建模杂谈系列252 规则的串行改并行
说明
提到规则,还是需要看一眼RETE算法:
Rete算法是一种用于高效处理基于规则的系统中的模式匹配问题的算法,广泛应用于专家系统、推理引擎和生产系统。它的设计目的是在大量规则和数据的组合中快速找到满足特定规则条件的模式。
Rete算法的几个关键特点,使它在特定场景下非常高效:
1. 避免冗余计算
- 保存中间结果:Rete算法利用称为“Rete网”的数据结构存储中间计算结果。每次新数据到来时,不会重新从头计算所有规则,而是仅更新那些受到影响的部分。这避免了对不相关数据的重复匹配,大大减少了计算量。
- 共享条件检查:许多规则往往有相似的条件。Rete算法通过共享相同条件的计算结果,避免了对相同条件的重复评估。例如,如果多个规则都检查某个属性是否为特定值,Rete算法只进行一次检查,而不是对每个规则重复进行检查。
2. 增量式匹配
- Rete算法是一种增量式匹配算法。它仅在有新数据到达或数据更新时进行部分更新,而不是每次都从头重新计算所有数据和规则。这样一来,对于大量规则和数据的系统来说,性能得到了显著提升。
3. 分离规则与数据的处理
- Rete算法将规则的模式匹配与具体的数据处理分离开来。每个规则的条件被分解成不同的节点,在数据到来时,数据在这些节点中传播。这样即便是非常复杂的规则,算法也可以高效地进行匹配。
4. 适合多条件匹配
- Rete算法特别适合处理多个条件组合的模式匹配问题。它通过构建树形或网络结构来对条件进行层次化处理,使得多个条件的组合能够被高效地处理。
5. 低重复性数据处理
- 如果一个系统中的事实变化较少,而规则非常多,Rete算法的优势尤其明显。它能够减少对不变事实的重新处理,只处理变化的事实或数据。
为什么高效:
- 空间换时间:Rete算法通过大量存储中间结果,换取计算效率,适合需要频繁进行规则匹配的场景。
- 避免冗余计算和重复条件检查,最大限度地减少了不必要的计算。
- 增量更新方式确保了只处理受影响的部分,而不是每次全局匹配,大大提升了效率。
这些特性使得Rete算法在处理复杂的规则系统时能够大大减少计算开销,尤其适用于规则众多、数据量大但变化频繁的场景。
事实上,RETE产生的时间特别早(1974年),那个时代的计算资源是特别稀缺的。那个时代的许多算法、命令都是具有极简、极高效的特点,同时可读性一般也很差。
我认为,随着硬件的进步,效率是次要考虑的问题。如何节约人的时间,如何确保可靠的决策(可解释性)才是要有限考虑的问题。当然我还是更多的从数据处理的角度,而不是一个纯粹业务的角度去考虑规则引擎这个产品。
内容
1 人能掌握的逻辑
横向来看,人能掌握的逻辑不会超过10个(超过一定数据,大脑会自己尝试聚类),但是通过层级化纵向构建,我们可以掌控上百,甚至上千个逻辑。
但是层级化,通常也是效率的大敌。即便是使用了RETE,但是规则的逻辑链条很长,最终的执行结果也快不了。
既然层级避免不了,那么就建立一个层级框架,让逻辑可以更有效的聚拢和排序。
逻辑层级:
- R0: 前置规则 : 例如 <18岁不可以贷款, 通用由业务的监管强行指定,常为 if
- R1: 强规则 : 例如 没有固定收入不可以贷款, 由业务本身的逻辑确定,常为 if
- R2: 弱规则 : 例如 信用评分低于600不可以贷款, 超出人可观察的部分,采用模型量化的方式,常为model
- R3: 规则的规则 : 例如 同时有5个特定规则打分低,不可以贷款, model or if
- R4: 后置规则 : 例如 测试用户可以通过 , 其他特定的修补,常为 if
执行层级不同与逻辑层级,按照顺序,尽量合并可以并行执行的部分;并且尽量提早过滤掉可以递减的部分。这里其实还有另一个问题:一条数据是应该尽早作出决定,还是坚持跑完所有规则。
2 现实问题
先解决一些现实问题:实体匹配环节特别慢。
最初在实现逻辑时,并没有考虑效率问题。
逻辑代码大抵如下,对一篇文档里的若干个实体,循环调用规则(微服务接口)来获得处理结果。
...# r0 for the_ent in the_ent_list:# r0resp1 = req.post(f'{base_url}r000/', json = {'some_ent':the_ent}).json()if resp1['status'] == 'reject':print('r000', the_ent)continue resp2 = req.post(f'{base_url}r001/', json = {'some_ent':the_ent}).json()if resp2['status'] == 'reject':print('r001', the_ent)mr.illegal_suffix.append(the_ent)continue# r0 endthe_ent_len = len(the_ent) if the_ent_len< 2:mr.too_short.append(the_ent)elif the_ent_len <7:mr.short.append(the_ent)elif the_ent_len < 25:mr.norm.append(the_ent)else:mr.too_long.append(the_ent)
...
