Neo4j安装部署及python连接neo4j操作
Neo4j安装部署及python连接neo4j操作
- Neo4j安装和环境配置
安装依赖库:
sudo apt-get install wget curl nano software-properties-common dirmngr apt-transport-https gnupg gnupg2 ca-certificates lsb-release ubuntu-keyring unzip -y
增加Neo4 GPG key:
curl -fsSL https://debian.neo4j.com/neotechnology.gpg.key | sudo gpg --dearmor -o /usr/share/keyrings/neo4j.gpg
添加Neo4j仓库:
echo “deb [signed-by=/usr/share/keyrings/neo4j.gpg] https://debian.neo4j.com stable latest” | sudo tee -a /etc/apt/sources.list.d/neo4j.list
更新仓库源并安装Neo4j:
sudo apt-get update && sudo apt-get install neo4j -y
启用Neo4j;
sudo systemctl enable --now neo4j
允许外部连接:
sudo nano /etc/neo4j/neo4j.conf
修改内容:server.default_listen_address=0.0.0.0
重启服务:
sudo systemctl restart neo4j
修改系统Host文件:
sudo nano /etc/hosts
添加上主机的ip地址和主机名
访问主机或者服务器的7474端口,登陆neo4j
2.实现简单的图数据库
以Kaggle上的arXiv数据集(https://www.kaggle.com/datasets/Cornell-University/arxiv)为实验数据
下载后,文件默认为json文件(arxiv-metadata-oai-snapshot.json)

通过以下代码读取数据:
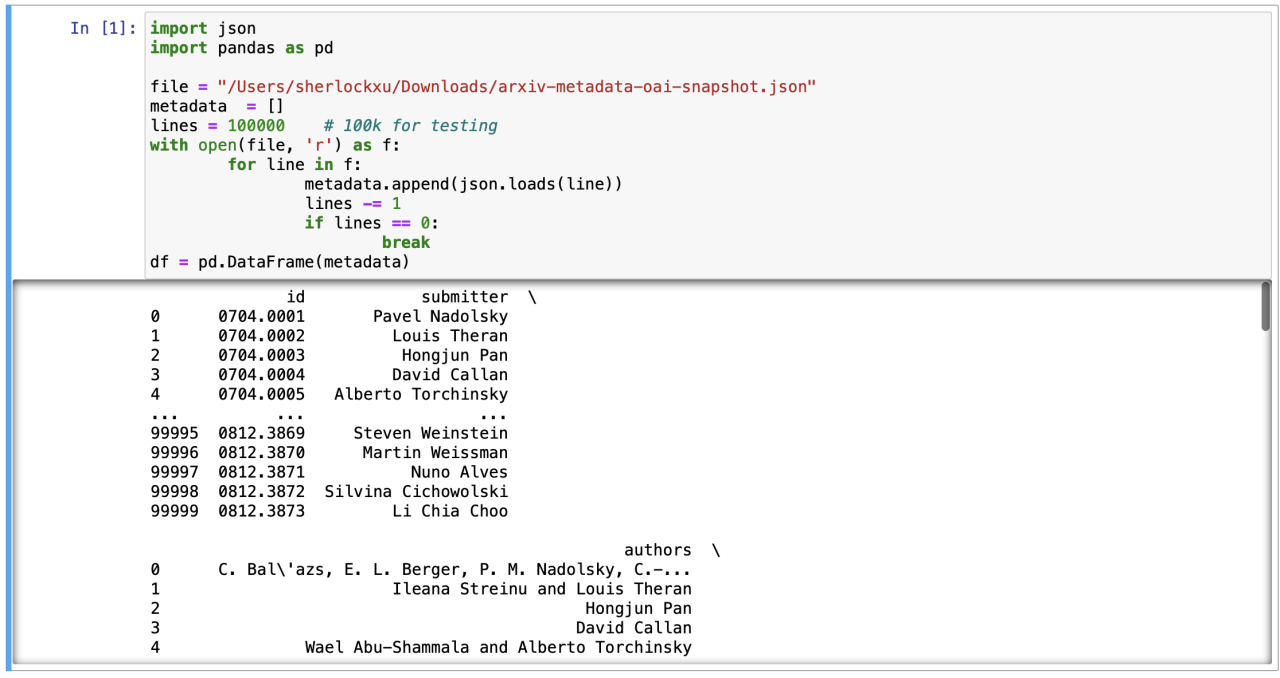
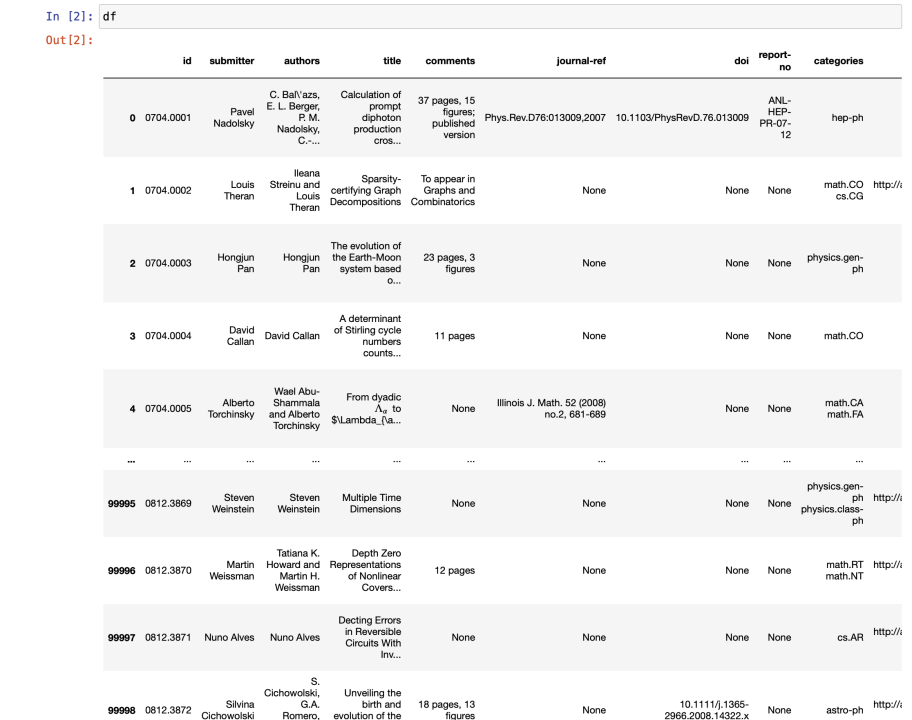
数据结构如下图所示:
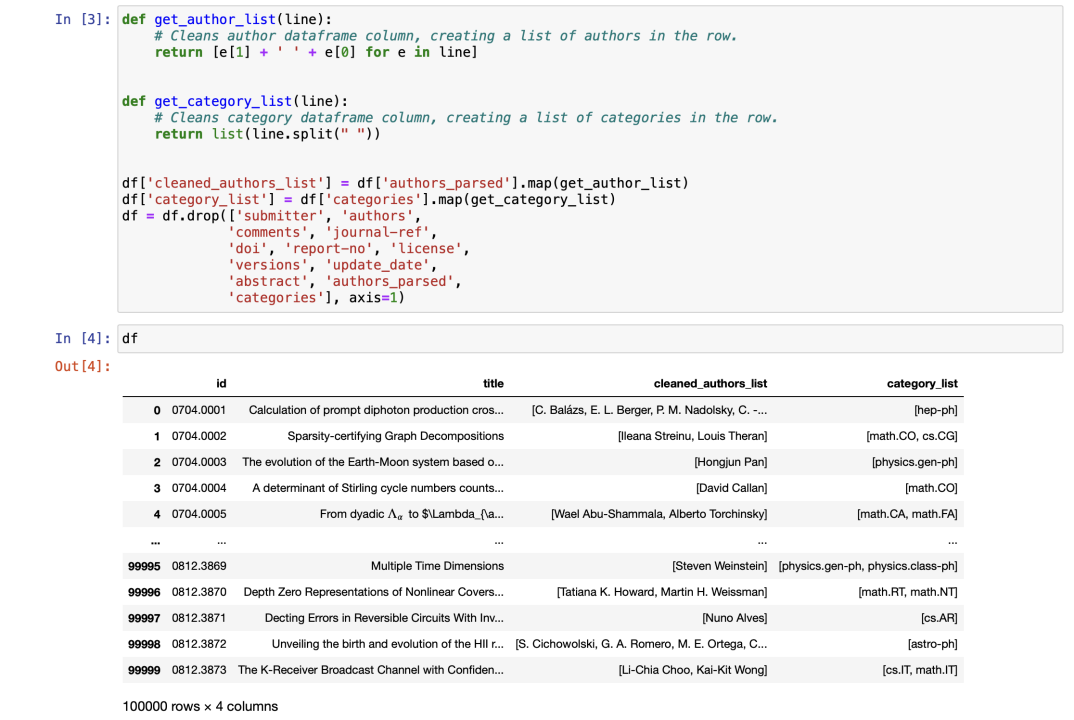
将数据简化,留下id作为唯一索引,主要属性title、authors_parsed、categories:
考虑到数据庞大,测试采用在线版的Neo4j Sandbox,创建的链接可以保留3天
创建一个空白的sanbox,得到Bolt URL及其端口号:
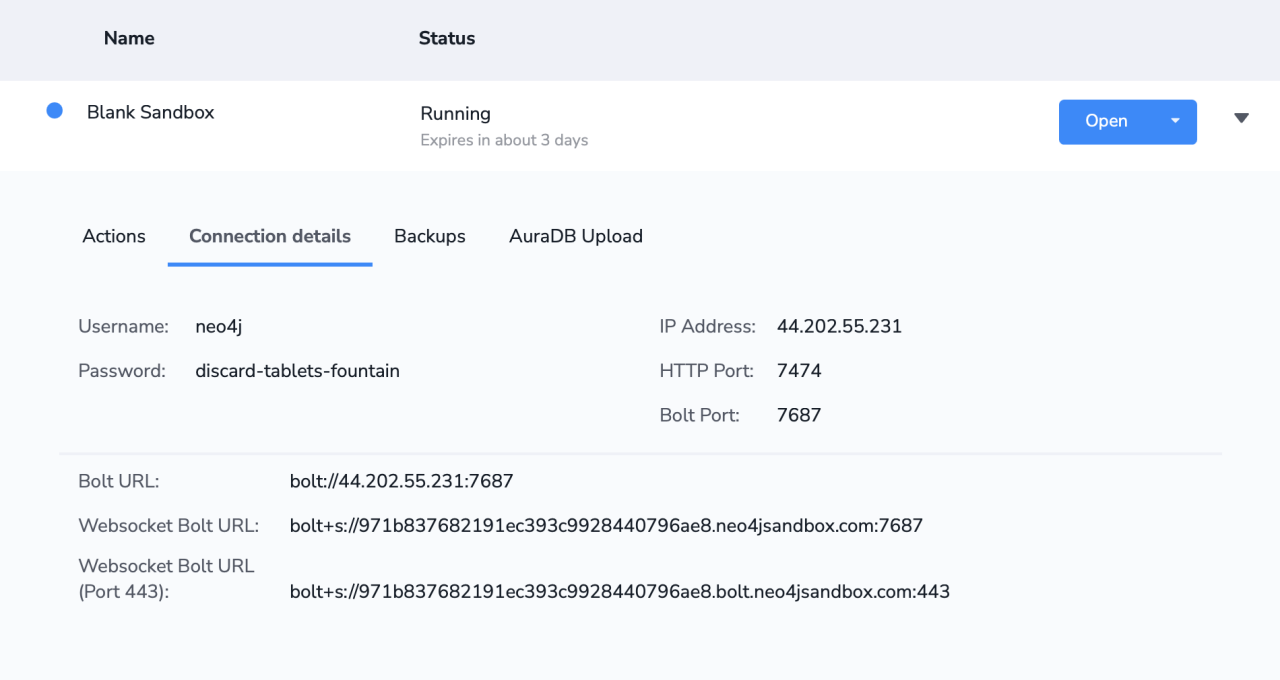
利用python连接到Neo4j并将数据存储到数据库:

在数据库中创建约束,以确保节点不重复,并设置索引:
conn.query(‘CREATE CONSTRAINT papers IF NOT EXISTS FOR (p:Paper) REQUIRE p.id IS UNIQUE’)
conn.query(‘CREATE CONSTRAINT authors IF NOT EXISTS FOR (a:Author) REQUIRE a.name IS UNIQUE’)
conn.query(‘CREATE CONSTRAINT categories IF NOT EXISTS FOR (c:Category) REQUIRE c.category IS UNIQUE’)
