数仓开发:DIM层数据处理
一、了解DIM层
这个就是数仓开发的分层架构

我们现在是在DIM层,从ods表中数据进行加工处理,导入到dwd层,但是记住我们依然是在DIM层,而非是上面的ODS和DWD层。
二、处理维度表数据
①先确认hive的配置
-- 开启动态分区方案
-- 开启非严格模式
set hive.exec.dynamic.partition.mode=nonstrict;
-- 开启动态分区支持(默认true)
set hive.exec.dynamic.partition=true;
-- 设置各个节点生成动态分区的最大数量: 默认为100个 (一般在生产环境中, 都需要调整更大)
set hive.exec.max.dynamic.partitions.pernode=10000;
-- 设置最大生成动态分区的数量: 默认为1000 (一般在生产环境中, 都需要调整更大)
set hive.exec.max.dynamic.partitions=100000;
-- hive一次性最大能够创建多少个文件: 默认为10w
set hive.exec.max.created.files=150000;
-- hive压缩
-- 开启中间结果压缩
set hive.exec.compress.intermediate=true;
-- 开启最终结果压缩
set hive.exec.compress.output=true;
-- 写入时压缩生效
set hive.exec.orc.compression.strategy=COMPRESSION;
②对于各个表数据进行处理
1、例如:拉平处理

2、例如:将分类编号替换为一二三级分类ID、编码和名称
关联分类表,将商品表中的category_no 对应的是分类表中的三级分类

