语音增强论文汇总
DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement
CRM=(Sr+jSi)/(Yr+jYi) ,本质就是原始信号/噪声信号

3种不同恢复修复波形的方法:
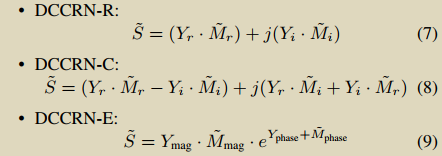
可以看出noise为加性的:
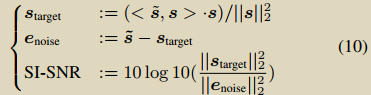
A Parallel-Data-Free Speech Enhancement Method Using Multi-Objective Learning Cycle-Consistent Generative Adversarial Network
北科
针对加性噪声:

恢复音频的幅度谱:
![]()
Conditional_Diffusion_Probabilistic_Model_for_Speech_Enhancement
摘要:本文利用最近的扩散模型,提出语音增强方案。
没明确写loss形式,感觉是加性的,毕竟扩散模型是加性的;
Deep learning for minimum mean-square error approaches to speech enhancement(2019)
摘要:目前,语音增强的研究从传统MSE方法转化到了基于NN的mask方法或映射方法。本文提出基于NN的先验SNR估计方法。
加性噪声:

DeepMMSE: A Deep Learning Approach to MMSE-Based Noise Power Spectral Density Estimation (2020)
加性噪声:

说loss是交叉熵,但是没给具体公式。
HuBERT Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
研究语音表征学习的,不是降噪的。。。
Improved Normalizing Flow-Based Speech Enhancement using an All-pole Gammatone Filterbank for Conditional Input Representation
加性噪声:

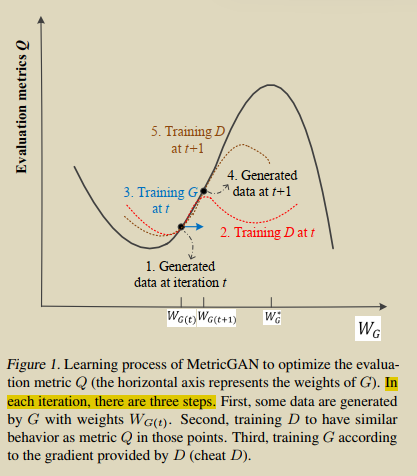
MetricGAN Generative Adversarial Networks based Black-box Metric Scores Optimization for Speech Enhancement
相较于传统判别器,metricgan的优势:
1.给定Gx,我们只期望传统判别器输出0,而metricgan可以输出一个打分,用于估计逼真程度;
2.传统判别器的输入仅有噪声音频,而metricgan的输入和传统metric一致;
先生成Gx,然后训练判别器,然后训练生成器;
Multi-task self-supervised learning for Robust Speech Recognition
语音识别的,没关系;
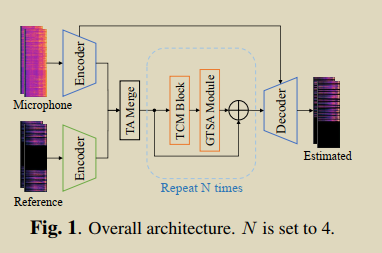
Real-time speech enhancement with dynamic attention span
接收音频中有:回声,加性噪声,路径增益;

Speech_Enhancement_Using_Harmonic_Emphasis_and_Adaptive_Comb_Filtering
2010年的,太老了;