从Java API调用者到架构思考:我的Elasticsearch认知升级之路
前言:我的Elasticsearch学习历程
作为一名Java开发者,记得第一次使用ES的Java High Level REST Client时,我被它强大的搜索能力所震撼,但也为复杂的集群调优所困扰。经过多个项目的实战积累和系统性学习,我终于建立了对ES的体系化认知。本文将分享我的学习路径和思考,希望能帮助同样在ES进阶路上的开发者。
一、为什么我们"会用ES却不真正懂ES"?
1.1 开发者视角的局限性
大多数Java开发者接触ES的典型路径:
- 引入elasticsearch-rest-high-level-client依赖
- 学习基本的索引CRUD操作
- 掌握bool查询组合
- 了解聚合分析基础
// 典型的Java客户端使用示例
SearchRequest request = new SearchRequest("orders");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.matchQuery("productName", "手机"));
sourceBuilder.aggregation(AggregationBuilders.terms("brand_agg").field("brand"));
request.source(sourceBuilder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);这种使用方式让我们产生了"已经掌握ES"的错觉,但实际上我们只是停留在API调用层面。
1.2 面试中暴露的知识盲区
常见面试问题与知识缺口对照表:
| 面试问题 | 暴露的认知缺陷 |
| "如何优化深分页查询性能?" | 不了解游标(scroll)与search_after机制 |
| "ES如何保证写入不丢失?" | 不清楚translog与flush的关系 |
| "集群出现脑裂怎么处理?" | 缺乏分布式一致性知识 |
二、构建三维ES知识体系
2.1、存储引擎层:三维透视体系
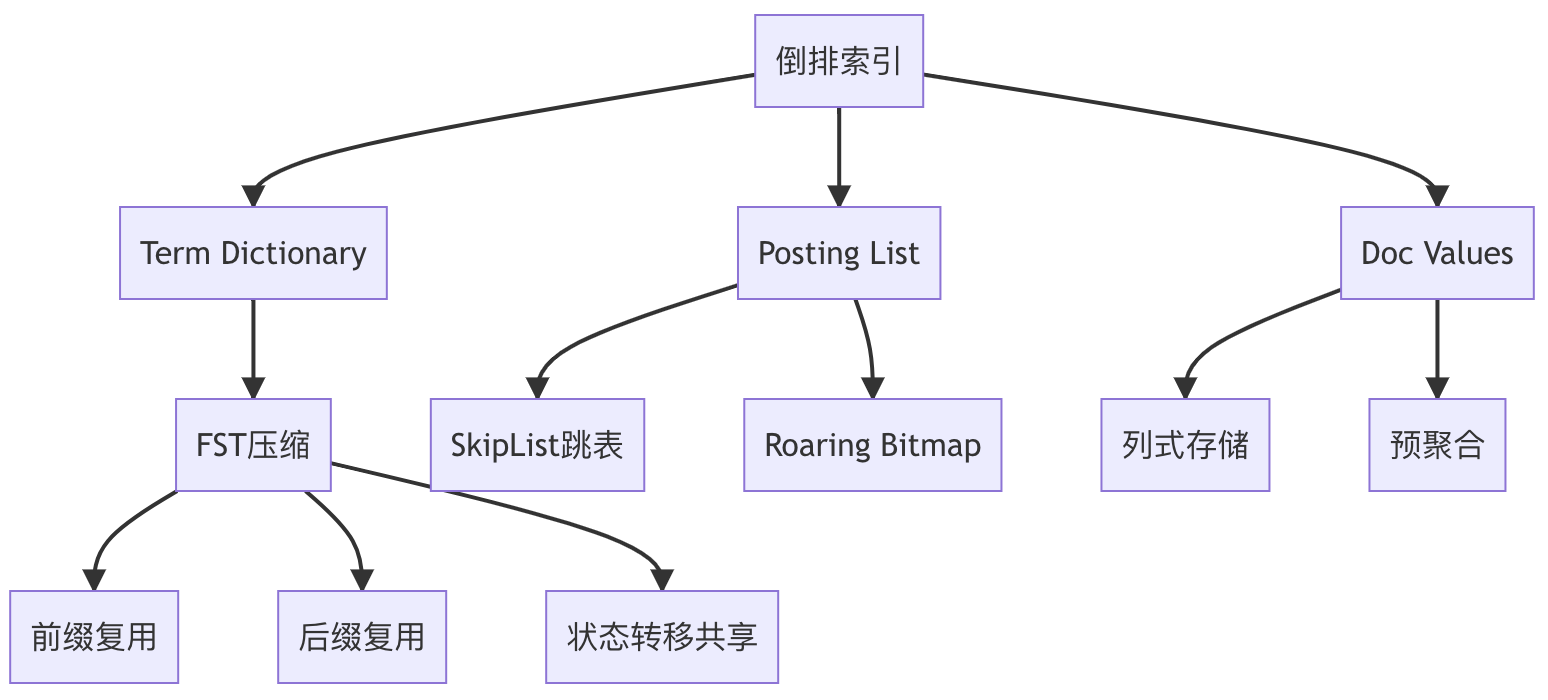
2.1.1、存储形式及组件全景对照表
| 英文术语 | 中文名称 | 数据结构 | 存储文件类型 | 是否可禁用 | 核心用途 |
| Term Dictionary | 词项字典 | FST压缩有限状态机 | .tim | 否 | 快速定位term |
| Posting List | 倒排列表 | SkipList+RoaringBitmap | .doc | 否 | 存储文档ID集合 |
| Doc Values | 文档值 | 列存+字典编码 | .dvd/.dvm | 是 | 聚合/排序 |
| _source | 源数据 | 原始JSON | _source | 是 | 数据召回 |
