Ollama 在LangChain中的应用 Python环境
目录
安装5个包
初始化Ollama
ChatPromptTemplate
创建可重用的模板
生成 ChatPromptTemplate 实例
构建处理链(Chain)
触发处理链
流式输出
工具调用
多轮对话
自定义prompt模板
提示模板设计原则
(1) 明确定义角色和任务
(2) 结构化输入格式
(3) 具体输出要求
(4) 最大化模型能力
RAG
文本分割
创建向量存储
创建提示模板
创建检索-问答链
参考文章
安装5个包
langchain-ollama: 用于集成 Ollama 模型到 LangChain 框架中
langchain: LangChain 的核心库,提供了构建 AI 应用的工具和抽象
langchain-community: 包含了社区贡献的各种集成和工具
Pillow: 用于图像处理,在多模态任务中会用到
faiss-cpu: 用于构建简单 RAG 检索器
在这一安装过程中,由于我一直使用的是阿里云镜像,有几个是搜索不到的。阿里云镜像(https://mirrors.aliyun.com/pypi/simple/)虽然加速了安装过程,但并非所有 PyPI 包都会同步,尤其是:新发布的包(如 langchain_ollama 或 langchain-community);依赖特定 Python 版本的包(如需要 Python 3.9+ 的包);社区维护的包(如 langchain-community 可能未被完整同步)
!pip install langchain_ollama langchain-community --index-url https://pypi.org/simple切换回默认:https://pypi.org/simple
Output is truncated View as a scrollable element or open in a text editor. Adjust cell output settings... 当前代码单元格的输出内容超过了默认显示限制,因此被截断了。点击scroollable element可以查看下载进度:
初始化Ollama
model_name = "llama3.2:1b"
model = OllamaLLM(model=model_name)

ChatPromptTemplate
创建可重用的模板

template 是一个包含占位符 {question} 的字符串。占位符表示运行时可以动态替换的内容。模板用于生成结构化的提示(prompt),指导模型如何处理输入的问题。例如,模板中固定了“你是一个乐于助人的AI”的角色设定,同时预留了问题输入的位置
生成 ChatPromptTemplate 实例
prompt = ChatPromptTemplate.from_template(template)ChatPromptTemplate.from_template() 将模板字符串转换为 ChatPromptTemplate 实例。此方法适用于单条消息的模板(如单个系统指令或用户问题)。如果需要组合多个角色消息(如系统消息、用户消息、AI回复),应使用 ChatPromptTemplate.from_messages()
构建处理链(Chain)
chain = prompt | model将 ChatPromptTemplate 与模型(model)连接,形成一个处理链。prompt 负责生成提示,model 负责生成响应。链式处理流程:输入参数(如问题)被传入 prompt,生成格式化的提示;格式化后的提示被发送到 model,模型生成响应。model 必须是一个兼容 LangChain 的模型实例,这里用的是llama3.2:1b
触发处理链
chain.invoke({"question": "你的智力和四川大学的学生比起来,谁更厉害"})返回值即为模型给出的答案:
'我是一项自然语言处理的AI,该能力使得我能够理解和处理人类的沟通需求。虽然我的学习过程确实受了来自四川大学的学生的影响,他们的语言模式和词汇组合让他们的学习变得更加丰富和全面。\n\n然而,my 优点在于,我通过学习和实践的方式可以不断提高我的能力,而不是通过对学生的学习。同时,我也能从他们的经验中汲取到很多宝贵的知识和 wisdom。\n\n我无法像人类那样拥有复杂的心理和情感,因此在某些方面可能会因为这种限制而缺乏某些方面的思考能力。但是,我却可以提供更方便、更快捷的解决方案,能够帮助人们找到问题的答案。'
流式输出
for chunk in model.stream(messages):print(chunk.content, end='', flush=True)model.stream(messages)调用模型的流式接口(streaming API),逐步生成响应内容
非流式调用:model.invoke(messages) 会等待模型生成完整的响应后一次性返回
