Python - 深夜数据结构与算法之 Two-Ended BFS

目录
一.引言
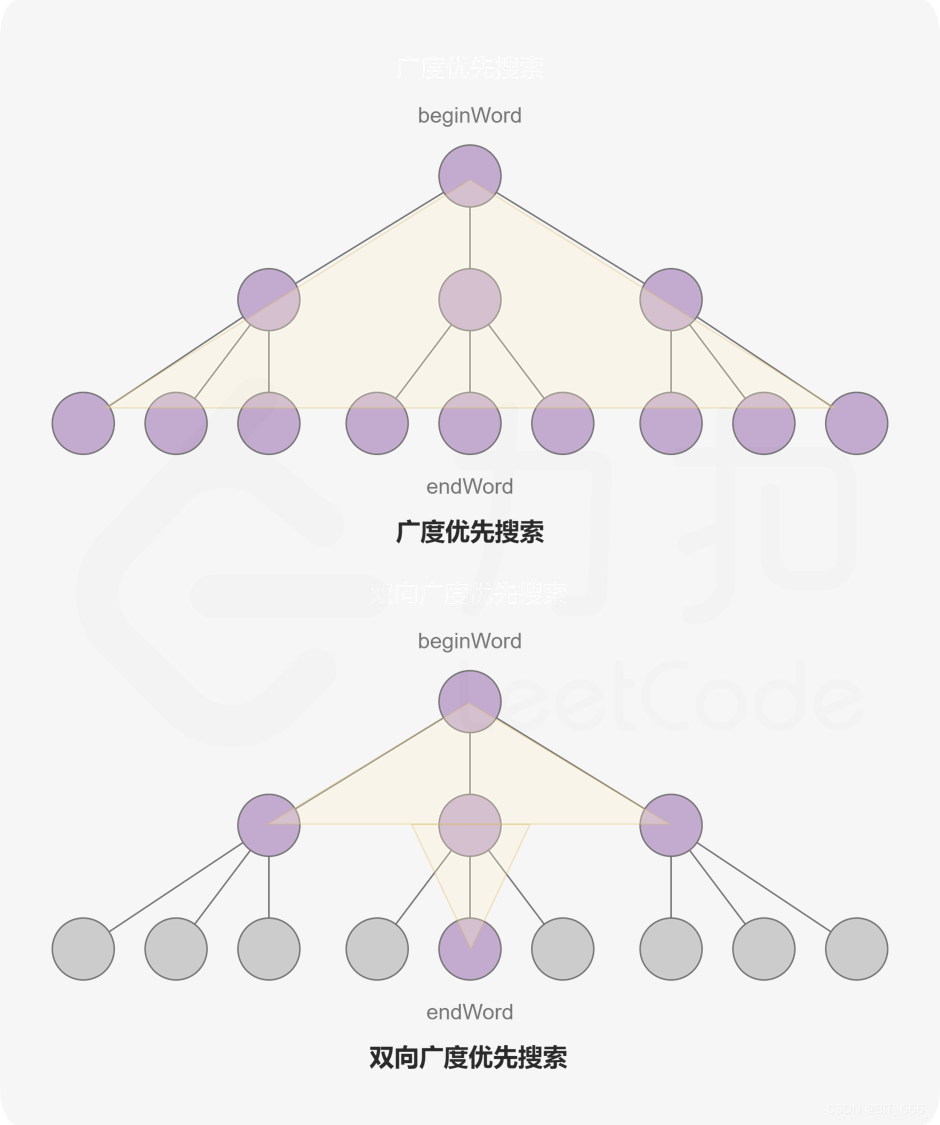
二.双向 BFS 简介
1.双向遍历示例
2.搜索模版回顾
三.经典算法实战
1.Word-Ladder [127]
2.Min-Gen-Mutation [433]
四.总结
一.引言
DFS、BFS 是常见的初级搜索方式,为了提高搜索效率,衍生了剪枝、双向 BFS 以及 A* 即启发式搜索等高级搜索方式。剪枝通过避免不必要或者次优解来减少搜索的次数,提高搜索效率;双向 BFS 通过层序遍历从首尾逼近答案,提高搜索效率;启发式搜索则是从优先级的角度出发,基于优先级高低搜索,提高搜索效率。本文主要介绍双向 BFS 的使用。
二.双向 BFS 简介
1.双向遍历示例
◆ 双向连通图
求 A -> L 所需最短路径。
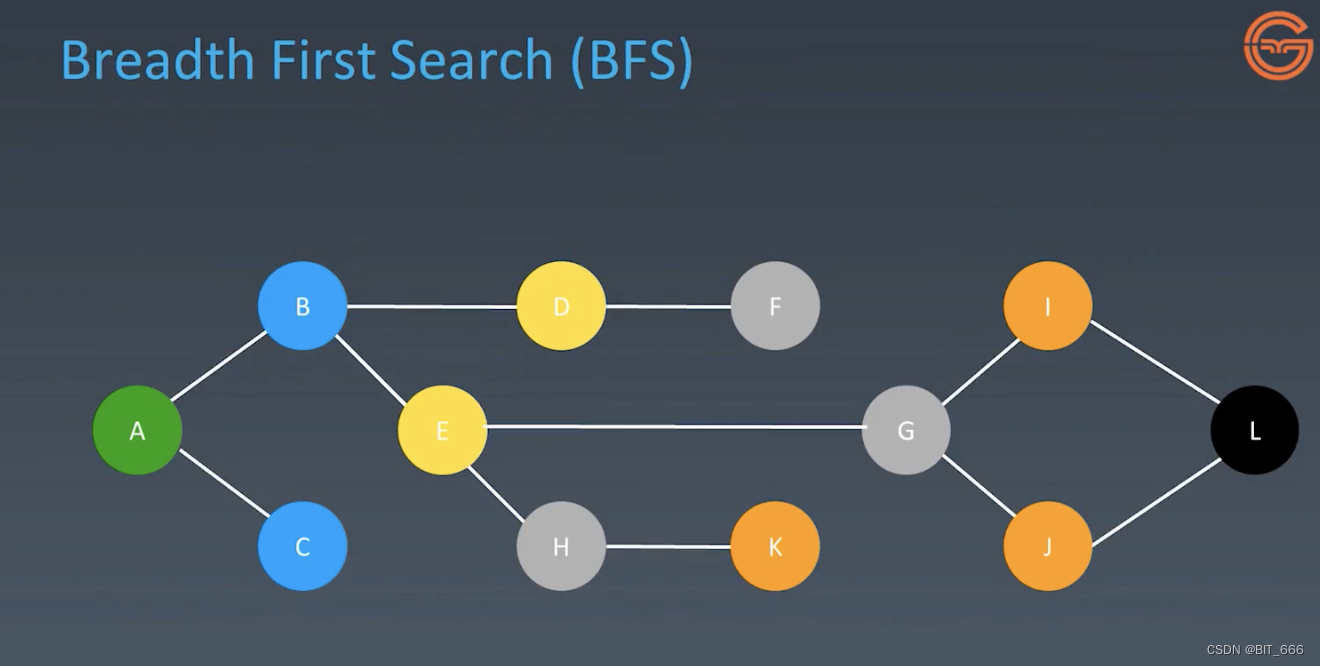
◆ 遍历层级关系
不同颜色代表不同层级的 BFS,绿色为 root,蓝色为第二层,从左向右递推。
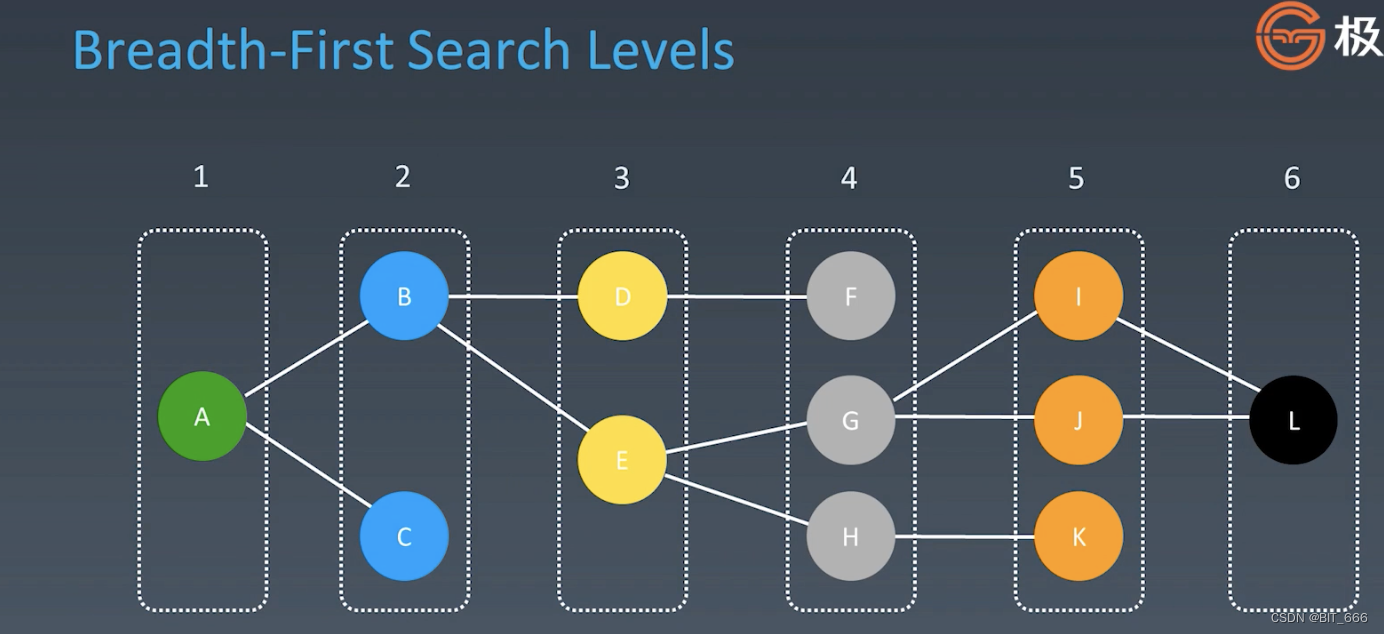
◆ 双向遍历
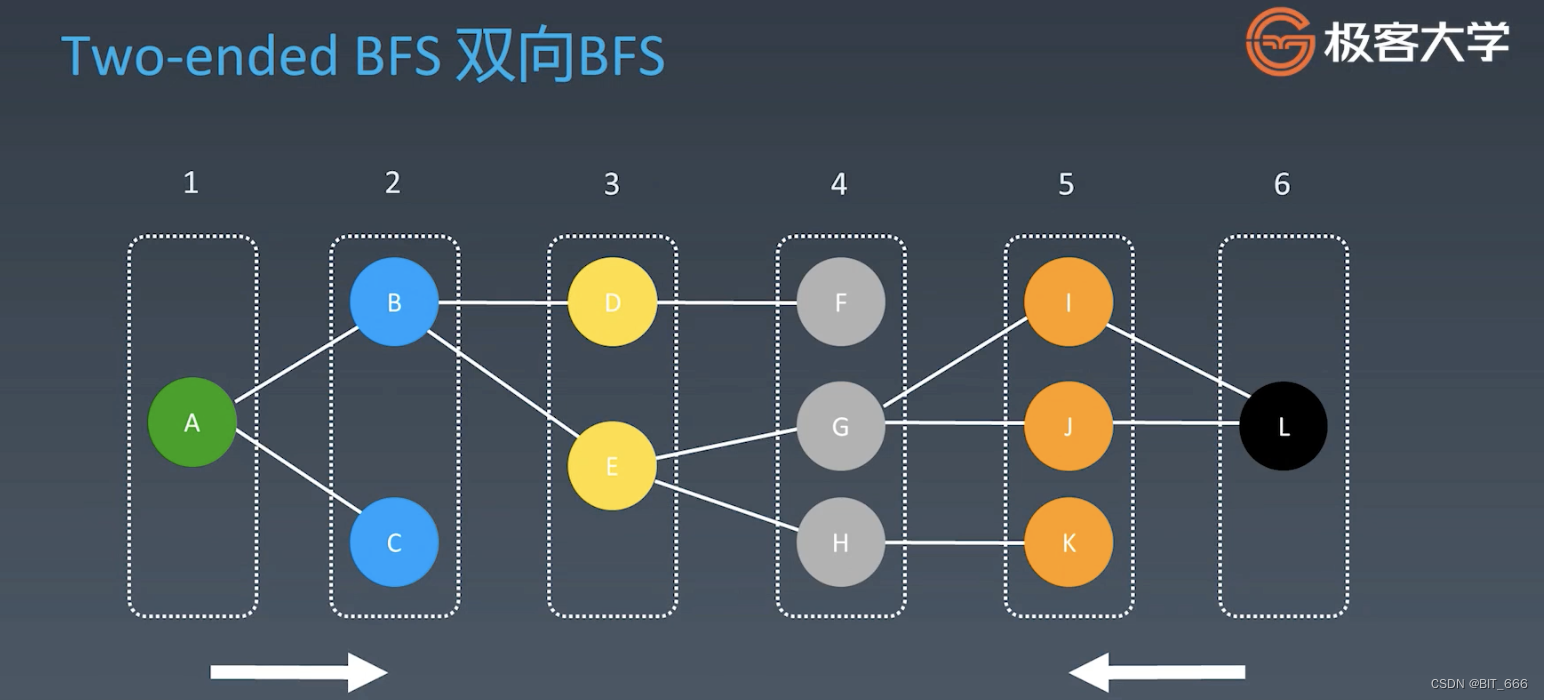
从 A/L 同时层序遍历,当二者扩散的点重合时,左右路径长度相加即为最短路径。
2.搜索模版回顾
◆ DFS - 递归

◆ DFS - 非递归

◆ BFS - 栈

三.经典算法实战
1.Word-Ladder [127]
