RDMA驱动学习(三)- cq的创建
用户通过ibv_create_cq接口创建完成队列,函数原型和常见用法如下,本节以该用法为例看下cq的创建过程。
struct ibv_cq *ibv_create_cq(struct ibv_context *context, int cqe,void *cq_context,struct ibv_comp_channel *channel,int comp_vector);
cq = ibv_create_cq(ctx, ncqe, NULL, NULL, 0);
用户态
ncqe为cq队列的容量,cqe_sz是cqe的大小,默认64B;mlx5_alloc_cq_buf就是通过posix_memalign分配cq队列的内存,记录到cq->buf_a。
static struct ibv_cq_ex *create_cq(struct ibv_context *context,const struct ibv_cq_init_attr_ex *cq_attr,int cq_alloc_flags,struct mlx5dv_cq_init_attr *mlx5cq_attr)
{...ncqe = align_queue_size(cq_attr->cqe + 1);cqe_sz = get_cqe_size(mlx5cq_attr);mlx5_alloc_cq_buf(to_mctx(context), cq, &cq->buf_a, ncqe, cqe_sz);cq->dbrec = mlx5_alloc_dbrec(to_mctx(context), cq->parent_domain,&cq->custom_db);...
}
然后通过mlx5_alloc_dbrec分配dbr,dbr位于物理内存,大小为8B,同时对齐到8B,记录了软件poll到了什么位置,即ci,以及cq的状态信息,dbr地址会被记录到cqc中,当用户执行poll_cq之后会更新dbr,后续会具体介绍。
__be32 *mlx5_alloc_dbrec(struct mlx5_context *context, struct ibv_pd *pd,bool *custom_alloc)
{ struct mlx5_db_page *page;__be32 *db = NULL;int i, j;...
default_alloc:pthread_mutex_lock(&context->dbr_map_mutex);page = list_top(&context->dbr_available_pages, struct mlx5_db_page,available);if (page)goto found;page = __add_page(context);if (!page)goto out;found:...return db;
}分配dbr的时候首先尝试去空闲链表中获取,如果拿不到则执行__add_page,开始时空闲链表为空,因此执行__add_page。
static struct mlx5_db_page *__add_page(struct mlx5_context *context)
{ struct mlx5_db_page *page;int ps = to_mdev(context->ibv_ctx.context.device)->page_size;int pp;int i;int nlong;int ret;pp = ps / context->cache_line_size; nlong = (pp + 8 * sizeof(long) - 1) / (8 * sizeof(long));page = malloc(sizeof *page + nlong * sizeof(long));if (!page) return NULL;if (mlx5_is_extern_alloc(context))ret = mlx5_alloc_buf_extern(context, &page->buf, ps);elseret = mlx5_alloc_buf(&page->buf, ps, ps);if (ret) {free(page);return NULL;}page->num_db = pp;page->use_cnt = 0;for (i = 0; i < nlong; ++i)page->free[i] = ~0;cl_qmap_insert(&context->dbr_map, (uintptr_t) page->buf.buf,&page->cl_map);list_add(&context->dbr_available_pages, &page->available);return page;
}struct mlx5_db_page {cl_map_item_t cl_map;struct list_node available;struct mlx5_buf buf;int num_db;int use_cnt;unsigned long free[0];