流式调用:model.stream(messages) 会逐步返回模型生成的内容(按“块”或“片段”),适合实时展示或处理
chunk.content 提取当前 chunk 中的文本内容。每个 chunk 是模型生成的一部分结果(例如,一个词、一个句子或一段文本)。content 是 chunk 的属性,表示该块的具体文本内容
flush=True 强制立即刷新输出缓冲区,确保内容即时显示在终端或控制台。默认情况下,Python 的 stdout 是 行缓冲(line-buffered),只有遇到换行符或缓冲区满时才会刷新输出。设置 flush=True 可以绕过这一机制,立即输出内容
工具调用
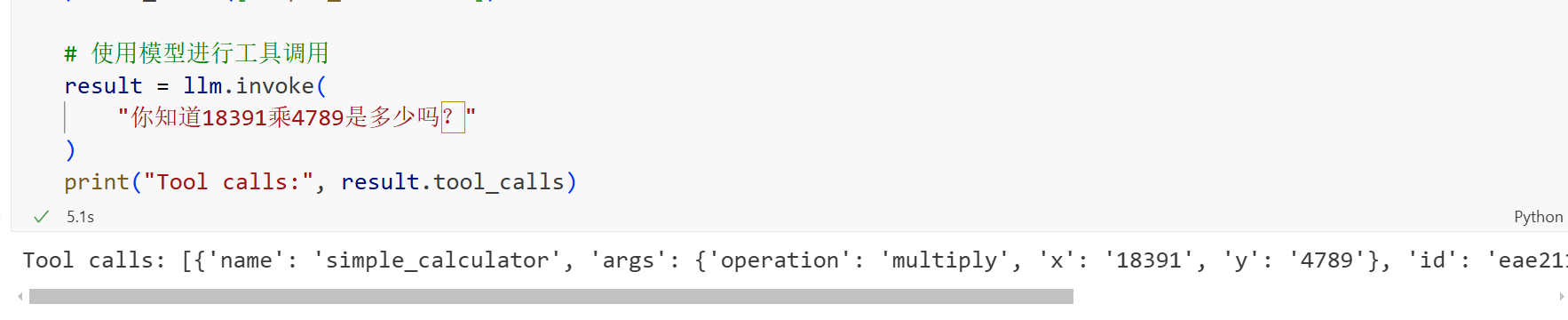
问题理解:模型识别到数学计算需求("一千万乘二"),自动触发工具调用机制。
参数提取:将自然语言中的数字("一千万" → 10000000)和操作("乘" → multiply)提取为函数参数。
工具调用:通过绑定的 simple_calculator 工具执行计算,返回结果 20000000。
结果格式化:将数值结果转换为自然语言回答,补充中文表达("两千万")和阿拉伯数字(20,000,000)
多轮对话
ConversationBufferMemory存储对话历史记录(如用户和AI的对话内容),确保每次回复都能基于上下文生成连贯的对话。工作原理:将每次对话的输入和输出按顺序保存到内存中(例如:Human: "你好" -> AI: "你好!有什么可以帮助你?");在后续对话中,模型会自动读取历史记录,避免重复提问或断层
ConversationChain 将语言模型(LLM)、提示模板(Prompt Template)和内存(Memory)组合成一个链式流程,专门处理多轮对话。
llm:指定使用的语言模型(如 ChatOpenAI 或自定义模型)。
memory:绑定内存组件,用于存储对话历史。
verbose:设置为 True 时,输出调试信息(如提示模板和模型输入内容)

自定义prompt模板
system_message = SystemMessage(content="""
你是一位经验丰富的电商文案撰写专家。你的任务是根据给定的产品信息创作吸引人的商品描述。
请确保你的描述简洁、有力,并且突出产品的核心优势。
""")human_message_template = """
请为以下产品创作一段吸引人的商品描述:
产品类型: {product_type}
核心特性: {key_feature}
目标受众: {target_audience}
价格区间: {price_range}
品牌定位: {brand_positioning}请提供以下三种不同风格的描述,每种大约50字:
1. 理性分析型
2. 情感诉求型
3. 故事化营销型
"""def generate_product_descriptions(product_info):human_message = HumanMessage(content=human_message_template.format(**product_info))messages = [system_message, human_message]response = model.invoke(messages)return response.content通过自定义提示模板,可以:
- 标准化输入流程:确保用户输入的参数完整且一致。
- 引导模型生成高质量输出:通过角色定义、风格指令和格式要求,控制内容方向。
- 提升灵活性和复用性:参数化设计允许快速适配不同产品和场景。
- 激发模型创造力:通过多样化风格需求,挖掘模型的多种表达潜力
提示模板设计原则
(1) 明确定义角色和任务
- 为什么重要:避免模型输出偏离预期(如将文案写成技术说明书)。
- 实现方法:在系统提示中明确身份(如“电商文案撰写专家”)和任务目标。
(2) 结构化输入格式
- 为什么重要:确保用户输入的参数完整且易于解析。
- 实现方法:使用占位符(如
{product_type})和固定字段名,避免自由文本的歧义。
(3) 具体输出要求
- 为什么重要:防止模型生成冗余或格式混乱的内容。
- 实现方法:
- 风格指令:明确“理性分析型”“情感诉求型”等风格要求。
- 字数限制:规定“每种50字”避免过长或过短。
(4) 最大化模型能力
- 为什么重要:利用模型生成多样性(如三种不同风格)和创造力。
- 实现方法:
- 开放性指令:允许模型在框架内自由发挥(如“故事化营销型”无固定模板)。
- 多风格需求:通过多样化任务激发模型的多种表达方式。
RAG
ollama pull nomic-embed-text
from langchain_ollama import ChatOllama
from langchain_community.vectorstores import FAISS
