Linux内存系统简介
Linux 内存系统是 Linux 操作系统核心功能之一,负责对物理内存(RAM)和虚拟内存进行高效管理,为进程提供独立、连续的内存抽象,并确保系统资源的合理分配与回收。
一、总体架构
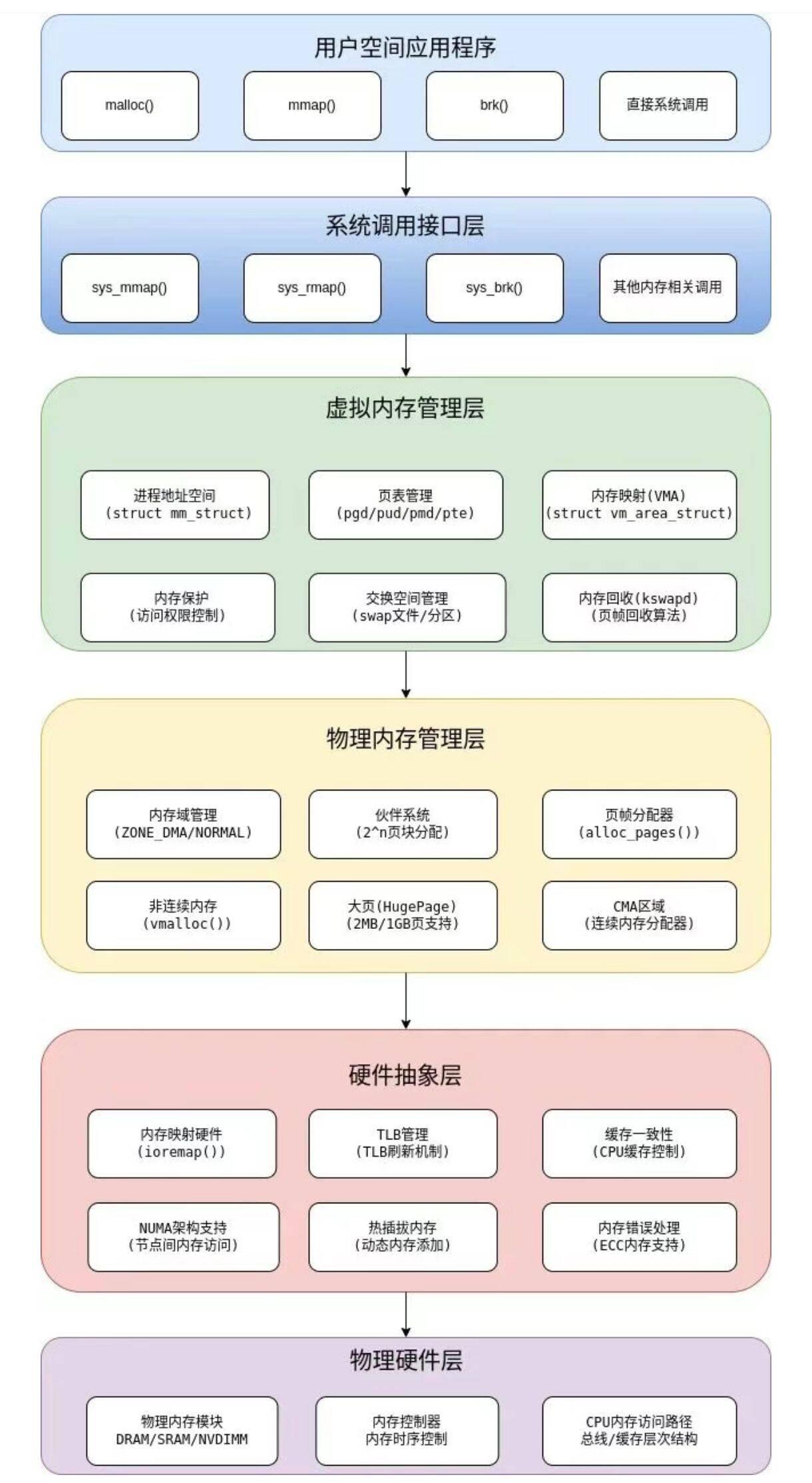
二、核心组件介绍
用户空间接口层
内存分配函数
- malloc/free
- 功能:动态分配 / 释放用户空间内存(堆内存)。
- 底层实现:
- 小内存(通常 < 128KB):通过
brk调整堆的边界(program break),分配连续空间,减少系统调用开销; - 大内存(通常 ≥ 128KB):通过
mmap映射匿名内存(MAP_ANONYMOUS | MAP_PRIVATE),避免堆碎片累积; - 内存池:
malloc内部维护内存池(如ptmalloc的arena结构),减少频繁分配 / 释放的开销,支持线程安全(通过互斥锁)。
- 小内存(通常 < 128KB):通过
- 注意:
free不会立即归还内存给内核,而是标记为空闲,供后续malloc复用(减少系统调用);若内存长期未使用,大内存块会通过munmap释放,小内存块通过brk收缩堆。
- new/delete
- 功能:C++ 面向对象的内存分配 / 释放,本质是
malloc/free的封装,但增加了对象构造 / 析构逻辑。 - 差异:
new分配失败时抛出bad_alloc异常(或返回nullptr,取决于编译器),而malloc返回nullptr;delete[]需用于数组释放,确保每个元素的析构函数被调用。
- 功能:C++ 面向对象的内存分配 / 释放,本质是
内存映射
- mmap
- 核心参数:
addr:建议映射的起始地址(内核可调整);length:映射长度(按页对齐);prot:内存保护标志(PROT_READ/PROT_WRITE/PROT_EXEC);flags:映射类型(MAP_SHARED:修改同步到文件;MAP_PRIVATE:私有副本,不影响文件;MAP_ANONYMOUS:匿名映射,无对应文件)。
- 应用场景:
- 共享库加载(如
libc.so通过MAP_SHARED映射,多进程共享同一份物理内存); - 大文件高效读写(无需一次性加载到内存,通过页缺失按需加载);
- 进程间共享内存(
MAP_SHARED+ 共享文件,或MAP_ANONYMOUS | MAP_SHARED)。
- 共享库加载(如
- 核心参数:
- munmap:解除mmap创建的映射,释放虚拟地址空间,若为MAP_SHARED且有未同步修改,会刷新到文件。
堆管理
- brk/sbrk:调整进程堆边界
- 功能:直接调整进程 “堆的边界”(
program break,堆的最高地址)。brk(addr):将堆边界设置为addr(需大于当前堆起始地址);sbrk(incr):将堆边界增加incr字节(incr为负则减少),返回调整前的边界地址。
- 局限:仅能分配连续内存,频繁分配 / 释放易导致 “堆内部碎片”(已分配区域中未使用的空间);不适合大内存分配(易导致堆过度扩张)。
- 功能:直接调整进程 “堆的边界”(
特殊内存
- posix_memalign/memalign
- 配按指定字节对齐的内存(如用于硬件要求的对齐地址,如 SIMD 指令、DMA 缓冲区)。
- 区别:
posix_memalign是 POSIX 标准,返回错误码;memalign是非标准接口,失败返回NULL。
系统调用层
核心系统调用
- sys_brk:内核实现brk的核心逻辑,负责调整进程堆边界。
- 内核处理:检查
addr是否在进程虚拟地址空间范围内,更新mm_struct中的brk字段,同时建立虚拟地址到物理内存的映射(延迟分配,首次访问时触发缺页中断)。
- 内核处理:检查
- sys_mmap/sys_munmap:内核实现内存映射的核心逻辑。
sys_mmap:在进程虚拟地址空间中分配一段连续区域,根据flags类型(文件映射 / 匿名映射)设置映射属性,并关联vm_area_struct(虚拟内存区域);sys_munmap:解除指定虚拟地址范围的映射,释放vm_area_struct,若为文件映射且有脏页,会同步到磁盘。
内存保护
- sys_mprotect:修改内存区域访问权限
- 功能:修改虚拟内存区域的访问权限(读 / 写 / 执行),实现内存保护(如防止栈溢出、代码段不可写)。
- 原理:通过更新对应虚拟地址范围的页表项标志位(如
PTE_R/PTE_W/PTE_X),若进程访问权限不匹配,CPU 会触发 “缺页异常”(#PF),内核终止进程(如SIGSEGV信号)。 - 应用:动态修改内存权限(如 JIT 编译器先分配可写内存,写入代码后改为只读可执行,防止篡改)。
内存统计
- sys_mincore:查询内存页是否在物理内存中
- 功能:查询指定虚拟地址范围内的页是否 “驻留物理内存”(in core),返回一个字节数组(每 bit 表示一个页的状态:1 = 驻留,0 = 不在内存)。
- 用途:帮助用户空间程序优化内存使用(如预加载即将访问的页,减少缺页中断)。
交换空间
+ sys_swapon:启用 Swap 设备(分区或文件),内核将其加入 Swap 链表,用于内存页换出; + sys_swapoff:关闭 Swap 设备,需先将该设备上的所有页换入物理内存(若内存不足则失败)。虚拟内存管理
进程地址空间
- struct mm_struct:进程的虚拟内存实例
- 每个进程有且仅有一个
mm_struct(进程描述符task_struct的mm字段),是虚拟内存的 “总控结构”。 - 核心字段:
pgd:页全局目录(页表的根节点);mmap:虚拟内存区域链表(vm_area_struct链表);brk:堆的当前边界地址;total_vm:进程使用的虚拟页总数;rss:驻留物理内存的页总数( Resident Set Size)。
- 每个进程有且仅有一个
虚拟内存区域
- struct vm_area_stuct:虚拟地址空间被划分为多个不重叠的 VMA,每个 VMA 代表一段具有相同属性(权限、映射类型)的连续虚拟地址。
- 核心字段:
vm_start/vm_end:VMA 的起始 / 结束虚拟地址;vm_flags:权限标志(VM_READ/VM_WRITE/VM_EXEC)、映射类型(VM_ANON= 匿名映射,VM_FILE= 文件映射);vm_ops:VMA 操作函数集(如fault:缺页处理,map_pages:批量映射页);vm_file:若为文件映射,指向对应文件的struct file。
- 管理方式:内核通过 “红黑树”(
mm_struct的mm_rb)快速查找 VMA(比链表查询效率高)。
- 核心字段:
页表管理
- 四级页表
- 地址转换过程:64 位虚拟地址被拆分为 6 个字段(PGD 索引 + PUD 索引 + PMD 索引 + PTE 索引 + 页内偏移),逐级查找页表,最终得到物理地址。
- pgd:页全局目录(一级页表),每个表项指向一个 PUD;
- pud:页上级目录(二级页表),每个表项指向一个 PMD;
- pmd:页中间目录(三级页表),每个表项指向一个 PTE;
- pte:页表项(四级页表),每个表项指向物理页框(或标记为 “未映射”“换出” 等状态)。
- 大页:直接使用pmd或者pgd映射2MB/1GB内存
- 常规页大小为 4KB,大页支持 2MB(通过 PMD 直接映射)或 1GB(通过 PGD 直接映射),减少页表层级(如 2MB 大页只需 PGD→PUD→PMD 三级查找)。
- 优势:降低 TLB miss(TLB 可缓存更多大页映射),适合内存密集型应用(如数据库、虚拟机);
- 管理:通过
/proc/sys/vm/nr_hugepages配置大页数量,用户空间通过mmap(MAP_HUGETLB标志)使用。
- 内存保护:页表项标志位:PTE_R、PTE_W、PTE_X
PTE_P:页存在(映射到物理页框);PTE_R:可读;PTE_W:可写;PTE_X:可执行;PTE_U:用户态可访问(否则仅内核态可访问)。
物理内存管理PMM
> 物理内存管理负责实际物理内存(RAM)的分配、回收和碎片处理,核心目标是高效利用物理页框。 >内存域Zone
- ZONE_DMA:低地址内存(x86 通常≤16MB),供传统 ISA 设备 DMA 访问(DMA 不经过 CPU,直接读写内存,地址需在设备可访问范围内);
- ZONE_NORMAL:常规内存(x86 通常 16MB~896MB),内核可直接映射(虚拟地址 = 物理地址 + 固定偏移);
- ZONE_HIGHMEM:高端内存(x86>896MB,仅 32 位系统存在),内核无法直接映射,需通过临时映射(如
kmap)访问(64 位系统因地址空间充足,无此 Zone)
伙伴系统
+ 按2的n次方进行管理空闲内存 + 解决外部碎片问题,合并相邻空闲块 + 分配过程:- 若请求`n`个页框,找到最小的`2^k ≥ n`的链表;- 若链表非空,直接分配`2^k`个页框,多余部分拆分后加入小一级链表;- 若链表为空,向大一级链表申请并拆分。 + 合并过程:当页框释放时,检查相邻页框(“伙伴”)是否空闲,若空闲则合并为大一级页框,减少外部碎片。页帧分配器
+ alloc_pages:分配连续物理页,分配`2^order`个连续页框(`order=0`→1 页,`order=3`→8 页); + __get_free_page:封装`alloc_pages`,返回单个页框的虚拟地址; + kmalloc:分配连续虚拟地址的小内存(基于 Slab 分配器,底层调用伙伴系统)。特殊内存分配
CMA
预留内存,支持动态复用和页迁移- 作用:预留一块物理内存区域,供驱动程序(如 GPU、摄像头)分配连续大页(DMA 需求),平时可被普通进程使用(通过 “可迁移页” 标记),驱动申请时内核会迁移该区域的普通页,释放连续空间。
- 配置:通过内核参数
cma=size@start预留(如cma=256M@0x10000000)。
巨页
减少TLB压力- 巨页通常指 “比标准页大的页”,Huge Pages 是内核预分配的静态巨页,而 “动态巨页”(Transparent Huge Pages,THP)由内核自动管理,无需用户配置,适合随机内存访问(如数据库)。
vmalloc
分配连续虚拟连续、物理离散的内存- 功能:分配 “虚拟地址连续、物理地址离散” 的内存(区别于
kmalloc的物理连续)。 - 用途:内核需要大内存但无需物理连续(如模块加载、网络缓冲区);
