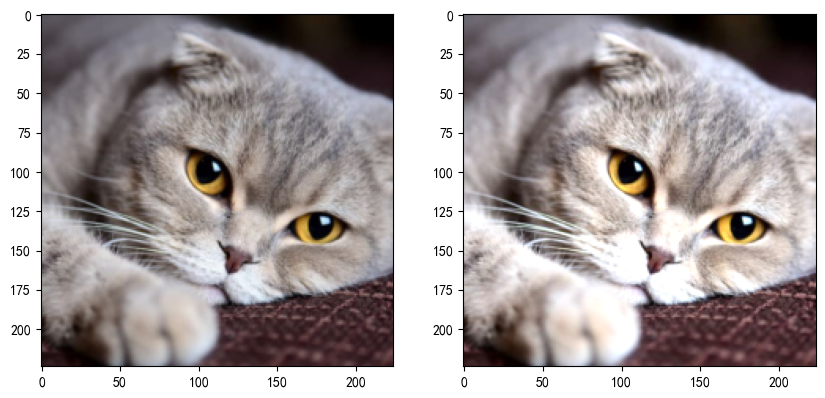
nn.Dropout2d(p):Dropout2d 是针对二维数据设计的 Dropout 层,它在训练过程中随机将输入张量的某些通道(二维平面)置为零。
| 参数 | 要求格式 | 示例形状 | 说明 |
|---|---|---|---|
| 输入 | (N, C, H, W) | (16, 64, 32, 32) | 批大小×通道×高×宽 |
| 输出 | (N, C, H, W) | (16, 64, 32, 32) | 与输入同形,部分通道归零 |
3.5 数据增强
样本不足时过拟合的常见原因之一
当训练数据过少时,模型容易“记住”有限的样本(包括噪声和无关细节),而非学习通用的规律。
简单模型更可能捕捉真实规律,但数据不足时,复杂模型会倾向于拟合训练集中的偶然性模式(噪声)。
样本不足时,训练集的分布可能与真实分布偏差较大,导致模型学到错误的规律。
小数据集中,个别样本的噪声(如标注错误、异常值)会被放大,模型可能将噪声误认为规律。
数据增强的好处:
大幅度降低数据采集和标注成本;
降低过拟合风险,提高模型泛化能力
transforms:
常用变换类
transforms.Compose:将多个变换操作组合成一个流水线。
transforms.ToTensor:将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,将图像数据从 uint8 类型 (0-255) 转换为 float32 类型 (0.0-1.0)。
transforms.Normalize:对张量进行标准化。
transforms.Resize:调整图像大小。
transforms.CenterCrop:从图像中心裁剪指定大小的区域。
transforms.RandomCrop:随机裁剪图像。
transforms.RandomHorizontalFlip:随机水平翻转图像。
transforms.RandomVerticalFlip:随机垂直翻转图像。
transforms.RandomRotation:随机旋转图像。
transforms.ColorJitter:随机调整图像的亮度、对比度、饱和度和色调。
transforms.RandomGrayscale:随机将图像转换为灰度图像。
transforms.RandomResizedCrop:随机裁剪图像并调整大小。
3.5.1 图片缩放
from PIL import Image
img1 = plt.imread('./img/100.jpg')
print(img1.shape)
plt.imshow(img1)
plt.show()img = Image.open('./img/100.jpg')
transorm = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor()])
r_img = transorm(img)
print(r_img.shape)r_img = r_img.permute(1,2,0)plt.imshow(r_img)
plt.show() 

3.5.2 随机裁剪
# 裁剪
img = Image.open('./img/100.jpg')
transform = transforms.Compose([transforms.RandomCrop(size=(224, 224)),transforms.ToTensor()])
r_img = transform(img)
print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)
plt.show() 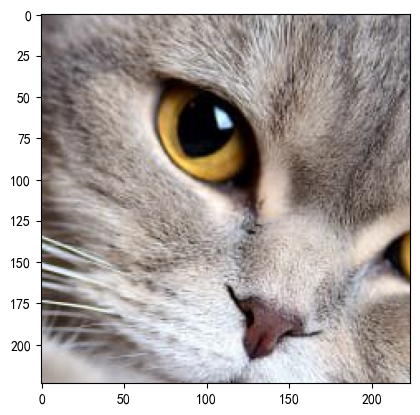
3.5.3 随机水平翻转
img = Image.open("./img/100.jpg")
transform = transforms.Compose([transforms.RandomHorizontalFlip(p=1),transforms.ToTensor()])
r_img = transform(img)
print(r_img.shape)r_img = r_img.permute(1, 2, 0)plt.imshow(r_img)
plt.show() 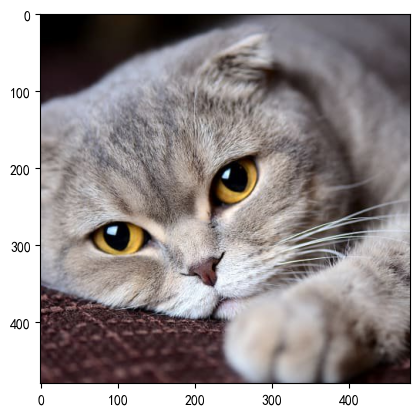
3.5.4 调整图片颜色
transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
brightness表示亮度:
float或者(min,max)
如果是
float(如brightness=0.2),则亮度在[max(0, 1 - 0.2), 1 + 0.2] = [0.8, 1.2]范围内随机缩放。如果是
(min, max)(如brightness=(0.5, 1.5)),则亮度在[0.5, 1.5]范围内随机缩放。
