CEEMDAN +组合预测模型(CNN-Transfromer + XGBoost)

注意:本模型继续加入 组合预测模型全家桶 中,之前购买的同学请及时更新下载!
往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
VMD + CEEMDAN 二次分解,Transformer-BiGRU预测模型-CSDN博客
独家原创 | 基于TCN-SENet +BiGRU-GlobalAttention并行预测模型-CSDN博客
独家原创 | BiTCN-BiGRU-CrossAttention融合时空特征的高创新预测模型-CSDN博客
基于LSTM网络的多步预测模型_pytorch transformer-CSDN博客
基于1DCNN网络的多步预测模型-CSDN博客
高创新 | CEEMDAN + SSA-TCN-BiLSTM-Attention预测模型-CSDN博客
基于Transformer网络的多步预测模型-CSDN博客
独家原创 | 超强组合预测模型!-CSDN博客
基于TCN网络的多步预测模型-CSDN博客
基于CNN-LSTM网络的多步预测模型-CSDN博客
时空特征融合的BiTCN-Transformer并行预测模型-CSDN博客
组合预测模型思路:使用复杂模型去预测数据的分量特征,因为复杂模型参数量大,适合预测高频复杂分量特征,但是低频分量特征比较简单,要是还用复杂模型的话,就容易过拟合,反而效果不好,所以对于低频分量特征 我们采用简单模型(或者机器学习模型)去预测,然后进行预测分量的重构以实现高精度预测。

创新1:通过CNN卷积池化层降低序列长度,增加数据维度,然后再送入Transformer编码器层进行特征增强,利用多头注意力和其优越的网络结构融合空间特征和时域特征;
创新2:把 CEEMDAN 算法对时间序列分解后的分量通过样本熵的计算进行划分,再分别通过 CNN-Transfromer 模型 和 XGBoost 模型进行组合预测,来实现精准预测。