所以,当有15个实体的时候,第一个规则就花了约(0.005x15 ~ 0.075秒),第二个规则花了(0.005x64 ~ 0.32秒)
['基金', '美芯晟', '高新兴', '骏成科技', '证券时报', '深市主板', '创业板', '沪市', '科创板', '计算机', '机械设备', '共有3', '潍柴动力', '乐心医疗', '嘉曼服饰', '敏芯股份', '渝开发', '长虹美菱', '德联集团', '数据宝', '中航西飞', '顺络电子', '基金家数', '华利集团', '杰瑞股份', '邦彦技术', '兴瑞科技', '深天马', '漫步', '金力永磁', '太阳能', '普蕊斯', '德方纳米', '华锐精密', '伊之密', '西子洁能', '陕西华达', '浙江鼎力', '诺瓦星云', '远光']
0.006989002227783203
0.006243467330932617
0.007495403289794922
0.00716400146484375
0.00490117073059082
0.006025791168212891
0.00599360466003418
0.0046253204345703125
0.00520634651184082
0.004281282424926758
0.00481104850769043
0.00475764274597168
0.004372358322143555
0.005066394805908203
0.005623817443847656
r001 沪市
0.005009651184082031
0.004489898681640625
0.00529026985168457
0.004183292388916016
0.005280017852783203
0.004261970520019531
0.00518345832824707
0.004296541213989258
0.004305362701416016
0.004907131195068359
0.004319667816162109
0.004322052001953125
0.005274534225463867
0.004192829132080078
0.005210399627685547
0.004171133041381836
0.005131244659423828
0.004136562347412109
0.0051212310791015625
0.004184722900390625
0.004403829574584961
0.006170988082885742
0.004761934280395508
0.009701728820800781
0.007318019866943359
0.004835844039916992
0.004235267639160156
0.002786397933959961
0.0059130191802978516
0.0027306079864501953
0.0025987625122070312
0.0024881362915039062
0.004175662994384766
0.002477884292602539
0.004856109619140625
0.0036249160766601562
0.002595186233520508
0.0032770633697509766
0.0023193359375
0.003595113754272461
0.002864360809326172
0.0032558441162109375
0.004605293273925781
0.003146648406982422
0.0032491683959960938
0.0031249523162841797
0.0046842098236083984
0.003545045852661133
0.0027167797088623047
0.0030341148376464844
0.0034787654876708984
0.004285573959350586
0.002904176712036133
0.0032575130462646484
0.0021605491638183594
0.003958225250244141
0.00409245491027832
0.005880117416381836
0.004957675933837891
0.0028581619262695312
0.0026171207427978516
0.0026040077209472656
0.0026750564575195312
0.002580881118774414所以,效率问题在这里可以通过IO并发来解决。理论上,用协程更好些,多线程简单一点。
2.1 先测试一个并发
使用asyncio 并发
import json