contrast:
对比度调整的范围。
格式与 brightness 相同。
saturation:
饱和度调整的范围。
格式与 brightness 相同。
hue:
色调调整的范围。
可以是一个浮点数(表示相对范围)或一个元组 (min, max)。
取值范围必须为
[-0.5, 0.5](因为色相在 HSV 色彩空间中是循环的,超出范围会导致颜色异常)。例如,hue=0.1 表示色调在 [-0.1, 0.1] 之间随机调整。
img = Image.open("./img/100.jpg")transform = transforms.Compose([transforms.ColorJitter(brightness=0.2,contrast= 0.2,saturation= 0.2,hue= 0.2),transforms.ToTensor()])
r_img = transform(img)
print(r_img.shape)
r_img = r_img.permute(1,2,0)plt.imshow(r_img)
plt.show()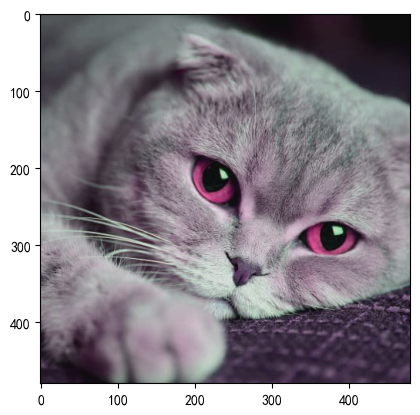
3.5.5 随机旋转
RandomRotation用于对图像进行随机旋转。
transforms.RandomRotation(degrees, interpolation=InterpolationMode.NEAREST, expand=False, center=None, fill=0 )
degrees:
旋转角度的范围,可以是一个浮点数或元组 (min_degree, max_degree)。
例如,degrees=30 表示旋转角度在 [-30, 30] 之间随机选择。
例如,degrees=(30, 60) 表示旋转角度在 [30, 60] 之间随机选择。
interpolation:
插值方法,用于旋转图像。
默认是 InterpolationMode.NEAREST(最近邻插值)。
其他选项包括 InterpolationMode.BILINEAR(双线性插值)、InterpolationMode.BICUBIC(双三次插值)等。
expand:
是否扩展图像大小以适应旋转后的图像。如:当需要保留完整旋转后的图像时(如医学影像、文档扫描)
如果为 True,旋转后的图像可能会比原始图像大。
如果为 False,旋转后的图像大小与原始图像相同。
center:
旋转中心点的坐标,默认为图像中心。
可以是一个元组 (x, y),表示旋转中心的坐标。
fill:
旋转后图像边缘的填充值。
可以是一个浮点数(用于灰度图像)或一个元组(用于 RGB 图像)。默认填充0(黑色)
image = Image.open("./img/100.jpg")
transform = transforms.RandomRotation(degrees=90)rotated_image = transform(image)plt.imshow(rotated_image)
plt.axis('off')
plt.show() 
3.5.6 图片转Tensor
import torch
from PIL import Image
from torchvision import transforms
import osimg = Image.open('./img/100.jpg')
transform = transforms.ToTensor()
img_tensor = transform(img)
print(img_tensor) 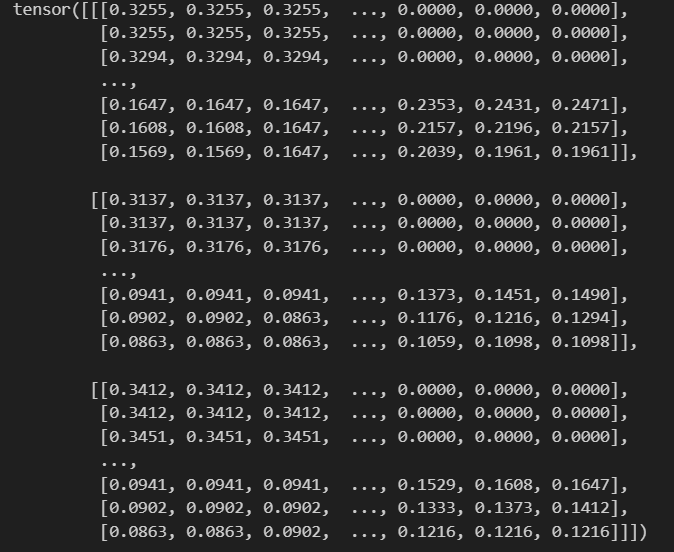
3.5.7 Tensor转图片
# img_tensor = torch.rand(3, 224, 224)
img = Image.open('./img/100.jpg')
transform1 = transforms.ToTensor()
img_tensor = transform1(img)transform2 = transforms.ToPILImage()
img = transform2(img_tensor)plt.imshow(img)
plt.show() 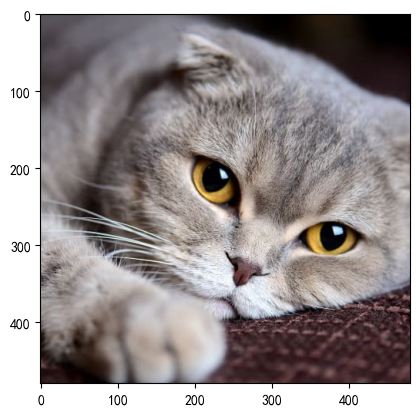
3.5.8 归一化
标准化:将图像的像素值从原始范围([0,255]或[0,1],转化为均值为0,标准差为1的分布。
加速训练:标准化后的数据分布更均匀,有利于训练
提高模型性能
img = Image.open('./img/100.jpg')
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
r_img= transform(img)
print(r_img.shape)r_img = r_img.permute(1,2,0)plt.imshow(r_img)
plt.show()