【无人机实时拼图框架(正射影像)论文翻译】OpenREALM: Real-time Mapping for Unmanned Aerial Vehicles
OpenREALM:无人机实时建图框架

作者:Alexander Kern, Markus Bobbe, Yogesh Khedar, Ulf Bestmann
出处:IEEE,2020
代码开源地址:https://github.com/laxnpander/OpenREALM
摘要

本文介绍了 OpenREALM,一个用于无人机(UAV)的实时建图框架。利用安装在移动无人机机载计算机上的摄像头,获取目标感兴趣区域的高分辨率图像拼接图。OpenREALM 提供不同的操作模式,允许在假设地面近似平面的情况下进行简单拼接,或者完全恢复复杂的 3D 表面信息以提取高程图和几何校正的正射影像。此外,利用无人机的全球位置对数据进行地理配准。在所有模式下,操作员都可以在地面实时查看生成地图的增量更新进度。所获得的最新表面信息将极大地推动各种无人机应用的发展。为社区利益,源代码公开在 https://github.com/laxnpander/OpenREALM。
I. 引言

对世界的勘测一直是人类好奇心的基本组成部分。随着飞机发明和上个世纪商业航空的成功,为这种好奇心增添了额外的视角。从空中观察世界总能令人惊叹。但这不仅仅是一个令人惊讶的视角,航空影像已融入生活的各个领域。精准农业、城市规划以及灾害风险管理只是未来几年中该领域最有前途的一些主题,它们将从该领域的进步中获益[1]。
除了获取数据的分辨率外,其他几个因素也将决定其成功。测绘过程的可用性、成本和时间对于几乎所有用例都至关重要。无人机(UAV)领域的快速发展为应对这些挑战提供了重要的解决机会。由于其潜在的轻量化设计和小尺寸,无人机可以快速大规模制造。随着开源自动驾驶仪的发展,它们的自主性已达到一个水平,几乎任何经过简短培训的用户都可以安全地规划和执行飞行任务。这一趋势已经使航空影像普及化,并催生了众多用于处理和分析获取的航空数据的软件,例如 Agisoft Metashape[2] 或 DroneDeploy[3]。此类软件背后的技术通常被称为“摄影测量”。虽然在经典理解中,任何考虑图像中物体形状或位置的空间测量都被称为摄影测量,但今天这个术语指代一个非常特定的工作流程。它涉及诸如光束法平差(bundle adjustment)等算法,这些算法通过大型几何优化公式来计算高度精确的相机位姿和观测场景的 3D 表面信息。

图1: OpenREALM 在无人机仍在空中时实时运行。它依赖于最先进的视觉位姿估计和单目密集重建框架来完全重建表面信息。
尽管光束法平差在考虑到通常需要优化的参数数量巨大时表现得异常高效和快速[4],但大多数提到的框架都仅在飞行后处理所有捕获的图像时才工作。这在几个方面并非最优。尽管所有信息在理论上是可用的,但在任务期间基于获取数据进行干预是不可能的。从任务开始到最终生成全局地图所需的总时间可能长达数小时,这在搜索和救援场景中是不可接受的。最后,尽管无人机在自主运行,但采集时间并未用于处理。
因此,在本文范围内,我们提出了一个框架,该框架能够读取由安装在无人机上的、经过标定的、向下指向的、两轴云台稳定摄像头获取的连续图像流。它提供四种不同的操作模式,每种模式复杂度递增,生成:

- 基于 GNSS 位置和航向的通用图像(RGB、IR等)的 2D 地图,
- 基于 GNSS 位置和视觉位姿估计的 RGB 图像的 2D 地图,
- 或基于 GNSS 定位和利用 GPU 加速立体重建的视觉位姿估计的 RGB 图像的 2.5D 数字高程模型。
模式 1) 设计用于现成硬件,如大疆产品。计算出的地图仅依赖 GNSS 和航向信息将图像对齐到全局地图中。然而,它也适用于创建无特征或高度动态区域的全局拼接图。
模式 2) 及更高模式需要具有高帧率的摄像头,适合视觉位姿估计。
模式 3) 的输出包括相机运动估计、每个视图的深度图、考虑表面高程的增量更新 2D 地图(正射影像),以及观测场景的顺序扩展的密集 3D 点云。
II. 相关工作