import asyncio, aiohttpasync def json_query_worker(task_id = None , url = None , json_params = None,time_out = 320, semaphore = None):async with semaphore:try:async with aiohttp.ClientSession() as session:async with session.post(url, json = {**json_params},timeout=aiohttp.ClientTimeout(total=time_out)) as response:res = await response.text()return {task_id: json.loads(res)}except json.JSONDecodeError as e:print({task_id: f"JSONDecodeError: {e}"})return Noneexcept Exception as e:print({task_id: f"Exception: {e}"})return Noneasync def json_player(task_list , concurrent = 3):semaphore = asyncio.Semaphore(concurrent) # 并发限制tasks = [asyncio.ensure_future(json_query_worker(**x, semaphore = semaphore)) for x in task_list]return await asyncio.gather(*tasks)
执行
rname = 'r000'
# rname = 'r001'
short_name_query_url = f'http://127.0.0.1:24133/{rname}/'
ent_list = ['基金', '美芯晟', '高新兴', '骏成科技', '证券时报', '深市主板', '创业板', '沪市', '科创板', '计算机',
'机械设备', '共有3', '潍柴动力', '乐心医疗', '嘉曼服饰', '敏芯股份', '渝开发', '长虹美菱', '德联集团', '数据宝',
'中航西飞', '顺络电子', '基金家数', '华利集团', '杰瑞股份', '邦彦技术', '兴瑞科技', '深天马', '漫步',
'金力永磁', '太阳能', '普蕊斯', '德方纳米', '华锐精密', '伊之密', '西子洁能', '陕西华达', '浙江鼎力', '诺瓦星云', '远光']import time
tick1 = time.time()
task_list = []
for ent in ent_list:tem_dict = {}tem_dict['task_id'] = ent tem_dict['url'] = short_name_query_urltem_dict['json_params'] = {'some_ent':ent}task_list.append(tem_dict)
res = asyncio.run(json_player(task_list, concurrent = 100))
tick2 = time.time()
print('takes %.2f ' %(tick2-tick1))tick3 = time.time()
import requests as req
res_dict = {}
for ent in ent_list:resp = req.post(short_name_query_url, json = {'some_ent':ent}).json()res_dict[ent] = resp
tick4 = time.time()
print('takes %.2f ' %(tick4-tick3))takes 0.06
takes 0.22
---
takes 0.05
takes 0.22
---
takes 0.05
takes 0.19
---
takes 0.05
takes 0.18
---
takes 0.05
takes 0.23
一共有40个请求,平均下来,并行情况下每个约0.0015, 串行下每个0.0055。
所以,改造的思路:
- 1 【以实体为中心】原来是每个实体,逐个循环去遍历请求规则服务(这个是one模式,有用且仍然会保留)。
- 2 【以规则为中心】将所有实体批次的请求规则,一次性获得结果。
在这里,有一个细节(序列化开销)还是需要注意的。
在大部分的请求中,只要将对应的实体进行请求即可,问题不大;但是有个别规则,为了实现上下文判别,需要实体和原文同时输入。这时,如果原文很大,而实体又很多,那么序列化的成本就会非常高。另外就是,当处理还是按文档级别来,那么其实也还是某种程度的one模式(文档内并行了,而文档间还是串行)
所以,api化和本地化(函数)又是一对模式。 如果是查询性质的,或者是密集计算型的任务,适合用api。例如,要进行数据库查询,或者大模型请求,比较适合api化。而IO类的,比如,要查询一个实体的上下文,本质上是要在一个稍微大一些的文本里做正则类模糊查询,这个就适合在本地(函数)做。
2.2 并行改造
从效率考虑,并行的,递减的执行
part1: 这部分主要是进行过滤和分流。
原来