}; ps为page size,mlx5一次性分配一个物理页用于存储多个dbr,用结构体mlx5_db_page page描述。通过mlx5_alloc_buf分配了大小为ps的内存,即一个物理页,地址记录到page中buf。这里为了防止false sharing,将dbr地址对齐到了cache_line_size,因此一个物理页能存储dbr的数量pp为page大小除以cacheline大小,pp记录到page的num_db,page中use_cnt初始化为0,表示这个page中还没有dbr被占用。page中free数组相当于一个bitmap,记录了这个page中dbr的空闲情况,nlong表示为了记录num_db个dbr需要几个long,即最少需要几个long才能有num_db个bit,free数组初始化为全1,表示所有dbr都为空闲。mlx通过树和链表的方式管理每一个mlx5_db_page,因此将page插入到dbr_available_pages链表head,链表节点为list_node available,将page插入到dbr_map,树节点为cl_map_item_t cl_map。
然后再回到mlx5_alloc_dbrec的逻辑
__be32 *mlx5_alloc_dbrec(struct mlx5_context *context, struct ibv_pd *pd,bool *custom_alloc)
{ ...++page->use_cnt;if (page->use_cnt == page->num_db)list_del(&page->available);for (i = 0; !page->free[i]; ++i)/* nothing */;j = ffsl(page->free[i]);--j;page->free[i] &= ~(1UL << j); db = page->buf.buf + (i * 8 * sizeof(long) + j) * context->cache_line_size;out:pthread_mutex_unlock(&context->dbr_map_mutex);return db;
}
首先增加use_cnt,表示又占用了一个dbr,如果use_cnt等于num_db,表示这个page已经满了,因此从空闲链表中删除。遍历free数组,找到第一个不为一的long,说明这个long里有空闲的dbr,然后通过ffsl找到free[i]中第一个为1的位置 j,然后将free[i]的第 j 位改为0,表示占用了,然后索引对应的dbr,因为一个long能存8 * sizeof(long)个dbr,因此这次分配的索引就是(i * 8 * sizeof(long) + j),最后将这个地址记录到db。
然后回到create_cq逻辑。
static struct ibv_cq_ex *create_cq(struct ibv_context *context,const struct ibv_cq_init_attr_ex *cq_attr,int cq_alloc_flags,struct mlx5dv_cq_init_attr *mlx5cq_attr)
{...cq->dbrec[MLX5_CQ_SET_CI] = 0; cq->dbrec[MLX5_CQ_ARM_DB] = 0; cq->arm_sn = 0; cq->cqe_sz = cqe_sz;cq->flags = cq_alloc_flags;cmd_drv->buf_addr = (uintptr_t) cq->buf_a.buf;cmd_drv->db_addr = (uintptr_t) cq->dbrec;cmd_drv->cqe_size = cqe_sz;{struct ibv_cq_init_attr_ex cq_attr_ex = *cq_attr;cq_attr_ex.cqe = ncqe - 1;ret = ibv_cmd_create_cq_ex(context, &cq_attr_ex, &cq->verbs_cq,&cmd_ex.ibv_cmd, sizeof(cmd_ex),&resp_ex.ibv_resp, sizeof(resp_ex),CREATE_CQ_CMD_FLAGS_TS_IGNORED_EX);}...
}
初始化dbrec和cq,然后将buf地址,dbrec地址,cqe_sz记录到cmd_drv,然后执行ibv_cmd_create_cq_ex,进入到了内核态。
内核态
dma映射
int mlx5_ib_create_cq(struct ib_cq *ibcq, const struct ib_cq_init_attr *attr,struct ib_udata *udata)
{if (udata) {err = create_cq_user(dev, udata, cq, entries, &cqb, &cqe_size,&index, &inlen);...}
}
进入内核态后执行mlx5_ib_create_cq,由于是用户态的create_cq,因此执行create_cq_user,cqb类型为mlx5_ifc_create_cq_in_bits,即第二章中介绍的create_cq的cmd,会在create_cq_user创建。
static int create_cq_user(struct mlx5_ib_dev *dev, struct ib_udata *udata,struct mlx5_ib_cq *cq, int entries, u32 **cqb,int *cqe_size, int *index, int *inlen)
{struct mlx5_ib_create_cq ucmd = {};*cqe_size = ucmd.cqe_size;cq->buf.umem = ib_umem_get_peer(udata, ucmd.buf_addr,entries * ucmd.cqe_size,IB_ACCESS_LOCAL_WRITE, 0);...
