第2章通用的高并发架构设计——2.3 高并发读场景方案2:本地缓存
笔者强烈推荐阅读的这本图书:《亿级流量系统架构设计与实战》
在计算机世界中,缓存(Cache)无处不在,如CPU缓存、DNS缓存、浏览器缓存等。值得一提的是,Cache在我国台湾地区被译为“快取”,更直接地体现了它的用途:快速读取。缓存的本质是通过空间换时间的思路来保证数据的快速读取。
业务服务一般需要通过网络调用向其他服务或数据库发送读数据请求。**为了提高数据的读取效率,业务服务进程可以将已经获取到的数据缓存到本地内存中,之后业务服务进程收到相同的数据请求时就可以直接从本地内存中获取数据返回,将网络请求转化为高效的内存存取逻辑。**这就是本地缓存的主要用途。在本书后面的核心服务设计篇中会大量应用本地缓存,本节先重点介绍本地缓存的技术原理。
2.3.1 基本的缓存淘汰策略
虽然缓存使用空间换时间可以提高数据的读取效率,但是内存资源的珍贵决定了本地缓存不可无限扩张,需要在占用空间和节约时间之间进行权衡。这就要求本地缓存能自动淘汰一些缓存的数据,淘汰策略应该尽量保证淘汰不再被使用的数据,保证有较高的缓存命中率。基本的缓存淘汰策略如下。
- FIFO(First In First Out)策略:优先淘汰最早进入缓存的数据。这是最简单的淘汰策略,可以基于队列实现。但是此策略的缓存命中率较低,越是被频繁访问的数据是越早进入队列的,于是会被越早地淘汰。此策略在实践中很少使用。
- LFU(Least Frequently Used)策略:优先淘汰最不常用的数据。LFU策略会为每条缓存数据维护一个访问计数,数据每被访问一次,其访问计数就加1,访问计数最小的数据是被淘汰的目标。此策略很适合缓存在短时间内会被频繁访问的热点数据,但是最近最新缓存的数据总会被淘汰,而早期访问频率高但最近一直未被访问的数据会长期占用缓存。
- LRU(Least Recent Used)策略:优先淘汰缓存中最近最少使用的数据。此策略一般基于双向链表和哈希表配合实现。双向链表负责存储缓存数据,并总是将最近被访问的数据放置在尾部,使缓存数据在双向链表中按照最近访问时间由远及近排序,每次被淘汰的都是位于双向链表头部的数据。哈希表负责定位数据在双向链表中的位置,以便实现快速数据访问。此策略可以有效提高短期内热点数据的缓存命中率,但如果是偶发性地访问冷数据,或者批量访问数据,则会导致热点数据被淘汰,进而降低缓存命中率。
**LRU策略和LFU策略的缺点是都会导致缓存命中率大幅下降。**近年来,业界出现了一些更复杂、效果更好的缓存淘汰策略,比如W-TinyLFU策略。
2.3.2 W-TinyLFU策略
W-TinyLFU策略结合了LFU策略和LRU策略的优点,兼具高缓存命中率与低内存占用,Redis和高性能的Java本地缓存Caffeine Cache组件都使用W-TinyLFU策略管理缓存。