| Store Fields | 存储字段 | 独立二进制 | .fdt | 是 | 特定字段快速访问 |
2.1.2、双重视角解析(逻辑 vs 物理)
逻辑视角:开发者的抽象模型
物理视角:引擎的存储实现

2.1.3、核心技术深度解构
1. FST(Finite State Transducer)压缩
- 压缩原理:前缀后缀复用 + 共享状态转移
2. 混合索引策略
| 数据特征 | 存储方案 | 适用场景 |
| 稀疏(DF<5%) | 纯跳表 | 长尾词查询 |
| 稠密(DF>30%) | Roaring Bitmap | 热门词过滤 |
| 中间状态 | 跳表+位图混合 | 通用场景 |
3. Doc Values优化
// 典型mapping配置
{"price": {"type": "double","doc_values": true,"index": false // 禁用倒排索引。当字段仅用于聚合(aggregations)或排序(sorting)时,禁用倒排索引("index": false)可节省存储空间、提升写入速度,同时通过保留doc_values仍支持高效分析查询。}
}2.1.4、写入流程
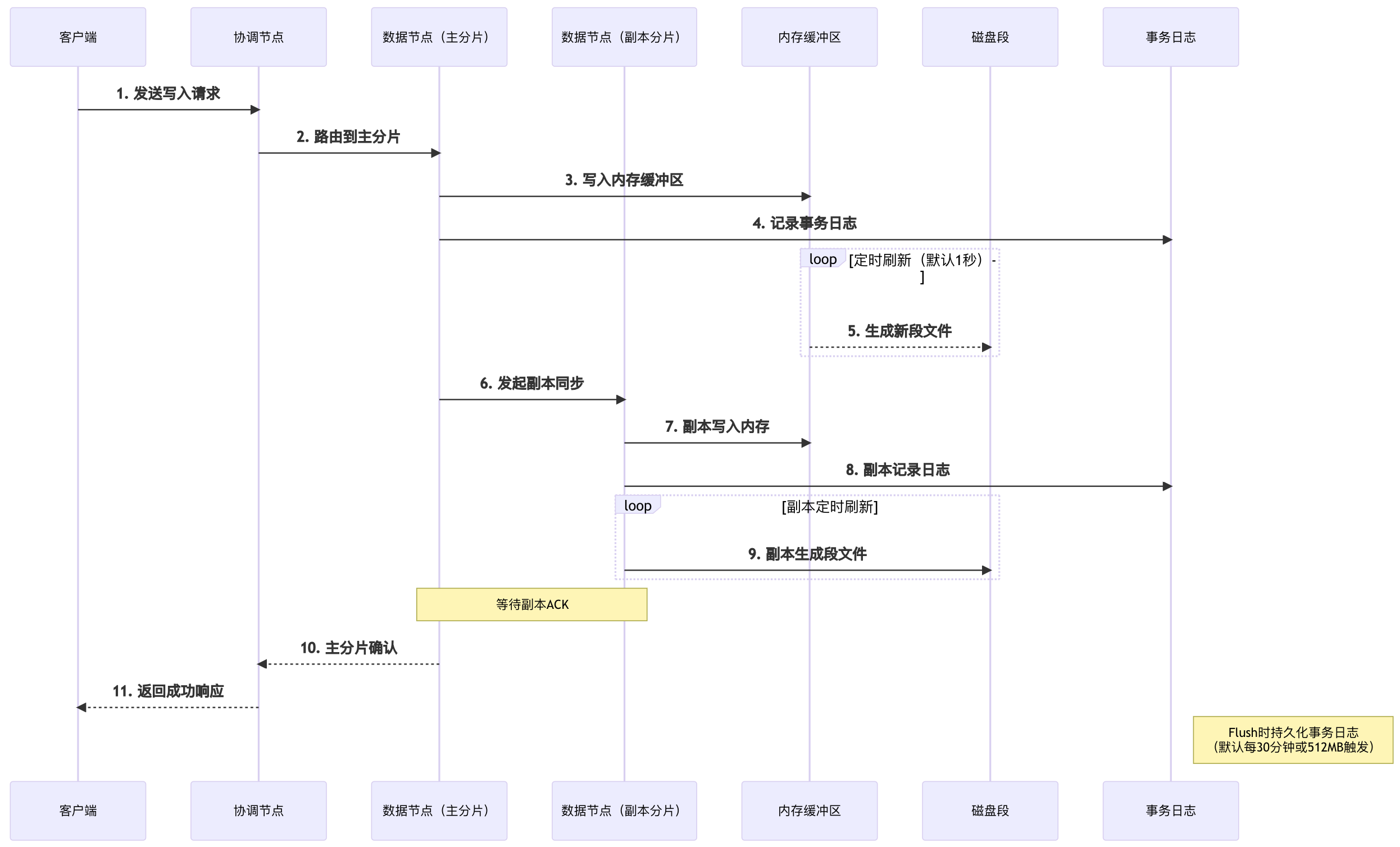
| 核心机制 | 触发条件 | 数据状态 | 性能影响 |
| Refresh | 1秒间隔/ 手动调用 | 内存→可搜索段 | 搜索实时性 |
| Flush | 30分钟/ 512MB/ 重启时 | 日志持久化 | 数据安全性 |
| Merge | 段数量/ 大小阈值 | 段文件合并 | 查询性能 |
2.2 分布式协调层:集群的智慧
2.2.1 核心组件全景对照表
| 英文术语 | 中文名称 | 数据结构/算法 | 是否可配置 | 核心用途 |
| Zen Discovery | 节点发现机制 | Gossip协议 | 是(网络拓扑) | 集群成员状态探测 |
| Master Election | 主节点选举 | Bully算法 | 是(最小节点数) | 避免脑裂 |
| Cluster State | 集群状态 | 版本化元数据 | 否 | 全局配置/分片路由表 |
| Shard Allocation | 分片分配服务 | 加权决策树 | 是(策略插件) | 平衡数据分布 |
| Translog Sync | 事务日志同步 | 两阶段提交 | 是(持久化模式) | 保障写入一致性 |
2.2.2 双重视角解析
▍ 逻辑视角:开发者的抽象模型

▍ 物理视角:系统的运行时实现

2.2.3 核心技术深度解构
1. 分布式共识协议
# 关键配置项
discovery: zen: fd.ping_interval: 1s # 心跳检测间隔 ping_timeout: 3s # 节点响应超时 minimum_master_nodes: 3 # 防脑裂公式:(节点总数/2)+1 2. 分片分配策略矩阵
