Scrapy框架内存泄漏问题及解决
说明:仅供学习使用,请勿用于非法用途,若有侵权,请联系博主删除
作者:zhu6201976
一、问题背景及原因
官方文档:Debugging memory leaks — Scrapy 2.11.1 documentation
Scrapy是一款功能强大的网络爬虫框架,但许多使用者(包括一些经验丰富的爬虫开发者)在开发过程中往往只注重功能的实现,而忽略了代码的性能、优雅和健壮性。这导致了代码可读性差、重复冗余和高耦合等问题。举例如下:
- 忽视算法的时间和空间复杂度,导致代码中存在多层嵌套for循环。经过重构和优化后,可以减少一层循环,使代码性能直接提升10倍以上。
- 忽略代码模块和公共代码组件的抽取,造成大量重复冗余的代码。频繁的复制粘贴使代码难以理解。
- 缺乏面向对象思维,常常采用面向过程的方式编写逻辑,导致代码复用性差,维护成本高。
- 不关注硬件成本,未充分利用Python中的生成器,导致项目运行过程中占用大量CPU和内存。
- 随意进行深拷贝和浅拷贝变量,操作大数组,导致内存占用过高。
- 随意进行变量引用和传递,导致Python解释器的垃圾回收机制无法正常回收变量。
- 在构造Request请求时,通过meta或cb_kwargs参数传递不可变类型数据,导致内存占用过高。
- 代码中构造海量请求,导致请求队列内存高占用。
- 不关闭释放资源。如爬虫中打开了一些资源(文件、数据库连接等),但在使用完后未正确关闭,这些资源会一直存在于内存中,导致内存泄漏。
- 随意使用不成熟、过时的第三方库。某些第三方库可能存在内存泄漏问题,需要注意及时更新和检查。
以上问题,导致爬虫项目随着时间的推移,CPU和内存持续增长,最终导致电脑的卡顿卡死,或被系统因OOM(out of memory)问题Kill。因此,这些问题必须引起高度重视。
二、通用解决方案
为了解决以上问题,开发者可以采取一系列有效的措施,以确保Scrapy框架的爬虫项目能够长期稳定运行。
首先,优化算法的时间和空间复杂度至关重要。在编写代码时,应该深入了解算法的性能特点,并尽量避免多层嵌套的for循环。通过重构和优化代码,可以大幅提升代码的执行效率,减少CPU和内存的消耗。
其次,重视代码的模块化和公共组件的抽取。合理划分代码模块,并提取可复用的公共代码片段,有助于降低代码的重复冗余,提高代码的可读性和可维护性。这样不仅使得代码更加清晰易懂,也有利于后期的代码维护和扩展。
此外,采用面向对象的编程方式可以提高代码的复用性和可维护性。通过定义类和对象,将代码结构化地组织起来,有助于降低代码的耦合度,并简化代码的设计和实现过程。
对于硬件资源的利用,开发者应当充分发挥Python中的生成器和迭代器的优势。合理使用生成器可以大幅减少内存的占用,并提高程序的运行效率。此外,及时关闭和释放资源也是保障程序稳定运行的重要手段。确保在爬虫程序中使用完资源后,及时关闭文件、数据库连接等资源,以防止资源泄漏导致的内存占用过高。
最后,要警惕使用不成熟或过时的第三方库可能存在的内存泄漏问题。定期检查并更新第三方库版本,以确保项目的稳定性和安全性。
三、Too Many Requests的解决
这个问题比较特殊,本质上不属于代码及开发者的问题。可能的原因在于Scrapy框架中请求队列的大小无法由开发者控制。在Scrapy的源码中,可能存在一个未经有效调度的无限大小内存队列,导致大量请求被存储在队列中,从而使内存占用率急剧上升。
针对这个问题,有一个相对简单的解决方案,即将job task本地化。将之前存储在内存中的大量请求持久化到本地文件中。Scrapy官方提供了一种解决方案:Jobs: pausing and resuming crawls — Scrapy 2.11.1 documentation
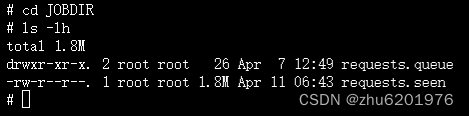
在框架中的具体使用方法也很简单,只需在启动爬虫时添加一个额外参数,告知Scrapy框架将海量请求持久化到本地存储中即可。
scrapy crawl somespider -s JOBDIR=JOBDIR运行爬虫后,会在当前目录生成一个JOBDIR,用于存储队列中的请求: