LangChain实际应用
1、LangChain与RAG检索增强生成技术
LangChain是个开源框架,可以将大语言模型与本地数据源相结合,该框架目前以Python或JavaScript包的形式提供;
- 大语言模型:可以是GPT-4或HuggingFace的模型;
- 本地数据源:可以是一本书、一个PDF文件、一个包含专有信息的数据库;
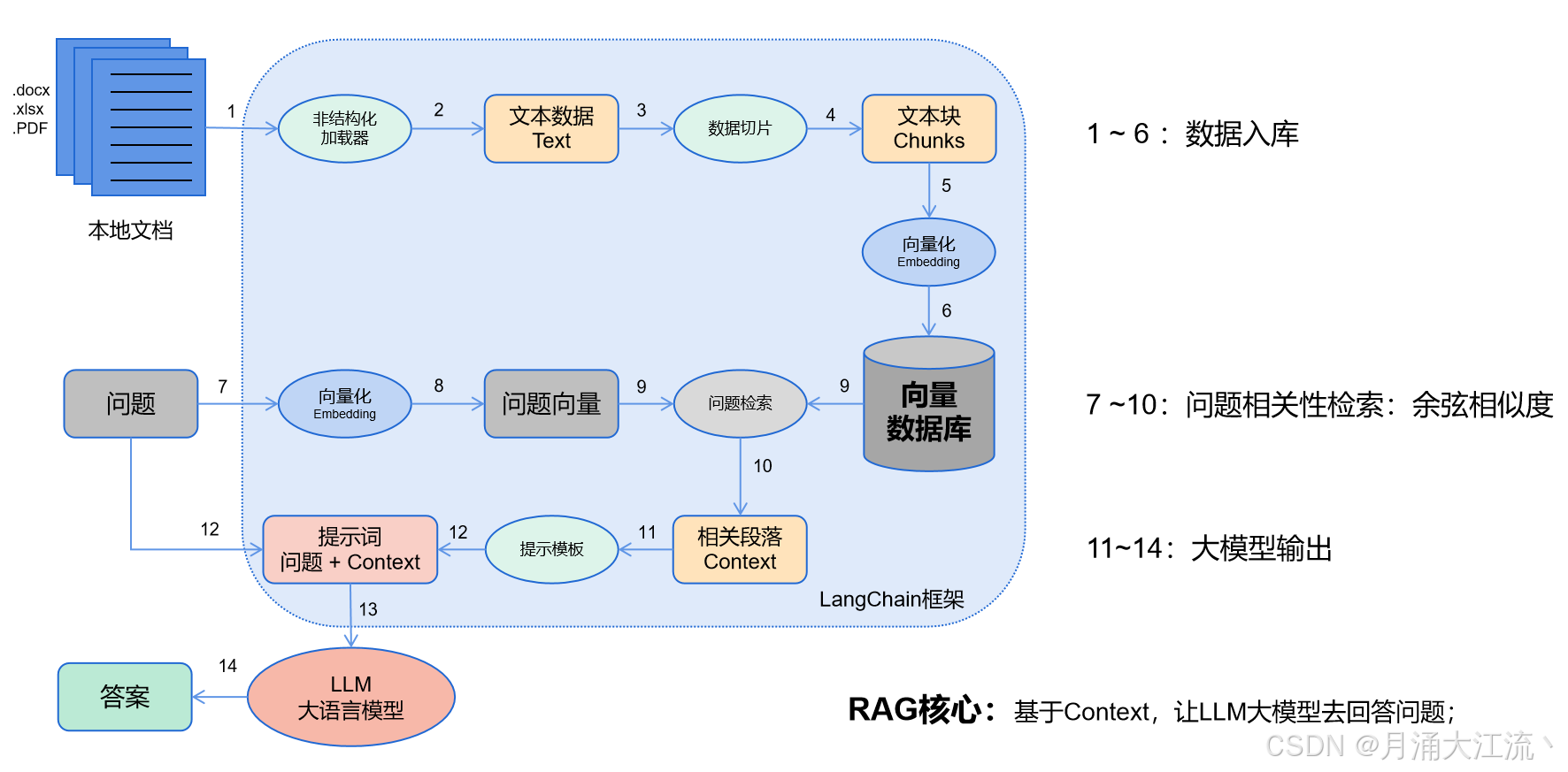
LangChain的工作流程:
- 数据入库:读取本地数据并切成小块,并把这些小块经过编码embedding后,存储在一个向量数据库中(下图1——6步);
- 相关性检索:用户提出问题,问题经过编码,再在向量数据库中做相似性检索,获取与问题相关的信息块context,并通过重排序算法,输出最相关的N个context(下图7——10步);
- 问题输出:相关段落context + 问题组合形成prompt输入大模型中,大模型输出一个答案或采取一个行动(下图11——15步)
安装 LangChain
pip install langchain
2、构建简单的 Chain 流程
LangChain 中的 Chain 能将多个 LLM 调用和逻辑步骤串联起来,比如将生成的问题传递给一个搜索工具,或将多个步骤的结果集成在一起。
示例:问答链(QA Chain)
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
import os# 初始化 OpenAI 的 LLM
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
llm = OpenAI(model_name="gpt-4")# 创建一个简单的问答模板
prompt_template = PromptTemplate(input_variables=["question"],template="Answer the question as detailed as possible: {question}",
)# 使用 LLM 和提示模板创建一个问答 Chain
qa_chain = LLMChain(llm=llm, prompt=prompt_template)# 提问
answer = qa_chain.run(question="What is LangChain?")
print(answer)
3、应用复杂的 Prompt 模板
在复杂的应用场景中,设计更灵活的 Prompt 模板,LangChain 支持动态生成复杂的输入模板。
from langchain.prompts import PromptTemplate# 创建带有多个变量的 Prompt 模板
prompt = PromptTemplate(input_variables=["product", "audience"],template="Describe the {product} in a way that appeals to {audience}.",
)# 生成 Prompt 内容
result_prompt = prompt.format(product="LangChain", audience="data scientists")
print(result_prompt)
4、构建多步 Chain