}
entries为cq容量,cqe_size为cqe大小,然后执行ib_umem_get_peer,因为用户态中的buf_addr或者dbr的地址均为虚拟地址,用户态软件使用虚拟地址访问cq,但是硬件需要使用总线地址访问cq,所以ib_umem_get_peer作用就是将虚拟地址连续的addr转为总线地址。
struct ib_umem *ib_umem_get_peer(struct ib_udata *udata, unsigned long addr, size_t size, int access, unsigned long peer_mem_flags)
{return __ib_umem_get(udata, addr, size, access, IB_PEER_MEM_ALLOW | peer_mem_flags);
}
首先分配ib_umem umem,相关信息都会记录到umem里。
struct ib_umem *__ib_umem_get(struct ib_udata *udata,unsigned long addr, size_t size, int access,unsigned long peer_mem_flags)
{struct ib_umem *umem;struct page **page_list;unsigned long dma_attr = 0;struct mm_struct *mm;unsigned long npages;int ret;struct scatterlist *sg = NULL;unsigned int gup_flags = FOLL_WRITE;unsigned long dma_attrs = 0;...umem = kzalloc(sizeof(*umem), GFP_KERNEL);if (!umem)return ERR_PTR(-ENOMEM);umem->context = context;umem->length = size;umem->address = addr;...
}
然后分配page_list,page_list用于保存接下来通过get_user_pages返回的物理页,ib_umem_num_pages计算得到npages,表示这段内存一共占用了多少个物理页。然后创建sg_table,用于保存离散的物理页集合,sg被赋值为sg_table的scatterlist sgl。
{page_list = (struct page **) __get_free_page(GFP_KERNEL);if (!page_list) {ret = -ENOMEM;goto umem_kfree;}npages = ib_umem_num_pages(umem);...cur_base = addr & PAGE_MASK;ret = sg_alloc_table(&umem->sg_head, npages, GFP_KERNEL);sg = umem->sg_head.sgl;...
}
接下来开始通过get_user_pages获取入参addr这个虚拟地址对应的物理页集合,get_user_pages通过每个页的虚拟地址找vma,找到之后通过follow_page_mask获取对应的物理页,如果没有分配物理页就分配,并且pin住保证不会交换,因为page_list大小为一个物理页,所以这里一次性最多传进去的page数为PAGE_SIZE / sizeof (struct page *)。
{while (npages) {cond_resched();down_read(&mm->mmap_sem);ret = get_user_pages_longterm(cur_base,min_t(unsigned long, npages,PAGE_SIZE / sizeof (struct page *)),gup_flags, page_list, NULL);if (ret < 0) {pr_debug("%s: failed to get user pages, nr_pages=%lu, flags=%u\n", __func__,min_t(unsigned long, npages,PAGE_SIZE / sizeof(struct page *)),gup_flags);up_read(&mm->mmap_sem);goto umem_release;}cur_base += ret * PAGE_SIZE;npages -= ret;sg = ib_umem_add_sg_table(sg, page_list, ret,dma_get_max_seg_size(context->device->dma_device),&umem->sg_nents);up_read(&mm->mmap_sem);}}
然后开始将返回的ret个物理页通过ib_umem_add_sg_table加入到sg_table中,因为第一次调用的时候sg里还没有保存page,所以可以通过sg_page判断是否是第一次调用。对于非第一次的调用这里会尝试合并本次操作的page到当前的sg里,通过page_to_pfn(sg_page(sg))可以拿到当前sg里物理页的pfn,然后加上sg的物理页数就得到了sg保存的连续物理页后的第一个物理页的pfn,如果和page_list[0]的pfn相等,说明是连续的,可以合并,通过设置update_cur_sg表示可以将page_list合并到当前sg。
static struct scatterlist *ib_umem_add_sg_table(struct scatterlist *sg,struct page **page_list,unsigned long npages,unsigned int max_seg_sz,int *nents)
{unsigned long first_pfn;unsigned long i = 0;bool update_cur_sg = false;bool first = !sg_page(sg);if (!first && (page_to_pfn(sg_page(sg)) + (sg->length >> PAGE_SHIFT) ==page_to_pfn(page_list[0])))update_cur_sg = true;...
