【自学笔记】神经网络(1)
文章目录
- 介绍
- 模型结构
- 层(Layer)
- 神经元
- 前向传播
- 反向传播
- Q1: 为什么要用向量
- Q2: 不用激活函数会发生什么
介绍
我们已经学习了简单的分类任务和回归任务,也认识了逻辑回归和正则化等技巧,已经可以搭建一个简单的神经网络模型了。
神经网络模仿人类神经元,进行运算、激活、传递等一系列行为,最终得到结果。这些将在之后详细讲述
模型结构
层(Layer)
一个完整的神经网络由许多层(layer)组成,除了输入层和输出层,中间的层被统称为隐藏层(Hidden Layers),具体根据功能不同有不同的名字。
神经元
一个层由许多神经元组成,一层中神经元的数量称为这一层的宽度。
比如,样本特征有“桌子的长 a a a”和“桌子的宽 b b b”,标签为"桌子的面积 s s s",则我们可以画出这样的图(举个例子):

每一个神经元要做的最基本的事情,就是获取上一个神经元的输入,经过计算,给出一个信号给下一个神经元。
前向传播
前向传播就是接收输入后,经过一系列神经元的计算,再输出的整个过程。最简单的,我们设每个神经元使用最简单的线性回归模型:
输入向量 x ( i ) x^{(i)} x(i)
f j ( i ) ( x ( i ) ) = w j ( i ) ⋅ x ( i ) + b j ( i ) f^{(i)}_{j}(x^{(i)}) = w^{(i)}_{j} \cdot x^{(i)} + b^{(i)}_{j} fj(i)(x(i))=wj(i)⋅x(i)+bj(i)
这里 w j ( i ) w^{(i)}_{j} wj(i)和 b j ( i ) b^{(i)}_{j} bj(i)都是神经元上附带的参数, i i i是层的编号, j j j是神经元的编号
通常计算出 f f f后,得到的结果会再经过一个激活函数 g g g,来实现非线性的拟合,我们以 S i g m o i d Sigmoid Sigmoid函数为例:
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1+e^{-z}} g(z)=1+e−z1
回顾一下 S i g m o i d Sigmoid Sigmoid函数的性质:
g ′ ( z ) = g ( z ) ∗ [ 1 − g ( z ) ] g'(z) = g(z) * [1-g(z)] g′(z)=g(z)∗[1−g(z)]
然后这一层得到的结果作为输入进入下一层:
x ( i + 1 ) = [ g ( f 1 ( i ) ( x ( i ) ) ) g ( f 2 ( i ) ( x ( i ) ) ) . . . g ( f k i ( i ) ( x ( i ) ) ) ] x^{(i+1)}=\begin{bmatrix}g(f^{(i)}_{1}(x^{(i)}))\\g(f^{(i)}_{2}(x^{(i)}))\\...\\g(f^{(i)}_{k_{i}}(x^{(i)}))\end{bmatrix} x(i+1)= g(f1(i)(x(i)))g(f2(i)(x(i)))...g(fki(i)(x(i)))
除了Sigmoid函数,Relu函数也经常被使用:
g ( z ) = { z i f z ≥ 0 , 0 i f z < 0 = m a x ( 0 , z ) g(z)=\begin{cases}z \ \ if \ z \ge 0, \\0 \ \ if \ z < 0 \end{cases} = max(0, z) g(z)={z if z≥0,0 if z<0=max(0,z)

由于它的导数非常简单,可以加速收敛;更重要的是它可以避免梯度消失问题,这个之后再讲。
