1.机器学习笔记第一周
机器学习利用领域:
1:随着网络数据增大,需要搜集用户的数据,做喜好性偏向判断等。
2:只要有数据的,无论是医疗领域,还是基因领域都是需要机器学习来发现数据密码。
3:机器自我学习类,飞机自己飞。
4:文字识别,路线规划
目前我所认为的机器学习本质:大数据技术,通过算法学习大量数据,然后给出预测或相关结果。
对于回归和分类算法的区别。
回归:对象是连续的数据,你要预测最后大致在哪一个区间,或者说具体的,杭州西湖区去年房子价格,然后要去预测今年西湖区平均房价。定量的算法。
分类:对象是离散的,比如我得了肿瘤,预测是良性还是恶性的,当然结果不一定是两个,可以是很多个,但是最后是要给判断性结果,简单说就是要定性。
监督学习:所有数据的输入就是人已经经过了第一次判断,比如这个是恶性肿瘤(已经被人为判断),你要先输入一定的定性判断。
无监督学习:就是单纯的数据集
聚类算法:无序数据集,可以通过算法将数据分类,比如每天今日头条的新闻,关于“恐怖袭击”这个关键词,搜索引擎会每天搜集上万条新闻,然后通过分类算法,把相关的新闻推送给你。
比如京东有很多用户,偏向数码类,母婴,衣服,不同类型的客户,随着浏览的商品或者搜索的商品等数据,可以判断这个顾客属于什么类型的顾客,做什么推动。
模型与线性回归
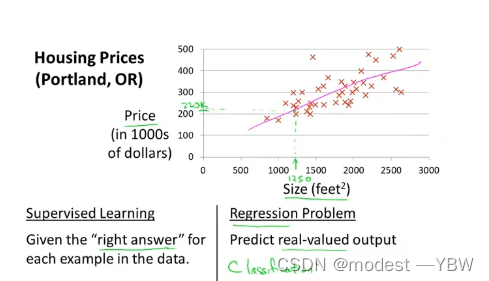
这是一个面积与放假模型,然后可以设置x和y 关系就变成了x通过h假设等于y
那么这就是一个回归问题,这个是一元的,所以是线性回归

这就是一个标准的预测集
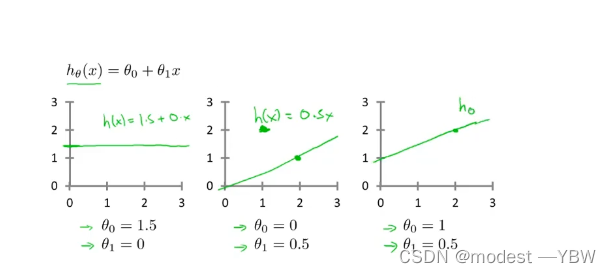
随着假设函数不同,拟合结果会有很大的不同
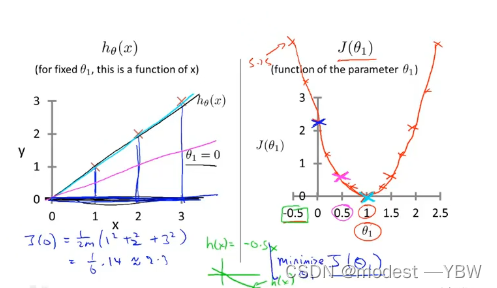
这样计算的目的在于方差最小,得到最佳曲线。
最佳曲线的计算方法就是差值平方方差

涉及的第二个概念代价函数(平方误差函数)
样本存在一个总体偏差量,代价函数的定义我可以称作个体偏差,也就是对应的代价。
所以说这样看来,代价函数在回归问题中,充当一个标准,可以对某种回归方式做具体评价。
第一个是假设函数,第三个是代价函数

然后是,随着关系函数的变化,代价函数会出现对应
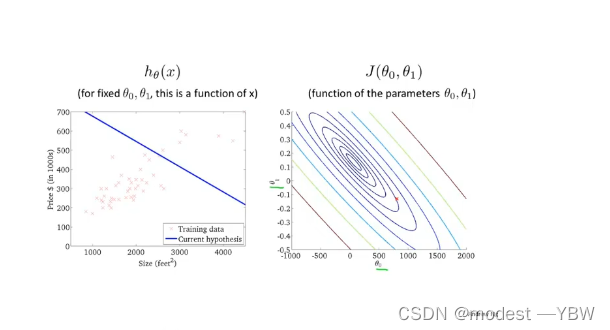
同理,变量变成两个的时候,代价函数就是依然是碗装,只不过变成三维,理论上是n+1
为了数学好解释,转化为等高线图