注意:此次产品,我们还有配套的模型讲解和参数调节讲解!

前言
本文基于前期介绍的电力变压器(文末附数据集),介绍一种综合应用完备集合经验模态分解CEEMDAN与组合预测模型(CNN-Transformer + XGBoost)的方法,以提高时间序列数据的预测性能。该方法的核心是使用CEEMDAN算法对时间序列进行分解,接着利用CNN-Transformer模型和XGBoost模型对分解后的数据进行建模,最终通过集成方法结合两者的预测结果。
电力变压器数据集的详细介绍可以参考下文:
电力变压器数据集介绍和预处理-CSDN博客
1 电力变压器数据CEEMDAN分解与可视化
1.1 导入数据
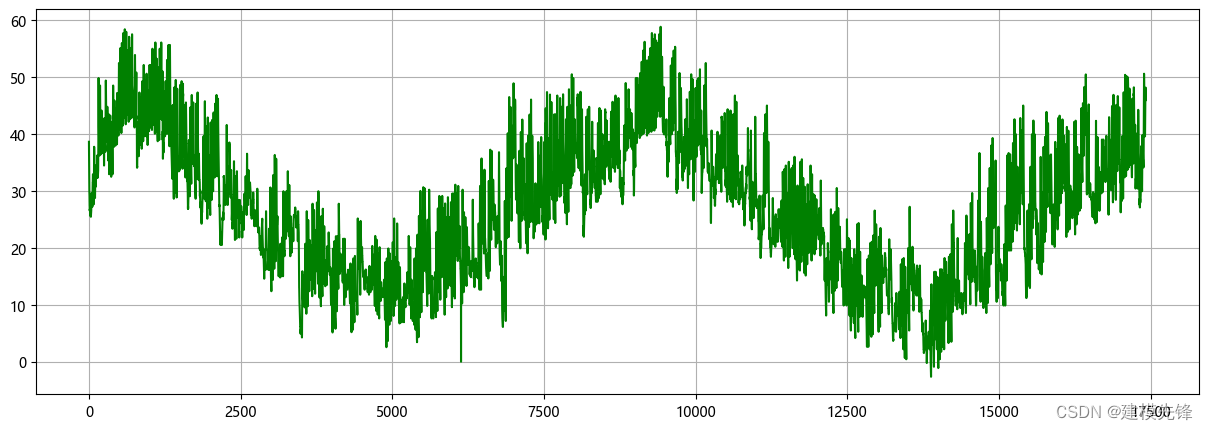
1.2 CEEMDAN分解
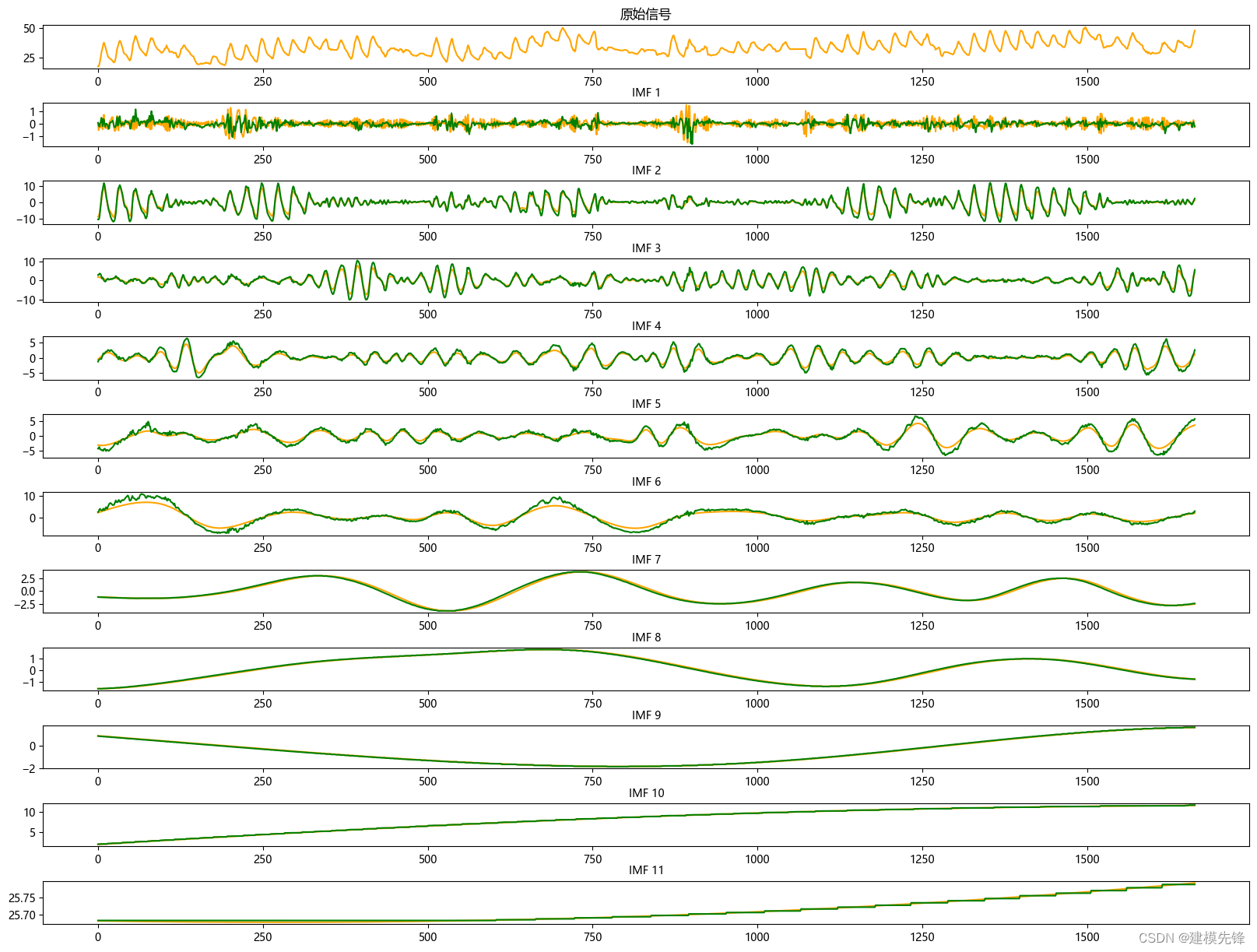
根据分解结果看,CEEMDAN一共分解出11个分量,然后通过计算每个分量的样本熵值进行分析。
样本熵是一种用于衡量序列复杂度的方法,可以通过计算序列中的不确定性来评估其复杂性。样本熵越高,表示序列的复杂度越大。
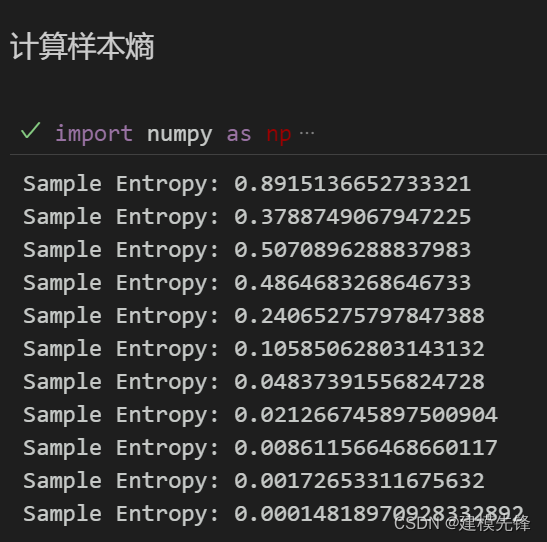
我们大致把前6个高样本熵值复杂分量作为CNN-Transformer模型的输入进行预测,后5个低样本熵值简单分量作为XGBoost模型的输入进行预测.
2 数据集制作与预处理
2.1 划分数据集
按照9:1划分训练集和测试集, 然后再按照前6后5划分分量数据。
在处理LSTF问题时,选择合适的窗口大小(window size)是非常关键的。选择合适的窗口大小可以帮助模型更好地捕捉时间序列中的模式和特征,为了提取序列中更长的依赖建模,本文把窗口大小提升到48,运用CCEMDAN-CNN-Transformer模型来充分提取前6个分量序列中的特征信息。
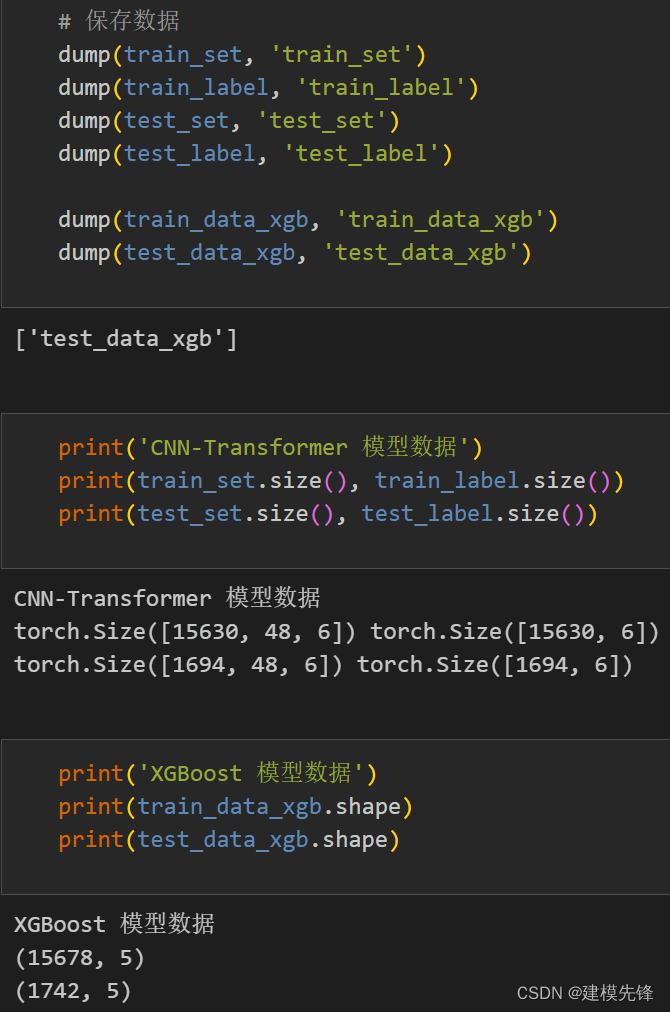
分批保存数据,用于不同模型的预测
3 基于CEEMADN的组合预测模型