}
然后开始循环添加page_list的页面到sg_table,拿到这次循环要处理的第一个page即first_page和他的pfn即first_pfn,然后从i往后看接下来有多少个物理页是连续的,len表示连续的page数量,如果可以合并到当前sg,那么直接更新sg的长度信息,然后continue。如果不能合并且不是第一次执行,那么就需要通过sg_next切换到下一个sg并更新,最后返回当前处理的sg。
static struct scatterlist *ib_umem_add_sg_table(struct scatterlist *sg,struct page **page_list,unsigned long npages,unsigned int max_seg_sz,int *nents)
{while (i != npages) {unsigned long len;struct page *first_page = page_list[i];first_pfn = page_to_pfn(first_page); */for (len = 0; i != npages &&first_pfn + len == page_to_pfn(page_list[i]) &&len < (max_seg_sz >> PAGE_SHIFT);len++)i++;/* Squash N contiguous pages from page_list into current sge */if (update_cur_sg) {if ((max_seg_sz - sg->length) >= (len << PAGE_SHIFT)) {sg_set_page(sg, sg_page(sg),sg->length + (len << PAGE_SHIFT),0);update_cur_sg = false;continue;}update_cur_sg = false;}/* Squash N contiguous pages into next sge or first sge */if (!first)sg = sg_next(sg);(*nents)++;sg_set_page(sg, first_page, len << PAGE_SHIFT, 0);first = false;}return sg;
}
最后通过sg_mark_end标记当前sg为最后一个sg,如果access属性有IB_ACCESS_RELAXED_ORDERING,那么dma_attr需要设置上DMA_ATTR_WEAK_ORDERING,表示读写可以乱序。最后通过ib_dma_map_sg_attrs将sg_table的物理页执行dma映射,实际用的就是dma_map_sg_attrs。
struct ib_umem *__ib_umem_get(struct ib_udata *udata,unsigned long addr, size_t size, int access,unsigned long peer_mem_flags)
{...sg_mark_end(sg);if (access & IB_ACCESS_RELAXED_ORDERING)dma_attr |= DMA_ATTR_WEAK_ORDERING;umem->nmap = ib_dma_map_sg_attrs(context->device,umem->sg_head.sgl,umem->sg_nents,DMA_BIDIRECTIONAL, dma_attrs); ...
}
这里就完成了对cq buf的dma映射,回到create_cq_user的逻辑:
page_size = mlx5_umem_find_best_cq_quantized_pgoff(cq->buf.umem, cqc, log_page_size, MLX5_ADAPTER_PAGE_SHIFT,page_offset, 64, &page_offset_quantized);if (!page_size) {err = -EINVAL;goto err_umem;} err = mlx5_ib_db_map_user(context, udata, ucmd.db_addr, &cq->db);if (err)goto err_umem;ncont = ib_umem_num_dma_blocks(cq->buf.umem, page_size);网卡支持多种大小的页大小,mlx5_umem_find_best_cq_quantized_pgoff就是计算出最合适的页大小,返回给pag_size,page_offset_quantized为buffer首地址相对于页的偏移,假设这里返回的还是4K,ib_umem_num_dma_blocks计算cq buff一共占用了多少个物理页。
