利用HIVE的窗口函数进行SQL查询中出现的问题记录


1、问题复现

--完整SQL
selectsti.stu_id,sti.stu_name,concat_ws(",",collect_set(ci.course_name)) over(partition by sti.stu_id)
fromstudent_info sti
left joinscore_info sci
onsti.stu_id=sci.stu_id
left joincourse_info ci
onsci.course_id=ci.course_id
limit 132、错误分析
在Hive的SELECT子句中使用窗口函数时,需要确保窗口规范(OVER子句)中的所有非聚合列都出现在GROUP BY子句中。因为Hive需要能够确定如何对数据进行分组以应用窗口函数。
在提供的查询中,使用了collect_list函数来收集每个学生的课程名称,并希望使用窗口函数来实现分区。然而,由于ci.course_name没有出现在GROUP BY子句中,Hive无法确定如何对数据进行分组。
3、解决措施
为了解决这个问题,我在这里尝试修改查询,将ci.course_name包含在GROUP BY子句中。再次运行还是报错,于是查询了这个collect_list函数,由于collect_list函数本身就是根据sti.stu_id和ci.course_name进行分组的,所以实际上我们不需要在GROUP BY子句中重复这些列,所以最后修改为下面的SQL后运行成功:
SELECTsti.stu_id,sti.stu_name,concat_ws(",", collect_list(ci.course_name)) AS stu_courses_sum
FROMstudent_info sti
LEFT JOINscore_info sci
ONsti.stu_id = sci.stu_id
LEFT JOINcourse_info ci
ONsci.course_id = ci.course_id
GROUP BYsti.stu_id, sti.stu_name
LIMIT 13;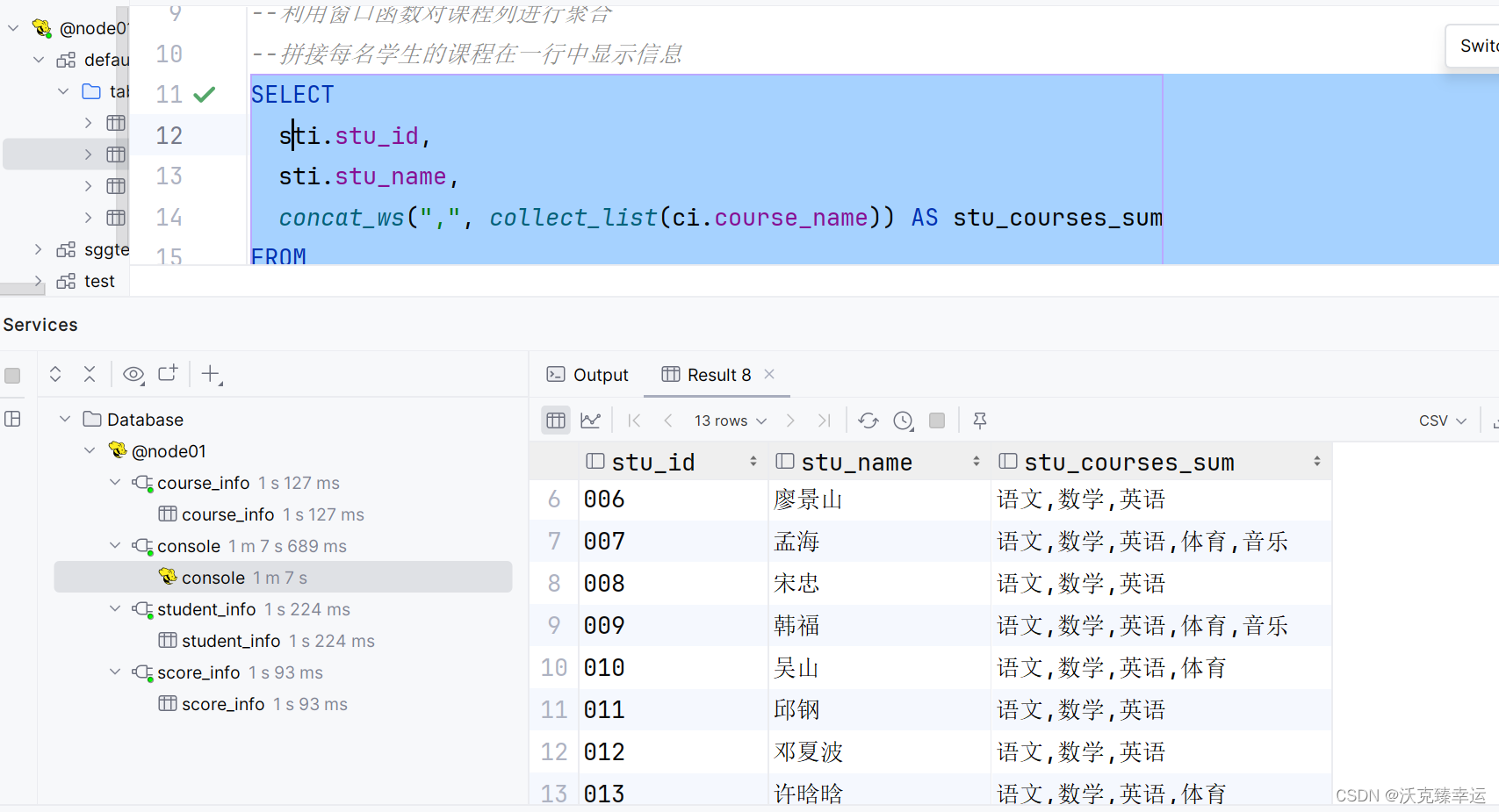
4、思考
在此查询中分别测试了大小表顺序不同的join,发现大表在前也不一定查询效率低,这次查询时大表在前查询速度比在后要快一些。我分析原因可能时on后的过滤条件起到了作用。