3.1 定义CNN-Transformer网络模型

3.2 设置参数,训练模型

50个epoch,MSE 为0.002122,CNN-Transformer预测效果显著,模型能够充分提取时间序列的时序特征和空间特征,收敛速度快,性能优越,预测精度高,适当调整模型参数,还可以进一步提高模型预测表现。
注意调整参数:
-
可以适当增加CNN层数和每层的维度,微调学习率;
-
调整Transformer编码器层数、多头注意力头数、注意力维度数,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
保存训练结果和预测数据,以便和后面XGBoost模型的结果相组合。
4 基于XGBoost的模型预测
传统机器学习模型 XGBoost 教程如下:
超强预测算法:XGBoost预测模型-CSDN博客
数据加载,训练数据、测试数据分组,5个分量,划分5个数据集
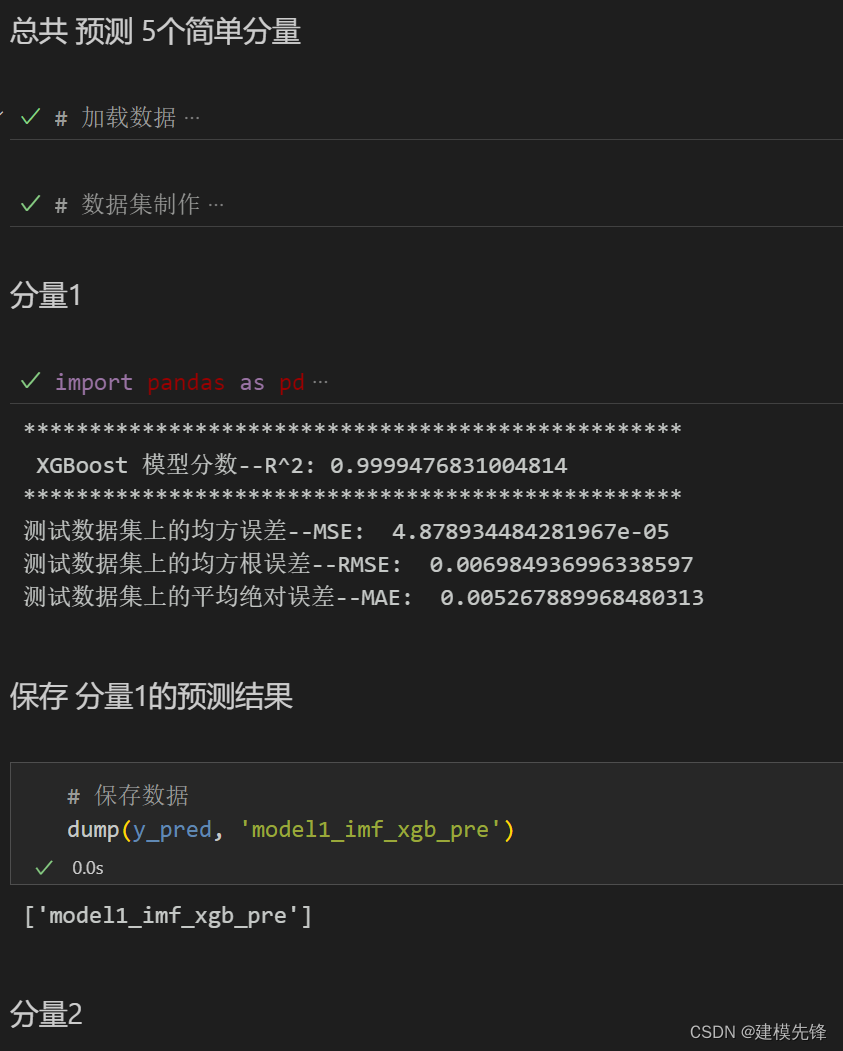