虽然W-TinyLFU的名字带有LFU,但它实际上是LFU策略和LRU策略的结合体。从缓存内存空间的布局来看,W-TinyLFU将缓存的内存空间划分为两部分,如图2-3所示。
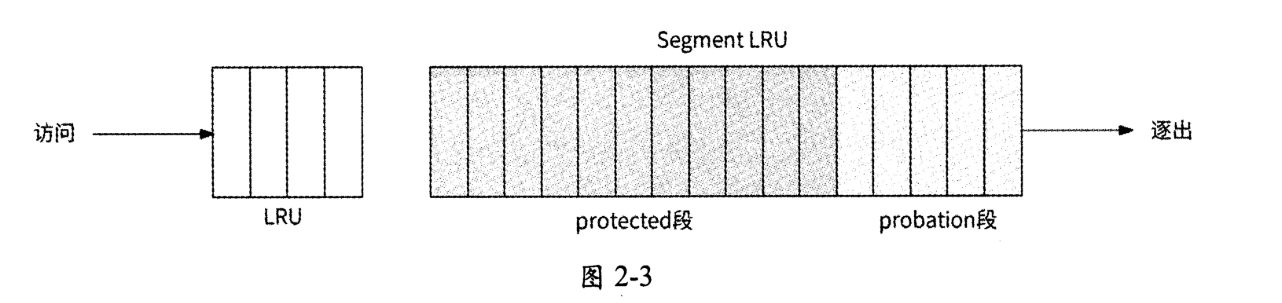
- Window LRU段(对应图中的LRU):此内存段使用LRU策略缓存数据,其占用的内存空间是总缓存内存空间的1%
- Segment LRU段(简称SLRU):此内存段使用SLRU策略缓存数据,具体是将缓存段进一步划分为protected段(保护段)和probation段(试用段),其中probation段负责存储最近被访问1次的缓存数据,protected段负责存储最近被访问至少2次的缓存数据。Segment LRU段内存空间的80%被分配给protected段,剩余20%的内存空间被分配给 probation 段。
W-TinyLFU策略的工作流程如下。
- 将首次被访问的数据X缓存到Window LRU段。
- 当Window LRU段的内存空间已满时,使用LRU策略将被淘汰的数据移入Segment LRU段中的probation段,之后数据X被访问时,再将其移入protected段。
- 当protected段的内存空间已满时,使用LRU策略将被淘汰的数据X移入probation段。
- 当数据X要被移入probation段,但是其内存空间已满时,使用LRU策略将被淘汰的数据V取出,与数据X进行访问频率的对比,将访问频率高的数据留在proation段,将访问频率低的数据淘汰。
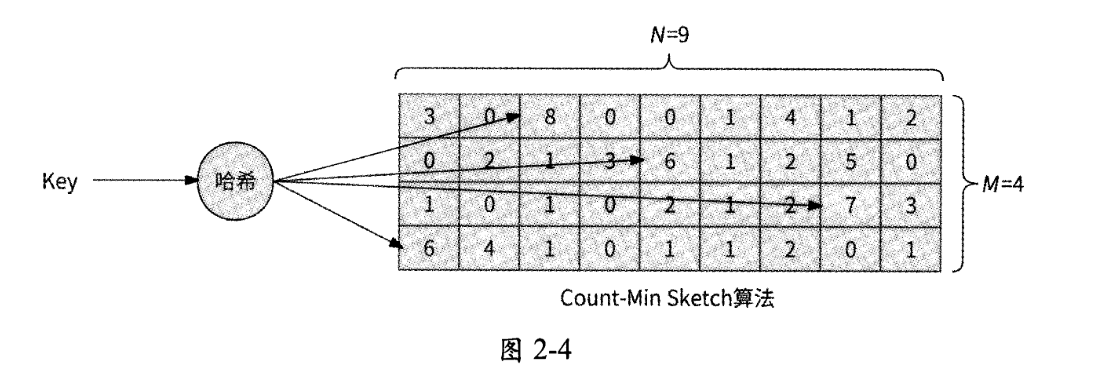
W-TinyLFU策略使用Count-Min Sketch近似算法来保存每条缓存数据的访问频率,如图2-4所示。
Count-Min Sketch算法的运行流程如下。
- 选定M个哈希函数,分配一个M行N列的二维数组作为哈希表。
- 当某数据的访问频率增加时,对数据Key分别使用M个哈希函数计算出哈希值,再对N取模,然后将二维数组每一行对应的列位置的数值加1,即二维数组中M个位置的数值均被更新。
- 当查询某数据的访问频率时,进行同样的哈希计算,将二维数组中M个位置的数值读出,选择其中的最小值作为此数据的访问频率。
值得注意的是,二维数组的每个位置仅需4bit,这是因为W-TinyLFU策略并不存储具体的访问计数,而是更希望反映出不同数据的访问频率的区分度。此策略认为每条数据的访问频率达到15次就已经很高了,于是以4bit表示每条缓存数据的访问频率。不过,如果大量数据均达到15次的访问频率,那么就会使得访问频率的区分度大大降低。
W-TinyLFU策略采用基于滑动窗口的时间衰减设计机制来解决这个问题:
- 此策略单独维护一个全局计数,每当二维数组更新1次时,此全局计数就加1;
- 当全局计数达到某个阈值时,将二维数组中的全部访问频率除以2,同时将全局计数除以2。