3、例如:有很多条件
门店日清商品表处理
日清商品,不满足以下要求的商品需要清理掉不再入库,主要是一些生鲜类和现做的食物
-
一切以实物为标准,不允许变色、不新鲜产品入库。
-
骨类入库存放时间不得超过24小时。
-
上冰台的所有促销品当天尽量要做到日清,对于上冰台的当日未销售完的产品,未变色,不影响第二天销售的可以入库。
-
对于化冻的禽副产品当日必须销售完毕,猪副产品根据品相颜色以实物相论。
从门店商品表中进行条件过滤,过滤出日清商品,然后进行保存
三、选择数据库,PostGreSql
①PostGreSql的介绍及其优势
PostgreSQL是一个强大的开源数据库系统,提供了诸如可靠性、功能性、可扩展性等特性,是企业级应用的理想选择。
以下是PostgreSQL的一些主要优势:
1.完全兼容ACID(原子性、一致性、隔离性、持久性):PostgreSQL支持事务的完整性和可靠性。
2.支持标准SQL:PostgreSQL遵循SQL标准,允许复杂和标准的SQL查询。
3.支持对象关系的数据库:PostgreSQL支持类似于Oracle的表空间、模式和数据库表的
概念。
4.强大的数据类型支持:PostgreSQL支持大对象、数组、范围查询等高级数据类型。
5.支持NoSQL数据类型:PostgreSQL的JSONB数据类型允许存储和查询NoSQL风格的数据。
6.强大的扩展性:PostgreSQL提供了扩展插件,如PostGIS(地理信息处理)、pg_partman(分区管理)
7.多版本并发控制:PostgreSQL支持多版本并发控制(MVCC),提供了一种高效的读写操作方式。
8.高可靠性:PostgreSQL提供了热备份、流复制等高可靠性特性。
