Level DB --- 写流程架构
Level DB是高效的k-v数据库,接受多线程写,既要保证多线程写临界区安全,同时又要保证写流程的尽量高效性。
写入数据
Level DB 用一个deque用来衔接生产-消费模型。一个新的kv写入请求,会先将kv封装成Writer结构体。插入之前要先获得mutex,独占deque,从尾部插入*writer,插入后,随即信号量进入wait状态,等待被唤醒处理(这个时候线程状态被挂起)。
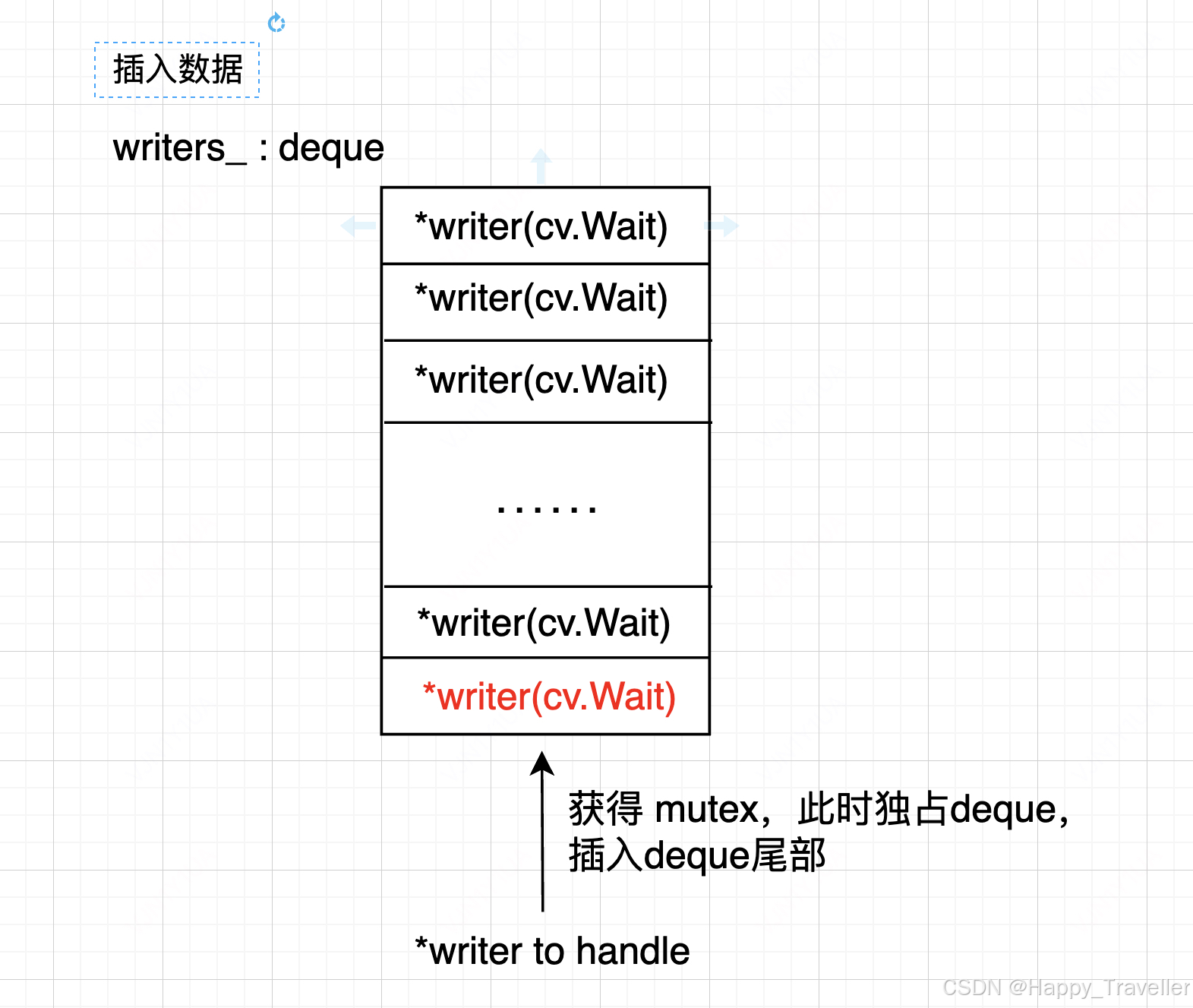
图1. 写入数据
数据处理
当进入数据处理流程中,这时deque 头部的*writer信号量被唤醒,这个时候获得mutex,并且独占deque。这个时候遍历deque,计算批量处理数据result,如图2所示。
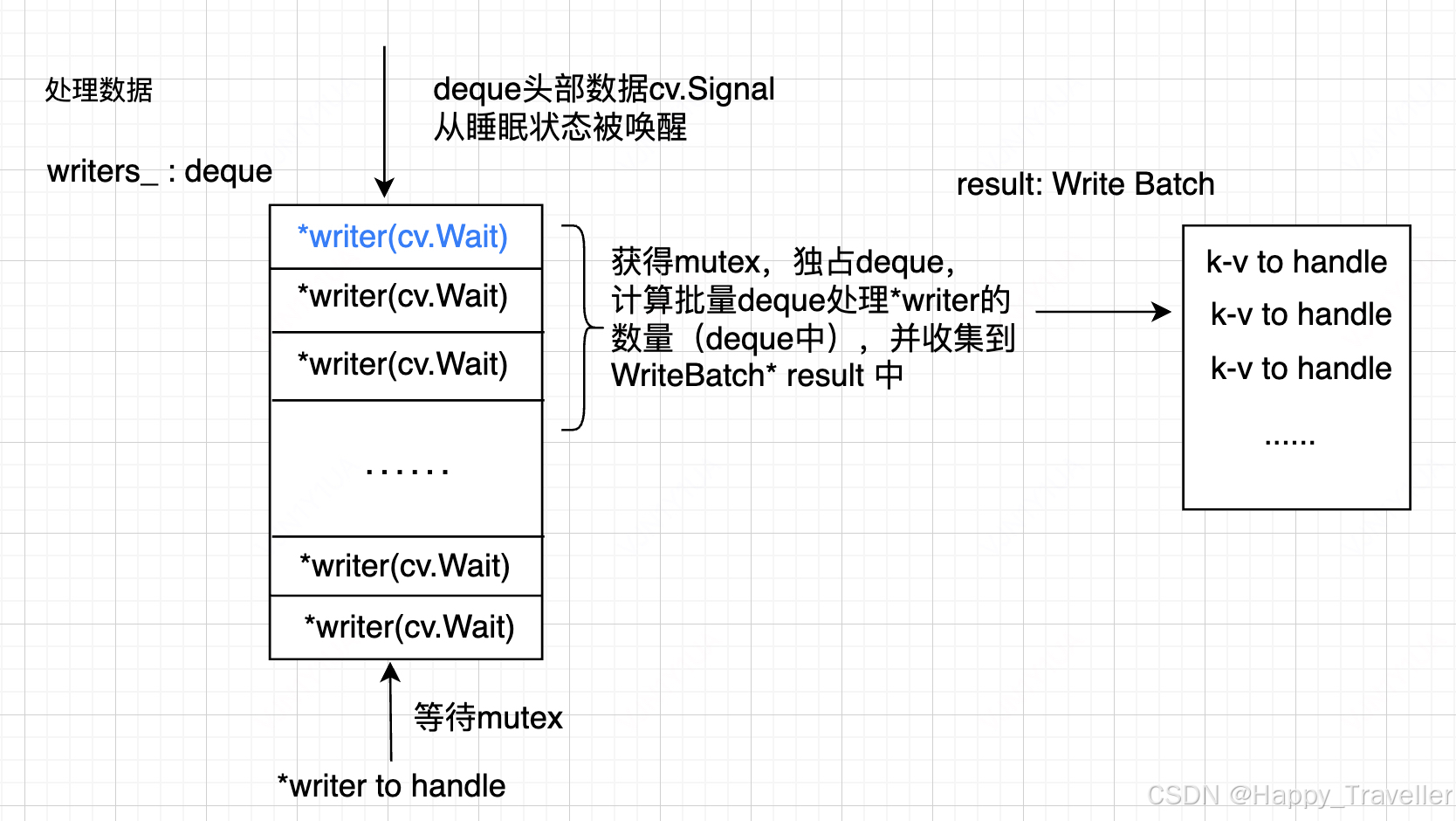
图2,准备批量处理
当待处理的数据量达到阈值,开始进行数据处理,并释放mutex。这个时候等待插入数据的线程又可以获得mutex,这个线程获得deque,可以再次插入数据。这个时候两边是并行的,提高系统的计算效率,如图3所示。
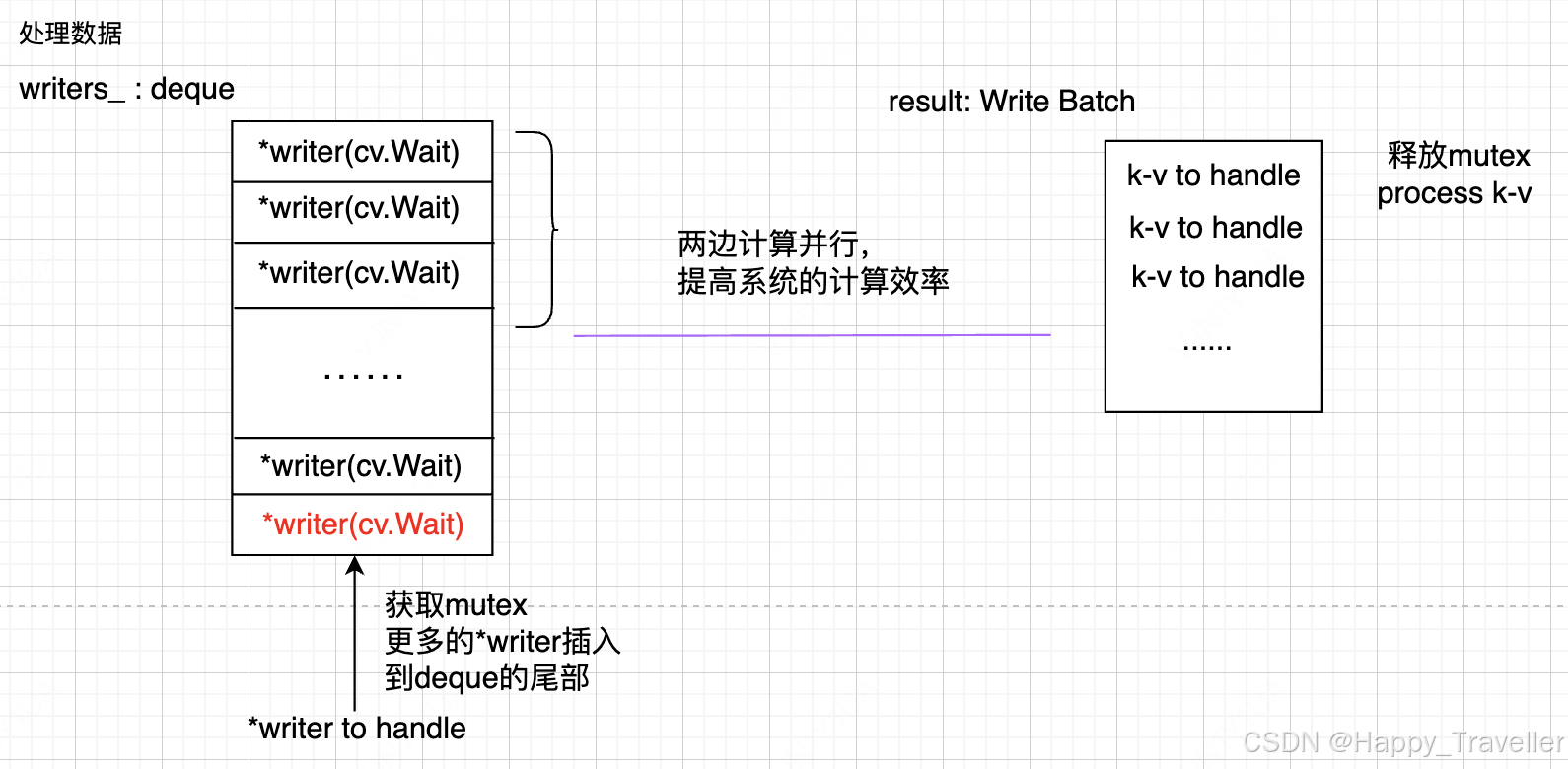
图3. 计算批量处理
计算完成批量处理后,释放已经在deque中处理好的kv对,如图4所示。
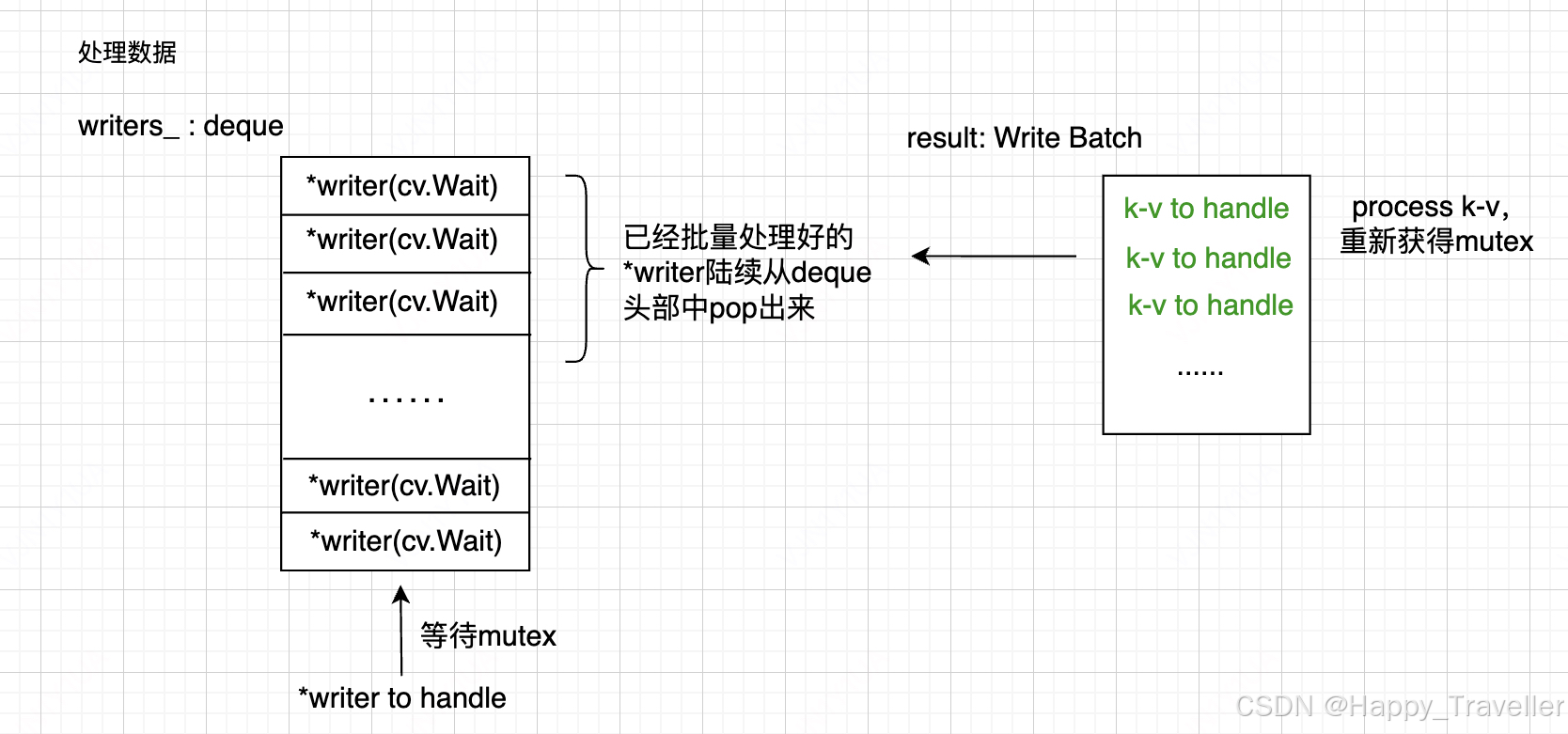
图4. 完成批量处理
上面的流程是持续反复的,不断进行用户端kv的写入。