2.3.3 缓存击穿与SingleFlight
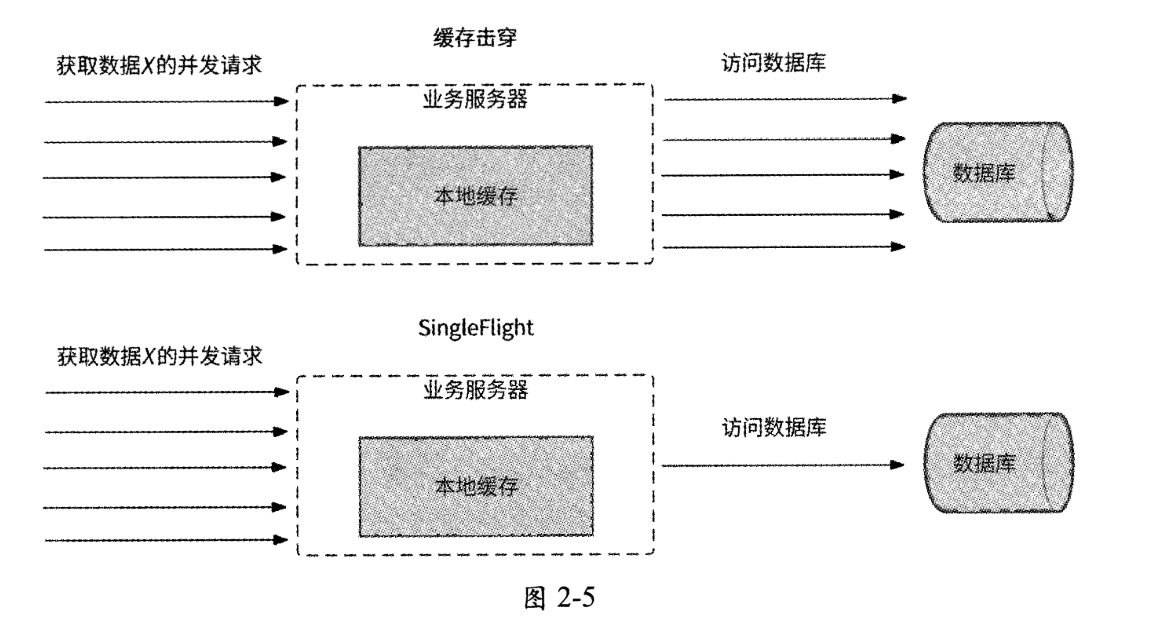
业务服务进程收到数据访问请求后,如果在本地缓存中没有查找到对应的数据(未命中缓存),则业务服务进程需要继续发起网络调用向数据库发送数据访问请求,获取到数据后再将其保存到本地缓存中。假设业务服务进程同时收到100个希望访问同一条热门数据的访问请求,且此数据未命中缓存,则业务服务进程会向下游发起100个数据访问请求。明明是访问同一条数据的请求,业务服务进程却执行了大量重复的网络调用,不仅浪费了网络带宽资源,而且可能将数据库击垮。此现象被称为“缓存击穿”。
通俗地讲,缓存击穿指的是缓存中一条热门数据在缓存失效的瞬间,对它的并发请求会“击穿”缓存,直接访问数据库,导致数据库被高并发请求击垮,就像如果防洪堤坝破了一个口,大量洪水就会涌入城市一样。
Golang语言扩展包提供的同步原语SingleFlight能很好地解决缓存击穿问题。如图2-5所示,SingleFlight可以将对同一条数据的并发请求进行合并,只允许一个请求访问数据库中的数据,这个请求获取到的数据结果与其他请求共享。
下面通过程序模拟10个获取my_key数据的并发请求的场景,来简单介绍SingleFlight的使用方式:
import ("golang.org/x/sync/singlefight""log""sync"
)// SingleFlight原语
var g singleflight.Group// getDataFromDB:模拟从数据库中获取key=”my_key”的数据
func getDataFromDB(key string) (string, error) {// 使用singleflight.Do()方法获取数据,仅执行一次data, err, _ = g.Do(key, func() (interface{}, error) {// 模拟众数据库中获取数据log.Printf("get data for key: %s from database", key)return "my_data", nil})if err != nil {return "", err}return data.(string), nil
}func main() {var wg sync.WaitGroupwg.Add(10)// 模拟10个并发请求for i := 0; i < 10; i ++ {go func() {defer wg.Done()// 这10个并发请求都希望获取key="my_key"的数据data, err := getDataFromDB("my_key")if err != nil {log.Print(err)return }// 获取数据成功log.Printf("I get data: %s for key: my_key", data)}()}wg.Wait()