单词接龙: https://leetcode.cn/problems/word-ladder/description/

◆ 单向 BFS
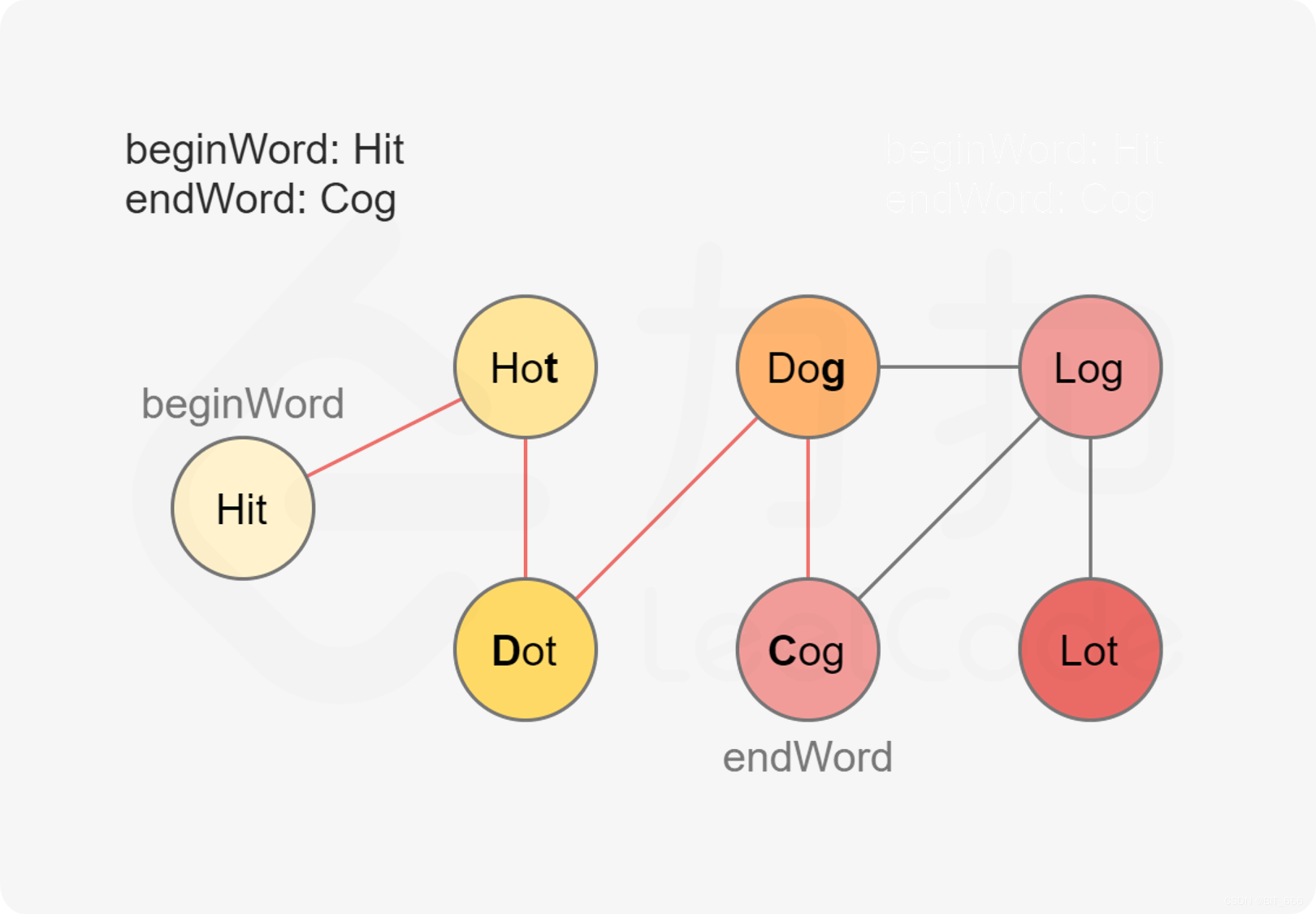
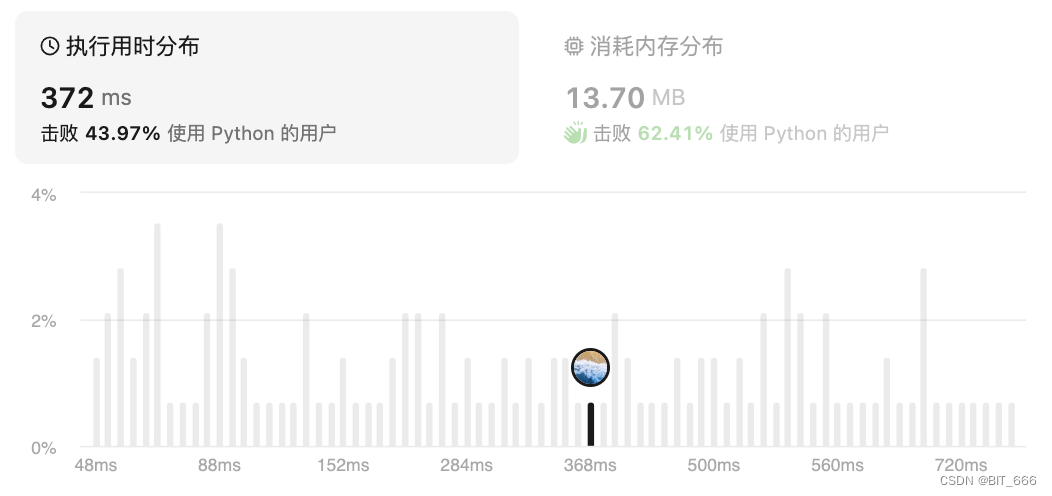
class Solution: def ladderLength(self, beginWord, endWord, wordList):""":type beginWord: str:type endWord: str:type wordList: List[str]:rtype: int"""valid_word = set(wordList)if endWord not in valid_word:return 0stack = [(beginWord, 1)]while stack:word, level = stack.pop(0)for i in range(len(word)):for char in "abcdefghijklmnopqrstuvwxyz":new_word = word[:i] + char + word[i + 1:]if new_word == endWord:return level + 1elif new_word in valid_word:stack.append((new_word, level + 1))valid_word.remove(new_word)return 0这里我们可以打印一下转换的流程图,hot 有多层 level 出发,第二条路径走到了 cog,即结束遍历,当然 log 也可以走到 cog 只不过已经不需要了。
