多模态(三)--- BLIP原理与源码解读
1 BLIP简介
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
传统的Vision-Language Pre-training (VLP)任务大多是基于理解的任务或基于生成的任务,同时预训练数据多是从web获取的图像-文本对,存在很大的噪声。
因此作者提出了BLIP架构,引导语言图像预训练,以实现统一的视觉语言理解和生成。
2 BLIP的创新点
-
BLIP 提出了一种编码器-解码器混合架构(MED):一种用于有效多任务预训练和灵活迁移学习的新模型架构。
MED有三个子模块:①. 单模态编码器。②. 基于图像的文本编码器。 ③.基于图像的文本解码器。
完成了三个视觉语言目标联合预训练任务:①.图像文本对比。②.图像文本匹配。 ③.图像条件语言建模。 -
BLIP 提出了一种高效利用网络噪声数据的方法:字幕和过滤(CapFilt)
即先使用噪声数据训练一遍 BLIP,再利用预训练的 Captioner 生成一系列的字幕,再把这些生成的字幕通过预训练的 Filter 过滤一遍,从原始网络文本和合成文本中删除嘈杂的字幕,得到干净的数据。最后再使用干净的数据训练一遍 BLIP。
3 BLIP的模型架构
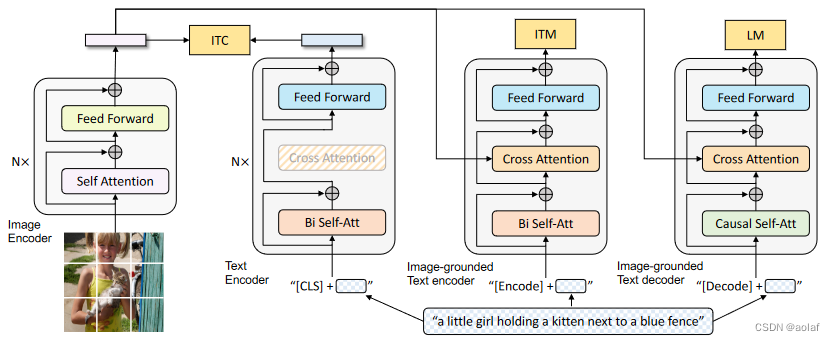
3.1 图像编码器:提取图片特征
使用VIT作为图像编码器,把输入图像分成patch,将它们编码为一系列 Image Embedding,并使用额外的[CLS] token来表示全局图像特征。
3.2 文本编码器:提取文本特征
文本编码器与BERT相同,其中将 [CLS] token附加到文本输入的开头以概括句子。
3.3 基于图像的文本编码器
在文本编码器的双向自注意层 (Bi-Self-Attention) 和前馈网络 (FFN) 之间插入一个额外的交叉注意 (Cross-Attention) 层来注入视觉信息。将[Encode] token附加到文本输入的开头,用作图像-文本对的联合表征。
3.4 基于图像的文本解码器
将基于图像的文本编码器中的双向自注意力层 (Bi-Self-Attention) 替换为因果自注意力层(Causal-Self-Attention )。[Decode] token用于表示序列的开始,而[EOS] token用于表示序列的结束。
4 BLIP预训练目标损失函数
在预训练期间共同优化了三个目标,其中两个基于理解的目标(图文对比、图文匹配)和一个基于生成的目标。每个图像-文本对仅通过一次计算量较大的视觉Transformer的正向传递,同时通过三次文本转换器的正向传递。其中文本端仅cross-attention和Causal-Self-Attention 不共享外,其余参数均共享。
4.1 图文对比损失(Image-Text Contrastive Loss,ITC)
ITC 作用于视觉编码器和文本编码器,目标是对齐视觉和文本的特征空间。使得正样本图文对的相似性更高,负样本图文对的相似性更低。
4.2 图文匹配损失 (Image-Text Matching Loss,ITM)
ITM 作用于视觉编码器和视觉文本编码器,目标是学习图像文本的联合表征,以捕获视觉和语言之间的细粒度对齐。ITM 是一个二分类任务,使用一个分类头来预测图像文本对是正样本还是负样本。
4.3 语言模型损失 (Language Modeling Loss, LM)
LM 作用于视觉编码器和 视觉文本解码器,目标是根据给定的图像以自回归方式来生成关于文本的描述。与 VLP 中广泛使用的 MLM 损失 (完形填空) 相比,LM 使模型能够将视觉信息转换为连贯的字幕。
5 CapFilt
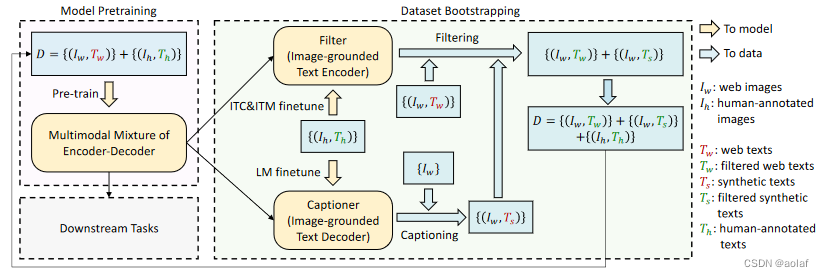
5.1 CapFilt的意义
高质量的人工注释图像-文本对 {(Ih, Th)} (例如,COCO) 因为成本高昂所以数量不多 。网络替代数据集 {(Iw, Tw)} 质量相对嘈杂,不会准确地描述图像的视觉内容。
作者提出了字幕和过滤(Captioning and Filtering,CapFilt),这是一种提高文本语料库质量的新方法。上图给出了CapFilt的图示。它引入了两个模块:一个用于生成给定web图像对应字幕的字幕器,以及一个用于去除噪声图像-文本对的过滤器。
5.2 字幕器 Captioner
它是一个视觉文本解码器,在 COCO 数据集上使用 LM 目标函数微调。给定网络图片 Iw,Captioner 生成字幕Ts
5.3 过滤器 Filter
它是一个视觉文本编码器,看文本是否与图像匹配,在 COCO 数据集上使用 ITC 和 ITM 目标函数微调。Filter 删除原始 Web 文本 Tw 和合成文本 Ts 中的嘈杂文本。