# r0 for the_ent in the_ent_list:# r0resp1 = req.post(f'{base_url}r000/', json = {'some_ent':the_ent}).json()if resp1['status'] == 'reject':print('r000', the_ent)continue resp2 = req.post(f'{base_url}r001/', json = {'some_ent':the_ent}).json()if resp2['status'] == 'reject':print('r001', the_ent)mr.illegal_suffix.append(the_ent)continue# r0 endthe_ent_len = len(the_ent) if the_ent_len< 2:mr.too_short.append(the_ent)elif the_ent_len <7:mr.short.append(the_ent)elif the_ent_len < 25:mr.norm.append(the_ent)else:mr.too_long.append(the_ent)
并行化
r000_url = base_url + 'r000/'tick1 = time.time()task_list = []for ent in ent_list:tem_dict = {}tem_dict['task_id'] = ent tem_dict['url'] = r000_urltem_dict['json_params'] = {'some_ent':ent}task_list.append(tem_dict)r000_res = asyncio.run(json_player(task_list, concurrent = 100))# 解析结果,保留passent_list1 = []for tem_res in r000_res:for k,v in tem_res.items():# print(k,v)if v['status'] == 'pass':ent_list1.append(k)tick2 = time.time()print('takes %.2f ' %(tick2-tick1))# 增加解析结果,慢了20%。如果可以传递一个全局对象,不需要再解析,这个可以更快
takes 0.06
r001
# r001 ent_list1 -> ent_list2r001_url = base_url + 'r001/'tick1 = time.time()task_list = []for ent in ent_list1:tem_dict = {}tem_dict['task_id'] = ent tem_dict['url'] = r001_urltem_dict['json_params'] = {'some_ent':ent}task_list.append(tem_dict)r001_res = asyncio.run(json_player(task_list, concurrent = 100))# 解析结果,保留passent_list2 = []for tem_res in r001_res:for k,v in tem_res.items():# print(k,v)if v['status'] == 'pass':ent_list2.append(k)elif v['status'] =='reject':mr.illegal_suffix.append(k)tick2 = time.time()print('takes %.2f ' %(tick2-tick1))
takes 0.06In [40]: mr
Out[40]: MultiRes(doc_id='aa', too_short=[], illegal_suffix=['沪市'], short=[], short_result=[], norm=[], norm_right=[], norm_modify=[], norm_vague=[], norm_right_result=[], norm_modify_result=[], norm_vague_result=[], too_long=[], mapping_list=[])
分流
# 分流for the_ent in ent_list2:the_ent_len = len(the_ent) if the_ent_len< 2:mr.too_short.append(the_ent)elif the_ent_len <7:mr.short.append(the_ent)elif the_ent_len < 25:mr.norm.append(the_ent)else:mr.too_long.append(the_ent)In [42]: mr
Out[42]: MultiRes(doc_id='aa', too_short=[], illegal_suffix=['沪市'], short=['基金', '美芯晟', '高新兴', '骏成科技', '证券时报', '深市主板', '创业板', '科创板', '计算机', '机械设备', '共有3', '潍柴动力', '乐心医疗', '嘉曼服饰', '敏芯股份', '渝开发', '长虹美菱', '德联集团', '数据宝', '中航西飞', '顺络电子', '基金家数', '华利集团', '杰瑞股份', '邦彦技术', '兴瑞科技', '深天马', '漫步', '金力永磁', '太阳能', '普蕊斯', '德方纳米', '华锐精密', '伊之密', '西子洁能', '陕西华达', '浙江鼎力', '诺瓦星云', '远光'], short_result=[], norm=[], norm_right=[], norm_modify=[], norm_vague=[], norm_right_result=[], norm_modify_result=[], norm_vague_result=[], too_long=[], mapping_list=[])