然后执行mlx5_ib_db_map_user完成对dbr的dma映射。
int mlx5_ib_db_map_user(struct mlx5_ib_ucontext *context,struct ib_udata *udata, unsigned long virt,struct mlx5_db *db)
{ struct mlx5_ib_user_db_page *page;int err = 0;mutex_lock(&context->db_page_mutex);list_for_each_entry(page, &context->db_page_list, list)if ((current->mm == page->mm) &&(page->user_virt == (virt & PAGE_MASK)))goto found;page = kmalloc(sizeof(*page), GFP_KERNEL);if (!page) {err = -ENOMEM;goto out;}page->user_virt = (virt & PAGE_MASK);page->refcnt = 0;page->umem =ib_umem_get_peer(udata, virt & PAGE_MASK,PAGE_SIZE, 0, 0);if (IS_ERR(page->umem)) {err = PTR_ERR(page->umem);kfree(page);goto out;}mmgrab(current->mm);page->mm = current->mm;list_add(&page->list, &context->db_page_list);found:db->dma = sg_dma_address(page->umem->sg_head.sgl) + (virt & ~PAGE_MASK);db->u.user_page = page;++page->refcnt;out:mutex_unlock(&context->db_page_mutex);return err;
}用户态分配dbr的时候会一次性分配一个page以容纳多个dbr,因此这里核心逻辑就是判断当前dbr所在的页是否已经执行过dma映射,执行过dma映射的页会保存在db_page_list链表中,所以这里先遍历链表里所有的mlx5_ib_user_db_page,如果发现和当前要映射的page是同一个进程,并且虚拟地址相等,就说明已经映射过,那直接通过umem中的sg_table拿到首地址加上偏移就得到了dma地址;如果没有找到,说明是第一次映射,将ib_umem_get_peer完成映射,将信息保存到page的umem,然后将当前page加入到db_page_list。
cmd初始化
然后开始初始化mailbox机制中的输入,即mlx5_ifc_create_cq_in_bits,如下所示,其中cq context entry即cqc,pas为cq buff对应的物理页集合。
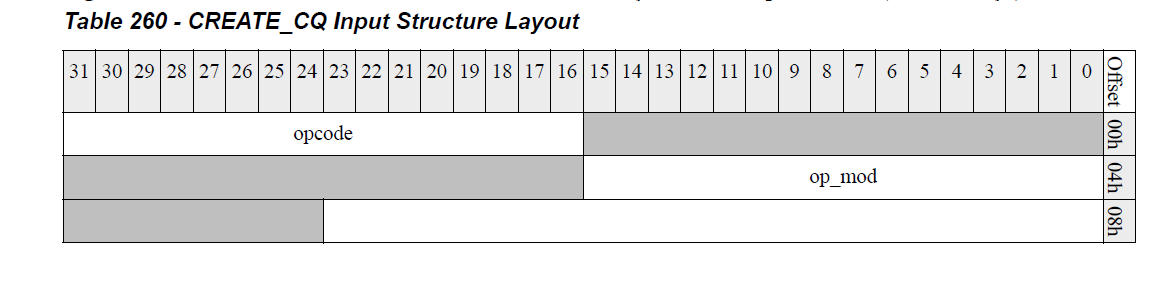

void mlx5_ib_populate_pas(struct ib_umem *umem, size_t page_size, __be64 *pas,u64 access_flags)
{struct ib_block_iter biter;rdma_umem_for_each_dma_block (umem, &biter, page_size) {*pas = cpu_to_be64(rdma_block_iter_dma_address(&biter) |access_flags);pas++;}
}
然后执行mlx5_ib_populate_pas,这里会将sg_table记录的物理内存即cq buff按照page_size大小记录到pas数组。
