CFD仿真硬件选型建议
本文仅针对台式机与工作站进行Fluent和Rokcy仿真的建议,仅供参考。硬件型号信息截至于2025年6月。
1 基础原则
硬件选型,各硬件的限制性因素总结如下:
- CPU决定计算速度
- 内存容量决定可计算模型规模
- 磁盘容量决定数据存储规模与数据读写时间
1.1 CPU
对于CPU,重点参考因素包括:
- 核心架构
- 核心数量与频率
- 缓存容量
CPU建议买新不买旧,优先选择核心架构发布时间较近的新款CPU,通常单核性能更快。
从实际运行表现而言,更推荐AMD的CPU。英特尔的大小核架构CPU极不推荐,因为可能会使部分负载任务放置于效能核心导致运算耗时过长。
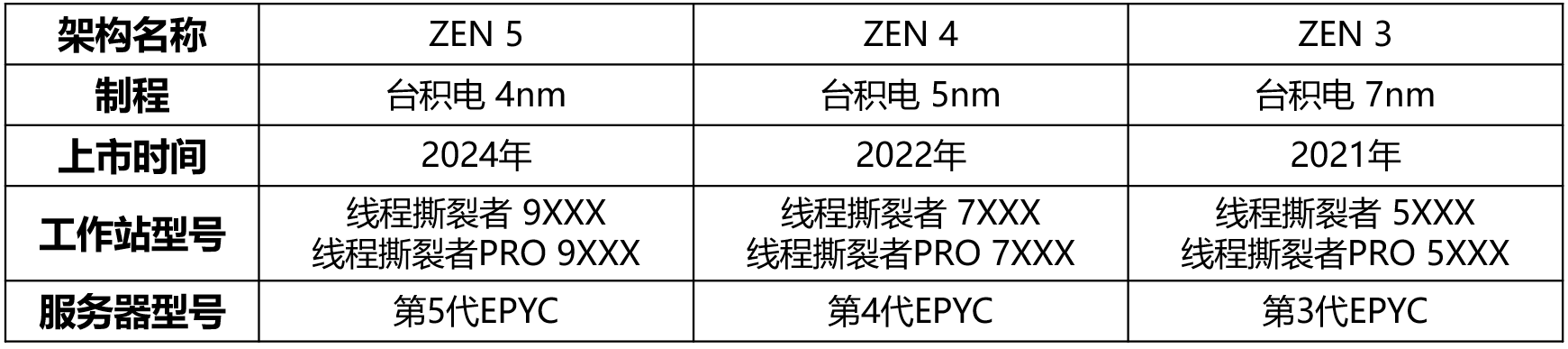
AMD近期的CPU如下表所示。截至发文时,ZEN 5 核心的线程撕裂者暂未上市。
1.2 内存
若内存容量过小,会因为内存不足而导致程序崩溃。内存用量由单元数量与类型、物理机理、算法设置等多种因素决定。
由于Fluent计算特性,建议所有问题均使用双精度计算。双精度相对单精度,内存需求量多50%。
对于纯多面体网格,若使用单精度计算,Fluent的内存用量预估:
- 两方程湍流模型(k-epsilon和k-omega),SIMPLE、PISO 速度-压力耦合格式,大约 2GB/百万单元