9.开源免费:PostgreSQL是开源免费的,有着活跃的开发者社区和广泛的应用场景。
10.安全性:PostgreSQL提供了强大的安全特性,包括ACL、SSL、密码加密等。以下是一个简单的PostgreSQL连接代码示例(使用Python的psycopg2库):
②PostGreSql的基本使用
1、datagrip配置

2、基本数据操作
-- 数据表的创建
create table tb_user(
id int,
name varchar(20),
age int,
gender varchar(20)
);-- 数据表的写入
insert into tb_user values(1,'张三',20,'男');-- 查询数据
select * from tb_user;
select count(*) from tb_user;
select gender,sum(age) from tb_user group by gender;
select id,sum(age) over(order by id) from tb_user;with tb as(
select * from tb_user
)
select * from tb;
四、hive表数据导出PostGreSql
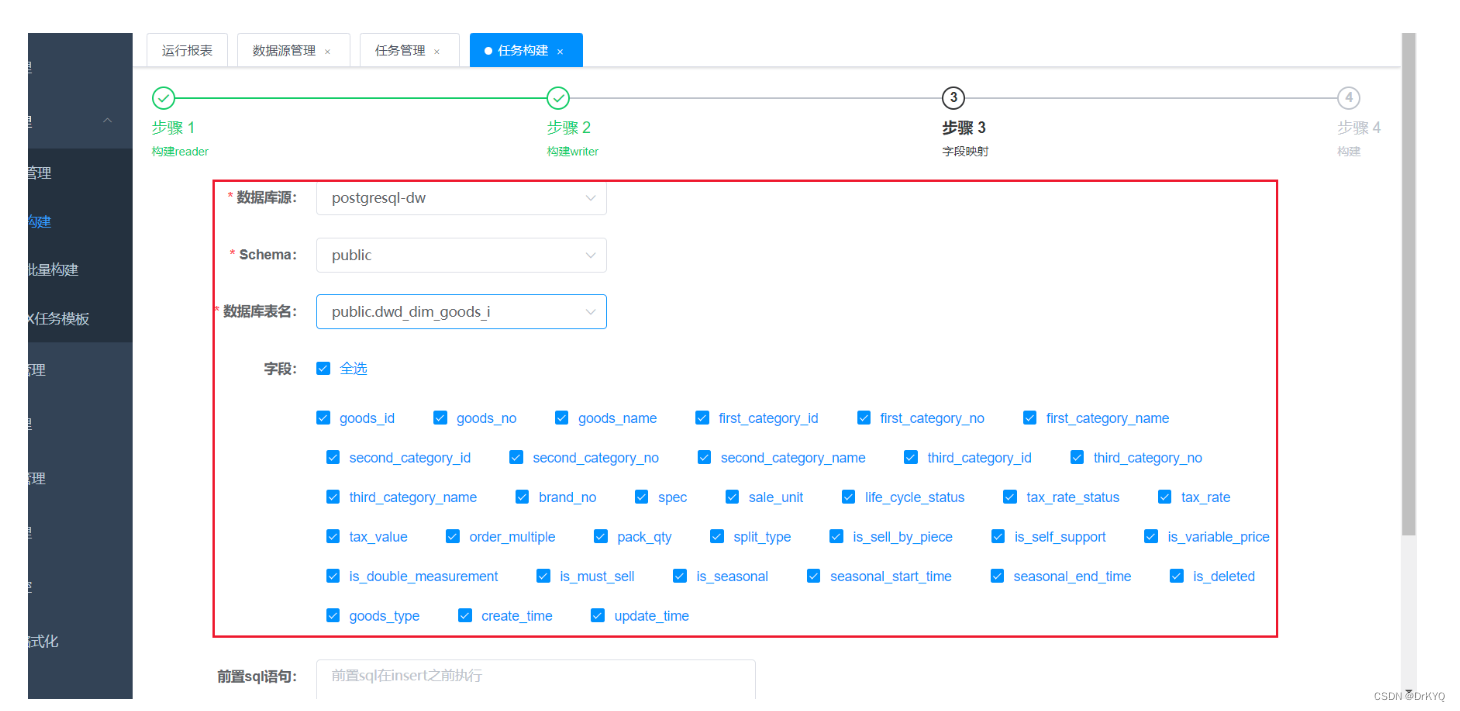
①需要再postGreSQL中创建对应表保存数据,参考建表语句文档
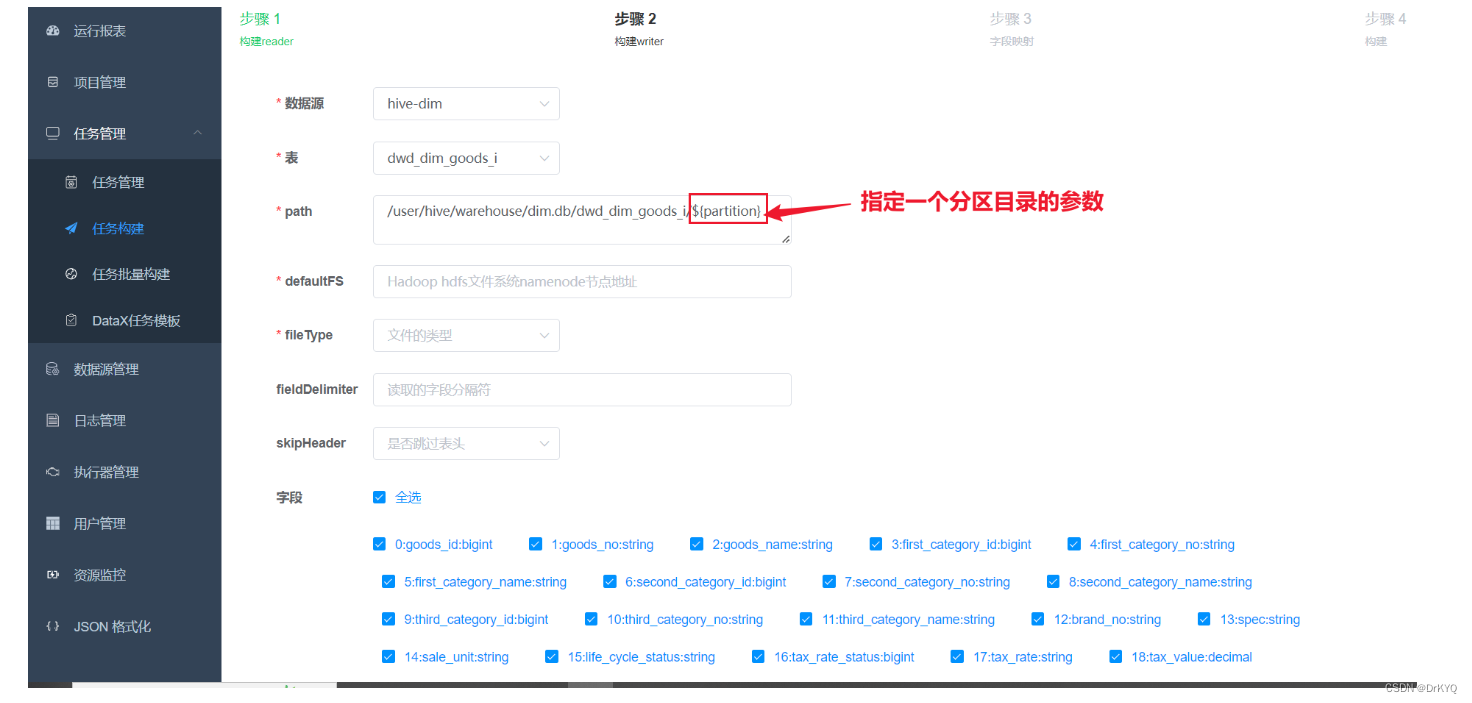
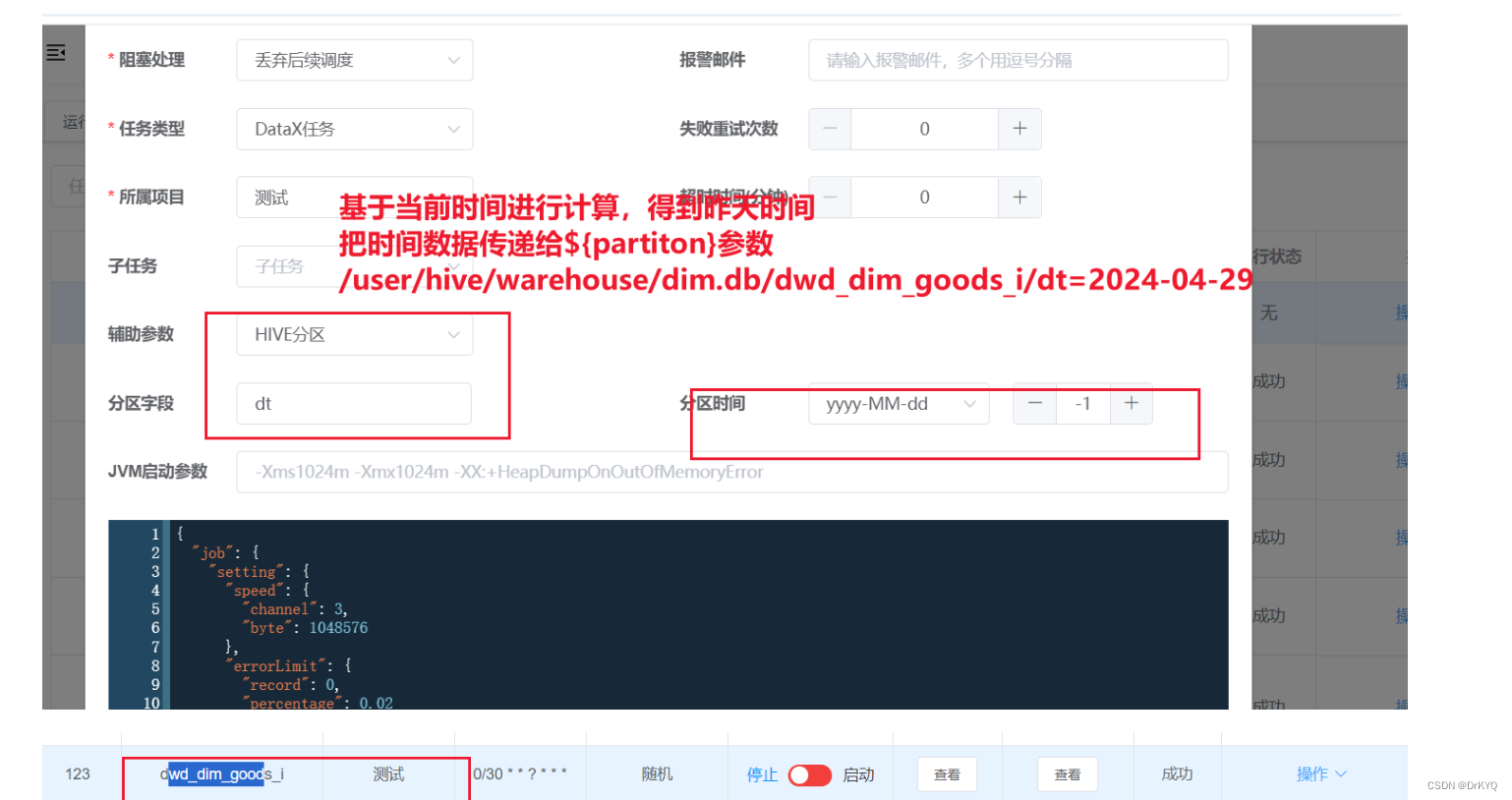
②配置datax任务,启动datax-web服务 /export/server/datax-web-2.1.2/bin/start-all.sh