【星海随笔】云解决方案学习日志篇(二) kafka、Zookeeper、Fielbeat
Elastic 中国社区官方博客
https://blog.csdn.net/ubuntutouch/category_9209092.html
Kafka
kafka的源代码是基于Scala语言编写的,运行在Java虚拟机(即:JVM)上。因此,在安装kafka之前需要先安装JDK
Kafka 为什么依赖 Zookeeper
- 1.协调分布式系统:Kafka是一个分布式系统,各个节点之间需要进行协调和同步,而Zookeeper正是为分布式系统提供协调和同步的服务的。
- 2.元数据管理:Kafka的元数据包括了集群的配置、broker的状态等信息,而这些信息需要被所有的Kafka节点共享和维护。Zookeeper提供了一个分布式的文件系统,可以方便地存储和管理这些元数据信息。
- 3.领导选举:Kafka的一个分区只会分配给一个broker进行读写,而这个broker就是该分区的leader。当leader宕机后,需要从剩余的broker中选举一个新的leader。而Zookeeper可以提供分布式锁和选举的功能,因此Kafka可以利用Zookeeper来实现leader选举。
综上所述,Kafka依赖Zookeeper主要是为了协调分布式系统、元数据管理和领导选举。
ZK安装
来源于apache
1.下载
下载地址:https://zookeeper.apache.org/releases.html
2.解压安装包
tar -zxf apache-zookeeper-3.7.1-bin.tar.gz -C /usr/local/
/usr/local/apache-zookeeper-3.7.1-bin/ /usr/local/zookeeper-3.7.1/
3.拷贝配置文件,
cp /usr/local/zookeeper-3.7.1/conf/zoo_sample.cfg /usr/local/zookeeper-3.7.1/conf/zoo.cfg
4.修改配置文件
#在配置文件中加一行监听本机 IP 即可
clientPortAddress=10.0.5.163
zookeeper默认会占用8080端口,如果你本机已有服务在使用8080,可以把下面参数添加到zoo.cfg 文件里,自定义端口
admin.serverPort=8001
5.启动zk
/usr/local/zookeeper-3.7.1/bin/zkServer.sh start
6.查看端口是否监听
netstat -lntp |grep 2181
如果服务未监听,请查看日志排查问题
more zookeeper-root-server-VM-5-163-centos.out
kafka 部署
1.下载
下载地址:https://kafka.apache.org/downloads
2.解压安装包
tar -zxf kafka_2.12-3.4.0.tgz -C /usr/local/
3.修改kafka配置
vim /usr/local/kafka_2.12-3.4.0/config/server.properties
#修改 zk 的IP
zookeeper.connect=10.0.5.163:2181#修改监听地址
listeners=PLAINTEXT://10.0.5.163:9092
4.启动kafka
nohup /usr/local/kafka_2.12-3.4.0/bin/kafka-server-start.sh /usr/local/kafka_2.12-3.4.0/config/server.properties >/tmp/kafka.log 2>&1 &
5.查看端口是否监听
netstat -lntp |grep 9092
Flebeat部署
原理流程如下:
首先是input输入,可以指定多个数据输入源,然后通过通配符进行日志文件的匹配
匹配到日志后,就会使用Harvester(收割机),将日志源源不断的读取到来
然后收割机收割到的日志,就传递到Spooler(卷轴),然后卷轴就在将他们传到对应的地方
1.下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.16.1-linux-x86_64.tar.gz
2.解压二进制包
tar zxf filebeat-7.16.1-linux-x86_64.tar.gz -C /usr/local/
mv /usr/local/filebeat-7.16.1-linux-x86_64/ /usr/local/filebeat-7.16.1
3.创建 Filebeat 配置文件
#备份模板文件
mv /usr/local/filebeat-7.16.1/filebeat.yml /usr/local/filebeat-7.16.1/filebeat.yml.bak
#创建配置文件
cat > /usr/local/filebeat-7.16.1/filebeat.yml << "EOF"
filebeat.inputs:
- type: logtail_files: truebackoff: "1s"paths:- /var/log/nginx/access.json.logfields:type: accessfields_under_root: true
- type: logtail_files: truebackoff: "1s"paths:- /var/log/messagesfields:type: messagesfields_under_root: true
output:kafka:hosts: ["10.0.5.163:9092"]topic: hosts_10-0-5-163
EOF
4.启动Fielbeat
#查看是否已存在进程,将其停止
ps -ef |grep filebeat |grep -v grep |awk '{print $2}' |xargs kill -9#启动Filebeat
nohup /usr/local/filebeat-7.16.1/filebeat -e -c /usr/local/filebeat-7.16.1/filebeat.yml >/tmp/filebeat.log 2>&1 &#查看进程
ps -ef |grep filebeat#查看是否与ZK建立连接
netstat -ntp |egrep -w '9092|filebeat'
Fielbeat使用
启动
./filebeat -e -c shengxia.yml
yaml文件介绍
filebeat.inputs: # filebeat input输入
- type: stdin # 标准输入enabled: true # 启用标准输入
setup.template.settings: index.number_of_shards: 3 # 指定下载数
output.console: # 控制台输出pretty: true # 启用美化功能enable: true
输送至ElasticSearch或者Logstash,在Kibana中实现可视化
然后我们在控制台输入hello,就能看到我们会有一个json的输出,是通过读取到我们控制台的内容后输出的,内容如下
{"@timestamp": "2023-05-31T22:57:58.700Z","@metadata": {#元数据信息"beat": "filebeat","type": "_doc","version": "8.8.1"},"log": {"offset": 0,"file": {"path": ""}},"message": "hello",#元数据信息"input": {#控制台标准输入"type": "stdin"#元数据信息},"ecs": {"version": "8.0.0"},"host": {"name": "elk-node1"},"agent": {#版本以及主机信息"id": "5d5e4b99-8ee3-42f5-aae3-b0492d723730","name": "elk-node1","type": "filebeat","version": "8.8.1","ephemeral_id": "24b4fd16-5466-4d7e-b4b8-b73d41f77de0"}
}
参考文档:https://blog.csdn.net/qq_52589631/article/details/131216188
再次创建一个文件,叫 shengxia-log.yml,然后在文件里添加如下内容
filebeat.inputs:
- type: logenabled: truepaths:- /opt/elk/logs/*.log
setup.template.settings:index.number_of_shards: 3
output.console:pretty: trueenable: true
添加完成后,我们在到下面目录创建一个日志文件
# 创建文件夹
mkdir -p /opt/elk/logs# 进入文件夹
cd /opt/elk/logs# 追加内容
echo "hello world" >> test.log
然后再次启动filebeat
./filebeat -e -c shengxia-log.yml
能够发现,它已经成功加载到了我们的日志文件 test.log
同时我们还可以继续往文件中追加内容
追加后,我们再次查看filebeat,也能看到刚刚我们追加的内容
检测到日志文件有更新,立刻就会读取到更新的内容,并且输出到控制台。
自定义字段
当我们的元数据没办法支撑我们的业务时,我们还可以自定义添加一些字段
filebeat.inputs:
- type: logenabled: truepaths:- /opt/elk/logs/*.logtags: ["web", "test"] #添加自定义tag,便于后续的处理fields: #添加自定义字段from: web-testfields_under_root: true #true为添加到根节点,false为添加到子节点中
setup.template.settings:index.number_of_shards: 3
output.console:pretty: trueenable: true
添加完成后,重启 filebeat