写着写着,我感觉可以归为一种称为 「waterfall」的模式
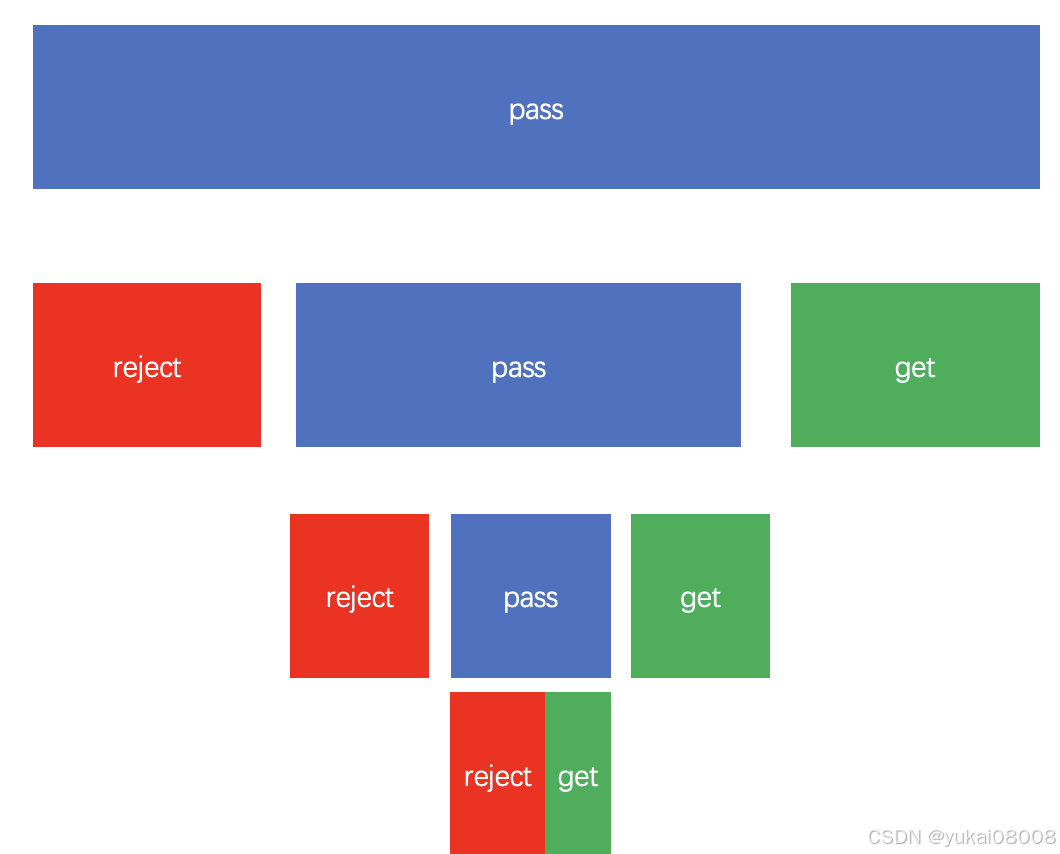
假设最初进来的数据是蓝色部分(pass),每一层的处理会分为三种情况:pass, reject和get。这样从形式上就可以完全统一起来
import json
import asyncio, aiohttpasync def json_query_worker(task_id = None , url = None , json_params = None,time_out = 320, semaphore = None):async with semaphore:try:async with aiohttp.ClientSession() as session:async with session.post(url, json = {**json_params},timeout=aiohttp.ClientTimeout(total=time_out)) as response:res = await response.text()return {task_id: json.loads(res)}except json.JSONDecodeError as e:print({task_id: f"JSONDecodeError: {e}"})return Noneexcept Exception as e:print({task_id: f"Exception: {e}"})return Noneasync def json_player(task_list , concurrent = 3):semaphore = asyncio.Semaphore(concurrent) # 并发限制tasks = [asyncio.ensure_future(json_query_worker(**x, semaphore = semaphore)) for x in task_list]return await asyncio.gather(*tasks)# 接口返回数据模型 v {status: pass/reject/get , data:None 或者匹配全称}
# mapping_list 仅用于本次,不是通用设计
# raw 也是如此
import time
def waterfall_api_mode(last_fall, rule_name ,reject_list = None, get_list = None, mappling_list = None, raw = None , base_url = None):next_fall = []last_ent_list = last_fall pure_rule_url = rule_name + '/'if len(last_ent_list):rule_url = base_url + pure_rule_url# api modetick1 = time.time()task_list = []for ent in last_ent_list:tem_dict = {}tem_dict['task_id'] = ent tem_dict['url'] = rule_urlif raw is None :tem_dict['json_params'] = {'some_ent':ent}else:tem_dict['json_params'] = {'some_ent':ent,'raw':raw}task_list.append(tem_dict)rule_res = asyncio.run(json_player(task_list, concurrent = 100))# 解析结果,保留passfor tem_res in rule_res:for k,v in tem_res.items():# print(k,v)if v['status'] == 'pass':next_fall.append(k)elif v['status'] == 'get':if get_list is not None :get_list.append(v['data'])if mappling_list is not None :mappling_list.append({'ent':k,'mapping_ent': v['data']})elif v['status'] == 'reject':if reject_list is not None :reject_list.append(k)tick2 = time.time()print('takes %.2f ' %(tick2-tick1))return next_fall
这样在运行规则时形式上会高度统一:
这次是事后调整,所以有些地方明显不是最优的。例如worker在并发时可以直接修改全局对象,而不是在处理完之后再进行合并。
2.3 等价校验
在并行化改造之后,需要进行结果校验才能切换。由于这部分内容不改变内容,仅仅是做运行效率的提升,所以结果可以直接使用程序进行比对。
方法:
- 1 随机抽取100-10000篇文档处理
- 2 分别采取串行和并行服务处理,结果直接进行等价判断
- 3 如果在随机一万的程度都没有差异,则可以替换