人工智能任务5-高级算法工程师需要学习哪些课程与掌握哪些能力
大家好,我是微学AI,今天给大家介绍一下人工智能的任务5-高级算法工程师需要学习哪些课程,需要掌握哪些能力。高级算法工程师需要掌握的算法模型有:人脸检测模型MTCNN,人脸识别方法Siamese network、center loss、softmax loss、L-softmax loss、A-softmax loss、AM-softmax loss、Arc-softmax loss(arc face loss)、多目标检测识别模型RCNN(RCNN、SPP-Net、fast-RCNN、faster-RCNN)系列、YOLO(v1-v5)系列,图像生成项目AE系列、AVE、GAN系列,图像分割项目UNet系列、DeepLab、Mask-Rcnn,语音识别、语音命令,NLP词嵌入、自然语言模型SEQ2SEQ模型、SEQ+注意力、word2vec、EMLo、Transformer、BERT、GPT、GPT2、GPT3,深度强化学习原理、深度强化学习模型Q-Learning、DQN、A2C\A3C、DDPG,以及深度学习框架TensorFlow的使用等内容。
文章目录
- MTCNN 模型
- Siamese Network
- Center Loss
- 各类损失函数
- RCNN 系列
- YOLO 系列 (YOLO v1-v5)
- AE系列, AVE, 生成对抗网络GAN
- UNet网络系列 DeepLab, Mask R-CNN)
- 语音识别技术
- NLP模型
- Word Embeddings的原理
- Seq2Seq模型的原理
- Transformer模型的原理
- BERT和GPT系列的原理
- 深度强化学习
- TensorFlow框架
MTCNN 模型
MTCNN是一种用于人脸检测的深度学习模型,它通过一个三级卷积神经网络结构来实现。第一级负责快速粗定位,第二级对第一级的输出进行精调,最后一级则进一步细化边界框并给出置信度评分。MTCNN能够同时处理人脸检测和对齐的任务,为后续的人脸识别提供准确的输入。

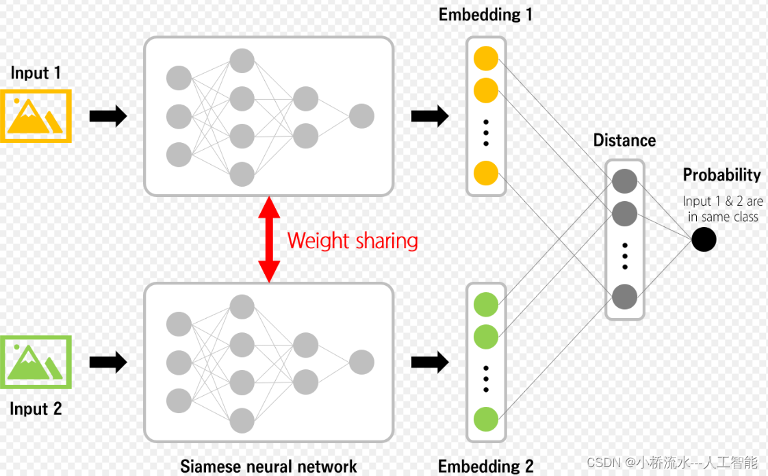
Siamese Network
Siamese网络是一种用于学习特征表示的神经网络架构,它包含两个相同的子网络,这两个子网络共享权重。Siamese网络通常用于比较两个输入样本之间的相似性,通过计算它们之间的距离来判断它们是否属于同一类别。这种网络在人脸验证和识别任务中非常有用。
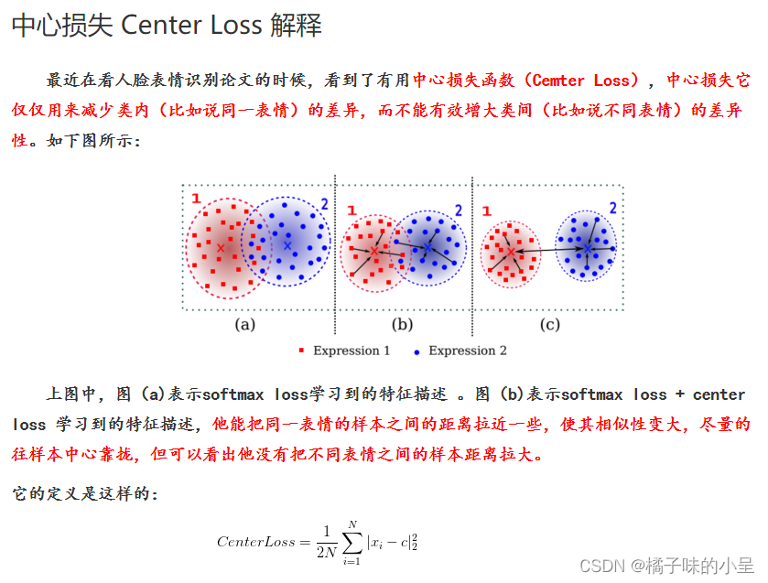
Center Loss
Center Loss是一种辅助损失函数,用于训练深度学习模型时减少类内差异和增加类间差异。它通过将每个类别的中心向量更新为其所属样本的平均值来工作,从而使得同一类别的样本更接近中心,不同类别的样本离中心更远。
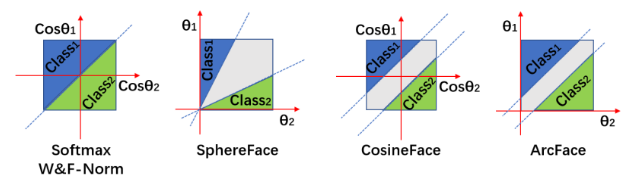
