【Langchain Agent研究】SalesGPT项目介绍(二)
【Langchain Agent研究】SalesGPT项目介绍(一)-CSDN博客
上节课,我们介绍了SalesGPT他的业务流程和技术架构,这节课,我们来关注一下他的项目整体结构、poetry工具和一些工程项目相关的设计。
项目整体结构介绍
我们把整个项目从git上拉下来之后,来看一下它的整体工程结构:
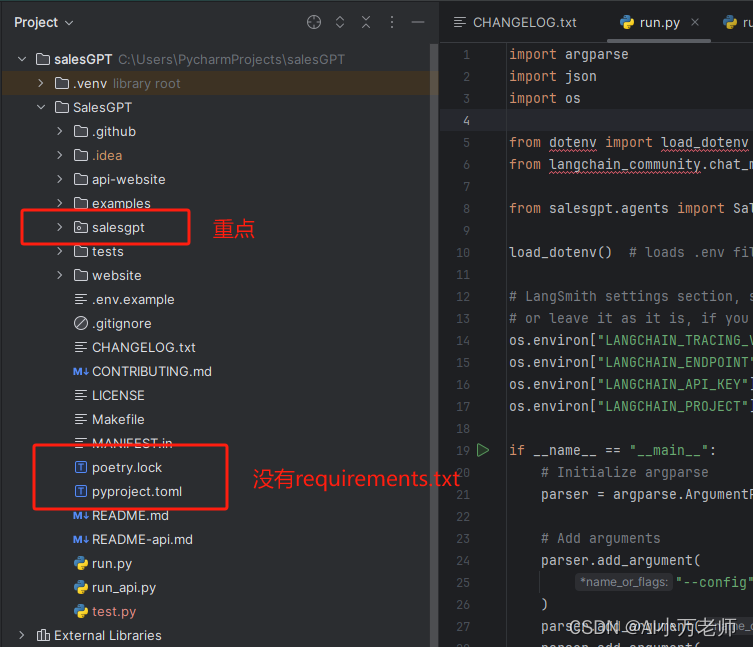
这里面所有的文件,其中,最最重要的是salesgpt这个文件夹,打开这个文件夹,可以看到里面的python文件:
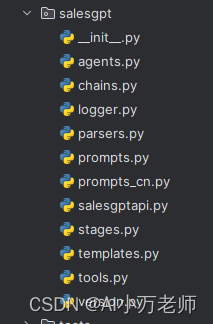
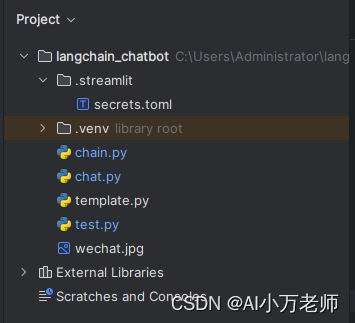
回想一下,我们旅游聊天机器人(【Langchain+Streamlit】旅游聊天机器人-CSDN博客)里面的工程结构,和这个有些类似是不是?只不过多了logger、parsers等其他的python文件,这些我们后面会涉及到:
所以后面我们会重点研究salesgpt文件夹里面的东西。我们在看salesGPT整个工程结构的时候发现一个问题,就是我们找不到一般项目的requirements.txt,但是我们发现了这两个文件:

我们打开pyproject.toml,看看里面的代码:
[tool.poetry]
name = "SalesGPT"
version = "0.1.1"
description = "SalesGPT - Your Context-Aware AI Sales Assistant"
authors = ["Filip Michalsky "]
license = "Apache-2.0"
readme = "README.md"
homepage = "https://github.com/filip-michalsky/SalesGPT"
repository = "https://github.com/filip-michalsky/SalesGPT"
classifiers = ["Development Status :: 4 - Beta","Intended Audience :: Developers","License :: OSI Approved :: Apache Software License","Programming Language :: Python :: 3","Programming Language :: Python :: 3 :: Only","Programming Language :: Python :: 3.8","Programming Language :: Python :: 3.9","Programming Language :: Python :: 3.10","Programming Language :: Python :: 3.11","Topic :: Scientific/Engineering :: Artificial Intelligence",
]
keywords = ["openai", "sales", "gpt", "autonomous", "agi"][tool.poetry.dependencies]
python = "^3.8.1"
langchain = "0.1.0"
openai = "1.7.0"
chromadb = "^0.4.18"
tiktoken = "^0.5.2"
pydantic = "^2.5.2"
litellm = "^1.10.2"
ipykernel = "^6.27.1"
pytest = "^7.4.3"
pytest-cov = "^4.1.0"
pytest-asyncio = "^0.23.1"
langchain-openai = "0.0.2"[tool.poetry.group.dev.dependencies]
black = "^23.11.0"
flake8 = "^6.1.0"
isort = "^5.12.0"
pytest = "^7.4.3"
pytest-cov = "^4.1.0"[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
大概可以猜出来这是一个类似配置文件的东西,上面有项目的基本信息,然后是项目的依赖,基本上可以确定这个文件就是顶替requirements.txt的,这个叫poetry的东西我们之前没有接触过,不过在网上能找到大把资料,我们花一小节简单介绍一下这个东西。
poetry介绍
简单来说,对于较大型、复杂和需要部署的项目,需要有好的依赖管理、虚拟环境管理、打包和发布的工具,poetry就是来做这个的。poetry的主要作用有如下三点:
1. 项目的依赖管理(下载和追踪)。替代pip的功能
2. 虚拟环境的管理。替代传统的python虚拟环境构建方法,poetry直接生成一个可直接使用的虚拟环境。
3. 打包和发布管理。这个我们知道就行了,暂时还用不上。
这个是poetry的官网和一些我觉得介绍poetry比较好的CSDN博主介绍文章:
1. 官网:Poetry - Python dependency management and packaging made easy
2. poetry其他博主的介绍:Python 依赖管理及打包三方库 Poetry_python poetry-CSDN博客
大家可以自己花一些时间去看一下poetry这个管理工具怎么用,我觉得这个工具设计得还是蛮好的,对于依赖管理、虚拟环境管理和打包发布都很方便,以后我们自己的大型项目我们也都用poetry好了。