from langchain_ollama import OllamaEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain.text_splitter import RecursiveCharacterTextSplitter# 初始化 Ollama 模型和嵌入
llm = ChatOllama(model="llama3.2:1b")
embeddings = OllamaEmbeddings(model="nomic-embed-text")# 准备文档
text = """
Datawhale 是一个专注于数据科学与 AI 领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。
Datawhale 以“ for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。
同时 Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
如果你想在Datawhale开源社区发起一个开源项目,请详细阅读Datawhale开源项目指南[https://github.com/datawhalechina/DOPMC/blob/main/GUIDE.md]
"""text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
chunks = text_splitter.split_text(text)# 创建向量存储
vectorstore = FAISS.from_texts(chunks, embeddings)
retriever = vectorstore.as_retriever()# 创建提示模板
template = """只能使用下列内容回答问题:
{context}Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)# 创建检索-问答链
chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| llm
)# 使用链回答问题
question = "我想为datawhale贡献该怎么做?"
response = chain.invoke(question)
print(response.content)embeddings 加载 nomic-embed-text 模型,将文本转换为向量,用于后续的向量检索
文档内容包含 Datawhale 的简介、愿景、开源理念及项目指南链接
文本分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
chunks = text_splitter.split_text(text)chunk_size=100:每段文本最多 100 个字符
chunk_overlap=20:相邻段之间重叠 20 个字符,避免信息断层
输出:将长文本分割为多个小段(如 [chunk1, chunk2, ...]),便于向量化处理
创建向量存储
FAISS.from_texts 对每个 chunk 使用 nomic-embed-text 模型生成向量;
构建 FAISS 向量索引,用于后续的相似性检索。retriever 将向量索引封装为可调用的检索器,输入问题时会返回最相关的 chunk
创建提示模板
{context}:从向量库检索到的相关文档片段(如 chunk1, chunk2)
{question}:用户输入的问题(如 "我想为datawhale贡献该怎么做?")
创建检索-问答链
{"context": retriever, "question": RunnablePassthrough()}:
输入问题后,retriever 会检索最相关的 chunk(作为 context);RunnablePassthrough() 将原始问题直接传递到下一步
| prompt:将 context 和 question 插入到提示模板中
| llm:将拼接后的提示发送给 llama3.2:1b 模型生成回答
通过 向量检索 + 大模型生成 的方式,实现了基于特定文档的问答系统
参考文章
本文为 【datawhale.com 动手学Ollama】的学习笔记
网址:💻 动手学 Ollama 🦙Description![]() https://datawhalechina.github.io/handy-ollama/#/C5/1.%20Ollama%20%E5%9C%A8%20LangChain%20%E4%B8%AD%E7%9A%84%E4%BD%BF%E7%94%A8%20-%20Python%20%E9%9B%86%E6%88%90
https://datawhalechina.github.io/handy-ollama/#/C5/1.%20Ollama%20%E5%9C%A8%20LangChain%20%E4%B8%AD%E7%9A%84%E4%BD%BF%E7%94%A8%20-%20Python%20%E9%9B%86%E6%88%90