各类损失函数
需要掌握的损失函数包括:Softmax Loss, L-Softmax Loss, A-Softmax Loss, AM-Softmax Loss, Arc-Softmax Loss (Arc Face Loss)
这些都是分类损失函数,用于训练深度学习模型进行分类任务。Softmax Loss是最常用的损失函数之一,适用于多分类问题。L-Softmax Loss、A-Softmax Loss、AM-Softmax Loss和Arc-Softmax Loss是Softmax Loss的变体,它们通过调整角度或者引入额外的参数来改善分类性能,特别是在小样本学习和高难度分类任务中表现更好。
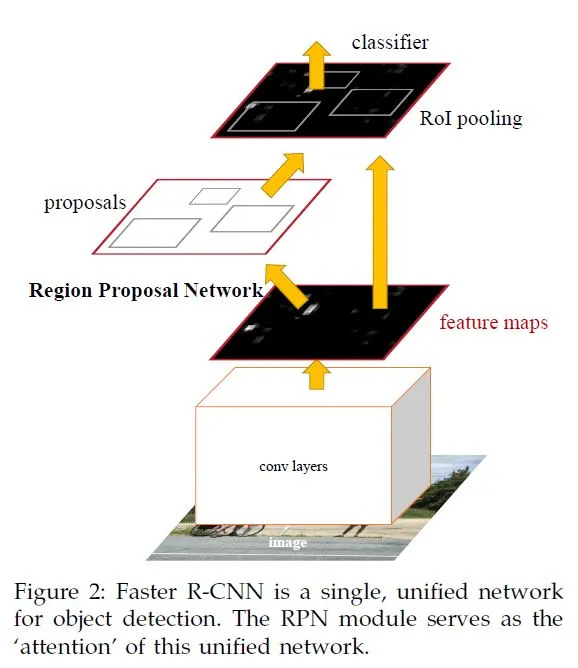
RCNN 系列
RCNN系列是一系列用于目标检测的深度学习模型。RCNN最初提出了区域提议网络的概念,随后SPP-Net改进了特征提取的效率,fast-RCNN通过共享卷积层提高了速度,而faster-RCNN则引入了、(RPN)来实现端到端的目标检测。
RCNN系列是通过提取候选区域并使用CNN进行分类和边界框回归来实现。SPP-Net提出了空间金字塔池化层来解决不同大小的输入图像问题。fast-RCNN改进了RCNN,通过共享卷积特征来加速检测过程。faster-RCNN进一步优化,引入了Region Proposal Network (RPN)来快速生成候选区域。
YOLO 系列 (YOLO v1-v5)
YOLO系列是另一组用于目标检测的深度学习模型,以其高速和实时性能著称。YOLO通过直接在整个图像上预测边界框和类别概率来工作,避免了传统目标检测方法中的区域提议步骤。随着版本的迭代,YOLO在精度和速度方面都有所提升。
YOLO系列是一种端到端的物体检测系统,它将检测和分类任务合并为单一的神经网络。YOLO通过将图像划分为网格,并为每个网格预测边界框和类别概率。YOLO系列包括多个版本,如YOLOv1、YOLOv2、YOLOv3、YOLOv4和YOLOv5,每一代都在速度和精度上有所改进。
AE系列, AVE, 生成对抗网络GAN
Autoencoders (AE series) 是一种无监督学习算法,它通过编码器和解码器的过程学习数据的压缩表示。Anomaly Detection with Variational Autoencoder (AVE) 利用变分自编码器来检测异常点。GAN是一种生成对抗网络,由生成器和鉴别器组成,通过对抗过程学习生成新的数据实例。
UNet网络系列 DeepLab, Mask R-CNN)
UNet系列是一种用于医学图像分割的深度学习模型,它通过对称的编码器和解码器结构来保持空间信息。DeepLab使用空洞卷积来扩大感受野,而Mask R-CNN结合了Faster R-CNN和FCN,用于实例分割。
语音识别技术
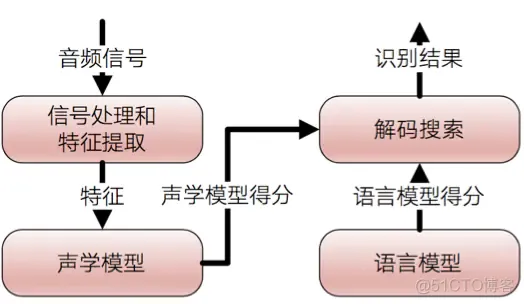