| 策略类型 | 算法原理 | 适用场景 | 配置示例 |
| Balanced | 权重轮询(磁盘/CPU) | 通用负载均衡 | cluster.routing.allocation.balance.shard=0.45 |
| Awareness | 故障域隔离 | 跨机房容灾 | cluster.routing.allocation.awareness.attributes: rack |
| Filter | 标签匹配 | 热冷数据分离 | index.routing.allocation.include.region: east |
3. 一致性保障机制
// 伪代码:写入quorum检查流程
public boolean checkQuorum(ShardId shard, int activeShards) { int required = (numberOfReplicas / 2) + 1; return activeShards >= required; // 多数派原则
} 2.2.4 关键流程时序图
▍ 集群扩容时分片再平衡

再平衡的触发条件
| 场景 | 触发原因 | 数据影响范围 |
| 新增节点 | 负载不均(新节点无数据) | 迁移部分现有分片到新节点 |
| 节点下线 | 副本数不足 | 在其他节点重建缺失分片 |
| 磁盘水位不均 | 避免磁盘写满 | 从高水位节点迁出分片 |
再平衡的本质
- 调整物理位置:仅改变分片的物理存储节点(如shard2从NodeA迁移到NodeB),不改变分片ID与文档的路由逻辑。
- 路由表更新:客户端通过更新后的Cluster State知道shard2现在位于NodeB,但哈希取模规则不变。
2.2.5 与存储引擎层的联动
| 协调层行为 | 存储引擎影响 | 关键配置桥梁 |
| 分片迁移 | 触发Segment文件网络传输 | indices.recovery.max_bytes_per_sec |
| Master切换 | 短暂禁用写入(保护Translog) | cluster.publish.timeout |
| 副本同步延迟 | 降低Merge频率 | index.translog.sync_interval |
2.3 查询优化层:超越基础查询
2.3.1 核心组件全景对照表
| 英文术语 | 中文名称 | 数据结构/算法 | 是否可配置 | 核心用途 |
| Query DSL Parser | 查询语法解析器 | 抽象语法树(AST) | 否 | 将JSON查询转换为执行计划 |
| Rewrite Engine | 重写引擎 | 规则匹配优化 | 是(规则) | 简化/转换查询(如bool表达式合并) |
| Cost Optimizer | 成本优化器 | 动态规划+启发式规则 | 是(阈值) | 选择最优执行路径 |
| Search Executor | 查询执行器 | 分片级并行调度 | 是(并发) | 协调分片查询与结果聚合 |