- 两方程湍流模型(k-epsilon和k-omega),COUPLED 速度-压力耦合格式,大约 3GB/百万单元
- 若开启传热、多相流等其他物理模型,则内存需求量更大
- 同一模型若调用更多核心数进行计算,也需要更多内存量,因为需要一部分内存空间用于核心间数据传递
内存传输速率和内存条数量会影响数据传递进而影响计算速度。建议尽量采用高频多通道 DDR5 内存条,数据传输速率更快。
内存也采用 MT/s(million transfer/second)作为数据传输速率单位,其数值上约为 MHz为单位的内存频率两倍。
1.3 磁盘
磁盘读写速度可以显著影响运算用时,特别是瞬态问题。磁盘建议使用固态硬盘,读写速度越高越好,并注意磁盘写入寿命。
1.4 主板
主板是每个CPU都有对应支持的主板型号,需要注意对应。不同主板之间主要差异除了尺寸之外,包括可支持的内存容量与频率、可扩展插槽数量、无线网络等。
1.5 显卡
目前Fluent和Rocky均支持GPU运行。受限于硬件支持情况,建议使用英伟达显卡,可使用游戏卡或工作站专业卡。
Fluent只有部分模型支持GPU运算,具体支持GPU运算的功能列表参考帮助文档,每个版本均有区别。Rocky所有模型均支持GPU运算。
英伟达近期的GPU如下表所示。