- 缺点:因物理离散,访问需多次页表查找,性能略低于
kmalloc。
slab
分配内核对象(对象池)- 问题:伙伴系统分配的是页框级内存(4KB 起),而内核对象(如
task_struct、inode)通常小于 4KB,直接分配会导致 “内部碎片”。 - 原理:基于伙伴系统,为每种内核对象创建 “slab 缓存”(
kmem_cache),缓存预先分配的对象(分为满 / 部分满 / 空 slab),分配时直接从缓存取对象,释放时放回缓存(不立即归还给伙伴系统)。 - 优势:减少碎片,提高分配效率(对象复用);
- 工具:
slabtop可查看 slab 缓存使用情况(如dentry缓存、inode缓存)。
内存回收和交换
kswapd
定期检查内存使用情况,触发页回收LRU
最近最少使用- 原理:将物理页分为 “活跃” 和 “不活跃” 链表(
active_list/inactive_list),优先回收不活跃页。 - 页迁移规则:
- 首次访问的页加入
inactive_list; - 再次访问时,从
inactive_list移到active_list(标记为 “活跃”); - 若
active_list过长,会将最久未访问的页移回inactive_list。
- 首次访问的页加入
交换空间
不活跃的页换出到磁盘内存压缩
压缩不活跃的页硬件抽象
MMU
实现映射- 功能:CPU 内置的硬件模块,负责虚拟地址到物理地址的转换(基于页表),若转换失败(如页不在内存),触发 “缺页异常”(
#PF),由内核处理(换入页或终止进程)。
TLB
缓存最近使用的页表项- 作用:缓存最近使用的页表项(虚拟地址→物理地址映射),避免每次访问内存都查页表(页表在内存中,访问慢)。
- 刷新机制:当页表项更新(如`mprotect`修改权限),需刷新 TLB(否则 CPU 会使用旧映射),内核通过`tlb_flush`指令完成(分全局刷新和局部刷新,减少性能损耗)。
缓存一致性
- 问题:多 CPU 或 DMA 设备访问内存时,CPU 缓存与内存数据可能不一致(如 CPU1 修改缓存,CPU2 未更新)。
- 解决:通过硬件缓存一致性协议(如 x86 的 MESI 协议),确保所有 CPU 看到的内存数据一致;DMA 操作时,内核通过
dma_sync_single_for_cpu等函数同步缓存与内存。
三、内存监控和调优工具
| 工具 | 功能 | 常用命令示例 |
|---|---|---|
free | 查看总内存、已用、空闲、缓存和 Swap | free -h(人性化显示) |
top/ htop | 实时查看进程内存占用(% MEM、RES/RSS) | 按M键按内存占用排序 |
vmstat | 监控内存、Swap、IO 等系统指标 | vmstat 1(每秒输出一次) |
sar | 历史内存使用统计(需预先配置) | sar -r 1 5(1 秒一次,共 5 次) |
pmap | 查看进程虚拟地址空间布局 | pmap -x <PID>(详细显示进程内存映射) |
slabtop | 查看内核 Slab 分配器使用情况 | 实时显示 slab 缓存占用 |
四、总结
Linux 内存系统通过分层设计(用户接口→系统调用→虚拟内存→物理内存→硬件),实现了高效、安全、灵活的内存管理:- 虚拟内存屏蔽物理细节,提供独立地址空间;
- 伙伴系统 + Slab 解决碎片问题,优化分配效率;
- LRU 回收 + Swap 平衡内存利用率与性能;
- 硬件抽象(MMU/TLB)确保地址转换高效。