LLMChain能够组合多步任务,比如文本分析、摘要、总结等任务。
from langchain.chains import LLMChain, SimpleSequentialChain
from langchain.prompts import PromptTemplate# 定义第一个步骤:描述产品
prompt_1 = PromptTemplate(input_variables=["product"],template="Please describe what {product} does in a brief way.",
)
chain_1 = LLMChain(llm=llm, prompt=prompt_1)# 定义第二个步骤:针对第一步的描述生成市场营销方案
prompt_2 = PromptTemplate(input_variables=["description"],template="Create a marketing strategy for a product with this description: {description}",
)
chain_2 = LLMChain(llm=llm, prompt=prompt_2)# 将两个步骤组合成一个 Chain
sequential_chain = SimpleSequentialChain(chains=[chain_1, chain_2])# 执行 Chain
result = sequential_chain.run("LangChain")
print(result)
5、Memory 记录上下文
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationChain# 初始化记忆模块
memory = ConversationBufferMemory()# 创建会话 Chain,包含记忆模块
conversation = ConversationChain(llm=llm, memory=memory)# 模拟对话
conversation_result_1 = conversation("What is LangChain?")
conversation_result_2 = conversation("And what can it be used for?")
print(conversation_result_1)
print(conversation_result_2)"""
不同类型的 Memory 记录上下文
"""
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory, ConversationSummaryMemory# Conversation Buffer Memory - 记录完整对话
buffer_memory = ConversationBufferMemory()
conversation_chain_1 = ConversationChain(llm=llm, memory=buffer_memory)# 模拟对话
conversation_chain_1("What is LangChain?")
conversation_chain_1("What applications can it be used for?")
