机器学习笔记 - LoRA:大型语言模型的低秩适应
一、简述
1、模型微调
随着大型语言模型 (LLM) 的规模增加到数千亿,对这些模型进行微调成为一项挑战。传统上,要微调模型,我们需要更新所有模型参数。这也称为完全微调 (FFT) 。下图详细概述了此方法的工作原理。

完全微调FFT 的计算成本和资源需求很大,因为更新每个参数都需要大量的处理和内存。其次,使用像 FFT 这样的方法,存在灾难性遗忘的风险,即模型在过度学习新数据时会忘记以前学到的信息。
于是为应对这一情况,出现了一系列称为参数高效微调 (PEFT)的方法。PEFT 仅需修改一小部分参数(在某些任务中甚至为 1%)即可达到与 FFT 相近的准确度。使用 PEFT,微调将需要更少的计算和时间,并降低过度拟合的风险。
2、LoRA
一种流行的 PEFT 方法就是LoRA,大型语言模型的低秩自适应 ( LoRA ) 由微软开发,通过学习秩分解矩阵对并冻结原始权重来减少可训练参数的数量。
该方法基于一个假设:权重变化矩阵 ΔW 可以在较低维度中表示。换句话说,ΔW 的秩很低。这被称为内在秩假设。
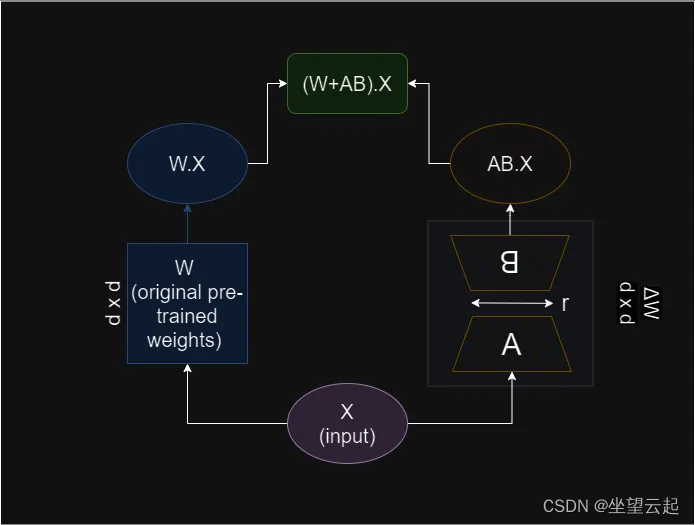
Lora 尝试微调模型的“残差”&#