实时计算正射影像涉及多个步骤,跨越多个主题领域。我们的方法强烈依赖于视觉位姿估计和实时单目密集重建,这就是为什么 II-A 和 II-B 节概述了这些领域当前的最新技术。然后在 II-C 节介绍其他现有的无人机实时建图框架。
A. 视觉 SLAM

同步定位与地图构建(SLAM)是获取未知环境结构以及传感器在该环境中运动的技术的总称[5]。它最初是为机器人自主控制开发的,但此后在增强现实或自动驾驶汽车等众多领域找到了新的应用。如今,针对各种传感器都存在实用的解决方案,例如旋转编码器、激光扫描仪、GNSS 接收器和摄像头。特别是后者在过去几年经历了积极的研究,这归功于硬件设置的简单性和灵活性,通常被称为“视觉”SLAM。
在这方面,Mur-Artal 等人[6] 的“ORB-SLAM2”框架是一项值得注意的工作。在发布时,它为该领域设立了新标准,不仅提供视觉跟踪模块,还提供利用回环检测的全局优化和重定位策略。ORB-SLAM2 依赖于图像中独特的点特征(如角和边)(间接方法),但在无特征区域(如水面或平原)则难以获得。其他技术旨在评估整幅图像进行位姿跟踪,以获得更鲁棒和准确的结果(直接方法)。直接稀疏里程计(DSO)[7] 利用光度优化公式,通过最小化像素强度的差异来对齐图像。然而,由于缺少特征形式的抽象,在不永久保存整幅图像的情况下识别已访问的位置要困难得多。半直接视觉里程计(SVO)[8]等混合方法在像素块集合上使用直接图像对齐,因此能够应用现有的基于坐标的全局优化技术,同时在无特征区域仍保持鲁棒性。
所有这些框架都具备实时性能并且开源可用,但没有一个是专门针对空中测绘场景中向下指向的摄像头进行开发和测试的。
B. 单目密集重建

为了校正航空地图中由场景几何特性(例如高大建筑)引起的透视畸变,必须获取有关表面的信息。过去几十年里,人们付出了巨大努力来实现单目密集重建,这在计算机视觉中也常被称为运动恢复结构(Structure-from-Motion)[9],在大地测量学中称为摄影测量(Photogrammetry)[10],在机器人学中部分也称为单目 SLAM [11]。顾名思义,仅需一个移动的摄像头就足以重建密集的表面信息。虽然今天商业软件的数量众多(见第一节)可以在离线状态下进行长达数小时的重建,但具有实时性能的通用产品尚不存在。像 Skydio[12] 这样的公司最近利用深度学习方法突破了看似可能的界限,但由于它们是闭源的,关于它们具体如何实现结果以及可能存在哪些限制的信息鲜为人知。
在实时要求下,基本挑战与视觉 SLAM 非常相似。只是创建的地图预期要完整得多。无特征区域不应该为了更高的位置精度而被遗漏。因此,需要重建更多的数据,计算负载是密集表面重建的关键挑战之一。Pizzoli 等人发表了该领域的重要开源研究。他们的框架“OpenREMODE”[13] 提供基于相机基线的距离加权和深度不确定性的贝叶斯公式以最小化噪声。同时,它允许在显卡上进行并行化,使其能够实时运行。GPU 加速对于 Hane 等人[14]也至关重要,他们使用固定数量的虚拟平面在不同方向上扫过一组图像,并识别共享同一平面的点对应关系。他们的“平面扫描库”(PSL)专门为城市环境中的实时重建而设计,这归功于城市环境中自然存在的“盒状”设置和数量有限但非常独特的平面。然而,它也将在航空测绘中证明其高效性。
C. 实时建图