在最后的输出层时,我们通常使用另一个激活函数 S o f t m a x Softmax Softmax
S o f t m a x : x = [ x 1 , x 2 , . . . , x k ] → y = [ y 1 , y 2 , . . . , y k ] Softmax: x = [x_{1}, x_{2}, ..., x_{k}] \to y = [y_{1}, y_{2}, ..., y_{k}] Softmax:x=[x1,x2,...,xk]→y=[y1,y2,...,yk]
s u c h t h a t y i = x i ∑ j = 1 k x j such \ that \ y_{i}=\frac{x_{i}}{\sum_{j=1}^{k}x_{j}} such that yi=∑j=1kxjxi
即按比例将结果转化为概率的形式,且总和为 1 1 1
因此得到的 y i y_{i} yi有时也会写为 P ( y = i ∣ x ) P(y=i | x) P(y=i∣x)
反向传播
在训练模型过程中,我们会将样本集丢进初始化的模型中,得到预测值,通过预测值与标签(真实值)的差异来调整模型;在神经网络中也是如此。我们这里采用梯度下降的方式,且假定损失函数为均方误差,前向传播的过程如下:
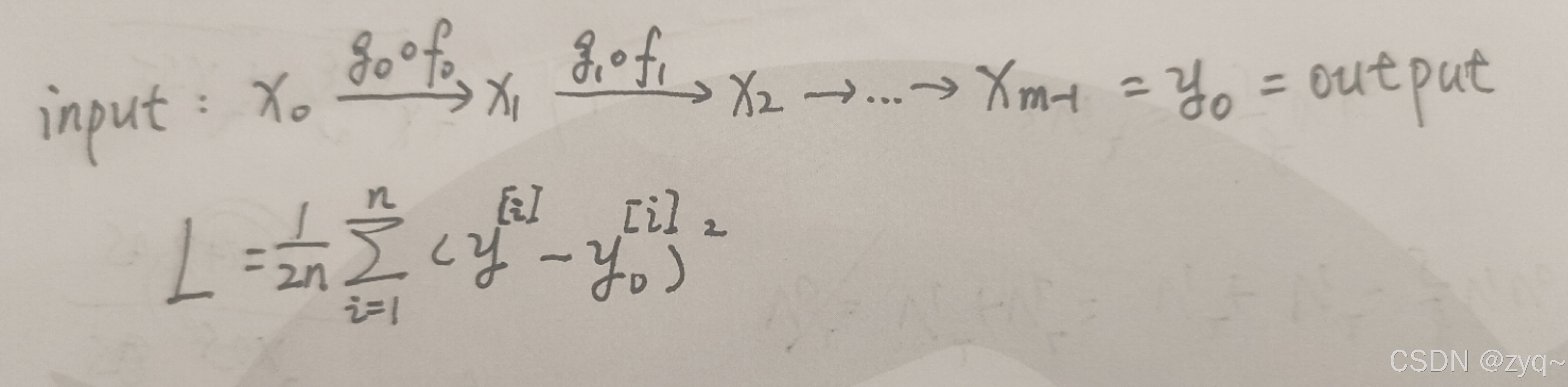
于是,根据梯度下降,有:
w j ( i ) = w j ( i ) − α δ L δ w j ( i ) w^{(i)}_{j} = w^{(i)}_{j} - \alpha \frac{\delta L}{\delta w^{(i)}_{j}} wj(i)=wj(i)−αδwj(i)δL
b j ( i ) = w j ( i ) − α δ L δ b j ( i ) b^{(i)}_{j} = w^{(i)}_{j} - \alpha \frac{\delta L}{\delta b^{(i)}_{j}} bj(i)=wj(i)−αδbj(i)δL
其中 α \alpha α为学习率, δ \delta δ是偏导,回顾一下每个神经元的运算:
z j ( i ) = f j ( i ) ( x ( i ) ) = w j ( i ) ⋅ x ( i ) + b j ( i ) z^{(i)}_{j} = f^{(i)}_{j}(x^{(i)}) = w^{(i)}_{j} \cdot x^{(i)} + b^{(i)}_{j} zj(i)=fj(i)(x(i))=wj(i)⋅x(i)+bj(i)
x j ( i + 1 ) = g ( z j ( i ) ) x^{(i+1)}_{j} = g(z^{(i)}_{j}) xj(i+1)=g(zj(i)),其中假设每个神经元用的都是g为 s i g m o i d sigmoid sigmoid函数,不作区分
应用链式法则:
δ L δ w j ( i ) = δ L δ x j ( i + 1 ) ∗ δ x j ( i + 1 ) δ z j ( i ) ∗ δ z j ( i ) δ w j ( i ) \frac{\delta L}{\delta w^{(i)}_{j}}=\frac{\delta L}{\delta x^{(i+1)}_{j}}*\frac{\delta x^{(i+1)}_{j}}{\delta z^{(i)}_{j}}*\frac{\delta z^{(i)}_{j}}{\delta w^{(i)}_{j}} δwj(i)δL=δxj(i+1)δL∗δzj(i)δxj(i+1)∗δwj(i)δzj(i)