运行文件run.py 和 run-api.py分析
我们看一下项目里的可运行文件(.py)只有两个:

我们来看一下run.py的代码:
import argparse
import json
import osfrom dotenv import load_dotenv
from langchain_community.chat_models import ChatLiteLLMfrom salesgpt.agents import SalesGPTload_dotenv() # loads .env file# LangSmith settings section, set TRACING_V2 to "true" to enable it
# or leave it as it is, if you don't need tracing (more info in README)
os.environ["LANGCHAIN_TRACING_V2"] = "false"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = os.getenv("LANGCHAIN_SMITH_API_KEY")
os.environ["LANGCHAIN_PROJECT"] = "" # insert you project name here引入必要的包,load_dotenv()用来加载环境变量,主要是openai_key。然后是langchain_smith的引入,langchain_smith是用来进行过程监督和控制的,这个我们有时间单独来讲一下,这个东西是一个辅助管理工具,可以不要。
然后是main函数里面的东西:
if __name__ == "__main__":# Initialize argparseparser = argparse.ArgumentParser(description="Description of your program")# Add argumentsparser.add_argument("--config", type=str, help="Path to agent config file", default="")parser.add_argument("--verbose", type=bool, help="Verbosity", default=False)parser.add_argument("--max_num_turns",type=int,help="Maximum number of turns in the sales conversation",default=10,)# Parse argumentsargs = parser.parse_args()# Access argumentsconfig_path = args.configverbose = args.verbosemax_num_turns = args.max_num_turns这个argparse也是一个新东西,我们之前也没见过,来看看它是做什么的。这个模块的介绍资料网上也是大把(argparse简介-CSDN博客),argparse 模块是 Python 内置的用于命令项选项与参数解析的模块,argparse 模块可以让人轻松编写用户友好的命令行接口,能够帮助程序员为模型定义参数。
这块代码的作用就是方便用户运行代码时,进行输入的(通过命令行),其中最主要的是
max_num_turns这个参数有实际的用处。我们之前介绍过agent,agent会不断审查agent_executor的执行结果,有可能就进死循环了(而且会不断消耗token),所以需要设置一个最大运行轮次来控制agent的循环轮次。这个参数就和我们之前在构造agentexecutor里设置的max_iterations是一个东西【2024最全最细LangChain教程-13】Agent智能体(二)-CSDN博客 这里面有这个参数,我直接截图了

可以看到上面的代码主要是用来获取用户输入的,我们继续来看代码:
llm = ChatLiteLLM(temperature=0.2, model_name="gpt-3.5-turbo-instruct")if config_path == "":print("No agent config specified, using a standard config")# keep boolean as string to be consistent with JSON configs.USE_TOOLS = "True"if USE_TOOLS == "True":sales_agent = SalesGPT.from_llm(llm,use_tools=USE_TOOLS,product_catalog="examples/sample_product_catalog.txt",salesperson_name="Ted Lasso",verbose=verbose,)else:sales_agent = SalesGPT.from_llm(llm, verbose=verbose)else:with open(config_path, "r", encoding="UTF-8") as f:config = json.load(f)print(f"Agent config {config}")sales_agent = SalesGPT.from_llm(llm, verbose=verbose, **config)这里构造了一个llm,然后判断一下用户之前的输入有没有config信息,如果没有项目config信息的话就构造一个默认的sales_agent,注意这里使用的SalesGPT的 from_llm方法,这个方法是后面我们关注的重点。这个agent使用了一个默认的产品目录和销售人员名称。