与视觉 SLAM 和密集重建方面的大量文献相比,研究无人机实时建图的资料很少。传统方法主要通过检测和匹配连续图像之间的特征点来执行 2D 全景拼接,例如[15]。然而,这种策略主要依赖于计算透视变换矩阵(单应性矩阵),而该矩阵仅描述了两个图像平面之间的运动。这种表示缺乏灵活性,因为它不允许使用摄影测量和运动恢复结构领域的成熟技术。对平面表面的限制排除了对 3D 数据的考虑,而这反过来又会改善结果,特别是在较低高度和有显著地面高程的情况下。此外,几乎任何实时航空测绘的用例都将受益于数字表面模型。
为了克服这一根本限制,需要获取采集相机的 3D 位姿。Bu 等人朝这个方向迈出了一步,他们发布了开源软件“Map2DFusion”[16]。它用一个最先进的视觉 SLAM 替代了典型拼接流程中的图像对齐模块。因此,回环检测、全局优化和在视觉挑战性环境中的鲁棒跟踪由成熟且经过充分研究的框架在外部提供。从 3D 位姿开始,然后将图像投影到一个公共参考平面以创建全局拼接图。然而,没有考虑表面高程,视觉畸变是不可避免的。为了实现今天公认的航空摄影测量,不仅要重建相机位姿,还要重建表面结构。Hinzmann 等人[17]首次提供了一个从位姿估计、密集场景重建到正射影像生成的实时完整流程。然而,他们既没有利用最先进的视觉 SLAM 进行位姿估计,也没有提供接口来集成其他密集重建实现。接下来几章介绍的框架旨在实现这两点,同时其架构足够通用,既可以执行简单拼接,也可以执行完整的 3D 重建。
III. OPENREALM

本章提出了一个用于实时航空测绘的实现方案。该框架的主要贡献不是提供特定的算法或数学公式,而是设计一个通用且鲁棒的基础架构。

图 2 展示了三层结构的整体设计。第一层是使用机器人操作系统(ROS)实现的“传输层”(Transport Layer)。在航空测绘场景中,至少有两个不同的处理设备。一个设备在无人机上,通过线缆连接到摄像头以保存或分发获取的图像。另一个通常是地面控制站(GCS),由用户操作以规划、执行和监控飞行任务。在我们的情况下,这两台设备之间的通信需要相当大的带宽来传输图像文件,但它们也可以分担处理负载。ROS 非常适合此任务,因为它通过 WiFi 以模块化的发布-订阅模式分发数据。捕获的数据包括带有地理标签的图像和摄像头的航向信息。这些数据通过一个适配器节点(可能针对特定应用进行定制)输入核心框架。我们倾向于简单地将所需数据作为 Exiv2 标签读写到图像的元信息中。
第二层是“阶段层”(Stage Layer),包含流程控制算法。由于提出的架构设计为流水线,每个阶段都被封装,仅通过其相应的 ROS 节点向其对应方向交换结果。这样,一个阶段的输出自然是下一个阶段的输入。这意味着存在一些限制,例如阶段之间缺少反馈循环,但优点是设计清晰,任务分配严格。各个阶段掌握关键技术,将在后面详细描述。
A. 位姿估计


位姿估计阶段的示意工作流程如图 3 所示。启动时,它为支持的框架之一(目前可以是 ORB SLAM 2、DSO 或 SVO,具体取决于传递的初始参数)创建一个视觉 SLAM 接口(IF)。传入的帧通过该接口重定向到实际的 SLAM 实现,其中估计相机位姿矩阵 M。注意,M 定义为从相机坐标系到世界坐标系的变换。如果跟踪成功,帧将在所谓的“地理配准器”(georeferencer)中处理。该模块尝试利用视觉位置和 GNSS 位置识别从局部视觉坐标系到全局地理坐标系的变换。由于需要一组初始测量值进行鲁棒计算,传入的帧可能会被排队,直到估计误差低于某个阈值。在求解任意尺度并对齐视觉轨迹和 GNSS 轨迹后,所有帧都会被发布。此步骤之后,计算出的位姿描述为:

![]()
如果视觉 SLAM 框架由于例如水面或平原等无特征区域而无法跟踪当前帧,状态将切换到“丢失”(Lost),并且不设置视觉位姿。为避免在这种情况下测绘过程完全失败,可以使用以下公式计算一个回退解决方案:
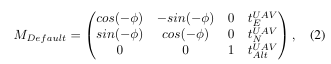

B. 密集化(Densification)
在上一阶段中,当前输入帧的相机位姿已在地理坐标系中计算出来。该位姿可以是视觉估计的,也可以仅基于 GNSS 和航向信息。前者精度高,但在无特征区域缺乏鲁棒性。后者通常总是可计算,但不确定性较高且姿态是固定的。在密集化阶段,仅使用具有视觉估计位姿的帧来重建观测场景的密集 3D 点云,遵循图 4 中的工作流程。

首先,检查输入帧的适用性。如果位姿被识别为视觉估计的,则初始化深度图创建。根据所选实现,一组帧被传递给密集化器接口(densifier interface)。与位姿估计阶段中的视觉 SLAM 接口类似,这反过来又提供了集成最先进重建框架的可能性。目前仅集成了 PSL(参见 II-B)。在密集重建之后,深度图被投影到 3D 点云中,任何先前存在的稀疏点都会被覆盖。
C. 表面生成

