学习和分析各种数据结构所要掌握的一个重要知识——CPU的缓存利用率(命中率)
什么是CPU缓存利用率(命中率),我们首先要把内存搞清楚。
硬盘是什么,内存是什么,高速缓存是什么,寄存器又是什么?
我们要储存数据就要运用到上面的东西。首先里面的硬盘是可以无电存储的,而后面的内存、缓存、寄存器都是有电存储的。无电存储就是不需要通电,有电就是需要持续通电才能将我们的数据存储到对应的存储器上面。
但是我们的从硬盘里面读取数据时间就相对较慢,但是我们从内存里面读取就相对较快一些,其次是缓存,再是寄存器。
因为我们CPU的算率是十分快的,一秒是亿的单位级。如果我们直接让CPU从硬盘里面找要计算的东西,肯定就不行的。相当于我们长跑的时候停下来去场外取一杯水一样慢。所以我们要把水放“近”一点,所以我们的是CPU从内存里面取数据的吗?也不是,还是比较慢,所以我们还有一个叫高速缓存的东西。CPU就从高速缓存里面取我们要的数据。
如果CPU在缓存里面找到了需要的数据,就叫缓存命中,那么就直接拿取这个数据;如果我们的CPU在缓存里面没有找到所需要的数据,就叫缓存不命中,那么就要从内存里面加载相应的数据。具体加载会只调用一个,它是调用连续一段的内存,将其全部加载过去。而这个加载的长度。而加载与CPU的字长(地址线的数量)有关,现在CPU字长一般是32位或者64位。
例如有一个数组:
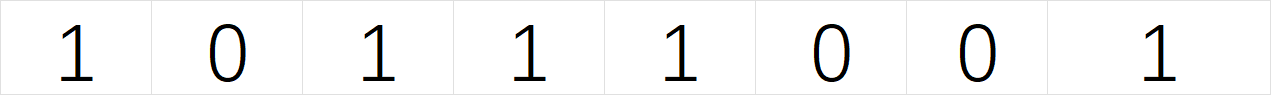
那么不会只加载1,而是可能将10111001所有的全部加载到高速缓存里面。然后我们的CPU会读取第一个数据,如果命中了就继续往下一个高速缓存位置进行读取。如果没有命中就重复上述操作。
缓存命中率(利用率)
那么CPU的缓存命中率/利用率就是这个。当加载一组的数据然后进行读取时,如果是数组,那么它的缓存命中率就会很高,因为它的内存是连续的,加载到高速缓存上面也是连续的,所以第一个数据命中后,后面的数据会继续命中。但是如果是链表的话,它的内存是分散的,那么就会出现第一个内存命中了,但是后续的内存不会命中的情况,那么我们就要进行多次的内存加载。那么时间就会大打折扣。
这里提一下寄存器,寄存器的内存很小,一般只能存储一个数据,用来对一个数据进行操作。例如我们返回函数值就是返回寄存器里面的值,我们进行数据的加减也是基于寄存器的。它和CPU之间的读取速率是最快的。