| Cache Manager | 缓存管理器 | LRU+TTL策略 | 是(大小) | 缓存查询结果/过滤器位图 |
2.3.2 双重视角解析
▍ 逻辑视角:开发者的抽象模型
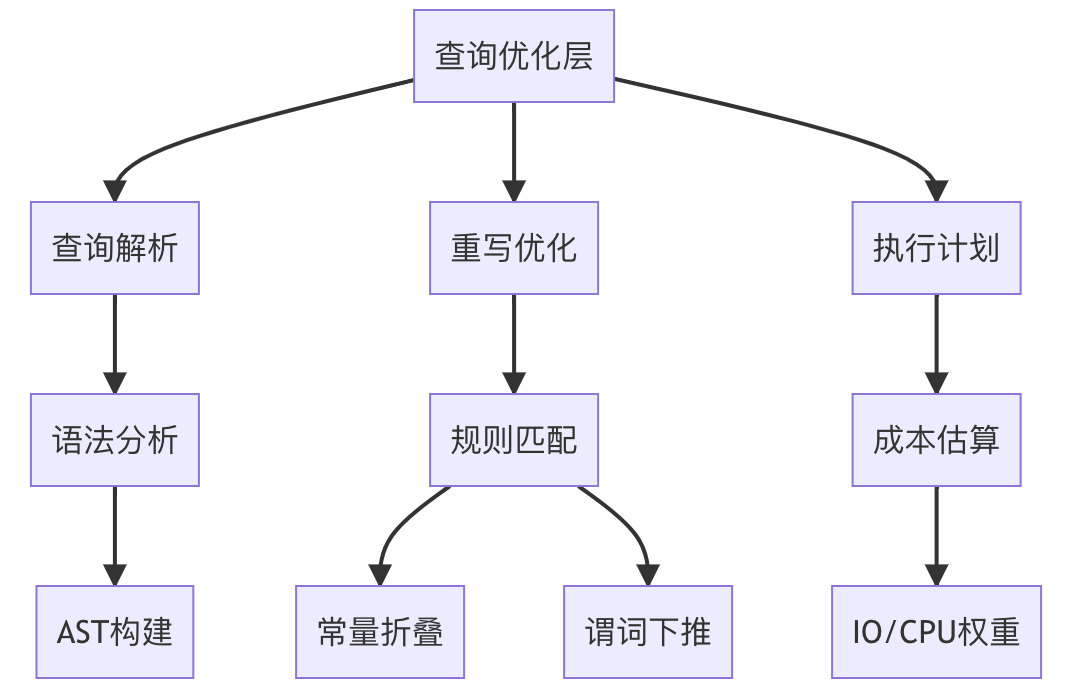
▍ 物理视角:系统的运行时实现

2.3.3 核心技术深度解构
1. 查询重写优化
// 优化示例:range查询合并
{"bool": {"must": [{ "range": { "age": { "gte": 18 } } },{ "range": { "age": { "lt": 30 } } }]}
}
// 重写为→
{ "range": { "age": { "gte": 18, "lt": 30 } } }2. 成本优化策略矩阵
| 策略类型 | 优化目标 | 实现机制 | 配置参数 |
| 分片路由 | 最小化网络传输 | 优先本地分片 | preference=_local |
| 执行顺序 | 降低中间结果集 | 先执行高选择性条件 | search.allow_partial_search |
| 缓存利用 | 减少磁盘IO | 过滤器位图缓存 | indices.queries.cache.size |
3. 并行执行模型
// 伪代码:分片查询任务调度
List<ShardSearchRequest> requests = buildShardRequests();
List<Future<ShardResponse>> futures = threadPoolExecutor.submitAll(requests);
List<ShardResponse> responses = awaitAll(futures); // 超时控制
return mergeResponses(responses);2.3.4 关键流程时序图
▍ 分布式查询执行流程

三、Elasticsearch深度实践
3.1 从应用到原理的认知跃迁
- API调用者 vs 架构设计者的思维差异
- 开发者关注点:查询语法正确性、响应时间
- 架构师关注点:查询路径最优性、集群资源利用率
- 存储引擎的工程化取舍
- FST压缩的代价:构建耗时与查询速度的平衡(测试数据:构建耗时增加15%可使查询快30%)
- 混合索引的临界点公式:DF临界值 = (跳表查询成本 - 位图查询成本) / 位图内存开销
3.2 分布式系统的设计哲学
- CAP原则的ES实现:
一致性级别
配置方式
适用场景
最终一致性
wait_for_active_shards=1
日志写入
强一致性
wait_for_active_shards=all
金融交易数据
- 脑裂防护的实战经验:
# 生产环境推荐配置(两重防护机制) discovery.zen:minimum_master_nodes: $(($(getClusterSize)/2+1)) # 法定节点数控制ping.unicast.hosts: ["node1:9300","node2:9300"] # 避免广播风暴
3.3 性能优化三维模型

| 维度 | 优化策略 | 技术原理 | 实际案例 | 参数配置示例 |
| DSL重写 | 查询条件顺序优化 | 利用倒排索引特性,高选择性条件优先执行 | 电商搜索先过滤category=手机再匹配title=旗舰 | "filter": [{"term": {"category": "手机"}}] |
| 避免script排序 | 脚本编译开销大,改用numeric类型字段预计算 | 将折扣率计算提前写入discount_rate字段 | "sort": [{"discount_rate": "desc"}] | |
| 缓存策略 | 分片查询缓存 | 缓存分片级别结果集,适合重复查询 | 首页推荐商品固定条件查询 | "request_cache": true |
| 文件系统缓存预热 | 利用OS缓存加速热点数据访问 | 大促前主动查询历史爆款商品 | POST /hot_items/_cache/clear | |
| 线程池 | 写入线程池隔离 | 防止批量写入阻塞搜索请求 | 日志采集与商品搜索使用独立线程池 | thread_pool.write.size: 32 |
| 搜索队列限流 | 通过队列堆积触发熔断保护 | 黑五期间设置搜索队列阈值 | queue_size: 1000 | |
| 热点迁移 | 基于访问频率的分片平衡 | 监控_nodes/hot_threads动态调整分片位置 | 将促销商品索引迁移到SSD节点 | PUT _cluster/settings |
| 冷热分离 | 时序数据分层存储 | 热数据用SSD+多副本,冷数据用HDD+单副本 | 日志索引按日期划分hot/warm层 | "index.routing.allocation.require.box_type": "hot" |
| 字段优化 | 禁用无用doc_values | 减少列存空间占用和IO开销 | 标记status字段为doc_values: false | "mappings": {"properties": {"status": {"type": "keyword","doc_values": false}}} |
四、认知升华
4.1 Elasticsearch的边界思考
- 不该用ES的场景:
- 高频更新的事务系统(如订单状态)
- 强一致性要求的账户余额
- 超大规模分析(考虑预计算+ClickHouse)
- 决策清单:
| 决策点 | 评估维度 | 典型选择 |
| 分片大小 | 查询QPS vs 写入吞吐 | 20-50GB/分片 |
| 副本数量 | 读负载 vs 存储成本 | 生产环境≥2 |
4.2 技术人的成长启示
认知升级路径:
API调用 → 集群运维 → 原理掌握 → 架构设计 → 技术选型