pytorch笔记:自动混合精度(AMP)
1 理论部分
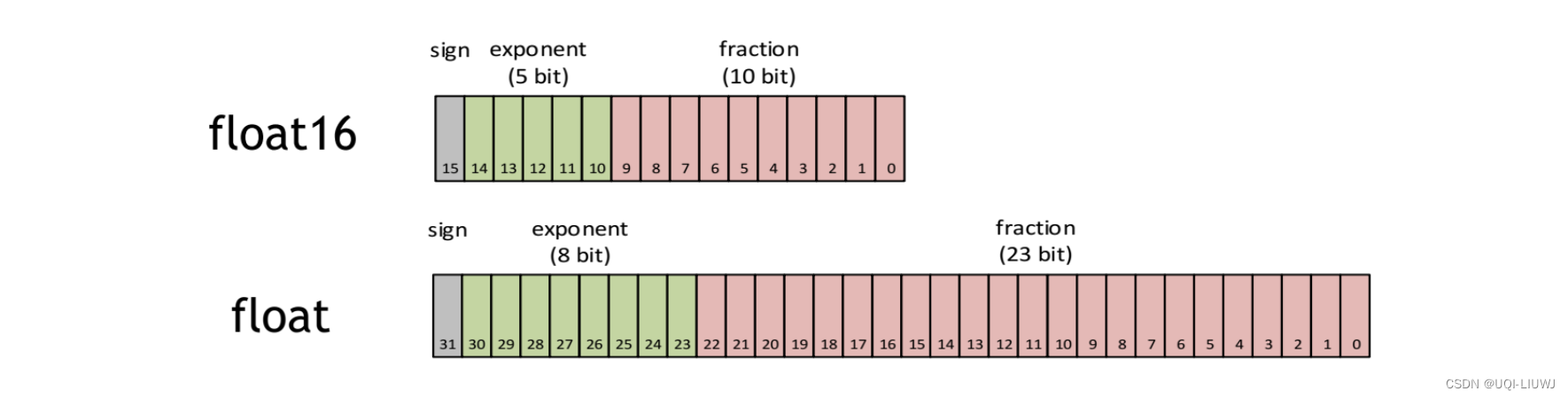
1.1 FP16 VS FP32
- FP32具有八个指数位和23个小数位,而FP16具有五个指数位和十个小数位
- Tensor内核支持混合精度数学,即输入为半精度(FP16),输出为全精度(FP32)
1.1.1 使用FP16的优缺点
- 优点
- FP16需要较少的内存,因此更易于训练和部署大型神经网络,同时还减少了数据移动(同时可以使用更大的batch)
- 数学运算的运行速度大大降低了
- NVIDIA提供的Volta GPU的确切数量是:FP16中为125 TFlops,而FP32中为15.7 TFlops(加速8倍)
- 缺点:
- 从FP32转到FP16时,必然会降低精度
- 但有的时候,这个精度的降低可以忽略不计
- FP16实际上可以很好地表示大多数权重和渐变。
- ——>拥有存储和使用FP32所需的所有这些额外位只是浪费。

- 溢出错误
- 由于FP16的动态范围比FP32位的狭窄很多,因此,在计算过程中很容易出现上溢出和下溢出
- 溢出之后就会出现"NaN"的问题
- 从FP32转到FP16时,必然会降低精度
1.2 解决上述FP16的问题
1.2.1 混合精度训练
- 用FP16做储存和乘法,而用FP32做累加避免舍入误差
- ——>混合精度训练的策略有效地缓解了舍入误差的问题
1.2.2 损失放大(Loss scaling)
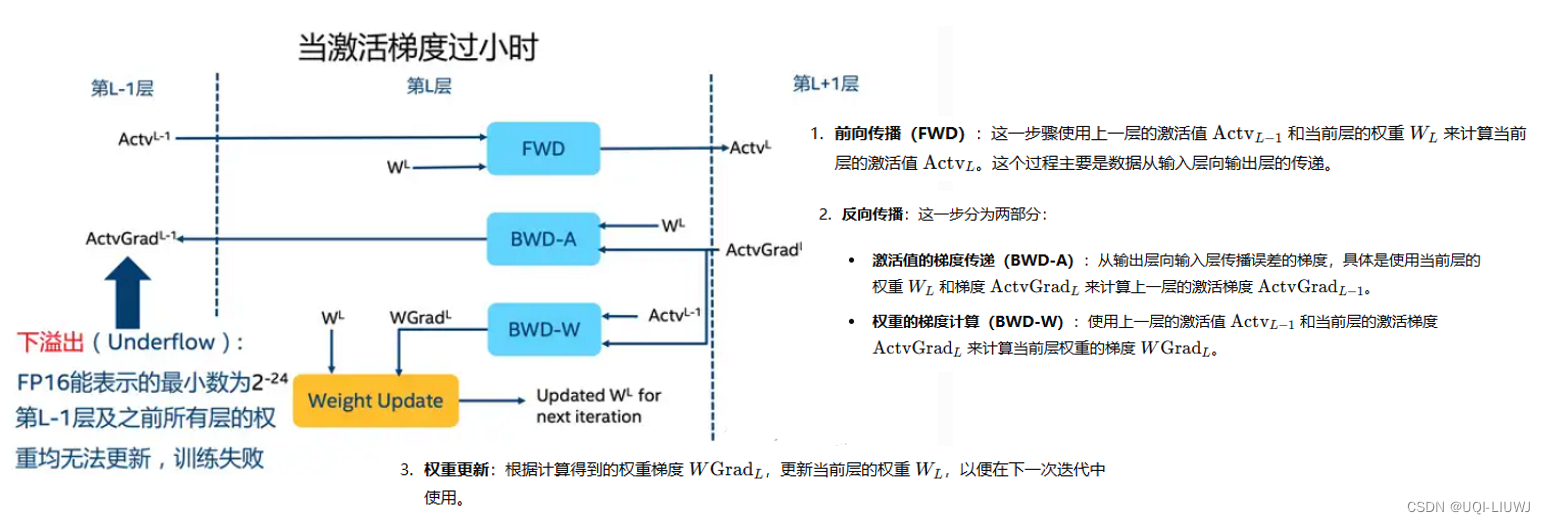
- 即使使用了混合精度训练,还是存在无法收敛的情况
- 原因是激活梯度的值太小,造成了溢出。
- ——>通过使用torch.cuda.amp.GradScaler,通过放大loss的值来防止梯度的下溢出
- 只在BP时传递梯度信息使用,真正更新权重时还是要把放大的梯度再unscale回去
-
反向传播前,将损失变化手动增大2^k倍
-
因此反向传播时得到的中间变量(激活函数梯度)不会溢出;
-
-
反向传播后,将权重梯度缩小2^k倍,恢复正常值。
-
- 只在BP时传递梯度信息使用,真正更新权重时还是要把放大的梯度再unscale回去
2 torch.cuda.amp
- AMP(自动混合精度)的关键词有两个:
- 自动
- Tensor的dtype类型会自动变化,框架按需自动调整tensor的dtype,当然有些地方还需手动干预
- 混合精度
- 采用不止一种精度的Tensor,torch.FloatTensor和torch.HalfTensor
- 自动
2.1 Pytorch中不同类型的tensor
| 类型名称 | 位数 |
| torch.DoubleTensor | 64bit |
| torch.LongTensor | 64bit |
| torch.FloatTensor(默认) | 32bit |
| torch.IntTensor | 32bit |
| torch.HalfTensor | 16bit |
| torch.BFloat16Tensor | 16bit |
| torch.ShortTensor | 16bit |
| torch.ByteTensor(无符号) | 8bit |
| torch.CharTensor | 8bit |
| torch.BoolTensor | Boolean |
2.2 在AMP上下文中,被自动转化为半精度浮点型的参数:
| __matmul__ |
| addbmm |
| addmm |
| addmv |
| addr |
| baddbmm |
| bmm |
| chain_matmul |
| conv1d |
| conv2d |
| conv3d |
| conv_transpose1d |
| conv_transpose2d |
| conv_transpose3d |
| linear |
| matmul |
| mm |
| mv |
| prelu |
2.3 autocast
