【生成对抗网络GAN】一篇文章讲透~
目录
引言
一、生成对抗网络的基本原理
1 初始化生成器和判别器
2 训练判别器
3 训练生成器
4 交替训练
5 评估和调整
二、生成对抗网络的应用领域
1 图像生成与编辑
2 语音合成与音频处理
3 文本生成与对话系统
4 数据增强与隐私保护
三、代码事例
四、生成对抗网络面临的挑战
1 模式崩溃问题
2 训练不稳定
3 评估标准不统一
五、生成对抗网络的未来发展趋势
1 理论基础的完善
2 模型架构的创新
3 应用领域的拓展
4 隐私保护与安全性提升
总结
引言
生成对抗网络(GAN,Generative Adversarial Networks)是近年来深度学习领域最为热门的研究方向之一。它的核心思想源于博弈论中的零和博弈,通过构建两个相互对抗的网络——生成器和判别器,来不断优化生成数据的质量,直至达到难以区分的程度。本文旨在深入探讨生成对抗网络的基本原理、应用领域、面临的挑战以及未来的发展趋势,以期为相关领域的研究人员和实践者提供有价值的参考。
一、生成对抗网络的基本原理
可以看这篇论文Generative Adversarial Networks
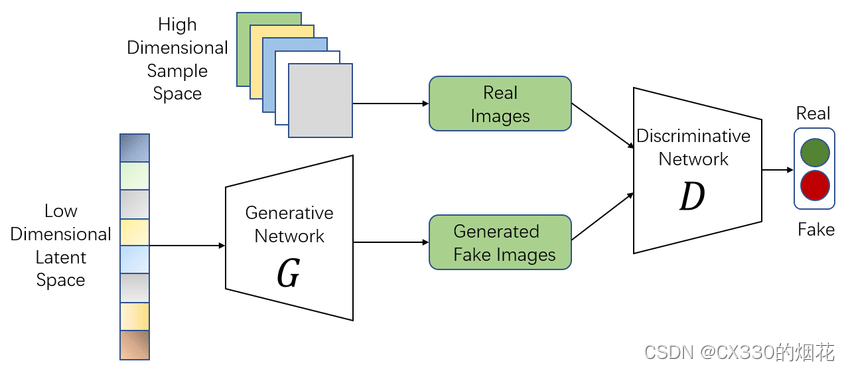
1 初始化生成器和判别器
首先,需要定义并初始化生成器和判别器的网络结构。生成器的任务是接收一个随机噪声向量作为输入,并尝试生成逼真的数据样本;而判别器的任务是接收来自生成器和真实数据的输入,并尝试区分它们。
2 训练判别器
在训练过程中,判别器首先会接收到一批真实数据,并尝试正确分类这些数据为“真实”。接着,生成器会生成一批数据,判别器再尝试区分这些数据与真实数据。通过反向传播算法,优化判别器的参数以提高其对生成数据和真实数据的区分准确性。
3 训练生成器
生成器的目标是生成尽可能逼真的数据,以欺骗判别器。因此,生成器在训练过程中会尝试生成数据,使得判别器无法区分这些数据与真实数据。同样,通过反向传播算法,优化生成器的参数以提高其生成数据的质量。
4 交替训练
生成器和判别器的训练是交替进行的,即在一个迭代中先训练判别器,然后训练生成器。这种交替训练的方式使得两个网络在对抗中不断提升各自的能力。
5 评估和调整
在训练过程中,需要定期评估生成器和判别器的性能。如果生成器生成的数据质量达到预期,或者判别器无法再区分生成数据和真实数据,则可以认为GAN已经训练完成。否则,需要根据评估结果调整网络结构或训练参数,以进一步优化GAN的性能。
二、生成对抗网络的应用领域
生成对抗网络具有广泛的应用领域,包括但不限于以下几个方面:
1 图像生成与编辑
GAN在图像生成和编辑领域取得了显著成果,可以生成高质量的图像、实现图像风格迁移、超分辨率重建等任务。
2 语音合成与音频处理
GAN也可用于语音合成、音频降噪、语音转换等任务,为语音技术领域带来新的突破。
3 文本生成与对话系统
GAN在文本生成和对话系统方面也有广泛应用,可以生成具有连贯性和多样性的文本内容,提高对话系统的性能。
4 数据增强与隐私保护
GAN可用于生成新的训练样本,以缓解数据稀缺问题;同时,通过生成具有隐私保护功能的虚假数据,可以在一定程度上保护用户隐私。
三、代码事例
生成对抗网络(GAN)的实现需要一定的编程基础和对深度学习框架的熟悉。以下是一个简单的生成对抗网络的实现示例,使用Python和TensorFlow框架。请注意,这只是一个基本的示例,用于说明GAN的基本结构和训练过程。在实际应用中,可能需要根据具体任务和数据集进行适当的修改和优化。
import tensorflow as tf
from tensorflow.keras import layers, models# 定义生成器模型
def build_generator(latent_dim):model = models.Sequential()model.add(layers.Dense(256, input_dim=latent_dim))model.add(layers.LeakyReLU(alpha=0.01))model.add(layers.BatchNormalization(momentum=0.8))model.add(layers.Dense(512))model.add(layers.LeakyReLU(alpha=0.01))model.add(layers.BatchNormalization(momentum=0.8))model.add(layers.Dense(1024))model.add(layers.LeakyReLU(alpha=0.01))model.add(layers.BatchNormalization(momentum=0.8))model.add(layers.Dense(784, activation='tanh'))return model# 定义判别器模型
def build_discriminator():model = models.Sequential()model.add(layers.Dense(512, input_dim=784))model.add(layers.LeakyReLU(alpha=0.01))model.add(layers.Dropout(0.3))model.add(layers.Dense(256))model.add(layers.LeakyReLU(alpha=0.01))model.add(layers.Dropout(0.3))model.add(layers.Dense(1, activation='sigmoid'))return model# 设置超参数