首先创建一个ib_block_iter,初始化设置__sg为scatterlist,__sg_nents 为nents,即sg_table里的成员个数。
#define rdma_umem_for_each_dma_block(umem, biter, pgsz) \for (__rdma_umem_block_iter_start(biter, umem, pgsz); \__rdma_block_iter_next(biter);)static inline void __rdma_umem_block_iter_start(struct ib_block_iter *biter,struct ib_umem *umem,unsigned long pgsz)
{__rdma_block_iter_start(biter, umem->sg_head.sgl, umem->nmap, pgsz);
}void __rdma_block_iter_start(struct ib_block_iter *biter,struct scatterlist *sglist, unsigned int nents,unsigned long pgsz)
{memset(biter, 0, sizeof(struct ib_block_iter));biter->__sg = sglist;biter->__sg_nents = nents;/* Driver provides best block size to use */biter->__pg_bit = __fls(pgsz);
}struct ib_block_iter {/* internal states */struct scatterlist *__sg; /* sg holding the current aligned block */dma_addr_t __dma_addr; /* unaligned DMA address of this block */unsigned int __sg_nents; /* number of SG entries */unsigned int __sg_advance; /* number of bytes to advance in sg in next step */unsigned int __pg_bit; /* alignment of current block */
};
然后通过__rdma_block_iter_next遍历sg_table,biter的dma_addr设置为当前scatterlist的dma地址,__sg_advance表示在当前entry中的偏移,第一次为0,所以biter第一次的__dma_addr就是第一个entry的dma地址,将dma地址记录到pas第一项,然后开始移动到下一个物理页,即将__sg_advance加上物理页大小,如果__sg_advance大于当前entry对应的物理内存长度,那么通过sg_next移动到scatterlist的下一个entry,直到遍历完成所有entry,就将所有物理页记录到了pas。
bool __rdma_block_iter_next(struct ib_block_iter *biter)
{unsigned int block_offset;if (!biter->__sg_nents || !biter->__sg)return false;biter->__dma_addr = sg_dma_address(biter->__sg) + biter->__sg_advance;block_offset = biter->__dma_addr & (BIT_ULL(biter->__pg_bit) - 1);biter->__sg_advance += BIT_ULL(biter->__pg_bit) - block_offset;if (biter->__sg_advance >= sg_dma_len(biter->__sg)) {biter->__sg_advance = 0;biter->__sg = sg_next(biter->__sg);biter->__sg_nents--;}return true;
}