= δ L δ x j ( i + 1 ) ∗ x j ( i + 1 ) ∗ ( 1 − x j ( i + 1 ) ) ∗ x j ( i ) \ \ \ \ \ \ \ \ \ =\frac{\delta L}{\delta x^{(i+1)}_{j}}*x^{(i+1)}_{j}*(1-x^{(i+1)}_{j})*x^{(i)}_{j} =δxj(i+1)δL∗xj(i+1)∗(1−xj(i+1))∗xj(i)
δ L δ b j ( i ) = δ L δ x j ( i + 1 ) ∗ δ x j ( i + 1 ) δ z j ( i ) ∗ δ z j ( i ) δ b j ( i ) \frac{\delta L}{\delta b^{(i)}_{j}}=\frac{\delta L}{\delta x^{(i+1)}_{j}}*\frac{\delta x^{(i+1)}_{j}}{\delta z^{(i)}_{j}}*\frac{\delta z^{(i)}_{j}}{\delta b^{(i)}_{j}} δbj(i)δL=δxj(i+1)δL∗δzj(i)δxj(i+1)∗δbj(i)δzj(i)
= δ L δ x j ( i + 1 ) ∗ x j ( i + 1 ) ∗ ( 1 − x j ( i + 1 ) ) \ \ \ \ \ \ \ \ \ =\frac{\delta L}{\delta x^{(i+1)}_{j}}*x^{(i+1)}_{j}*(1-x^{(i+1)}_{j}) =δxj(i+1)δL∗xj(i+1)∗(1−xj(i+1))
计算 δ L δ x j ( i ) \frac{\delta L}{\delta x^{(i)}_{j}} δxj(i)δL:
δ L δ x j ( i ) = δ L δ x j ( i + 1 ) ∗ δ x j ( i + 1 ) δ x j ( i ) \frac{\delta L}{\delta x^{(i)}_{j}} = \frac{\delta L}{\delta x^{(i+1)}_{j}} * \frac{\delta x^{(i+1)}_{j}}{\delta x^{(i)}_{j}} δxj(i)δL=δxj(i+1)δL∗δxj(i)δxj(i+1)
= δ L δ x j ( i + 1 ) ∗ x j ( i + 1 ) ∗ ( 1 − x j ( i + 1 ) ) ∗ w j ( i ) \ \ \ \ \ \ \ \ = \frac{\delta L}{\delta x^{(i+1)}_{j}} *x^{(i+1)}_{j}*(1-x^{(i+1)}_{j}) * w_{j}^{(i)} =δxj(i+1)δL∗xj(i+1)∗(1−xj(i+1))∗wj(i)
最后一层,这里 y y y是标签, y ′ y^{'} y′是预测值:
δ L δ x j ( m − 1 ) = δ L δ y j ′ = 1 n ∗ ( y j ′ − y j ) \frac{\delta L}{\delta x^{(m-1)}_{j}}=\frac{\delta L}{\delta y^{'}_{j}}=\frac{1}{n}*(y^{'}_{j}-y_{j}) δxj(m−1)δL=δyj′δL=n1∗(yj′−yj)
使用归纳(反向递推),即可得到 δ L δ x j ( i ) \frac{\delta L}{\delta x^{(i)}_{j}} δxj(i)δL
Q1: 为什么要用向量
因为电脑在处理向量或矩阵时能进行批量运算,在计算数量级很大时能显著节约训练时间。
Q2: 不用激活函数会发生什么
如果不用激活函数,意味着每一个节点都是进行线性变化,而线性变化的复合依然是线性变化,故再多的神经元也无法拟合出更好的结果。