latent_dim = 100# 构建生成器和判别器模型
generator = build_generator(latent_dim)
discriminator = build_discriminator()# 构建GAN模型
gan_input = tf.keras.Input(shape=(latent_dim,))
img = generator(gan_input)
discriminator.trainable = False
validity = discriminator(img)
gan = tf.keras.models.Model(gan_input, validity)# 编译GAN模型
gan.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])# 编译判别器模型
discriminator.trainable = True
discriminator.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])# 定义生成器和判别器的训练步骤
def train_step(epoch, batch_i, batch_size, X_train):# 选择随机噪声输入noise = np.random.normal(0, 1, (batch_size, latent_dim))# 生成图像gen_imgs = generator.predict(noise)# 标签平滑valid_y = np.ones((batch_size, 1))fake_y = np.zeros((batch_size, 1))# 训练判别器d_loss_real = discriminator.train_on_batch(X_train[batch_i*batch_size:(batch_i+1)*batch_size], valid_y)d_loss_fake = discriminator.train_on_batch(gen_imgs, fake_y)d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)# 训练生成器noise = np.random.normal(0, 1, (batch_size, latent_dim))valid_y = np.ones((batch_size, 1))g_loss = gan.train_on_batch(noise, valid_y)# 打印进度print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))# 加载或生成训练数据(这里以MNIST数据集为例)
from tensorflow.keras.datasets import mnist
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 784).astype('float32') / 127.5 - 1.0# 训练GAN
epochs = 10000
batch_size = 256
sample_interval = 500for epoch in range(epochs):# 遍历整个数据集for i in range(0, X_train.shape[0], batch_size):train_step(epoch, i, batch_size, X_train)# 如果达到采样间隔,则保存生成的图像样本if epoch % sample_interval == 0:noise = np.random.normal(0, 1, (1, latent_dim))gen_imgs = generator.predict(noise)# 将生成的图像保存到文件中(这里省略了保存图像的代码)
首先,确保已经安装了TensorFlow库。
接下来,我们来实现一个简单的GAN。这个例子将使用一个简单的多层感知机(MLP)作为生成器和判别器。
请注意,这个示例仅用于说明GAN的基本结构和训练过程,并不是一个高性能的GAN实现。在实际应用中,您可能需要对模型架构、超参数、训练策略等进行更多的优化和调整。此外,还可以使用更高级的GAN变体,如DCGAN、WGAN等,以进一步提高生成图像的质量和多样性。
四、生成对抗网络面临的挑战
尽管生成对抗网络在多个领域取得了显著成果,但仍面临一些挑战:
1 模式崩溃问题
生成对抗网络在训练过程中可能出现模式崩溃现象,即生成器只能生成有限的几种样本,而无法覆盖真实数据的全部模式。
2 训练不稳定
GAN的训练过程往往不稳定,容易受到初始化、超参数设置等因素的影响,导致训练失败或性能不佳。
3 评估标准不统一
目前尚未形成统一的GAN评估标准,使得不同方法的性能比较变得困难。
五、生成对抗网络的未来发展趋势
随着深度学习技术的不断发展,生成对抗网络有望在以下几个方面取得突破:
1 理论基础的完善
未来研究将更加注重GAN的理论基础,通过深入研究其数学原理和收敛性等问题,提高GAN的稳定性和可靠性。
2 模型架构的创新
研究人员将继续探索新的模型架构,以提高GAN的生成质量和效率,同时降低计算成本。
3 应用领域的拓展
GAN的应用领域将进一步拓展,涵盖更多领域和问题,如视频生成、3D建模、医学图像处理等。
4 隐私保护与安全性提升
未来GAN将在隐私保护和安全性方面取得更多进展,以应对日益严峻的数据安全和隐私保护问题。
总结
总之,生成对抗网络作为一种强大的深度学习技术,具有广阔的应用前景和巨大的发展潜力。通过不断深入研究和创新实践,我们有望在未来实现更多的突破和进步。