static int create_cq_user(struct mlx5_ib_dev *dev, struct ib_udata *udata,struct mlx5_ib_cq *cq, int entries, u32 **cqb,int *cqe_size, int *index, int *inlen)
{...cqc = MLX5_ADDR_OF(create_cq_in, *cqb, cq_context);MLX5_SET(cqc, cqc, log_page_size,order_base_2(page_size) - MLX5_ADAPTER_PAGE_SHIFT);MLX5_SET(cqc, cqc, page_offset, page_offset_quantized);...
}
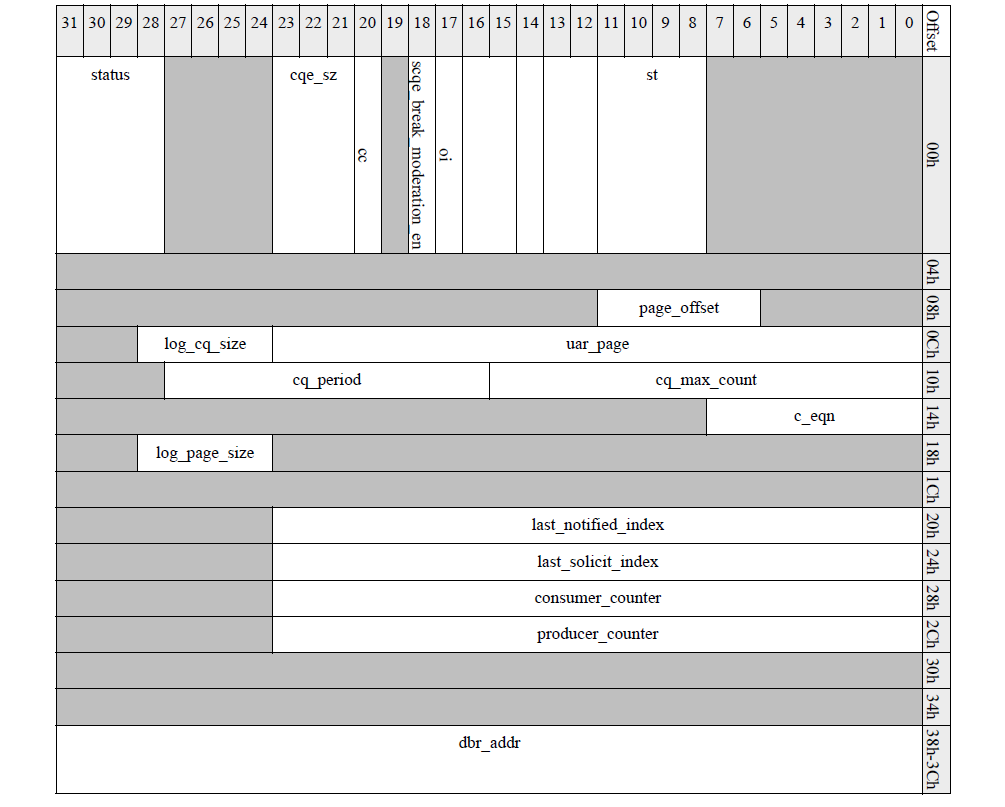
然后开始设置mlx5_ifc_create_cq_in_bits的cqc,cqc的格式如下所示,log_page_size表示以log表示的物理页大小;page_offset表示cq buff首地址相对物理页的偏移,对于cq这个值必须为0。
cmd执行
然后回到create_cq的逻辑
int mlx5_ib_create_cq(struct ib_cq *ibcq, const struct ib_cq_init_attr *attr,struct ib_udata *udata)
{...cqc = MLX5_ADDR_OF(create_cq_in, cqb, cq_context);MLX5_SET(cqc, cqc, cqe_sz,cqe_sz_to_mlx_sz(cqe_size,cq->private_flags &MLX5_IB_CQ_PR_FLAGS_CQE_128_PAD));MLX5_SET(cqc, cqc, log_cq_size, ilog2(entries));MLX5_SET(cqc, cqc, uar_page, index);MLX5_SET(cqc, cqc, c_eqn_or_apu_element, eqn);MLX5_SET64(cqc, cqc, dbr_addr, cq->db.dma);if (cq->create_flags & IB_UVERBS_CQ_FLAGS_IGNORE_OVERRUN)MLX5_SET(cqc, cqc, oi, 1);err = mlx5_core_create_cq(dev->mdev, &cq->mcq, cqb, inlen, out, sizeof(out));...
}
设置好cqc之后执行mlx5_core_create_cq,会执行到mlx5_create_cq
int mlx5_create_cq(struct mlx5_core_dev *dev, struct mlx5_core_cq *cq,u32 *in, int inlen, u32 *out, int outlen)
{int eqn = MLX5_GET(cqc, MLX5_ADDR_OF(create_cq_in, in, cq_context),c_eqn_or_apu_element);u32 din[MLX5_ST_SZ_DW(destroy_cq_in)] = {};struct mlx5_eq_comp *eq;int err;eq = mlx5_eqn2comp_eq(dev, eqn);if (IS_ERR(eq))return PTR_ERR(eq);memset(out, 0, outlen);MLX5_SET(create_cq_in, in, opcode, MLX5_CMD_OP_CREATE_CQ);err = mlx5_cmd_do(dev, in, inlen, out, outlen);if (err)return err;cq->cqn = MLX5_GET(create_cq_out, out, cqn);cq->cons_index = 0;cq->arm_sn = 0;cq->eq = eq; cq->uid = MLX5_GET(create_cq_in, in, uid);refcount_set(&cq->refcount, 1); init_completion(&cq->free);...
}
就是执行mlx5_cmd_do,通过第二章介绍的mailbox机制将cmd下发给硬件执行,执行完成后将结果通过out返回,得到cqn记录到cq,到这里cq的创建就完成了。