这块代码有点让人困惑的就是这块,大家应该知道我在说啥:
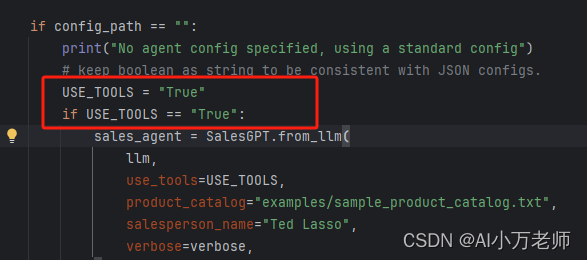
这段代码运行到这里,我们就成功构造了一个sales_agent,然后我们继续往下走:
sales_agent.seed_agent()print("=" * 10)cnt = 0while cnt != max_num_turns:cnt += 1if cnt == max_num_turns:print("Maximum number of turns reached - ending the conversation.")breaksales_agent.step()# end conversationif "<END_OF_CALL>" in sales_agent.conversation_history[-1]:print("Sales Agent determined it is time to end the conversation.")breakhuman_input = input("Your response: ")sales_agent.human_step(human_input)print("=" * 10)然后我们用seed_agent()这个方法来初始化一下这个agent,然后就开始进入用户输入、系统输出的阶段了,这里都是用CMD来交互的。
这里会用到之前我们设置的max_num_turns这个参数,如果达到了这个上限就终止对话,如果没有的话,就调用sagels_agent的step方法来进行输出。
如果sales_agent的会话历史conversation_history的最后一个元素不是"END_OF_CALL",就让用户进行他的输入,并把用户输入放到sales_agent的human_step这个方法里作为入参。
可以看到,run.py整个代码的逻辑是:设置用户命令行输入的参数结构,如果没有的话就用默认设置,然后初始化agent,然后让agent先向用户提问,然后让用户通过命令行输入,然后一轮一轮进行对话,直到到达用户设置的最大轮次(默认是10次)或者对话完结。这个基本上就是run.py的整个业务流程。不难看出,这里最重要的就是:
from salesgpt.agents import SalesGPT从这里引入的SalesGPT这个类了,通过这个类实例化构造的agent,是整个业务逻辑的核心,下节课我们开始重点分析SalesGPT这个类。
最后我们来看看run-api.py这个文件:
import os
from typing import Listimport uvicorn
from fastapi import FastAPI
from pydantic import BaseModelfrom salesgpt.salesgptapi import SalesGPTAPIapp = FastAPI()GPT_MODEL = "gpt-3.5-turbo-0613"
# GPT_MODEL_16K = "gpt-3.5-turbo-16k-0613"@app.get("/")
async def say_hello():return {"message": "Hello World"}class MessageList(BaseModel):conversation_history: List[str]human_say: str@app.post("/chat")
async def chat_with_sales_agent(req: MessageList):sales_api = SalesGPTAPI(config_path="examples/example_agent_setup.json", verbose=True)name, reply = sales_api.do(req.conversation_history, req.human_say)res = {"name": name, "say": reply}return resdef _set_env():with open(".env", "r") as f:env_file = f.readlines()envs_dict = {key.strip("'"): value.strip("\n")for key, value in [(i.split("=")) for i in env_file]}os.environ["OPENAI_API_KEY"] = envs_dict["OPENAI_API_KEY"]if __name__ == "__main__":_set_env()uvicorn.run(app, host="127.0.0.1", port=8000)
简单浏览一下整个代码,尤其是main函数里的东西,就大概知道了,这是要用FASTAPI(一种用python快速构建服务端的工具)来构建一个可以给前端响应的后端服务,那我们就基本明白了这是聚焦于如何和用户交互获取用户输入信息的另外一个版本,和run.py没有啥本质的区别,就是交互方式不一样了,所以我们也不需要花太多时间在这个上面。如果到了服务要部署的时候,我们再系统地学习一遍FASTAPI工具然后模仿他这块的代码就行,后面我们就不讲这块代码了,我们就用run.py的命令行方式来和agent交互就足够了。