在前面的阶段中,所有已处理的帧都估计了地理配准的位姿。这可以基于图像数据使用视觉 SLAM,也可以基于先验的 GNSS 位置和航向。随后,仅针对那些具有视觉估计位姿的帧生成了深度图并将其投影为密集点云。因此,后续阶段必须处理可能出现的三种不同类型的帧:
● 具有 GNSS 位置、固定姿态且无点云的帧(如果视觉位姿估计失败),
● 具有视觉估计的精确位姿和稀疏点云的帧(如果仅密集化失败),
● 具有视觉估计的精确位姿和密集点云的帧(如果所有先前阶段都成功)。
表面生成阶段评估当前输入帧的所有数据,并提出一个数字表面模型(DSM),该模型使用简单平面或 2.5D 高程图来描述观测到的场景。但感兴趣的不仅是高程,表面法线和观测角通常也可以在相同过程中重建。为此,一种高效的结构是有益的,它能将特定的地理位置与其所有收集到的信息紧密耦合。Hinzmann 等人提出使用 Péter Fankhauser 的开源库“Grid Map”[18] 来完成此类任务。它由一个感兴趣区域(ROI)和地面采样距离(GSD)定义。可以堆叠多个数据层,因此网格的每个单元都由一个多维信息向量组成。对于 OpenREALM,我们采纳了这个想法,但重新实现了一些模块。因为 Grid Map 设计为固定尺寸并随机器人系统移动,所以动态增长地图效率较低。然而,在我们框架的后期阶段,这恰恰是有用的(见章节 III-E)。
算法 1 展示了在传入帧被识别为“平面”情况下的通用工作流程。必须已知粗略的地面尺寸,这可以通过将帧投影到一个公共参考平面来计算。下一步创建一个网格并用零高程表面填充。因为地图稍后会调整大小,所以在此特殊情况下 GSD 并不重要,只要该结构至少包含一个单元即可。
相比之下,创建高程表面的过程更为复杂。算法 2 以伪代码形式展示了实现。它主要遵循 Timo Hinzmann 等人[17] 提出的工作流程。首先,密集点云的 x 和 y 坐标通过一个二维二叉 k-d 树进行结构化。接下来,使用此 k-d 树计算 1% 所有点的最近邻距离。结果被假定为后续网格地图创建的 GSD,而感兴趣区域再次由帧在参考平面上的投影提供。在添加了“高程”('elevation')和“有效性”('valid')层之后,对网格的每个单元 (xcell,ycell)进行最近邻搜索。注意,xcell 和 ycell都是 UTM 坐标。对于所有检测到的邻点,从密集点云中提取 z 分量,最后插值计算出该单元的高程。

(伪代码表格 算法1和2 - 保持原样)
D. 正射校正(Ortho Rectification)

正射校正阶段的目标是利用先前估计的表面模型和相机位姿来校正由视角和表面结构引起的图像视觉畸变。最佳情况下,生成的正射影像具有高分辨率,以便轻松检测兴趣点(例如人、车辆等)。Hinzmann 等人提出了两种不同的方法来实现这种校正:
- 基于点云的正射影像(前向投影)
- 基于网格的正射影像(后向投影)
虽然方法 1) 的计算时间最短,但作者指出其对重建的密集点云有很强的依赖性。特别是由于点云中的孔洞导致的较小区域覆盖被注意到。但有更多理由考虑方法 2)。通过将观测场景的高程保存为 2.5D 网格地图,它可以被视为一个规则的单通道图像,只是数据是浮点高程值而非强度值。因此,它也可以像常规图像一样高效地调整到任何所需的分辨率。因此,空间分辨率和纹理分辨率可以视为两个独立的参数。空间分辨率主要取决于密集化和表面生成阶段,而纹理分辨率是独立的,可以设置为任意值,仅受原始图像分辨率的限制。如果测绘流水线的输入图像远大于多视图重建所能处理的尺寸,这尤其有用。因此,本实现选择了“基于网格的正射影像”技术。

图 5 可视化了正射校正的基本工作流程。首先,包含高程和有效性层的输入网格地图将调整大小到所需的正射影像地面采样距离。下一步,为网格的每个单元创建一个 3D 点 X:

对于特定单元观测到的像素位置 (u,v)(u, v)(u,v) 现在被确定,并可以设置在包含 RGB 信息的新颜色层中。由于高程图中的噪声或弱位姿估计,反向投影的点可能被识别为超出图像边界。这些点将被标记为无效。在此阶段,除了校正图像外,还为每个单元计算观测角。这是实现最终影像拼接中高正交性的附加参数。
E. 影像拼接(Mosaicing)

影像拼接是最后的处理阶段,将之前收集的所有数据融合到一个单一的场景表示中。虽然所有先前的阶段都能随着时间的推移保持计算资源大致恒定,但影像拼接不能。所有顺序密集化、重建和校正的帧被组合成一个高分辨率的拼接图。主要挑战是保持所需资源最小化。

图6可视化了该工作流程。通过接收来自正射校正阶段的第一帧,全局地图被初始化。之后的新帧被称为“地图更新”,可以分成没有先前信息的区域和重叠区域。前者直接写入全局地图。然而,后者被提取出来,从而存在两个子地图,它们都仅描述各自数据(全局地图重叠区域或地图更新重叠区域)的重叠区域。下一步,为子地图的每个网格单元计算一个混合值,该值最能描述该区域各层的表面。最后,这个混合区域被写回全局影像。
流程如下:
-
第一帧:系统以第一帧为基础,初始化一个包含“栅格图”(GridMap)结构的全局地图。
-
后续每一帧:
-
如果该帧对应的区域在全局地图中尚未被覆盖,则直接将其写入;
-
如果该区域已经被其他帧覆盖,则进入融合处理流程:
-
从全局地图中裁剪出一个子图,表示已有图像的重叠区域;
-
将新图像帧中对应区域也提取出来,构成一个“更新子图”;
-
对两个子图中重叠的像素进行融合处理;
-
将融合结果写回到全局地图中。
-
-
对于网格单元的混合,可以采用多种策略。本文选择了一种概率方法,描述如下。基本问题可以总结为:“如果对一个网格单元的高程存在两个不同的假设,选择哪一个?”为了解决这个基本问题,在全局地图中添加了三个附加层:“高程方差”('elevation variance')、“高程假设”('elevation hypothesis')和“观测次数”('number of observations')。一旦地图更新到达,对于重叠区域的每个单元,使用以下公式计算新的高程的临时浮动平均值:

如果 ![]() 低于某个阈值,则方差和平均值的新值将被写入网格地图层。此外,当前单元的观测次数会递增。如果
低于某个阈值,则方差和平均值的新值将被写入网格地图层。此外,当前单元的观测次数会递增。如果 ![]() 超过方差阈值,则存在该单元的两种不同假设。在此新假设首次出现后,它无法解决,因此被写入“高程”层,而现有数据保持不变。一旦该特定单元的新更新到达影像拼接阶段,就将浮动平均值和样本方差与已设定的高程和可能的第二个假设进行比较。现在选择样本方差较低的那个作为最可能的假设,而另一个则写入假设层。上述策略旨在通过最小化方差来减少高程中的噪声。
超过方差阈值,则存在该单元的两种不同假设。在此新假设首次出现后,它无法解决,因此被写入“高程”层,而现有数据保持不变。一旦该特定单元的新更新到达影像拼接阶段,就将浮动平均值和样本方差与已设定的高程和可能的第二个假设进行比较。现在选择样本方差较低的那个作为最可能的假设,而另一个则写入假设层。上述策略旨在通过最小化方差来减少高程中的噪声。
IV. 评估

对所提出框架进行全面分析超出了本文的范围。因此重点放在评估初始要求是否得到满足上。关键特性是提供实时 2D 地图。因为基于数字表面模型创建正射影像是最具挑战性的任务,所以在以下评估中将其视为默认操作模式。然而,为了在 IV-D 节进行比较,我们也展示了其他模式的建图结果。
A. 数据集