print(conversation_chain_1.memory.buffer)# Conversation Summary Memory - 提供对话概述
summary_memory = ConversationSummaryMemory(llm=llm)
conversation_chain_2 = ConversationChain(llm=llm, memory=summary_memory)# 模拟对话
conversation_chain_2("Tell me about quantum computing.")
conversation_chain_2("How is it different from classical computing?")
print(conversation_chain_2.memory.buffer)6、自定义 Agent:添加多个工具和自定义动作
Agent 可以配置多个工具,如搜索、计算和数据库访问。以下是一个包含自定义工具的示例。
示例:基于自定义工具的 Agent
from langchain.agents import initialize_agent, Tool
from langchain.tools import DuckDuckGoSearchResults, WikipediaAPI# 配置多个工具
search_tool = Tool.from_function(DuckDuckGoSearchResults(), name="search")
wiki_tool = Tool.from_function(WikipediaAPI(), name="wikipedia")# 创建 Agent 并加载工具
agent = initialize_agent(tools=[search_tool, wiki_tool],llm=llm,agent="zero-shot-react-description",
)# 使用 Agent 查询
response = agent("Find the latest information on AI and summarize it for me.")
print(response)
7、使用 Self-Ask 模式的 Agent
Self-Ask 是一种链式推理 Agent,适合回答需要分解的复杂问题。
from langchain.agents import initialize_agent# 初始化 Self-Ask 模式的 Agent
agent_self_ask = initialize_agent(tools=[search_tool, wiki_tool],llm=llm,agent="self-ask",
)# 测试 Self-Ask 模式
response = agent_self_ask("What is the main difference between AI and ML?")
print(response)
8、结合外部数据源:用 Pandas DataFrame 处理表格数据
LangChain 支持直接处理 Pandas 数据,可以轻松构建一个从表格数据中提取信息的功能。
import pandas as pd
from langchain.chains import AnalyzeDocumentChain# 创建数据表
data = pd.DataFrame({"name": ["AI Model A", "AI Model B", "AI Model C"],"accuracy": [0.95, 0.90, 0.85]
})# 配置 Chain 以处理表格数据
analyze_chain = AnalyzeDocumentChain.from_df(llm=llm,dataframe=data,question="Which AI model has the highest accuracy?"
)# 生成答案
result = analyze_chain.run()
print(result)
9、自定义 PromptPipelineChain:多模型的组合使用
可以结合多个模型,按步骤组合成更复杂的 Pipeline。
例如先调用小模型进行摘要,再用大模型进行详细生成。
from langchain.chains import PromptPipelineChain# 配置 PromptPipelineChain
pipeline_chain = PromptPipelineChain(steps=[{"llm": OpenAI(model_name="gpt-3.5-turbo", api_key="your_key"), "prompt": "Summarize the text: {text}"},{"llm": OpenAI(model_name="gpt-4"), "prompt": "Explain in detail: {summary}"},]
)# 运行 Pipeline
text = "LangChain is a framework for developing applications powered by language models."
result = pipeline_chain.run(text=text)
print(result)
10、使用 Retrieval 进行大规模文档查询
LangChain 支持集成向量存储库,例如 FAISS、Pinecone,进行语义搜索,适用于处理大量文档数据的场景。
示例:基于 FAISS 的语义搜索
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers import RetrievalQAChain# 假设有文档数据
docs = ["LangChain is a library for LLM applications.", "AI is revolutionizing many fields."]# 使用 FAISS 创建向量数据库
embedding = OpenAIEmbeddings()
faiss_store = FAISS.from_texts(docs, embedding)# 使用检索器进行语义搜索
retrieval_chain = RetrievalQAChain(llm=llm, retriever=faiss_store.as_retriever())
result = retrieval_chain.run("Tell me about LangChain.")
print(result)
11、结合 LangChain 的 RAG 模式
from langchain.chains import RetrievalQAChain# 创建 Retrieval Chain
rag_chain = RetrievalQAChain(llm=llm, retriever=faiss_store.as_retriever())# 查询
result = rag_chain("What is the LangChain library used for?")
print(result)