保存预测的数据,其他分量预测与上述过程一致,保留最后模型结果即可。
5 结果可视化和模型评估
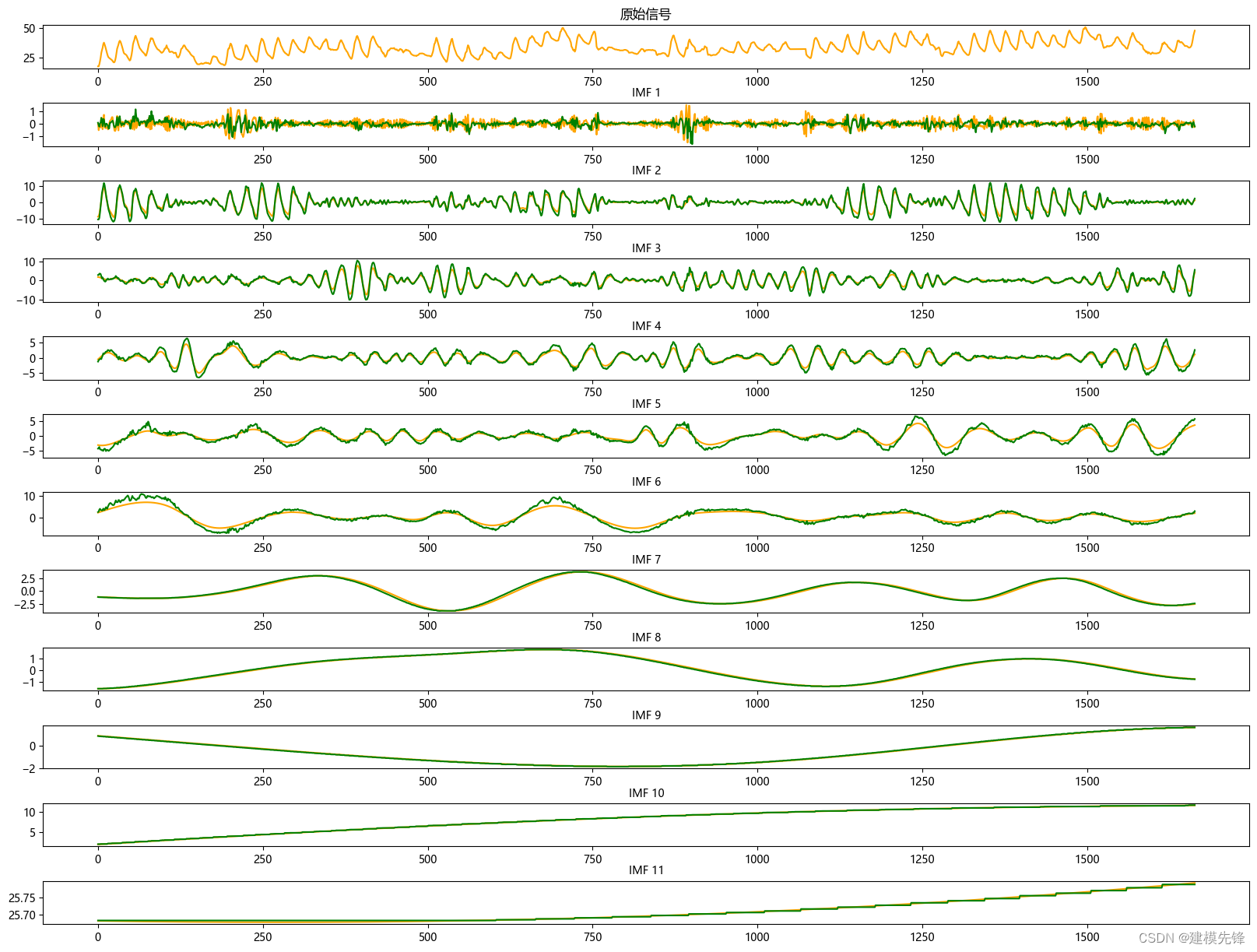
5.1 分量预测结果可视化
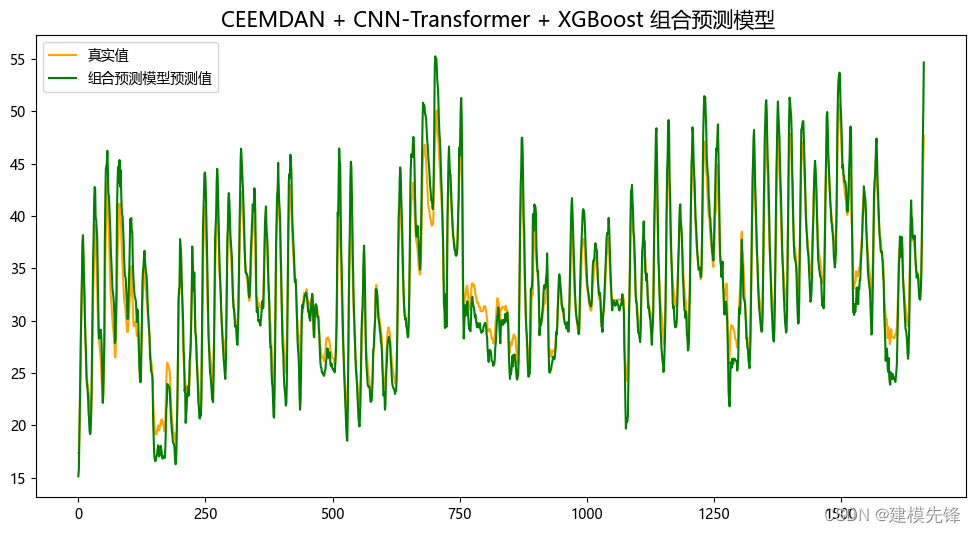
5.2 组合预测结果可视化
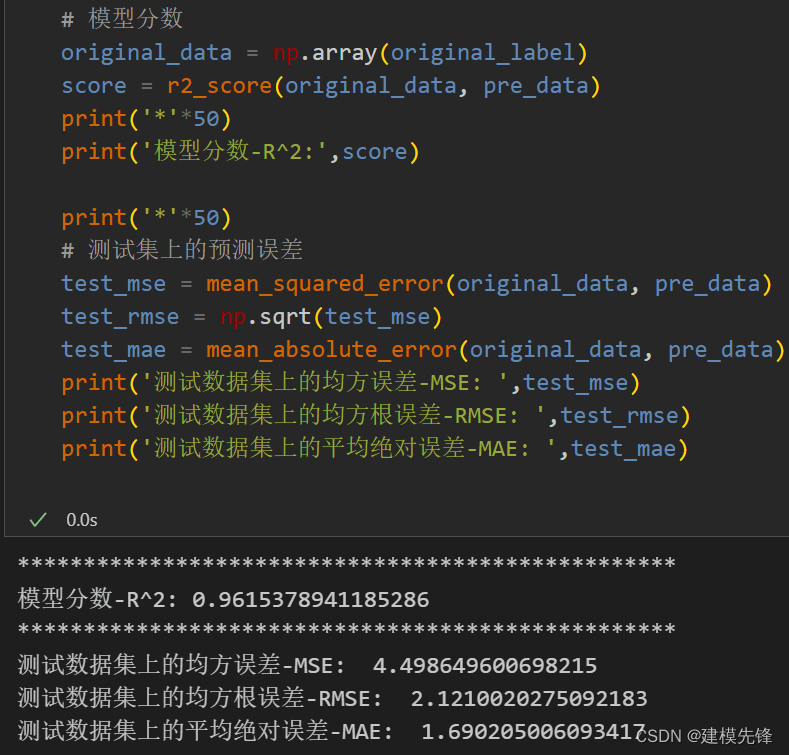
5.3 模型评估
由分量预测结果可见,前6个复杂分量在CNN-Transformer预测模型下拟合效果良好,后5个简单分量在XGBoost模型的预测下,拟合程度特别好,组合预测效果显著!
代码、数据如下:
对数据集和代码感兴趣的,可以关注最后一行
# 加载数据
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#代码和数据集:https://mbd.pub/o/bread/mbd-ZZ6ZmJtq