据我们所知,目前没有公开的、适用于视觉 SLAM 应用(高帧率、高质量固定内参摄像头)的基准航空测绘框架数据集。因此,有必要创建一个。我们的自定义数据集由一个 560mm 轴距的四旋翼无人机获取,起飞重量 2 kg,估计总飞行时间 15 分钟。无人机导航栈包括运行 APM 的 Pixhawk 2.1 自动驾驶仪、ublox NEO-7 GNSS 模块和 HMC5883L 数字罗盘。它配备了一个 Odroid XU4 伴侣计算机,通过线缆连接到 Pixhawk。Odroid 运行 Mavros 和一个自定义摄像头节点来抓取图像、创建 Exiv2 标签(例如 GNSS 和航向信息)并将所有数据写入硬盘。图像流和全局位置均以 10 Hz 更新,但未同步。视觉设置包括一个由 IDS Imaging Development Systems GmbH 制造的 UI-5280CP Rev. 2 摄像头,具有全局快门、5 MPix 分辨率和 2456x2054 像素的图像尺寸。然而,为了减少带宽并提高伴侣计算机的性能,图像被下采样为 1228x1027 像素。作为评估的处理硬件,所有测试均在 XMG P406 笔记本电脑上进行,该笔记本配备 Intel i7-6700HQ CPU、NVIDIA GeForce GTX 970M 显卡和 16 GB RAM。使用上述硬件,获取了包含 3276 张图像的集合。无人机轨迹在观测场景(约 250x250m,展示德国 Edemissen 的一个废弃机场)上方描绘了蛇形航线(图 7,绿色),具有 99% 航向重叠和 50% 旁向重叠。该数据集对视觉算法存在一些挑战,这些挑战也展示在图中。A) 是南部的森林,其纹理非常重复,使得基于特征的视觉 SLAM 难以提取独特的点。B) 的情况类似,但由均匀的表面引起。插图 C) 展示了波纹铁皮屋顶上的区域混叠效应,这是因为重复的屋顶图案尺寸处于 GSD 的范畴内。
B. 视觉 SLAM 的位姿精度

首先应该对位姿估计进行评估。高精度的位姿很重要,因为所有后续处理阶段都会继承其不确定性。

我们使用经典的离线摄影测量软件 Agisoft Metashape 计算了所有 3276 张图像的轨迹作为地面真值(ground truth)。作为视觉 SLAM 框架,我们将分析限制在 ORB SLAM2。

图 8 显示了结果。在 a) 图中,显示了每个坐标轴的平移误差。尤其是 xy 轴的对齐几乎没有可见的位移。另一方面,z 轴等同于场景的估计深度,这是使用多视图几何重建的。因此,该轴应该是最不确定的,并且确实可以测量到与地面真值的轻微偏差。在 60-100 秒之间,无人机出现了第一个转弯点,这也是图 7 中的视觉挑战区域 B。该区域的特征点数量少显著降低了整体精度。图 8 b) 中的相对位姿误差(RPE)支持了这一论点,因为它在转弯前达到最高峰值,之后迅速下降。平均绝对位姿误差(APE)为 0.53 米,表明 ORB SLAM 2 在视觉位姿估计方面整体表现良好。
图 8: ORB SLAM2 的位姿精度比较。地面真值轨迹使用 Agisoft Metashape 计算。
C. 表面质量

上一节展示了视觉位姿估计的性能。考虑到某些区域具有挑战性的、低特征纹理,结果是很有希望的。下一步是分析 3D 表面重建。使用 Agisoft Metashape 生成地面真值(ground truth)。为此目的,将数据集的前向重叠度减少到 80%,以保持合理的计算时间(1小时45分钟)。各阶段的设置选择使得处理在硬件上仍然能够实时进行,同时空间分辨率尽可能高。最终地图的生成密集点云被导出到开源软件“CloudCompare”[19]中。在那里,使用迭代最近点算法(ICP)将其与地面真值对齐,以减少地理配准的影响。随后,实时创建的密集点云图像中的每个点都通过其对应的位置在网格上的颜色值进行编码显示。

如图 9 所示。
所提出实现的密集化处理使用了 PSL。达到的 GSD 为 0.15 米/网格单元。数据集中观察到的混叠效应(见图 7 c))对重建过程产生了严重影响。房屋在 3D 中几乎无法识别。这并不令人惊讶,因为 PSL 试图计算每个像素的深度值,即使三角测量非常不确定。跑道的其余部分与地面真值对齐良好。地图左上角的平地(就在转弯点之前)具有最高的偏差(-1.5 至 0.5 米)。这也是位姿估计显示显著偏移的区域。因此,第一阶段中的初始误差很可能已经传播到了影像拼接阶段。总体而言,结果仍有改进空间,但重要的是要记住,OpenREALM 的处理时间是实时的,而相比之下 Agisoft Metashape 花费了数小时。
D. 正射影像质量