}
singleflight.Do(key string, fn func() (interface{}, error))方法保证:对于同一条数据(用Key作为唯一标识)的fn函数调用,在并发请求时只执行一次,fn函数返回的结果被并发请求共享。程序中10个并发请求都需要从数据库中获取数据,而实际上最终输出的结果如下:

我们可以很容易地看到,10个并发请求仅执行了一次从数据库中获取数据的操作,最终获取到的数据被10个并发请求所共享,缓存击穿问题被完美解决。
总结
缓存的本质?
- 缓存的本质是通过空间换时间的思路来保证数据的快速读取。
本地缓存的用途?
- 业务服务一般需要通过网络调用向其他服务或数据库发送读数据请求。
- 为了提高数据的读取效率,业务服务进程可以将已经获取到的数据缓存到本地内存中,之后业务服务进程收到相同的数据请求时就可以直接从本地内存中获取数据返回,将网络请求转化为高效的内存存取逻辑。
基本的缓存淘汰策略有哪些?
- FIFO(First In First Out):优先淘汰最早进入缓存的数据。
- LFU(Least Frequently Used):优先淘汰最不常用的数据。
- LRU(Least Recent Used):优先淘汰缓存中最近最少使用的数据。
- W-TinyLFU
LRU策略和LFU策略的缺点?
- 会导致缓存命中率大幅下降
W-TinyLFU将缓存的内存空间划分为哪两部分?
- Window LRU段
- Segment LRU段
W-TinyLFU策略的工作流程?
- 将首次被访问的数据X缓存到Window LRU段。
- 当Window LRU段的内存空间已满时,使用LRU策略将被淘汰的数据移入Segment LRU段中的probation段,之后数据X被访问时,再将其移入protected段。
- 当protected段的内存空间已满时,使用LRU策略将被淘汰的数据X移入probation段。
- 当数据X要被移入probation段,但是其内存空间已满时,使用LRU策略将被淘汰的数据V取出,与数据X进行访问频率的对比,将访问频率高的数据留在proation段,将访问频率低的数据淘汰。
Count-Min Sketch算法的运行流程?
- 选定M个哈希函数,分配一个M行N列的二维数组作为哈希表。
- 当某数据的访问频率增加时,对数据Key分别使用M个哈希函数计算出哈希值,再对N取模,然后将二维数组每一行对应的列位置的数值加1,即二维数组中M个位置的数值均被更新。
- 当查询某数据的访问频率时,进行同样的哈希计算,将二维数组中M个位置的数值读出,选择其中的最小值作为此数据的访问频率。
什么是缓存击穿?
- 缓存击穿指的是缓存中一条热门数据在缓存失效的瞬间,对它的并发请求会“击穿”缓存,直接访问数据库,导致数据库被高并发请求击垮。