【大模型】Ollama本地部署DeepSeek大模型:打造专属AI助手
【大模型】Ollama本地部署DeepSeek大模型:打造专属AI助手
- Ollama本地部署DeepSeek大模型:打造专属AI助手
- 一、Ollama简介
- 二、硬件需求
- 三、部署步骤
- 1. 下载并安装Ollama
- (1)访问Ollama官网
- (2)安装Ollama
- 2. 配置Ollama
- (1)检查安装是否成功
- (2)配置模型存储路径(可选)
- 3. 下载并运行DeepSeek模型
- (1)下载DeepSeek模型
- (2)运行模型
- 4. 使用可视化工具(可选)
- (1)下载并安装AnythingLLM
- (2)配置AnythingLLM
- 5. 验证部署是否成功
- 四、常见问题及解决方法
- 1. 显存不足
- 2. 网络问题
- 3. 配置文件问题
- 五、总结
Ollama本地部署DeepSeek大模型:打造专属AI助手
随着AI技术的飞速发展,大语言模型逐渐走进了我们的生活。DeepSeek作为一款备受关注的国产大模型,以其高性能和低资源消耗的特点脱颖而出。然而,由于访问量激增,DeepSeek的在线服务有时会出现响应缓慢甚至中断的情况。为了更好地利用DeepSeek,我们可以选择将其部署到本地,这样不仅可以提高响应速度,还能保护个人隐私。本文将详细介绍如何使用Ollama在本地部署DeepSeek大模型。
一、Ollama简介
Ollama是一个轻量级的本地AI模型运行框架,支持在Windows、Linux和MacOS上运行各种开源大语言模型。它提供了丰富的模型库,包括DeepSeek、Llama等1700+大语言模型。此外,Ollama还支持用户上传自己的模型,并允许通过编写配置文件来自定义模型的推理参数。
二、硬件需求
在开始部署之前,我们需要了解DeepSeek对硬件的要求。根据模型大小和显存需求,以下是推荐的硬件配置:
| 配置级别 | 内存 | 显卡 |
|---|---|---|
| 基础级 | 16GB | RTX 4060(8GB显存) |
| 中高级 | 32GB | RTX 4090(24GB显存) |
| 高级 | 64GB | RTX 5090 D(32GB显存) |
注意:如果显存不足,可以选择较小的模型版本,例如3B或7B版本,以避免显存溢出。
三、部署步骤
1. 下载并安装Ollama
(1)访问Ollama官网
打开Ollama官网:https://ollama.com/,选择适合你操作系统的安装包进行下载。
(2)安装Ollama
- Windows用户:下载完成后,双击安装包并按照提示完成安装。
- Linux用户:使用以下命令安装:
curl -fsSL https://ollama.com/install.sh | sh - MacOS用户:使用以下命令安装:
brew install ollama/tap/ollama
2. 配置Ollama
(1)检查安装是否成功
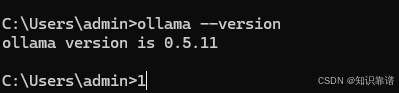
打开命令行工具(Windows用户可以按Win+R键,输入cmd并回车),输入以下命令:
ollama --version
如果安装成功,会显示Ollama的版本信息。
(2)配置模型存储路径(可选)
如果需要更改模型存储路径,可以在命令行中运行以下命令:
ollama config set model_path /path/to/your/model
将/path/to/your/model替换为你希望的路径。
3. 下载并运行DeepSeek模型
(1)下载DeepSeek模型
在命令行中输入以下命令来下载DeepSeek模型:
ollama pull deepseek-r1:7b
这里选择的是7B版本的模型,适合大多数家用电脑。
(2)运行模型
下载完成后,运行以下命令启动模型:
ollama run deepseek-r1:7b
此时,DeepSeek模型已经开始运行,你可以在命令行中与其进行交互。
4. 使用可视化工具(可选)
为了更方便地使用DeepSeek,我们可以安装一个可视化工具,如AnythingLLM。
(1)下载并安装AnythingLLM
访问https://anythingllm.com/,下载并安装适合你操作系统的版本。
(2)配置AnythingLLM
打开AnythingLLM,选择“LLM提供商”为Ollama,并设置模型为deepseek-r1:7b。新建工作区后,即可开始使用DeepSeek。

5. 验证部署是否成功
在命令行中输入以下命令,与DeepSeek模型进行交互:
ollama run deepseek-r1:7b
输入你的问题,例如:
你好,DeepSeek!
如果模型能够正常响应,说明部署成功。
四、常见问题及解决方法
1. 显存不足
如果显存不足,可以选择较小的模型版本,例如3B或7B版本。运行以下命令:
ollama pull deepseek-r1:3b
2. 网络问题
如果下载过程中出现网络中断,可以重新运行ollama pull命令,Ollama支持断点续传。
3. 配置文件问题
如果需要自定义模型参数,可以编辑ollama.json配置文件。例如:
{"model": "deepseek-r1:7b","temperature": 0.7,"max_tokens": 512
}
五、总结
通过以上步骤,我们可以在本地成功部署DeepSeek大模型,将其变成自己的私人AI助手。本地部署不仅提高了响应速度,还增强了隐私保护。希望这篇教程能帮助你更好地利用DeepSeek,提升工作和学习效率。
如果你在部署过程中遇到任何问题,欢迎在评论区留言,我会尽力为你解答。
作者简介:我是知识靠谱,一个热爱技术的程序员,专注于AI和大语言模型的研究。如果你喜欢这篇文章,别忘了点赞和关注哦!