语音识别技术涉及将语音信号转换为文本的过程。语音命令识别则是识别特定指令的语音模式。这些技术通常依赖于深度学习模型,如循环神经网络(RNN)和长短期记忆网络(LSTM),来处理序列数据。
NLP模型
Word Embeddings的原理
Word Embeddings是一种将文本数据中的单词映射到连续向量空间中的技术。这种映射可以将单词的语义信息编码为向量中的位置和方向。通常情况下,这些向量是固定长度的,因此不同的单词都被映射到相同维度的向量空间中。Word Embeddings的主要思想是根据单词的上下文来学习单词的向量表示。Word2Vec和GloVe是两种常见的word embedding方法。它们的主要思想是根据单词的上下文来学习单词的向量表示。Word2Vec有两个主要变种,CBOW(Continuous Bag of Words)和Skip-gram。CBOW试图从上下文中的单词预测目标单词,而Skip-gram则相反,从目标单词预测上下文单词。GloVe(Global Vectors for Word Representation)结合了全局统计信息和局部上下文信息,以学习单词向量。
Seq2Seq模型的原理
Seq2Seq模型是一种用于处理输入和输出均为序列的任务,例如机器翻译、语音识别和文本摘要。Seq2Seq模型通常包括编码器和解码器两部分。编码器负责将输入序列编码为固定大小的上下文向量,解码器则根据上下文向量生成输出序列。
Transformer模型的原理
Transformer模型是一种基于自注意力机制的模型,它能够更有效地捕捉序列中的长距离依赖关系。Transformer模型主要由两个部分组成:一个编码器和一个解码器。编码器接收输入序列的单词,并将其转换为一个位置编码的向量序列。解码器则将这个向量序列解码为输出序列。
BERT和GPT系列的原理
BERT和GPT系列模型都是基于Transformer架构的预训练语言模型。BERT使用双向Transformer Encoder结构,在预训练阶段使用了两种任务:遮盖语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)。GPT则使用了多层的 Transformer decoder结构,在预训练阶段使用了两种任务:语言模型(LM)和下一句预测(NSP)。
这些模型通过学习大量的语料库,学习词与词之间的语义关系,并生成对应的词向量。这些词向量可以用于各种NLP任务,如文本分类、命名实体识别、情感分析等。
深度强化学习
深度强化学习是一种机器学习范式,其中智能体通过与环境互动来学习最优策略。Q-Learning、DQN、A2C/A3C和DDPG是一些常见的深度强化学习模型,它们分别采用不同的方法来解决强化学习问题。
TensorFlow框架
TensorFlow是一个开源的深度学习框架,它允许研究人员和工程师构建复杂的神经网络模型。TensorFlow提供了灵活的API和广泛的社区支持,使其成为许多深度学习项目的首选工具。