在上一节进行表面重建的同时,生成了 2D 正射影像。正射影像提供了测绘区域的快速概览,并已成为航空摄影测量的基本要素。它们与选择的全局坐标系对齐,并允许测量真实世界的距离。对此类影像的质量评估很困难,因为视觉畸变很容易被人眼发现,但自动检测更具挑战性。因此,人工检查应该是足够的。
一张好的正射影像应具有高分辨率、均匀的外观、低几何畸变且没有视觉伪影。它应尽可能多地代表观测场景的细节,并应在全局上精确对齐。

视觉检查的地面真值如图 11(左)所示。正如预期的那样,Agisoft Metashape 能够重建场景而没有重大缺陷。该地图没有重影或重叠边缘,分辨率高达 0.07 米/像素。相机曝光时间的变化传递到了地图顶部的田野区域,使其略微变亮。但这并没有显著影响地图的完整性。
作为比较,也展示了所有操作模式的结果。左起第二张图(Mode 1)的图像仅基于 GNSS 和航向信息定位。可以看到几处明显的错位,这是由于假定的相机航向与真实航向之间存在系统性偏移造成的。通过同步以及更严格地对齐相机和无人机航向,该模式的正射影像可以进一步改进。右起第二张图(Mode 2)使用了视觉 SLAM 进行位姿估计,但没有执行 3D 重建。它代表了实时建图的最新技术水平,因为它不需要完整的表面重建,但可以生成视觉上吸引人的结果。通过改进的混合(blending),正射影像接近地面真值。然而,这两种模式的几何畸变都是无法在没有表面信息的情况下克服的根本问题。最右边(Mode 3)是带有高程信息的地图。由于密集化过程,它在计算上更昂贵,但显示出与 Metashape 正射影像相似的、经过校正的、均匀的结果。特别是地图上部的建筑伪影更少,看起来更像地面真值。
总的来说,表面数据在视觉上改善了全局地图。较大的错位和几何畸变得以消除。然而,最大的好处是观测场景的 3D 效果。在搜索和救援等用例中,此类信息对于协调和态势感知至关重要。
E. 实时性能

作为本节的最后一步,进行处理性能的评估。一般来说,一个阶段的处理速度应略快于接收新输入的速度。由于所提出的实现设计为多线程流水线,仅对每个阶段进行简单的时间测量是不够的。例如,如果密集化阶段的平均计算时间为 0.2 秒,它可能以 5 Hz 的频率发布新帧给下一阶段,但也可能以 1 Hz 发布。那么,一个平均计算时间为 1.0 秒的后续阶段可能没问题,或者可能超载 5 倍。通过测量停机时间(downtime)也可以检测到空闲状态。然而,停机时间为 0.0 秒也可能意味着该阶段运行良好。因此,选择了另一种方法,概述如下。当前的传输层是在 ROS 中实现的。因此,处理阶段之间交换的消息在 ROS 基础设施中传输。为了识别每个阶段是否在限制范围内执行,跟踪了交换的消息速率。通过测量每个阶段的输入和输出消息频率,可以估计整体工作负载。一个必要的假设是,每个阶段都处理每一帧,并且没有人为限制来降低输出速率。由于关键帧选择,这对位姿估计阶段不成立,因此暂时忽略它。所有其他阶段处理并发布它们接收到的每一帧。性能度量定义为:


图 10 显示了使用 PSL 进行 3D 重建方法的性能。位姿估计阶段以 10 帧/秒的输入图像流提供,并以大约 2.4 Hz 的频率输出关键帧。其他阶段的性能日志显示,尤其是在开始时存在波动。密集化阶段有周期性的峰值。这可以用 GPU 的额外参与或场景重建的复杂性增加来解释。然而,所有阶段都收敛到 δPerf=1.0\delta_{\text{Perf}}=1.0δPerf=1.0,因此满足要求范围内的性能。
V. 结论

我们提出了一个用于无人机的实时建图框架。不同的操作模式使用户能够执行基于 GNSS 或视觉 SLAM 的图像拼接,或者完全重建 3D 表面并提取几何校正的正射影像。表面质量应在未来进一步改进。当前 SLAM 和 3D 重建的实现并非为航空测绘场景设计和优化。该领域的进一步研究应显著改善结果。此外,提供用于基准测试建图框架的公共数据集可能会推动未来的进展。