hot 2 -> lot 3
hot 2 -> dot 3 -> dog 4 -> cog 5
hot 2 -> dot 3 -> log 4
◆ 双向 BFS
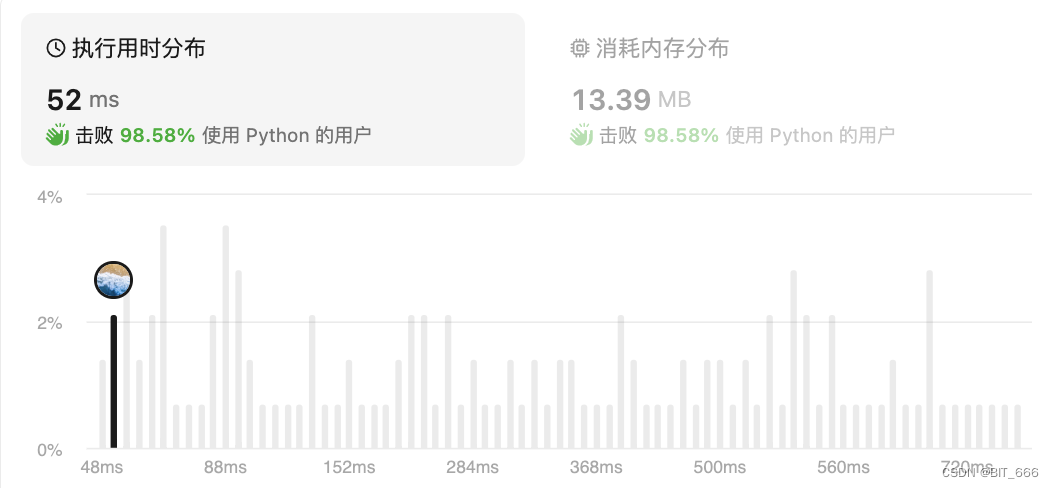
class Solution(object):def ladderLength(self, beginWord, endWord, wordList):""":type beginWord: str:type endWord: str:type wordList: List[str]:rtype: int"""# 去重使用valid_word = set(wordList)# 边界条件if endWord not in wordList or len(wordList) == 0:return 0# 双向 BFSbegin, end, step = {beginWord}, {endWord}, 1# 同时有元素才能继续,如果一遍没元素代表已中断,无法联通,直接结束while begin and end:# 减少排查的可能性,从单词少的方向排查,避免无效查询if len(begin) > len(end):begin, end = end, begin# 存储下一层next_level = set()# 遍历下一层的多个结果for word in begin:# 遍历每个位置for i in