对于GPU运算,显存作用和内存相同。但是GPU由于显存无法自行扩展,因此需要优先考虑显存的限制性。
由于Fluent计算特性,建议所有问题均使用双精度计算。双精度相对单精度,显存需求量多50%。
对于纯多面体网格,若使用单精度计算,Fluent的显存用量预估:
- 两方程湍流模型(k-epsilon和k-omega),SIMPLE、PISO 速度-压力耦合格式,大约 1.4GB/百万单元
- 两方程湍流模型(k-epsilon和k-omega),COUPLED 速度-压力耦合格式,大约 3.4GB/百万单元
- 若开启传热、多相流等其他物理模型,则内存需求量更大
Rocky的显存用量预估:
- 非球形颗粒:3.2GB/百万颗粒
- 球形颗粒:2GB/百万颗粒
目前Fluent仅能支持AMD的部分显卡,Rocky未见支持AMD显卡的消息。
1.6 其他部件
电源搭配注意功率合理性与工作范围,适度保留冗余。功率不足或电压波动可能导致系统运行不稳定、死机等问题。
建议使用水冷散热,避免长时间高负载运行导致过热和硬件寿命缩减。
1.7 系统环境
及时对硬件驱动、主板BIOS、MPI组件、某些编译库等组件进行升级更新,以优化程序加速运算。
若出现蓝屏死机现象,需要及时根据DUMP文件中的记录定位问题发生根源。