./filebeat -e -c shengxia-log.yml
filebeat.inputs:
- type: logenabled: truepaths:- /opt/elk/logs/*.logtags: ["web", "test"]fields:from: web-testfields_under_root: false
setup.template.settings:index.number_of_shards: 1
output.elasticsearch:hosts: ["192.168.40.150:9200","192.168.40.137:9200","192.168.40.138:9200"]
Logstash 配置
1.修改Logstash 配置文件(下面 output 将日志打印到本地,观察日志是否采集到,日志格式是否正确)
cat > /usr/local/logstash-7.16.1/config/logstash.conf << "EOF"
input {kafka {bootstrap_servers => "10.0.5.163:9092"topics => ["hosts_10-0-5-163"]group_id => "test"codec => "json"}
}filter {if [type] == "access" {json {source => "message"remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]}}
}output {stdout {codec=>rubydebug}
}
EOF
2.执行前台启动命令
#查看是否已存在进程,将其停止
ps -ef |grep logstash |grep -v grep |awk '{print $2}' |xargs kill -9#启动 Logstash
logstash -f /usr/local/logstash-7.16.1/config/logstash.conf
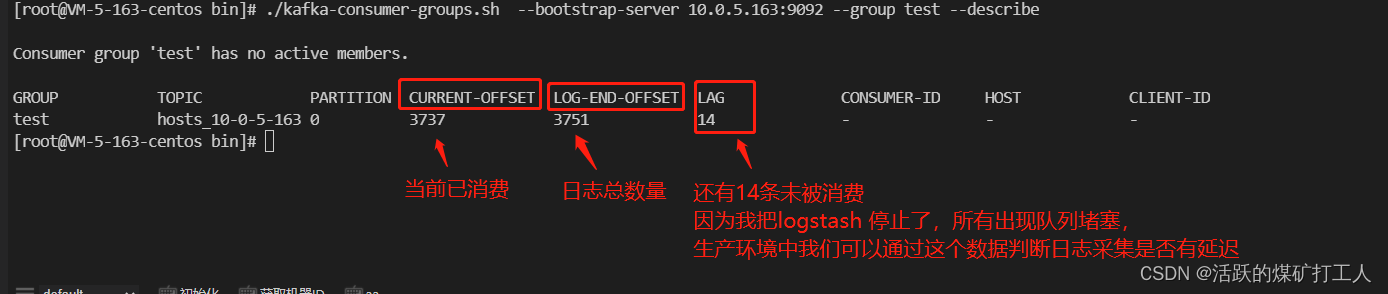
3.查看kafka Group 和队列信息
#进入kafka 安装目录
cd /usr/local/kafka_2.12-3.4.0/bin
#查看所有topic
./kafka-topics.sh --bootstrap-server 10.0.5.163:9092 --lis
#查看Group
./kafka-consumer-groups.sh --bootstrap-server 10.0.5.163:9092 --list
#查看队列
./kafka-consumer-groups.sh --bootstrap-server 10.0.5.163:9092 --group test --describe
4.修改配置文件,将output 将日志写入elasticsearch
cat > /usr/local/logstash-7.16.1/config/logstash.conf << "EOF"
input {kafka {bootstrap_servers => "10.0.5.163:9092"topics => ["hosts_10-0-5-163"]group_id => "test"codec => "json"}
}
filter {if [type] == "access" {json {source => "message"remove_field => ["message","@version","path","beat","input","log","offset","prospector","source","tags"]}}
}output{if [type] == "access" {elasticsearch {hosts => ["http://127.0.0.1:9200"]user => "elastic"password => "elk@2023"index => "access-%{+YYYY.MM.dd}"}}else if [type] == "messages" {elasticsearch {hosts => ["http://127.0.0.1:9200"]user => "elastic"password => "elk@2023"index => "messages-%{+YYYY.MM.dd}"}}
}
EOF
4.后台启动 Logstash
#查看是否已存在进程,将其停止
ps -ef |grep logstash |grep -v grep |awk '{print $2}' |xargs kill -9#启动 Logstash
nohup logstash -f /usr/local/logstash-7.16.1/config/logstash.conf >/tmp/logstash.log 2>&1 &
查看服务日志是否正常
查看日志是否有 ERROR 持续输出
tailf /tmp/logstash.log#查看logstash 端口是否监听
netstat -lntp |grep 9600