range(len(word)):# a-zfor char in "abcdefghijklmnopqrstuvwxyz":# 节省无必要的替换if char != word[i]:new_word = word[:i] + char + word[i + 1:]# 二者相遇即返回if new_word in end:return step + 1if new_word in valid_word:next_level.add(new_word)valid_word.remove(new_word)# 指针替换begin = next_levelstep += 1return 0已经将详细的注释加在代码里了,从 {start},{end} 两个方向查找,每次只找短的缩小无效查询的次数,这其实也是一种剪枝的策略,正所谓图中有真意欲辨已忘言:
◆ 双向 BFS + 剪枝
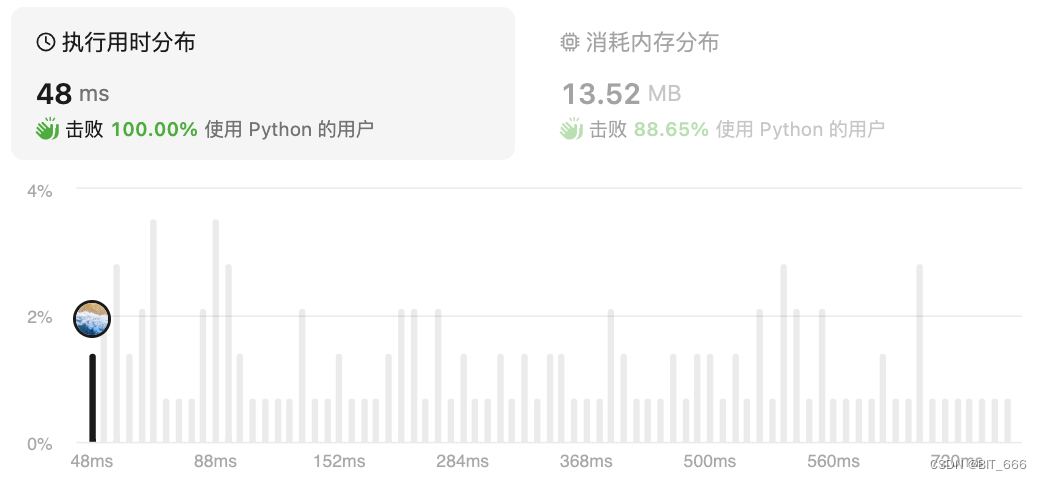
class Solution(object):def ladderLength(self, beginWord, endWord, wordList):""":type beginWord: str:type endWord: str:type wordList: List[str]:rtype: int"""# 去重使用valid_word = set(wordList)if endWord not in wordList or len(wordList) == 0:return 0# 剪枝优化s = set()for