2 测试数据
硬件性能常用的数据常用指标包括:MIUPS、加速倍率、并行效率。
MIUPS(million-cell iteration updates per second),通常用于CFD评估,数值越大越好。
加速倍率(speedup)指相对于基准硬件,测试硬件计算耗时缩短倍数。基准硬件计算耗时 A,加速倍率 N 的测试硬件计算耗时 A/N。
并行效率(parallel efficiency)定义为加速倍率/核心数。通常并行效率小于1,且核心数越多并行效率越低。并行效率等于1称为线性加速,大于1称为超线性加速。
AMD官方发布的CPU在不同CPU上的测试结果,横轴为各个测试模型,纵轴为两款AMD CPU相对于英特尔的CPU的加速倍率。从数据上来看,AMD的两款CPU均远快于英特尔的测试款。第五代EPYC相对于测试型号提升大约50%。
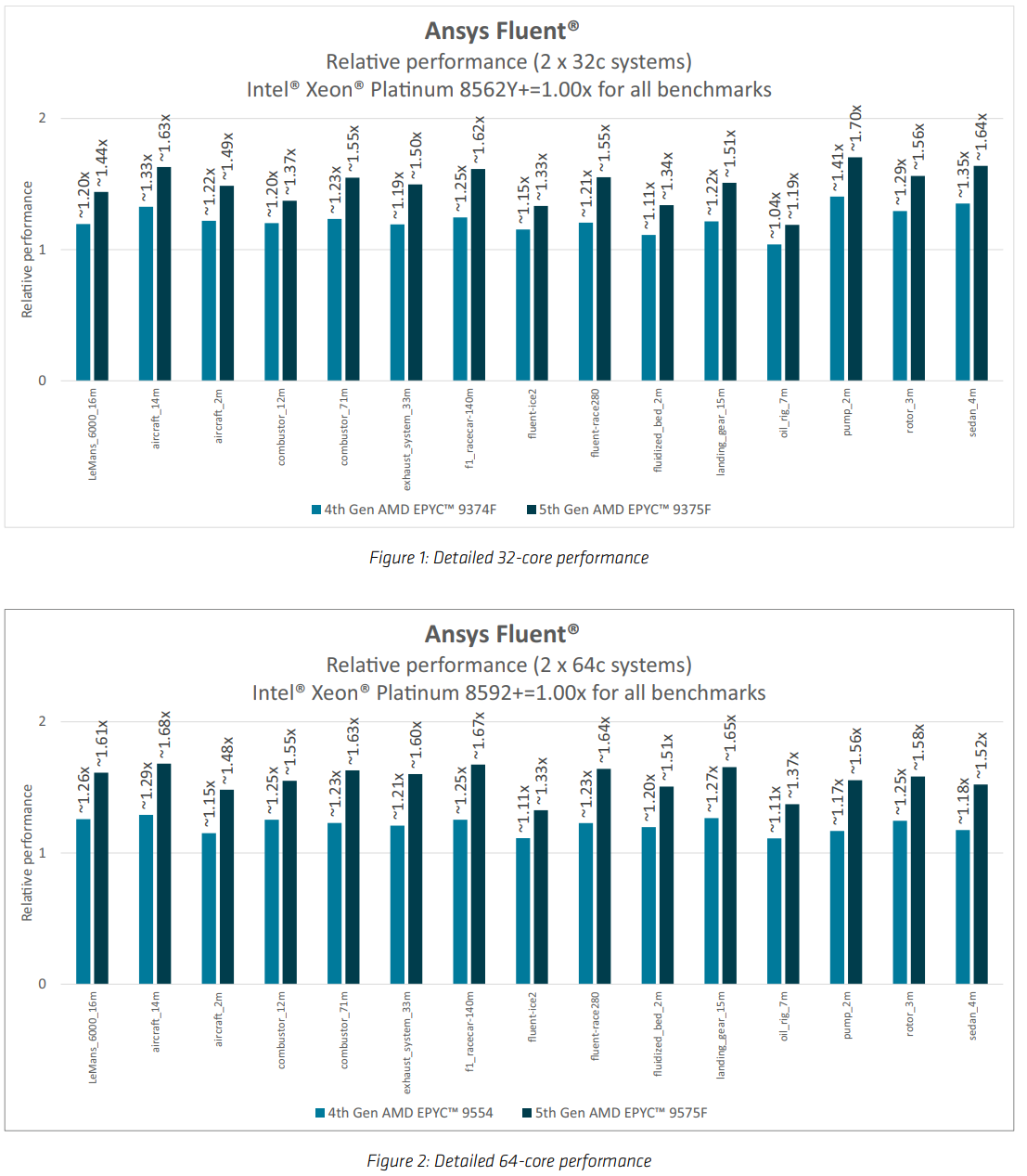
图源:https://www.amd.com/content/dam/amd/en/documents/epyc-technical-docs/performance-briefs/amd-epyc-9005-pb-ansys-fluent.pdf
ANSYS官方的模型测试数据,横轴为各款显卡,纵轴为显卡相对于CPU的加速倍率。从数据上来看,即使工作站专业卡相对CPU多核心都有较大提升。
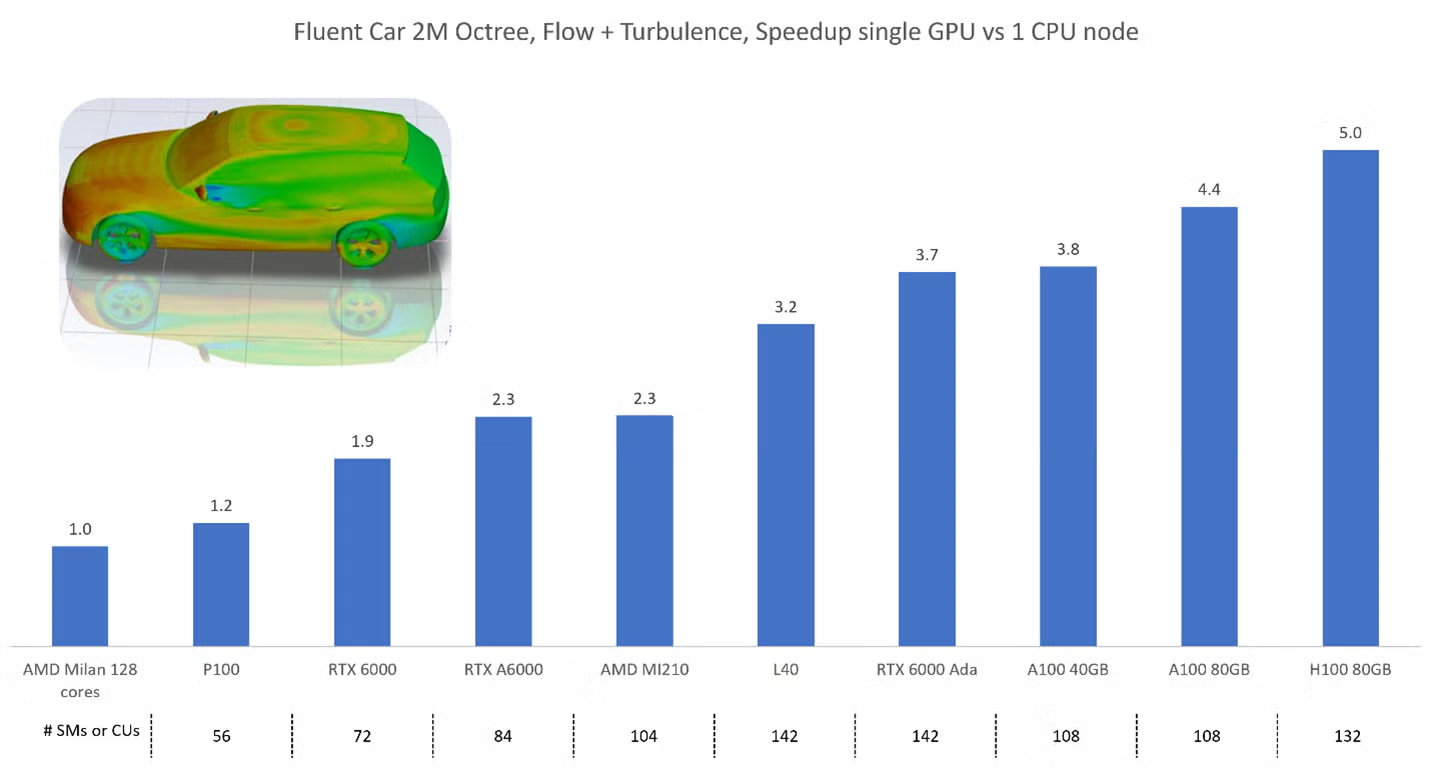
图源:https://innovationspace.ansys.com/knowledge/forums/topic/fluent-gpu-solver-faq/
CADFEM(欧洲区的ANSYS代理商)对某款阀门在不同硬件条件下的计算耗时统计。很明显,GPU运算速度远超过CPU。
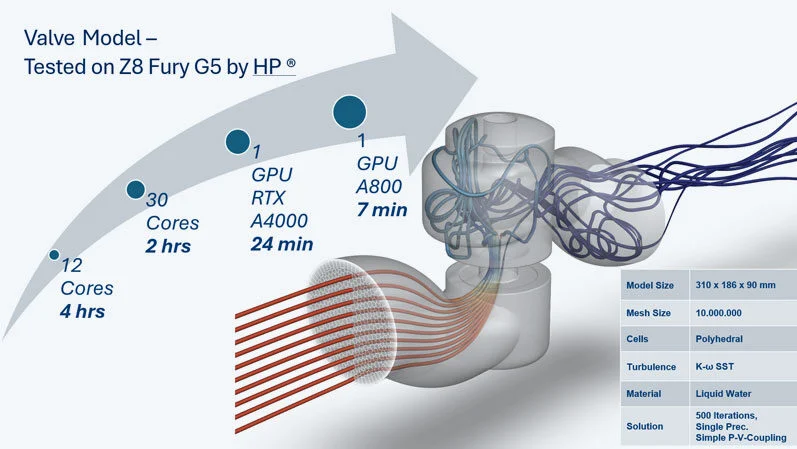
图源:https://blog.cadfem.net/en/ansys-fluent-gpu-performance-testing-use-case
贝克休斯(ANSYS客户)在超算上的模型测试数据,横轴为显卡数量,纵轴为显卡相对于CPU的加速倍率,GPU型号 AMD Instinct MI250X。从数据上来看,即使调用1024个GPU依旧可以保证近乎于线性加速。
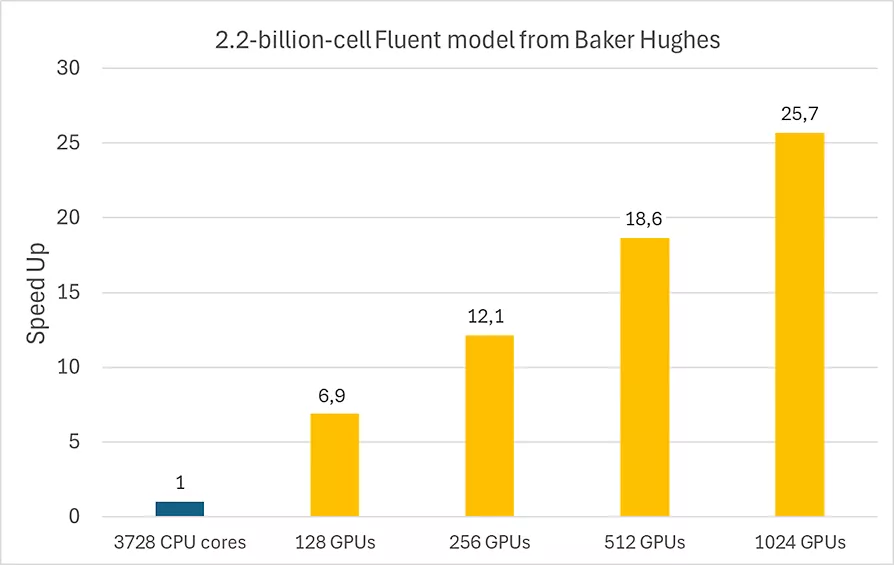
图源:https://www.ansys.com/blog/ansys-baker-hughes-groundbreaking-cfd-simulation