from torch.cuda.amp import autocast as autocastmodel = Net().cuda()
#首先初始化一个网络模型Net(),并使用.cuda()方法将模型移至GPU上以利用GPU加速
#Net中的参数默认是torch.FloatTensoroptimizer = optim.SGD(model.parameters(), ...)for input, target in data:optimizer.zero_grad()with autocast():output = model(input)loss = loss_fn(output, target)'''自动混合精度环境包含了前向过程(模型的输出)和loss的计算把支持参数对应tensor的dtype转换为半精度浮点型,从而在不损失训练精度的情况下加快运算进入autocast的上下文时,tensor可以是任何类型不需要在model或者input上手工调用.half() ,框架会自动做'''loss.backward()optimizer.step()# 反向传播在autocast上下文之外2.4 GradScaler
在2.3的基础上增加,反向传播时增加梯度,以防止下溢出
from torch.cuda.amp import autocast as autocast
from torch.cuda.amp import GradScalermodel = Net().cuda()
#首先初始化一个网络模型Net(),并使用.cuda()方法将模型移至GPU上以利用GPU加速
#Net中的参数默认是torch.FloatTensoroptimizer = optim.SGD(model.parameters(), ...)scaler = GradScaler()
# 在训练最开始之前实例化一个GradScaler对象for epoch in epochs:for input, target in data:optimizer.zero_grad()with autocast():output = model(input)loss = loss_fn(output, target)'''自动混合精度环境包含了前向过程(模型的输出)和loss的计算把支持参数对应tensor的dtype转换为半精度浮点型,从而在不损失训练精度的情况下加快运算进入autocast的上下文时,tensor可以是任何类型不需要在model或者input上手工调用.half() ,框架会自动做'''scaler.scale(loss).backward()# Scales loss. 为了梯度放大,防止下溢出# 代替原来的loss.backward()scaler.step(optimizer)'''scaler.step() 首先把梯度的值unscale回来.如果梯度的值不是 infs 或者 NaNs, 那么调用optimizer.step()来更新权重,否则,忽略step调用,从而保证权重不更新(不被破坏)'''scaler.update()'''准备着,看是否要增大scaler'''- scaler的大小在每次迭代中动态的估计
- 为了尽可能的减少梯度underflow,scaler应该更大
- 但是如果太大的话,半精度浮点型的tensor又容易overflow(变成inf或者NaN)。
- ——>动态估计的原理就是在不出现inf或者NaN梯度值的情况下尽可能的增大scaler的值
3 一些tips
- 为了保证计算不溢出,首先保证人工设定的常数不溢出。如epsilon,INF等
- Dimension最好是8的倍数:维度是8的倍数,性能最好
- 涉及sum的操作要小心,容易溢出
- 比如softmax操作,建议用官方API,并定义成layer写在模型初始化里
- 如果遇到以下的报错:
-
RuntimeError: expected scalar type float but found c10::Half - 需要手动在tensor上调用.float()
-