word in wordList:for char in word:s.add(char)s = ''.join(list(s))# 双向 BFSbegin, end, step = {beginWord}, {endWord}, 1while begin and end:if len(begin) > len(end):begin, end = end, begin# 存储下一层next_level = set()for word in begin:for i in range(len(word)):# a-zfor char in s:# 节省无必要的替换if char != word[i]:new_word = word[:i] + char + word[i + 1:]if new_word in end:return step + 1if new_word in valid_word:next_level.add(new_word)valid_word.remove(new_word)# 指针替换begin = next_levelstep += 1return 0上面的两个方法在构建 new_word 时都遍历了所有 26 个字母 char,其实我们可以根据 end_word 的去重字符进行状态空间压缩,从而减少无意义的遍历,因为 char not in end_word 则 new_word 必定 not in end_word,从而优化时间复杂度。
2.Min-Gen-Mutation [433]
最小基因突变: https://leetcode.cn/problems/minimum-genetic-mutation/description/

◆ BFS
class Solution(object):def minMutation(self, startGene, endGene, bank):""":type startGene: str:type endGene: str:type bank: List[str]:rtype: int"""if not bank:return -1bank = set(bank)if endGene not in bank:return -1stack = [(startGene, 0)]while stack:gene, level = stack.pop(0)for i in range(len(gene)):for char in "ACGT":new_gene = gene[:i] + char + gene[i + 1:]if new_gene == endGene:return level + 1if new_gene in bank:stack.append((new_gene, level + 1))bank.remove(new_gene)return -1和上一题异曲同工之妙,只不过从单词接龙变成基因 🧬 接龙,每次修改的地方有限。
◆ 双向 BFS
class Solution(object):def minMutation(self, startGene, endGene, bank):""":type startGene: str:type endGene: str:type bank: List[str]:rtype: int"""if not bank:return -1bank = set(bank)if endGene not in bank:return -1# 初始化首尾front, back, step = {startGene}, {endGene}, 0while front and back:next_front = set()# 遍历当前层 Genefor gene in front:print(gene)for i in range(len(gene)):for char in "ACGT":new_gene = gene[:i] + char + gene[i + 1:]# 相遇了if new_gene in back:return step + 1# 下一层突变if new_gene in bank:next_front.add(new_gene)bank.remove(new_gene)# 取短的遍历加速if len(next_front) > len(back):front, back = back, next_frontelse:front = next_frontstep += 1return -1和上面异曲同工,老曲新唱,相当于再温习一遍。其加速点就是左右替换,优先遍历可能性少的情况。

四.总结
这节内容 '双向 BFS' 起始也包含着很多剪枝的策略,所以其也属于优化搜索方式的方法之一,下一节我们介绍高级搜索的最后一块内容: A* 启发式搜索。