Mechanical和Fluent在不同内存频率的计算效率对比,横轴为各个测试模型,纵轴为内存频率 3200MHz 相对于 2933MHz 的加速倍率。从数据上来看,即内存频率的提升可以显著提升运算速度。
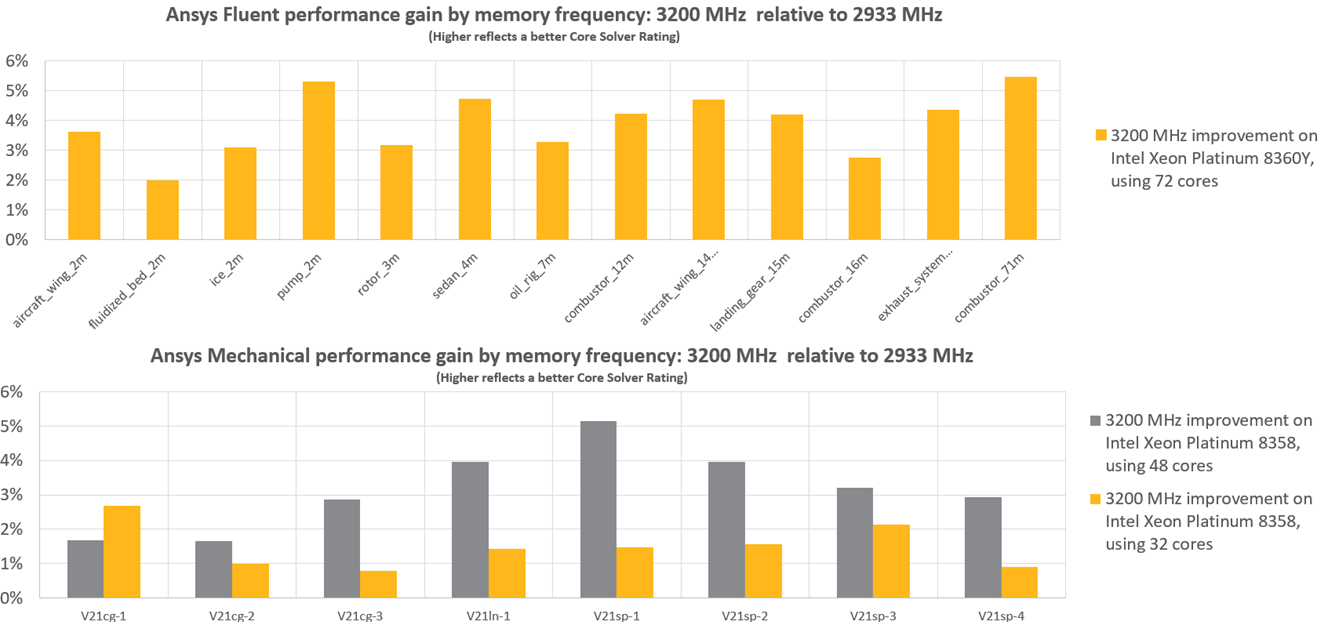
图源:ANSYS官方PPT《HPC Best Practices for Ansys Simulations》
是否安装AOCL(AMD Optimizing CPU Libraries)组件的计算效果对比,横轴为各个测试模型,纵轴为安装AOCL后的加速倍率。从数据上来看,安装AOCL可显著提升AMD CPU的运算速度。
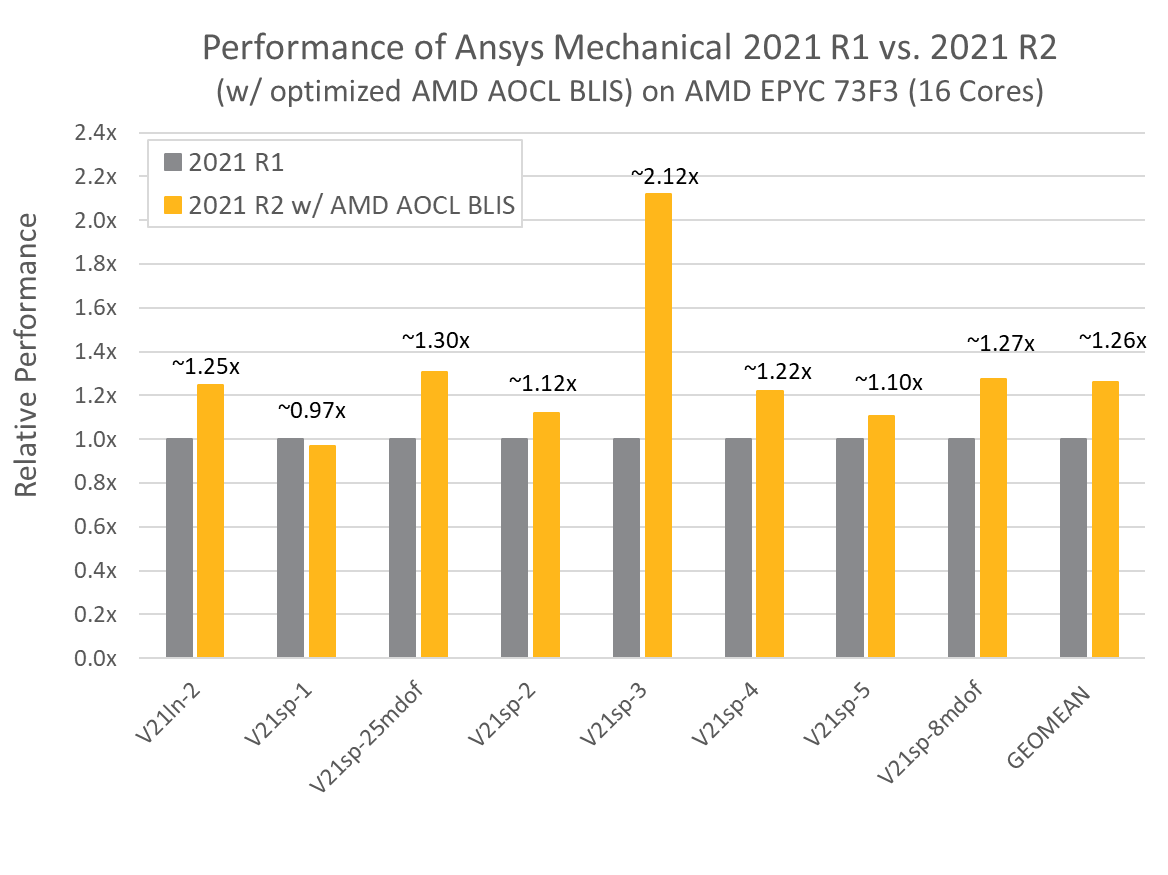
图源:ANSYS官方PPT《HPC Best Practices for Ansys Simulations》
3 注意事项
1 使用多核心CPU或者GPU加速,对于网格数量过低的模型意义不大。多核心CPU运算,建议平均每个核心不低于数千单元。使用GPU计算,建议模型单元数量不低于100万。
2 在Windows中提交计算,建议实际使用的核心数略少于CPU的物理核心数,否则可能因为系统读写、图形渲染等占用系统资源导致计算速度变慢。