创建三个函数,用于为类别和作者节点创建数据框架:

使用以下函数添加paper节点以及所有关系:
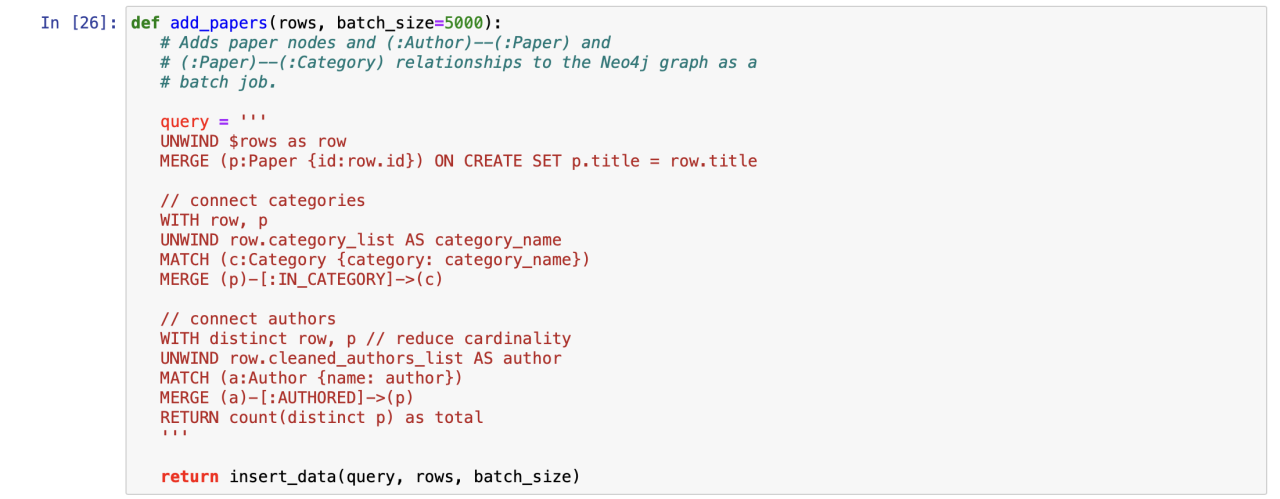
采用批处理将处理加载到neo4j中:

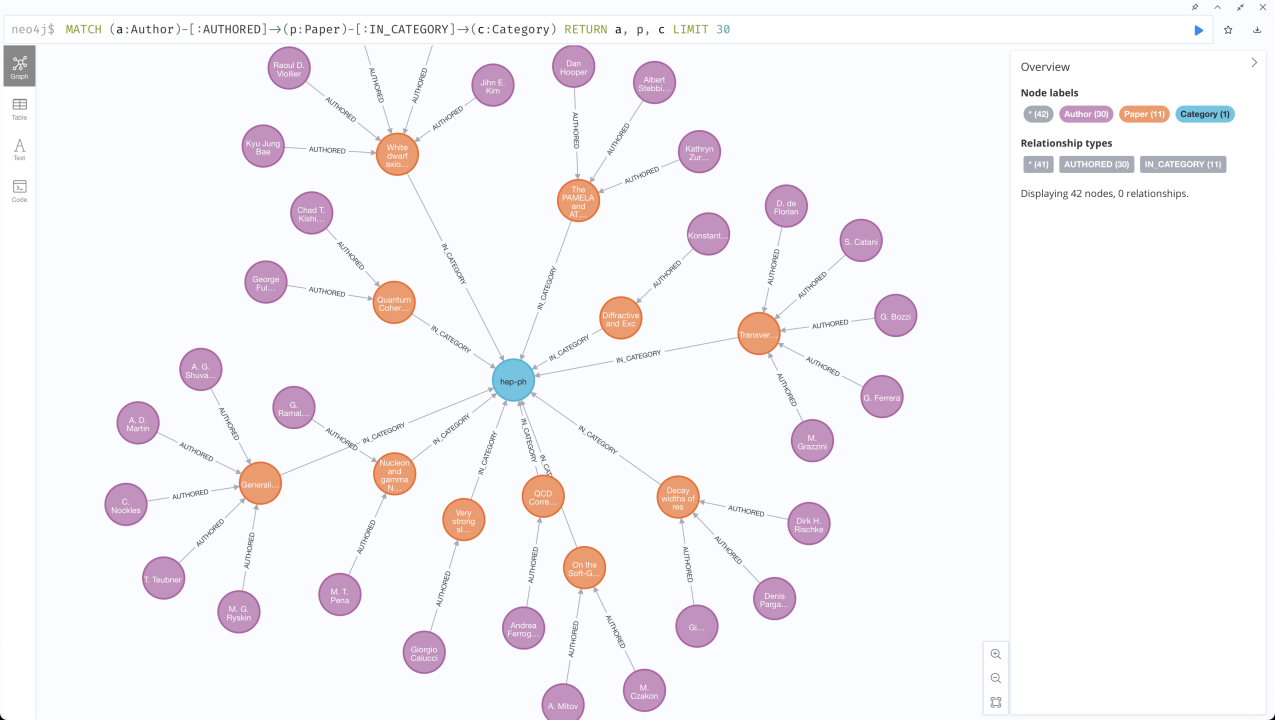
最后,在neo4j Sandbox中执行MATCH操作,得到graph,例如
MATCH (a:Author)-[:AUTHORED]->(p:Paper)-[:IN_CATEGORY]->(c:Category) RETURN a, p, c LIMIT 30
通过以下代码可以直接在python中进行和上面一样的MATCH查询,并返回结果:
query_string = '''
MATCH (a:Author)-[:AUTHORED]->(p:Paper)-[:IN_CATEGORY]->(c:Category) RETURN a, p, c LIMIT 30
'''
top_cat_df = pd.DataFrame([dict(_) for _ in conn.query(query_string)])
top_cat_df.head(20)